📄 Thinking While Speaking: Inference-Time Knowledge Transfer for Responsive and Intelligent Conversational Voice Agents
#知识蒸馏
6.7/10 | 创新 1.5/2 | 严谨 1.2/1.5 | 实验 1/1.5 | 清晰 1/1 | 影响 0.5/1.5 | 开源 0/1.5 | 复现 0.5/0.5 | 工程 1/1.5
✅ 6.7/10 | 后50% | #知识蒸馏 | #知识蒸馏 | arxiv
👥 作者与机构
Vidya Srinivas†,Zachary Englhardt†,Maximus Powers,Shwetak Patel,Vikram Iyer Paul G. Allen School of Computer Science & Engineering † equal contribution
💡 毒舌点评
这篇工作想法挺直接:让小模型先说话,大模型在后台思考,然后小模型把大模型的结果“塞”进自己的话里。概念上不错,解决了云模型推理慢的问题。但问题在于,你这个“塞”的效率太低了!在NaturalQuestions上,小模型从10%提升到46%听起来不错,但和大模型69%-80%的准确率一比,就知道这个“知识转移”丢了大量信息。更关键的是,你们的核心评估指标——轮级蕴含分析——结果显示大部分生成结果(约60%)被NLI模型判为“中立”。作者在讨论里拼命解释说“中立”可能是“可接受的对话润色”,但作为审稿人,我必须指出这恰恰暴露了当前评估框架的根本缺陷和系统潜在的“事实漂移”风险。论文提出的“对话填充”任务定义本身有价值,但证明其有效性的证据链(特别是从流式知识到最终生成文本的保真度)是不充分、不令人信服的。代码、模型、数据集全部未开源,在这个强调可复现性的时代,这严重削弱了工作的影响力。
📌 核心摘要
本文针对语音智能体部署中“响应延迟”与“模型能力”之间的核心矛盾,提出了一个新任务“对话填充”及其模型实现ConvFill。其核心思想是解耦响应延迟与模型能力:一个轻量级(360M参数)的端侧模型(ConvFill)负责即时生成上下文相关的对话填充词,以维持对话流畅;同时,一个强大的云端后端模型(如GPT-5)在后台异步处理整个对话历史,并以流式方式向端侧模型提供知识块。ConvFill在推理时动态整合这些知识块,生成既流畅又富含知识的回答。实验表明,该系统在多种后端模型配置下均能实现低于200ms的首字延迟,相比同等规模的独立小模型,问答准确率提升36%-42%,但未能完全达到后端模型的性能水平。轮级蕴含分析显示,系统在避免引入事实矛盾(低矛盾率)方面表现尚可,但大量响应与原始知识块存在语义偏差(高“中性”率),揭示了当前方法在保持知识保真度方面的局限。
🔗 开源详情
代码:论文中提及代码将在后续发布,当前未提供任何公开链接。
模型权重:论文中未提及公开模型权重链接。
数据集:论文中未提及公开合成数据集链接。
Demo:论文中未提及。
复现材料:论文提供了部分训练细节(基于SmolLM2-360M-Instruct,在L40 GPU上训练5个epoch,学习率1e-5,500步warmup,使用余弦学习率调度器,添加了
<|sil|>特殊token),但未提供完整的代码、数据集或模型检查点。论文中引用的开源项目:
- SmolLM2: https://huggingface.co/HuggingFaceTB/SmolLM2-360M-Instruct
- DeBERTaV3 (用于MNLI验证): https://huggingface.co/moritzlaurer/deberta-v3-base-mnli
- PersonaHub: https://github.com/THUDM/PersonaHub
- MNLI 数据集: https://cims.nyu.edu/~sbowman/multinli/
- Ollama (用于本地模型推理): https://github.com/ollama/ollama
- CANDOR 对话数据集: https://candor.uchicago.edu/
- NaturalQuestions 数据集: https://ai.google.com/research/NaturalQuestions
- Mini-Omni-Reasoner, Talker-Reasoner, SplitReason, Qwen2.5-Omni: 论文引用但未提供具体链接。
补充链接(自动提取):
- 代码仓库:https://github.com/vysri/conversational-infill
🏗️ 方法概述和架构
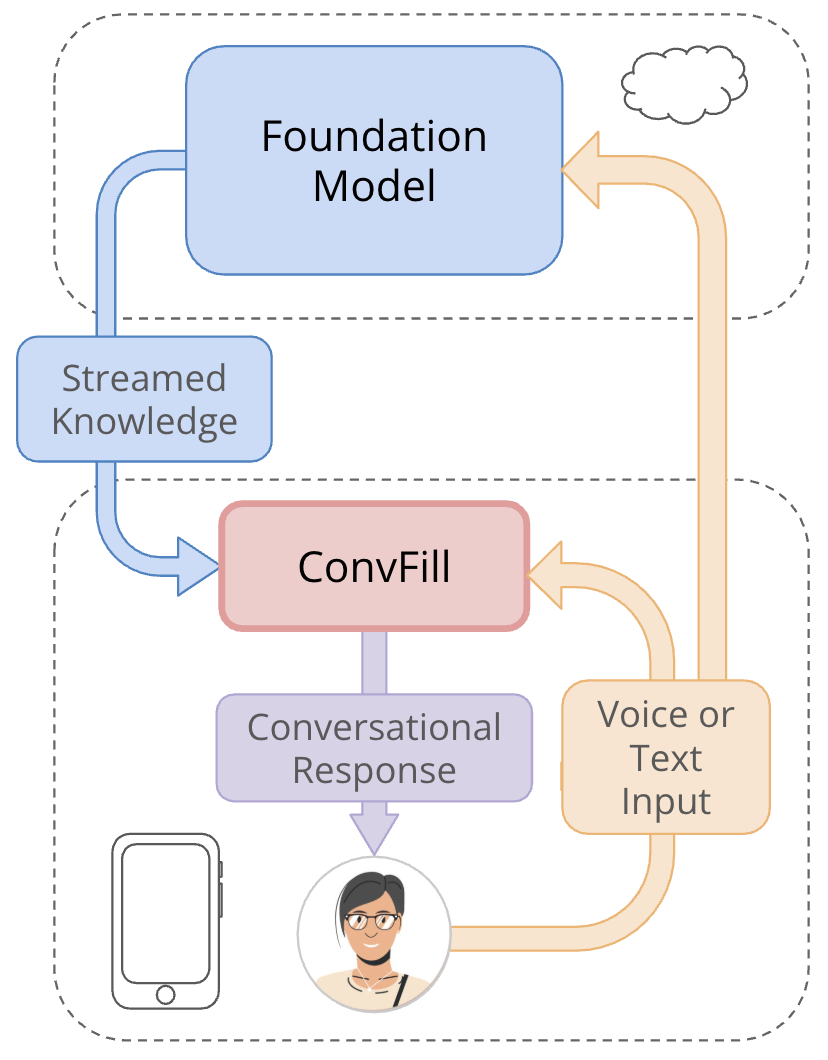
本文提出的核心架构是基于“模型协作”的混合推理系统,其关键组件与流程如下:
任务定义与系统角色:
- 对话填充任务:定义为一个小型端侧模型在生成自然对话的同时,以流式方式接收并整合来自大型后端模型的知识块,以增强其响应。该任务的核心是将知识整合与对话生成解耦,并利用时间差来隐藏后端模型的高延迟。
- 端侧模型(ConvFill):作为对话前端,直接与用户交互。它仅接收当前轮次的用户输入以及按时间顺序到达的外部知识块(或静默标记)。其职责是快速(低延迟)生成连贯的对话短语。
- 后端模型:作为知识源,接收整个对话历史。它异步地生成与问题相关的知识块(以简洁短语形式),并通过一个共享队列以流的方式发送给端侧模型。论文中主要使用Gemini 2.5 Pro作为后端。
ConvFill模型架构与训练:
- 基座模型:采用
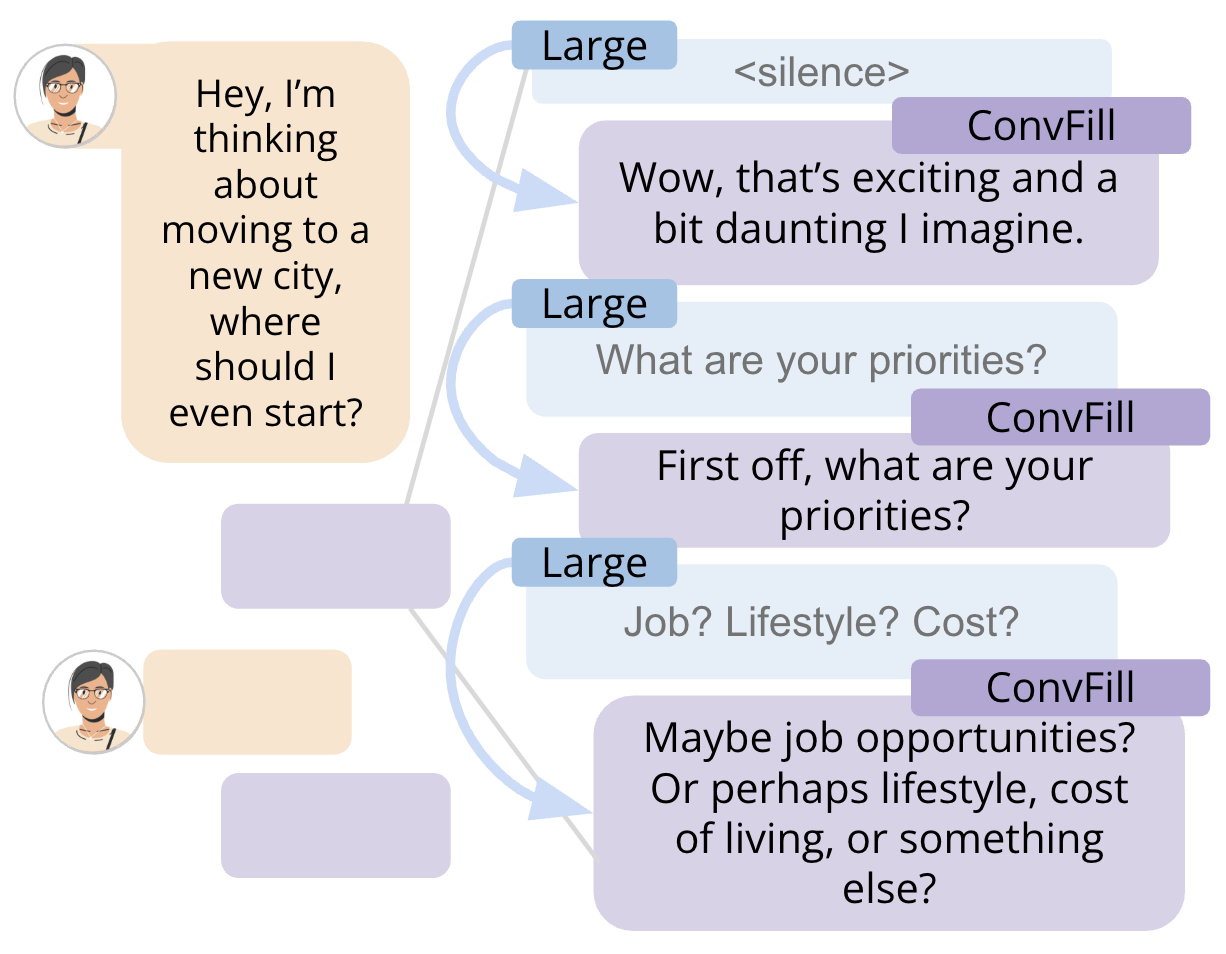
SmolLM2-360M-Instruct作为基础,因其参数量小、推理速度快,适合端侧部署。 - 输入格式与特殊标记:在微调时,引入了新的角色标签
knowledge用于标记来自后端模型的知识块。对于知识流中的静默间隔,引入特殊令牌<|sil|>。模型输入由当前轮次的用户话语、以及本该轮内已收到的外部知识块序列和已生成的对话短语序列交织构成(如图2所示)。训练目标是预测当前轮次的最后一个对话短语。 - 训练数据生成:
- 使用
GPT-4o生成涵盖建议、助手、教育、活动规划、客服、医疗六个领域的合成对话(每个领域1000个对话),对话长度为8-12轮。 - 每个对话样本包含
user(用户话轮)、responder(模型应生成的独立句子列表)和responder_thoughts(与responder对应的、代表后端知识或静默的列表)。 - 为确保生成的“知识块”与对应的“对话短语”在语义上一致,使用在MNLI数据集上微调过的
DeBERTaV3模型来验证知识块是否蕴含对话短语,从而过滤掉语义不匹配的样本。
- 使用
- 训练细节:在单个L40 GPU上训练5个epoch,使用余弦学习率调度器,初始学习率为 \(1e-5\),500步预热。训练数据共包含5997个对话,衍生出46151个“用户-填充轮次”。
- 基座模型:采用
推理流水线:
- 系统采用双线程并行:一个线程运行ConvFill,另一个线程运行后端大模型,两者共享一个流式知识队列。
- 当用户输入到达时,查询同时被发送给ConvFill和后端模型。
- 后端模型将用户输入追加到对话历史后开始生成回答。
- 在ConvFill侧,系统会以固定间隔(论文中设为 \(d=1\) 秒)检查知识队列。如果队列为空,则向ConvFill输入
<|sil|>令牌;如果存在知识块,则将其输入。ConvFill根据最新的输入(用户话、知识块或静默标记)以及本该轮内已生成的短语历史,流式地生成下一个对话短语。 - 该过程持续进行,直到ConvFill生成一个完整的回答或达到轮次结束。
形式化定义:
- 设时间 \(i\) 时,端侧模型接收的外部输入序列为 \((e_1, \cdots, e_i)\),其中每个 \(e_i\) 要么是知识块 \(l_i \in L\),要么是静默标记 \(s_i \in S\)。
- 端侧模型基于此序列及自身已生成的短语序列 \((c_1, \cdots, c_{i-1})\),生成短语 \(c_i\)。
- 关键约束是:\(len(S) + len(L) = len(C) = n\),即静默次数与知识块数之和等于生成的短语总数。
- 任务要求 \(e_i \rightarrow c_i\),即若 \(e_i\) 是知识块,则生成的 \(c_i\) 应仅作为对应该知识块的智能填充,不能引入额外信息。若 \(e_i\) 是静默标记,则 \(c_i\) 为独立生成的对话填充词。

💡 核心创新点
- 提出新任务:正式定义了“对话填充”任务,为在资源受限的端侧设备上实现实时、智能的语音交互提供了一个明确的问题框架。
- 解耦设计范式:将响应延迟(由轻量级端侧模型保证)与模型能力(由强大的云端后端模型提供)进行了解耦,提出了“端侧即时响应 + 后端异步知识提供”的协作范式。
- 流式知识整合机制:设计了端侧模型以流式方式接收并动态整合后端知识块的推理框架,有效隐藏了后端模型的高延迟。
📊 实验结果
论文在三个维度评估了ConvFill系统:
- 首字延迟(TTFT) ConvFill系统在所有后端配置下均实现了亚200毫秒的首字延迟,与独立的小模型相当,远低于单独的后端大模型。
| 模型 | 参数量 | TTFT ± 标准差 (s) |
|---|---|---|
| GPT-5 | N/A | 0.74 ± 3.04 |
| ConvFill + GPT-5 | 360M | 0.16 ± 0.04 |
| Claude Sonnet 4.5 | N/A | 2.16 ± 0.99 |
| ConvFill + Claude 4.5 | 360M | 0.17 ± 0.04 |
| Gemini-2.5-Pro | N/A | 10.9 ± 2.74 |
| ConvFill + Gemini | 360M | 0.17 ± 0.04 |
| SmolLM2-360M (Base) | 360M | 0.16 ± 0.04 |
| SmolLM2-1.7B | 1.7B | 0.17 ± 0.18 |
| Qwen3-0.6B | 600M | 0.15 ± 0.05 |
| Qwen1.7B | 1.7B | 0.20 ± 0.24 |
| Llama3.2-1B | 1B | 0.18 ± 0.13 |
| Gemma3-270M | 270M | 0.14 ± 0.07 |
| Gemma3-1B | 1B | 0.22 ± 0.08 |
- 问答准确率(QA Accuracy) 在NaturalQuestions数据集(250个样本)上,ConvFill系统显著提升了基座小模型的准确率,但仍与后端大模型有较大差距。
| 模型 | NQ 准确率 |
|---|---|
| GPT-5 | 0.78 |
| ConvFill + GPT-5 | 0.46 |
| Claude Sonnet 4.5 | 0.80 |
| ConvFill + Claude 4.5 | 0.52 |
| Gemini-2.5-Pro | 0.69 |
| ConvFill + Gemini | 0.49 |
| SmolLM2-360M (Base) | 0.10 |
| SmolLM2-1.7B | 0.26 |
| Qwen3-0.6B | 0.12 |
| Qwen1.7B | 0.28 |
| Llama3.2-1B | 0.34 |
| Gemma3-270M | 0.06 |
| Gemma3-1B | 0.19 |
- 轮级文本蕴含(Turn-Level Entailment) 使用DeBERTaV3-MNLI评估ConvFill生成的短语相对于后端模型知识块的蕴含关系。结果显示,完全蕴含(E)的比例较低,矛盾(C)的比例也较低,但中立(N)的比例非常高。
| 后端模型 | 样本对数 | E (%) | N (%) | C (%) |
|---|---|---|---|---|
| GPT-5 | 414 | 34.1 | 59.9 | 6.0 |
| Claude Sonnet 4.5 | 495 | 28.1 | 64.2 | 7.7 |
| Gemini-2.5-Pro | 245 | 35.5 | 59.2 | 5.3 |
论文指出,高“中立”率部分源于ConvFill在对话中加入的自然修饰语(如评价性形容词),这些修饰在严格逻辑蕴含下不属于“蕴含”,但在对话场景下可能被接受。矛盾率低表明系统能较好地避免引入明显错误信息。
⚖️ 评分理由
- 创新性 (1.5/2):提出了“对话填充”这一新任务,定义清晰,其解耦延迟与能力的思想在端云协同领域具有启发性。方法组合(微调小模型整合流式知识)有一定新意,但并非革命性突破。
- 技术严谨性 (1.2/1.5):任务形式化定义严谨。训练数据生成中使用NLI模型进行过滤是合理的设计。然而,对“中立”蕴含结果的讨论略显辩护性,未能提出更根本的解决方案或更深入的分析。系统依赖特定后端模型以“短语”形式输出知识,这一假设在通用性上可能存在限制。
- 实验充分性 (1.0/2):评估维度(延迟、准确率、蕴含)设计合理。但存在显著局限:评估数据集(NaturalQuestions子集,250个问题)规模偏小;缺乏在真实语音交互场景或多人对话中的评估;缺乏对不同知识块粒度、传输间隔(\(d\))等关键系统参数的消融研究。无法全面评估方法的鲁棒性和泛化能力。
- 清晰度 (1.5/2):论文结构清晰,问题定义、方法描述和实验设置阐述得较为清楚。图表(如图1, 2, 3)有效辅助了理解。部分形式化符号(如 \(a \rightarrow b\))的引入略显突兀,但整体可读性良好。
- 影响力 (0.5/1.5):对语音交互领域解决延迟-能力权衡问题提供了有价值的思路。然而,其核心贡献(模型协作与流式知识整合)具有较强领域通用性,并非语音领域独有。对于专注于语音信号处理、语音合成等方向的读者,直接可借鉴的价值有限。
- 开源 (0/1.5):论文明确表示代码“will be released at a later time”,模型权重和数据集也未提供公开链接。在审稿时,可视为完全未开源,严重影响可复现性和社区贡献。
- 可复现性 (0.5/1.5):由于未开源,可复现性完全依赖论文描述的训练细节(基座模型、超参数、数据生成方法)。虽然描述了一定细节,但缺失完整的数据集、代码和模型权重,使得完全复现实验几乎不可能,只能进行非常粗略的复现。
- 工程/实践价值 (1.0/1.5):该架构为构建低延迟、高智能的语音助手提供了一个可行的工程蓝图。其模块化设计允许灵活更换后端大模型。但当前验证停留在文本层面,未涉及完整的“语音输入-文本处理-语音输出” pipeline,其在真实语音系统中的集成效果和额外开销(如ASR/TTS延迟)未被评估。
🚨 局限与问题
- 评估局限性:实验仅在文本问答数据集(NaturalQuestions)上进行,缺乏对对话管理、多轮上下文跟踪等能力的评估,也未涉及真实的语音交互场景。250个样本的测试集规模较小,可能影响结论的统计显著性。
- 知识保真度问题:轮级蕴含分析中高达60%的“中立”率是一个严重的警示信号。虽然作者将其解释为“可接受的对话润色”,但这恰恰表明系统在整合流式知识时存在普遍的语义漂移。如何量化评估这种“润色”是否损害了事实准确性或改变了关键语义,是未解决的难题。当前的NLI评估框架对此区分力不足。
- 系统依赖与假设:系统性能高度依赖后端模型以“简洁短语”形式输出知识块。然而,主流LLM的默认输出格式是连贯长文。虽然论文提到通过提示工程引导模型简洁输出,但这引入了额外的不稳定性,且可能损害后端模型本身的推理质量。论文未探讨不同知识粒度(句子 vs. 段落 vs. 关键词)对系统性能的影响。
- 端侧模型能力天花板:360M的端侧模型容量有限,即使接入流式知识,其将知识转化为流畅、准确自然语言的能力(即“整合”与“表达”能力)存在明显上限。这解释了为何其准确率无法逼近后端模型。论文未探讨使用更大或更专业的端侧模型(如经过知识蒸馏的模型)是否能缩小这一差距。
- 缺乏用户研究:论文声称该方法能提升用户体验(“feel responsive”),但并未提供任何主观用户研究数据(如感知延迟、回答有用性、自然度评分)来支撑这一说法。系统在真实交互中的效果仍是未解之谜。
- 与语音系统的集成空白:作为一篇关于“语音智能体”的论文,其整个框架和实验完全建立在文本层面。未讨论如何与自动语音识别(ASR)和文本到语音(TTS)模块集成,也未分析ASR和TTS引入的额外延迟会如何影响整体的“响应性”体验。这使得工作的实际适用性打了折扣。