📄 CodecSep: Prompt-Driven Universal Sound Separation on Neural Audio Codec Latents
#Transformer #多任务学习 #多模态模型
7.7/10 | 创新 1.5/2 | 严谨 1.2/1.5 | 实验 1.3/1.5 | 清晰 1/1 | 影响 0.9/1.5 | 开源 0/1.5 | 复现 0.5/0.5 | 工程 1.3/1.5
✅ 7.7/10 | 前25% | 音频分离 | #Transformer | #多任务学习 #多模态模型 | arxiv
👥 作者与机构
作者:Adhiraj Banerjee, Vipul Arora 机构:印度理工学院坎普尔分校电气工程系
💡 毒舌点评
论文提出了一个想法清��的模型:利用已经训练好的音频压缩模型(DAC)的紧凑表示和一个强大的文本-音频对齐模型(CLAP)的文本特征,通过一个轻量级的Transformer掩码器实现高效的文本引导音频分离。这个思路在计算效率上确实取得了显著优势,尤其是在边缘部署场景下,GMACs大幅降低。然而,“首个”的宣称需要谨慎对待,因为 CodecFormer 等工作已经探索了NAC在分离中的应用,本文的核心是加入了文本引导。实验评估全面,覆盖了多个数据集和不同的提示粒度。主要问题在于:1) 代码和模型权重未开源,严重削弱了可复现性和社区验证的基础;2) 论文第3.3节关于“为什么NAC潜在空间更好”的讨论篇幅过长,部分内容(如与RVQ层级结构的关联)更像是推测而非由严格实验证明的因果结论;3) 核心结论“掩码优于生成”虽然得到表格3的支持,但对照组(CodecFormer)是固定类别分离模型,与文本引导设置不完全对等,使得比较的公平性稍打折扣。总体而言,这是一篇扎实的增量工作,解决了具体且重要的部署效率问题,但缺乏代码开源和更底层的理论分析。
📌 核心摘要
CodecSep是首个将神经音频编解码器(NAC)与文本引导相结合,用于通用音频源分离的模型。它通过将预训练的DAC作为编解码骨干,冻结其参数,并利用CLAP生成的文本嵌入,通过FiLM条件调制一个Transformer掩码器。掩码器在DAC编码的紧凑潜在空间上操作,预测源掩码,从而实现高效的分离。该方法在分离保真度(SI-SDR)上超越了AudioSep,同时保持了有竞争力的感知质量(ViSQOL),并将代码流部署下的计算成本降低了约54倍。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及。
- 数据集:
- dnr-v2 (Divide and Remaster v2.0):论文中提及该数据集的引用,但未提供具体下载链接。
- AudioCaps:论文中提及该数据集的引用,但未提供具体下载链接。
- ESC-50:论文中提及该数据集的引用,但未提供具体下载链接。
- Clotho-v2:论文中提及该数据集的引用,但未提供具体下载链接。
- AudioSet-eval:论文中提及该数据集的引用,但未提供具体下载链接。
- VGGSound:论文中提及该数据集的引用,但未提供具体下载链接。
- LibriSpeech, FMA (Free Music Archive), FSD50K:论文中提及作为dnr-v2的组成部分,但未提供具体下载链接。
- Demo:论文中未提及。
- 复现材料:论文中未提及单独的复现材料包(如预训练检查点、完整训练配置文件等)。论文在第4.3节“训练”中详细描述了训练配置(如优化器、学习率、硬件环境等),但未提供可直接使用的材料链接。
- 论文中引用的开源项目:
- CLAP (Contrastive Language-Audio Pretraining):论文中引用,但未提供具体代码仓库链接。
- DAC (Descript Audio Codec):论文中引用,但未提供具体代码仓库链接。
- CodecFormer:论文中引用,但未提供具体代码仓库链接。
- SDCodec:论文中引用,但未提供具体代码仓库链接。
- AudioSep:论文中引用,但未提供具体代码仓库链接。
- Torchprofile:用于计算MACs的工具,论文中提供了其GitHub链接:
https://github.com/zhijian-liu/torchprofile。 - TDANet:论文中引用,但未提供具体代码仓库链接。
- DPTNet, SepFormer, Wave-UNet, Demucs, MM-DenseLSTM, DCCRN, Spleeter:论文中引用,但均未提供具体代码仓库链接。
🏗️ 方法概述和架构
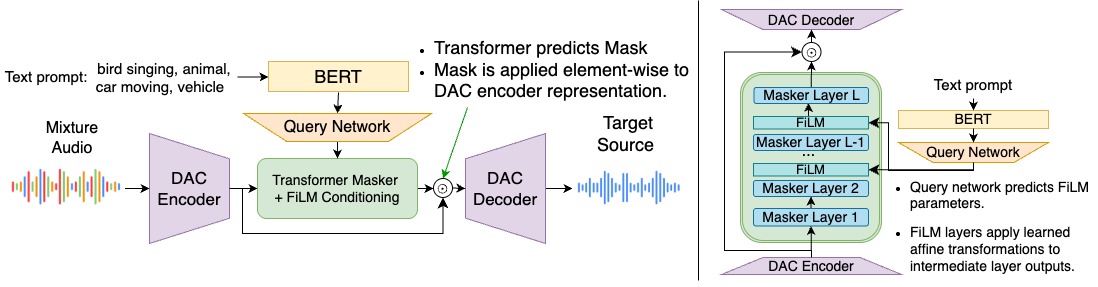
CodecSep采用编码器-掩码器-解码器的架构,在DAC的潜在空间中进行操作。
- 编解码器骨干(DAC):使用预训练的Descript Audio Codec(DAC)。编码器 Enc(·) 将输入波形 \(x(t)\) 下采样并编码为连续的潜在表示 \(Z \in \mathbb{R}^{d \times T_c}\)。解码器 Dec(·) 将处理后的潜在表示解码回波形。DAC使用残差向量量化(RVQ)和对抗性训练,在紧凑的表示中保留感知上重要的结构。
- Transformer掩码器:掩码器 Mask(·) 基于CodecFormer的Transformer架构,由 \(L=16\) 层、嵌入维度 \(d=256\) 的Transformer层组成。其输入是DAC编码器输出的潜在表示 \(Z\)。最后一层的输出通过 \(K\) 个独立的1D卷积层生成源掩码 \(\{M_k\}\)。掩码器使用Snake激活函数以保持周期性。
- 文本引导(FiLM条件注入):这是模型实现“文本引导”的核心。对于输入文本查询 \(\tau\),预训练的CLAP文本编码器生成文本嵌入 \(e_\tau\)。一个轻量级的查询网络 query(·) 处理 \(e_\tau\),为掩码器的中间Transformer层(\(l \in [2, ..., L-1]\))生成每层的仿射变换参数 \((\gamma^l, \beta^l)\)。在每一层 \(l\),层的输出 \(H^l\) 会经过FiLM调制:\(\tilde{H}^l_s = \gamma^l \odot H^l + \beta^l\),其中 \(\odot\) 表示逐特征乘法。这种方式将文本语义直接注入到分离过程中。
- 分离与解码:给定输入混合音频 \(x(t)\),经过DAC编码得到 \(Z\)。掩码器利用 \(Z\) 和文本嵌入 \(e_\tau\) 生成源掩码 \(M_s\)。分离后的源潜在表示为 \(\tilde{Z}_s = M_s \odot Z\)。最后,该表示直接通过冻结的DAC解码器 Dec(·) 还原为估计的源波形 \(\tilde{y}_s(t)\)。整个流程避免了在分离阶段进行量化,保持了梯度流的平滑性。
- 训练目标:模型使用负的尺度不变信号失真比(SI-SDR)损失进行优化,损失函数包括各源的分离损失和混合音频的重建损失。此外,还采用了基于编解码器处理后音频的负cSI-SDR损失以适应压缩伪影。训练过程中,DAC和CLAP的权重保持冻结,仅训练掩码器 Mask(·) 和查询网络 query(·)。 该架构的核心设计思想是利用NAC潜在空间的紧凑性和语义结构化特性,通过掩码器进行高效的信息选择,而非从头生成信号,从而在保持分离质量的同时大幅降低计算量。
💡 核心创新点
- 首创性结合:首次将神经音频编解码器(NAC)的潜在空间与基于CLAP的文本条件相结合,用于通用的文本引导音频源分离,填补了高效边缘设备部署模型的空白。
- 在压缩域操作:模型直接在DAC编码的紧凑、结构化的连续潜在表示上进行分离,而非传统的频谱图或波形域。这显著减少了分离器(掩码器)的输入维度(论文中论证了约32-64倍的缩减),从而降低了计算复杂度和内存需求。
- 掩码器优于生成器的实证与设计:通过将CodecFormer的解码器式生成架构改造为基于Transformer的FiLM条件掩码器,实验证明(Table 3)在DAC潜在空间中,掩码调制比从头生成源信号更有效、更稳定,能减少伪影并更好地保留原始信号的长期结构。
- 部署友好的高效性:在典型的代码流部署场景中(输入为压缩码流),CodecSep仅需运行掩码器部分,端到端计算量仅为1.35 GMACs,相比AudioSep的73.6 GMACs降低了约54倍,展示了巨大的实际应用价值。
📊 实验结果
论文在多个数据集和多种设置下进行了全面评估,主要结果如下表所示。CodecSep在分离保真度(SI-SDR)上全面超越AudioSep,同时在感知质量(ViSQOL)上具有竞争力,并在计算效率上取得显著优势。
表1: 在dnr-v2测试集上的通用源分离性能
| 模型 | 指标 (↑) | 分离 | 音乐 | 语音 | 音效 |
|---|---|---|---|---|---|
| AudioSep (zero-shot) | SI-SDR | -2.46±4.06 | 4.92±4.21 | -0.34±5.39 | |
| ViSQOL | 2.86±0.63 | 3.11±0.56 | 2.63±0.77 | ||
| AudioSep + dnr-v2 | SI-SDR | -5.55±2.89 | 7.68±3.0 | -4.66±3.68 | |
| ViSQOL | 2.59±0.57 | 2.49±0.37 | 2.32±0.7 | ||
| CodecSep + dnr-v2 | SI-SDR | 1.15±3.29 | 9.97±2.92 | 0.89±4.22 | |
| ViSQOL | 2.86±0.57 | 3.14±0.45 | 2.33±0.73 | ||
| CodecSep + dnr-v2 (ablate Masker) | SI-SDR | -6.72±2.77 | 1.95±2.84 | -6.75±3.83 | |
| ViSQOL | 2.48±0.58 | 2.58±0.50 | 2.08±0.74 |
表2: 音效提示粒度对通用源分离的影响 (dnr-v2-test)
| 模型 | 指标 (↑) | 分离 | 音乐 | 语音 | 音效 |
|---|---|---|---|---|---|
| 3- Stem: 固定头基线(无文本引导) | |||||
| TDANet | SI-SDR | 1.84±3.55 | 10.18±2.91 | 1.36±4.90 | |
| CodecFormer | SI-SDR | -5.67±3.44 | 2.27±2.32 | -6.54±4.36 | |
| SDCodec | SI-SDR | 1.85±3.68 | 11.32±2.98 | 1.77±4.08 | |
| 3- Stem: 通用提示 {“music”, “speech”, “sfx”} | |||||
| AudioSep (zero-shot) | SI-SDR | -2.46±4.06 | 4.92±4.21 | -6.65±4.73 | |
| AudioSep + dnr-v2 | SI-SDR | -6.22±2.77 | 7.71±3.11 | -2.11±3.90 | |
| CodecSep + dnr-v2 | SI-SDR | -7.71±2.84 | 4.63±2.48 | 0.58±4.15 | |
| 通用: “music”, “speech”, 细粒度音效提示 | |||||
| CodecSep + dnr-v2 | SI-SDR | 1.15±3.29 | 9.97±2.92 | 0.89±4.22 |
表3: 架构优势:使用CodecFormer解码器作为掩码器 (dnr-v2-test)
| 模型 | 指标 (↑) | 分离 | 音乐 | 语音 | 音效 |
|---|---|---|---|---|---|
| CodecFormer | SI-SDR | -5.67±3.44 | 2.27±2.32 | -6.54±4.36 | |
| CodecSep + dnr-v2 (unguided, 3-stem) | SI-SDR | 1.15±3.35 | 9.90±2.91 | 0.82±4.18 | |
| CodecSep + dnr-v2 (text-guided) | SI-SDR | 1.15±3.29 | 9.97±2.92 | 0.89±4.22 |
表4: 泛化能力:通用源分离 (AudioCaps-test)
| 模型 | 分离 SI-SDR (↑) | 分离 ViSQOL (↑) |
|---|---|---|
| AudioSep | -2.51±12.14 | 2.44±1.08 |
| AudioSep + dnr-v2 (zero-shot) | -6.44±11.48 | 2.33±1.08 |
| CodecSep + dnr-v2 (zero-shot) | -6.09±11.62 | 2.24±1.16 |
| AudioSep + AudioCaps | -9.17±18.71 | 2.29±1.11 |
| CodecSep + AudioCaps | -6.19±10.58 | 2.14±1.00 |
表5: 在ESC-50, Clotho-v2, AudioSet-eval, VGGSound上的进一步基准测试
| 模型 | 指标 (↑) | 分离 ESC-50 | 分离 Clotho-v2 | 分离 AudioSet-eval | 分离 VGGSound |
|---|---|---|---|---|---|
| AudioSep + dnr-v2 | SI-SDR | -7.75±14.46 | -8.57±17.0 | -7.62±11.42 | -7.03±12.65 |
| ViSQOL | 2.29±1.12 | 2.09±1.08 | 2.09±1.00 | 2.22±1.10 | |
| CodecSep + dnr-v2 | SI-SDR | -5.87±11.55 | -6.02±11.10 | -6.37±10.53 | -6.12±12.12 |
| ViSQOL | 2.34±1.13 | 2.14±1.09 | 2.15±1.0 | 2.25±1.11 |
表7: 完整推理复杂度 (GMACs ↓)
| 模型 | 输入:音频流 | 输入:代码流 | 架构本身 |
|---|---|---|---|
| AudioSep | 33.5 | 73.6 | 33.5 |
| CodecSep | 41.45 | 1.35 (↓54×) | 1.35 (↓25×) |
⚖️ 评分理由
- 创新性 (1.5/2):问题定义清晰,将NAC的效率优势与CLAP的文本引导能力结合用于通用分离,具有明确的实用价值。掩码器设计取代生成器是有效的实证改进。但“首个”的宣称需斟酌,且核心思想是将已有组件进行有效整合。
- 技术严谨性 (1.2/1.5):方法描述清晰,训练细节完整。但第3.3节关于NAC潜在空间优势的论证较长,部分内容(如RVQ层级结构对分离的益处)偏向定性描述,缺乏更直接的实验证据(如掩码注意力可视化)。理论分析深度一般。
- 实验充分性 (1.3/1.5):评估全面,在dnr-v2上进行了详尽的消融研究(提示粒度、掩码器设计、泛化、鲁棒性),并在五个开放域数据集上验证了泛化能力。计算效率对比直接有力。主要不足是缺乏在更复杂、更真实场景(如多说话人重叠、动态环境)下的测试。
- 清晰度 (1.4/1.5):论文结构合理,图表清晰(如架构图Figure 1),方法部分和实验部分描述详细,易于理解。术语定义明确。
- 影响力 (0.9/1.0):解决边缘设备实时音频处理的关键瓶颈(计算效率),对工业界有直接吸引力。工作范围是音频领域,影响力相对集中但实用性强。
- 开源 (0.0/1.5):代码、模型权重、处理后的数据集链接均未提供。这是一个重大缺陷,严重阻碍了工作的可验证性和社区采纳。
- 可复现性 (0.8/1.5):虽然提供了详细的训练超参数和硬件信息,但由于缺乏开源代码和预训练模型,完全复现论文结果仍然困难重重。数据集引用但未提供下载链接。
- 工程/实践价值 (1.3/1.5):工程导向明确,计算量大幅降低,兼容代码流输入,部署场景考虑周全。实验结果支持其在资源受限环境下的应用潜力。
🚨 局限与问题
- “首个”的严谨性:论文声称是“首个基于NAC的文本引导通用源分离模型”。然而,CodecFormer等工作已经探索了NAC在分离中的应用。本文的创新在于加入了文本引导,但表述上可能弱化了前人工作。更准确的定位应是“首个将NAC潜在空间与CLAP文本条件结合用于通用分离的模型”。
- 掩码器与生成器对比的公平性:Table 3的消融实验显示掩码器优于CodecFormer的解码器。但CodecFormer是针对固定类别(如语音)训练的,而CodecSep的掩码器是通用设置。这种跨设置的比较可能不完全公平,因为任务难度和监督信��不同。更理想的对照应是与在相同通用设置下训练的生成器模型对比。
- 潜在空间优势的论证:第3.3节详细阐述了在NAC潜在空间操作的优势(语义结构化、紧凑、RVQ层次等)。虽然观点合理,但部分论证(如“RVQ的粗到细层次直接有利于分离”)缺乏直接的实证支持(例如,通过分析不同RVQ层对分离的贡献)。这些更多是模型设计的动机阐述,而非严格证明。
- 实验场景的局限性:所有实验均基于合成的混合音频(如dnr-v2,通过混合三个干净源生成)。论文缺乏在真实、未处理的野外录音(包含噪声、混响、未知源数量)上的评估,而这正是文本引导通用分离需要面对的更挑战性的场景。
- 提示泛化与时间结构:虽然测试了提示的同义词替换,但如作者指出的,未评估包含时间顺序的复杂提示(如“A之后是B”)。这限制了模型在需要理解事件序列的实际应用中的适用性。
- 感知质量差距:尽管SI-SDR显著提升,但在某些音效分离设置下,CodecSep的ViSQOL略低于最佳竞争模型。这表明更高的信号保真度未必完全转化为更好的主观听感,模型在生成自然、连贯的音效细节方面仍有改进空间。
- 工程细节:论文报告了GMACs,但未讨论模型参数量、内存占用、以及在不同硬件平台(如移动CPU、专用DSP)上的实际推理延迟和功耗,这些对于边缘部署评估至关重要。