📄 ORCA: Open-ended Response Correctness Assessment for Audio Question Answering
#音频理解 #大语言模型 #基准测试 #模型评估 #数据集
7.9/10 | 创新 1.5/2 | 严谨 1.3/1.5 | 实验 1.4/1.5 | 清晰 1/1 | 影响 0.9/1.5 | 开源 0.5/1.5 | 复现 0.3/0.5 | 工程 1/1.5
✅ 7.9/10 | 前25% | #音频理解 | #大语言模型 | #基准测试 #模型评估 | arxiv
👥 作者与机构
- 第一作者:Šimon Sedláček(Brno University of Technology, Speech@FIT)、Sara Barahona(Universidad Autónoma de Madrid)、Bolaji Yusuf(Brno University of Technology, Speech@FIT)、Laura Herrera-Alarcón(Universidad Autónoma de Madrid)、Santosh Kesiraju(Brno University of Technology, Speech@FIT)(注明同等贡献)
- 通讯作者:未说明
- 作者列表:Šimon Sedláček(Brno University of Technology, Speech@FIT)、Sara Barahona(Universidad Autónoma de Madrid)、Bolaji Yusuf(Brno University of Technology, Speech@FIT)、Laura Herrera-Alarcón(Universidad Autónoma de Madrid)、Santosh Kesiraju(Brno University of Technology, Speech@FIT)、Cecilia Bolaños(University of Buenos Aires)、Alicia Lozano-Diez(Universidad Autónoma de Madrid)、Sathvik Udupa(Brno University of Technology, Speech@FIT)、Fernando López(Universidad Autónoma de Madrid)、Allison Ferner(Tufts University)、Ramani Duraiswami(University of Maryland)、Jan Černocký(Brno University of Technology, Speech@FIT)
💡 毒舌点评
亮点:将Beta分布引入音频QA评估,巧妙地把人类评分的均值和分歧度同时建模,并提供了一套完整的三阶段标注-修正流程,数据集价值较高。短板:框架严重依赖由Gemini生成的rationale和Whisper转录文本,这些文本grounding的质量直接影响评估上限;方法在大规模、多类型、多语言音频QA上的泛化能力完全未知,且关键训练超参数意外缺失,削弱了复现信心。
📌 核心摘要
- 该论文针对音频问答(Audio QA)开放回答评估中人类标注经常存在真实分歧(而非噪声)的问题,提出ORCA框架,用于同时预测答案正确性的期望值和标注不确定度。
- 方法核心是将评估建模为预测评分概率分布:基于预训练大语言模型(LLM)编码问题、参考答案、理由、转录和候选答案,再用小型MLP输出Beta分布的两个参数(α, β),通过极大似然学习所有个体评分,同时给出平均分和方差。
- 与传统的LLM-judge点估计相比,ORCA是首个在音频QA中使用分布预测的工作,额外提供方差信息;并通过三阶段人工标注框架系统性地修正基准数据中的问题(问题描述不清、理由不足、参考答案有误等),同步提升训练数据和基准质量。
- 在两个音频QA基准(MMAU、MMAR)上收集了3580个问答对、11721条人工标注,最终保留2459个有效对,Krippendorff’s α从0.76提升至0.82。ORCA(Gemma-3-12B-clamped)Spearman ρ = 0.9103,与最强LLM-judge Gemini-2.5-Flash(ρ=0.8998)相当,MAE更优,且计算量仅需单次前向。在看不见的LALM响应上泛化良好,仅对超长响应模型(Audio-Reasoner)略有蹿陷。
- 实际意义:为音频LALM提供了一种即插即用、可复现、轻量级的评估器,能区分“一致高分/低分”与“真实分歧”情况,更有洞察力;配套的开源数据集和标注流水线可被后续研究复用。
- 主要局限:评估完全依赖从音频自动抽取的文本表示,文本摘要错误会传导;只在两个英文音频QA数据集上验证,多语言或音乐/声音占据极端的场景未覆盖;训练关键超参数未披露;开源资产虽宣传将发布,但评审时点内容未知。
🔗 开源详情
- 代码:https://github.com/BUTSpeechFIT/ORCA
- 模型权重:与代码一并发布于同一 GitHub 仓库,论文未提供单独的 HuggingFace 或 ModelScope 链接。
- 数据集:ORCA 收集并清理的标注数据集(包含 11,721 条初始标注,过滤后 8,571 条)将在同一仓库发布。原始基准 MMAU 和 MMAR 的获取方式论文未提供链接。
- Demo:论文中未提及
- 复现材料:训练与评估配置在论文第5节及附录中给出(但不含关键训练超参数);代码仓库将包含训练脚本和标注框架。
- 论文中引用的开源项目:
- OLMo-2(Walsh et al., 2025):https://github.com/allenai/OLMo
- Gemma 3(Gemma Team, 2025a):https://ai.google.dev/gemma(模型权重在 HuggingFace 等平台开放)
- Llama 3.2(Llama Team, 2024):https://www.llama.com/
- Llama 3.1(Llama Team, 2024):同上
- Qwen2.5(Qwen Team, 2025):https://github.com/QwenLM/Qwen2.5
- Prometheus 2(Kim et al., 2024):https://github.com/kaistAI/Prometheus
- Whisper large-v3(Radford et al., 2023):https://github.com/openai/whisper
- POTATO annotation tool(Pei et al., 2022):https://github.com/UKPLab/potato
- MMAU 基准(论文中未提供链接,需参考原论文)
- MMAR 基准(论文中未提供链接,需参考原论文)
🏗️ 方法概述和架构
ORCA是一个基于预训练大语言模型的评估框架,核心思想是将音频QA答案评估建模为预测人类评分分布而非单一分数。整体流程分为数据准备、标注收集、模型训练与推理三个大阶段,其中标注阶段采用三阶段人工框架对基准进行修正。
模型架构:ORCA以冻结或可训练的预训练transformer LLM为骨架。评估输入由五个文本部件拼接:问题(\(q\))、参考答案(\(r\))、由Gemini-2.5-Flash生成的理由(\(a\),解释为什么\(r\)是正确答案)、由Whisper-large-v3生成的音频转录(\(t\),仅对语音类问题)、以及待评估的候选回答(\(c\))。通过分隔符串联形成 \(x = [q; r; a; t; c]\),送入LLM得到最终隐藏表示 \(\mathbf{h}_{\mathrm{final}}\)。上方接入一个单隐层MLP,直接输出 \(\log \alpha\) 和 \(\log \beta\),经 \(\exp\) 还原为 \(\alpha, \beta >0\),定义[0,1]区间上的Beta分布 \(\mathrm{Beta}(y; \alpha, \beta)\)。训练目标为最大化所有人类评分的对数似然,将1-5分线性归一化至[0,1]后作为样本。模型无需音频特征,仅依赖文本表示,避免了用音频模型评判音频模型的循环依赖。
三阶段标注框架:
- 阶段1:数据准备。并行进行(1a)用Gemini-2.5-Flash和Whisper-large-v3为每个基准问题生成理由、转录;(1b)用15个当前SOTA音频大语言模型生成候选回答,确保答案多样性和不同错误模式。具体模型包括:Audio Flamingo 2 & 3, Audio Reasoner, DeSTA2 & DeSTA2.5-Audio, GAMA, Gemma-3n (2B, 4B), GLM-4-Voice, Kimi-Audio, Qwen2-Audio-7B & Qwen2-Audio-7B-Instruct, Qwen2.5-Omni-7B, and SALMONN (7B, 13B)。所有问题-模型配对的候选回答总数达30,000个(2000个问题 × 15个模型)。
- 阶段2:标注与反馈。37名经过培训的标注员(研究生、研究人员和教授)基于问题、参考答案、理由、转录、候选答案这五样纯文本信息,在POTATO标注工具构建的界面上给出1-5分正确性评分。当文本信息不足时,标注员可以选择收听原始音频。评分同时提供结构化反馈(代码Q:问题不完整,A:理由不足,R:参考答案错误,U:因模糊无法判断,E:缺乏专业知识)以及自由格式评语。LLM-judge并行执行相同输入下的评分,供后续对比。
- 阶段3:迭代修正。6名领域专家根据反馈对问题、参考答案、理由、转录进行校正。修正过程与AI辅助生成相结合,但所有修改均经人工核验。共修正791处(MMAU: 464,MMAR: 327),涉及402个问题、73个参考答案和316个理由。修正后的数据重新回流到阶段1b生成新候选回答。基于阶段3的修正,过滤掉与不可靠问题相关的1121个问答对(对应3150条评分,占总数32%)。这些被过滤的评分一致性较低(α=0.59),确认其不可靠。最终保留2459个有效问答对(含8571条评分),标注一致性从α=0.76提升至α=0.82。尽管如此,仍有17.7%的问答对评分方差大于1.0,表明存在真正的解释性模糊,这正是ORCA分布建模的动机。
分布建模细节:推导上,Beta分布的均值为 \(\mu = \alpha / (\alpha + \beta)\),方差 \(\sigma^2 = \alpha\beta / [(\alpha+\beta)^2(\alpha+\beta+1)]\),自然地提供了点估计和不确定性度量。训练时,单个问答对可以有来自多位标注员的多个评分,每个评分视为同一Beta分布的独立采样,损失为总负对数似然:\(\mathcal{L}_{\mathrm{Beta}}(\theta) = \sum_{i\in\mathcal{D}}\sum_{j=1}^{N_i} \log \mathrm{Beta}(y_{i,j}; \alpha_i, \beta_i)\)。此设计使得ORCA能同时捕捉高共识(低方差)与高分歧(高方差)的场景。
后处理:ORCA的Beta分布天然避免输出精确的0或1(与人类和LLM-judge不同),导致在极端��附近产生噪声预测。为此,当ORCA原始预测值在0或1的0.125范围内,且预测方差低于在开发集上优化的阈值时,会将其钳位(clamp)到硬0或1。该阈值通过最大化 \(\rho + \tau - \mathrm{MAE}_{\mu}\) 得到。这一后处理步骤显著提升了Kendall’s τ表现。
推理:仅需单次前向计算α, β,再计算μ和σ²即可,无需生成式解码,因此计算开销极低(单卡15分钟训练)。

💡 核心创新点
- 评分分布预测替代点估计:首次在音频QA评估中引入Beta分布拟合人类判断的全部分布,同时输出期望正确性和标注分歧度,抓住了传统均分指标丢失的不确定性,丰富了评估信息。实验证明即使17.7%的问答对存在高方差(>1.0),ORCA的方差预测MAE也仅为0.018-0.023。
- 三阶段标注‑修正流水线:设计了包含结构化反馈与专家修正的迭代标注框架,在收集训练数据的同时修正基准数据中的问题(问题、参考答案、理由),实现了数据质量和基准质量的双提升。过滤后标注一致性Krippendorff’s α从0.76升至0.82,修正了791处错误,验证了流水线的实用价值。
- 轻量级高精度评估器:基于小尺寸开源LLM(如OLMo2-7B、Gemma-3-12B)的文本‑回归架构,在不使用音频信号与复杂解码的前提下,Spearman ρ达到0.91,与最强的API闭源LLM-judge(Gemini-2.5-Flash)持平,MAE_μ更优(0.084 vs 0.091),推理仅需一次前向,提供了完全可复现和高效率的替代方案。
📊 实验结果
主要基准:MMAU test-mini和MMAR,各1000题,覆盖语音、声音、音乐等模态。评测指标为Spearman ρ,Kendall τ,MAE_μ(均值绝对误差),MAE_σ²(方差绝对误差)。以未见问题(Unseen Questions)划分的5折测试集均值与标准差如下(截取代表性结果):
| Model | Spearman ρ | Kendall τ | MAE_μ | MAE_σ² |
|---|---|---|---|---|
| ORCA Gemma3-12B (clamped) | 0.9103 ± 0.0086 | 0.8085 ± 0.0108 | 0.0840 ± 0.0065 | 0.0199 ± 0.0028 |
| ORCA OLMo2-7B (clamped) | 0.8992 ± 0.0100 | 0.7900 ± 0.0145 | 0.0827 ± 0.0036 | 0.0179 ± 0.0015 |
| Gemini-2.5-Flash (LLM-judge) | 0.8998 ± 0.0066 | 0.8070 ± 0.0073 | 0.0911 ± 0.0048 | — |
| Judge Fusion (-Gemini) | 0.8993 ± 0.0054 | 0.7682 ± 0.0087 | 0.1079 ± 0.0031 | — |
| Average Judge (-Gemini) | 0.8902 ± 0.0065 | 0.7614 ± 0.0099 | 0.1172 ± 0.0026 | 0.0296 ± 0.0014 |
在LALM留出实验中(OLMo2-7B clamped),每次将2个LALM作为测试集、13个LALM作为训练集,覆盖全部10个LALM。除Audio-Reasoner(生成超长答案)外,ORCA在多数保留模型上ρ接近或略低于Gemini但MAE更优,且明显优于融合判官。这表明ORCA对未见过的LALM响应风格具有较好的泛化能力,但对长文本回复的鲁棒性有待提升。
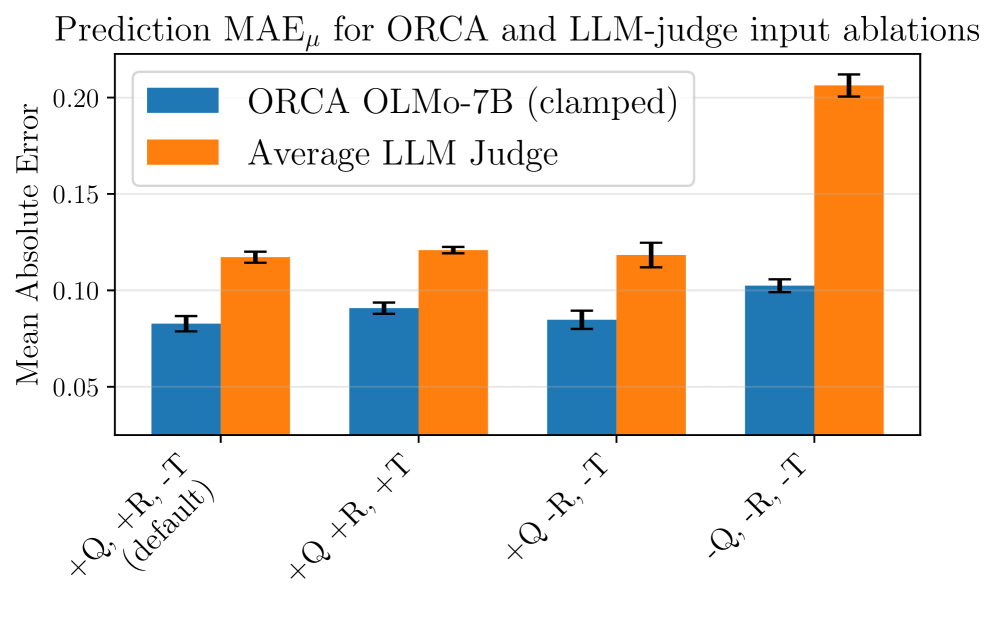
输入消融实验显示(见原文Figure 4,针对ORCA和LLM-judge均值):默认配置使用理由不含转录。移除转录或移除理由均导致MAE略微变差(约+0.003到+0.008),但移除问题导致LLM-judge的ρ从约0.81骤降至0.66左右、MAE翻倍,ORCA的MAE增加约0.022。该实验证实了问题信息最关键,其次才是理由和转录的支持性作用。这些���融通过在评估提示中移除相应字段实现(如原文图7/8所示)。
仅用LLM-judge标注(与人类数据相同问题ID)训练ORCA(OLMo2-7B),其ρ约0.886,MAE为0.108,低于人类数据训练版本(ρ=0.899,MAE=0.083),确认高质量人类标注的关键性。当使用全部可用LLM-judge数据时ρ提升至0.889。更值得注意的是,两阶段训练(先在全量LLM-judge数据上预训练,再在人类数据上微调)将ρ提升至0.902,MAE降至0.085——这表明LLM-judge数据虽质量不如人类数据,但作为预训练数据仍有降低人工标注需求的潜力。

🔬 细节详述
- 训练数据:MMAU test-mini(1000题)和MMAR(1000题)。由15个音频大模型生成候选回答,共30,000个候选对。经标注和过滤后,最终保留2459个有效问答对,含8571条评分(原文中11,721条为Stage 2标注总数,过滤后保留8,571条)。每个问答对平均有2.7条评分,共覆盖3580个原始问答对。被过滤的1,121个问答对(含3,150条评分,占32%)具有较低一致性(α=0.59)。
- 损失函数:最大化Beta分布负对数似然,每条评分独立贡献log-likelihood,目标函数为 \(\mathcal{L}_{\mathrm{Beta}}(\theta) = \sum_{i\in\mathcal{D}}\sum_{j=1}^{N_i} \log \mathrm{Beta}(y_{i,j}; \alpha_i, \beta_i)\),无加权项。
- 训练策略:论文中未说明学习率、batch size、优化器种类、warmup、调度策略、���练epoch数等细节,仅提及训练在单块24GB或48GB GPU上耗时约15分钟。推理:单次前向,后接exp和clamping。
- 关键超参数:模型骨架包括OLMo2-1B/7B、Gemma3-270M至12B、Llama3.2-1B。MLP为单隐藏层(隐藏层维度未给出)。输出log α和log β无额外正则化。后处理clamping的界值为0.125(即预测值在[0, 0.125]钳位为0,[0.875, 1]钳位为1),方差阈值由开发集优化(具体值未给出)。
- 训练硬件:单GPU(24GB或48GB),未说明具体型号或数量。
- 推理细节:直接计算 \(\mu = \alpha/(\alpha+\beta)\),\(\sigma^2 = \alpha\beta/[(\alpha+\beta)^2(\alpha+\beta+1)]\),低方差接近0/1时clamp到硬0/1。
- 数据预处理:评分从1-5线性映射到[0,1]。候选回答由LALM生成时使用的prompt未详细描述。理由由Gemini-2.5-Flash生成,提示词模板在附录B.1中给出。LLM-judge评估提示词在附录B.2中完整展示,包含带完整上下文(理由+转录)、不带转录、不带上下文、不带问题等多种变体。
- 标注细节:1-5分评分标准明确:1=不相关或太长;2=包含少许关键词但不充分;3=至少50%准确但缺关键信息;4=接近但有不必要细节;5=语义完全一致且简短精确。37名标注员在4周内完成。6名专家在2周内完成791处修正。
⚖️ 评分理由
创新性 (1.5/2):首次在音频QA开放回答评估中引入Beta分布建模人类判断的全部分布,实现对“正确性期望”与“标注分歧”的联合预测,扩展了传统均值评分或LLM-judge点估计范式。三阶段标注‑修正框架兼具数据收集与基准质量提升功能,组合设计具有一定新颖性。不是完全范式级突破,因此未达到满分。
技术严谨性 (1.3/1.5):最大似然推导清晰,Beta分布假设对归一化评分自然成立。三阶段数据流水线有明确的量化验证(α从0.76升至0.82,修正791处)。后处理clamping有目标驱动(最大化开发集ρ+τ-MAE)。但存在几点不足:未讨论当真实分布偏离Beta时的模型拟合偏差;完全依赖文本中间表示,未对理由和转录的质量波动进行敏感性分析或纠错机制探讨;训练超参数关键细节缺失,影响了方法复现的严格性。
实验充分性 (1.4/1.5):在未见问题和未见LALM两种场景下进行了5折交叉验证,与多种开源和闭源LLM-judge进行了详尽对比(含单模型和两种聚合策略)。输入消融实验清晰论证了问题、理由、转录的相对重要性。训练数据来源消融(仅人、仅LLM-judge、混合、两阶段)分别揭示了人类数据的关键性和LLM-judge预训练的潜力。缺失部分:未按音频模态(语音/声音/音乐)细分性能,无法判断ORCA在各类别上的相对表现;未进行统计显著性检验。
清晰度 (1.0/1):写作流畅,架构图清晰,三阶段框架和模型结构的表述易懂,附录中的提示词模板和标注指南增加了可操作性。核心不足:训练超参数(学习率、批次大小、优化器、轮次等)完全未披露,读者无法直接复现;后处理方差阈值的优化过程和取值未给出;MLP隐藏层维度缺失。这些缺陷影响了论文的自包含性。
影响力 (0.9/1.5):ORCA为音频LALM评估提供了一个轻量级、可复现、对齐人类判断的工具,其对不确定性的刻画能力弥补了现有LLM-judge的缺陷。三阶段标注框架和开源数据集有可能成为该子领域的基准实践。然而,方法限定在英文语音QA及其文本表示,其在更广泛音频理解(音乐美学、环境声事件检测等)、多语言场景下的可迁移性未被验证,预训练于此的LLM骨架限制了独立部署的通用性。
开源 (0.5/1.5):论文提供了GitHub链接并明确承诺(“will release”)发布代码、模型和数据集。但评审时点链接内容未知,无法验证其完整性和可用性。按“有承诺��未验证”给出基础分。
可复现性 (0.25/0.5):模型架构和标注流程表述清晰。但训练核心配置(学习率等)缺失构成严重障碍,仅凭“15分钟单GPU”远不足以严格复现。
工程/实践价值 (1.0/1.5):提供了从标注界面到模型推理的完整pipeline,有望封装成可安装包,适合算力有限的评测场景。评估计算的轻量性(单次前向 vs LLM-judge的解码)是明确的工程优势。但仍依赖外部模型(Gemini、Whisper)生成输入特征,距独立规模化部署仍有距离。
🚨 局限与问题
论文明确承认的局限:
- 评估完全基于文本表示(理由、转录),理由或转录质量若不可靠会影响评估准确性。Gemini有时仅凭文字线索而非音频内容生成理由,产生无信息量的说明。
- 只在两个英文音频QA基准上验证,对其他音频问答数据集的推广能力未知。
- 当前模型对超长候选回答(如Audio-Reasoner)泛化较差,在留出LALM实验中性能显著下降,可能需要更多样化的训练数据。
- 需要一定量的人工标注数据。虽已证明LLM-judge预训练可部分降低需求,但仍以人类标注为核心。
审稿人发现的潜在问题:
- 缺失关键训练超参数(学习率、批次大小、优化器等),构成严格复现的主要障碍。即使有开源代码,论文本身亦应具备自包含性。
- 未与直接使用音频特征的评估方法进行对比或讨论。全文仅论证了文本评估“避免循环依赖”的优势,但未探讨信息损失的现实代价。例如,对于音乐或环境音频,Whisper转录的语义覆盖不足,而ORCA此时高度依赖Gemini理由的质量,这成为一个单点故障源。
- 未按音频模态(语音、声音、音乐)进行细分评估。对于主观性更强或文本表征更不充分的模态(如音乐、声音),ORCA和LLM-judge可能出现系统性的性能差异,但论文未提供相关分析。
- 1-5评分到[0,1]的线性归一化以及clamping阈值的选取缺乏深入的理论或实验论证,可能在某些分布形态下造成畸变。后处理的方差阈值依赖开发集优化,可能导致过拟合。
- 尽管17.7%的高方差问答对被视为“真实分歧”,本文并未深入分析其来源(是合理的主观差异还是标注指引不清晰导致的歧义)。
- 开源资产目前仅为承诺,实际可用性存疑。
📷 论文图片
