📄 AVI-Edit: Audio-sync Video Instance Editing with Granularity-Aware Mask Refiner
#视频编辑 #扩散模型 #音频生成 #音视频
🔥 8.0/10 | 前25% | #视频编辑 | #扩散模型 | #音频生成 #音视频 | arxiv
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Haojie Zheng(北京大学软件与微电子学院,北京人工智能研究院)
- 通讯作者:Boxin Shi(北京大学计算机科学学院,多媒体信息处理国家重点实验室,国家视觉技术工程研究中心),Xinlong Wang(北京人工智能研究院)
- 作者列表:Haojie Zheng(北京大学软件与微电子学院,北京人工智能研究院),Shuchen Weng(北京人工智能研究院,北京大学计算机科学学院),Jingqi Liu(北京大学软件与微电子学院,北京人工智能研究院),Siqi Yang(北京大学人工智能研究院),Boxin Shi(北京大学计算机科学学院,多媒体信息处理国家重点实验室,国家视觉技术工程研究中心),Xinlong Wang(北京人工智能研究院)
💡 毒舌点评
这篇工作就像一位细心的“音频-视频外科医生”,不仅能精准切除或替换视频中的特定实例(如把狗变成猫),还能确保它的叫声也同步变化,这种对模态间精细时空对齐的执着在现有编辑工具中相当稀缺。然而,其“手术”目前一次只能处理一个“病人”(单实例),且整个“手术器械”(自反馈音频代理)依赖一个外部模型“工具箱”,这让人担心其在真实世界复杂场景下的自主性和鲁棒性。
📌 核心摘要
- 问题:现有视频编辑方法主要关注视觉层面,破坏了原始视频中至关重要的音频-视频同步,且缺乏实例级别的精细空间和时间控制。
- 方法核心:提出AVI-Edit框架,包含三个关键组件:基于Wan2.2的音频同步视频骨干网络(通过帧级交叉注意力融合音频信息)、粒度感知遮罩精炼器(GAMR,迭代式地将用户提供的粗糙遮罩精化为精确的实例轮廓)、自反馈音频代理(通过“分离-生成-重混-修正”的闭环流程,利用外部工具生成高质量的引导音频)。
- 创新点:a) 引入“精度因子”来量化和控制遮罩的粗糙程度,实现迭代式遮罩精化;b) 设计了自反馈音频代理,能够根据场景自适应选择分离和生成模型,并通过质量评判进行迭代优化;c) 构建了首个大规模、实例中心的音频-视频编辑数据集AVISet。
- 实验结果:在AVISet和AvED-Bench两个数据集上,AVI-Edit在视觉质量(FVD/IS)、条件遵循(TC/AC)和音视频同步(Sync-C/D)等定量指标上均优于现有方法(AvED, Ovi, VACE-Foley)。用户研究显示,在音视频同步、文本对齐和总体偏好方面,AVI-Edit均获得最高支持率(最高达49.20%)。
- 实际意义:为高质量的视频内容创作提供了新工具,允许用户在保留背景和非目标音频的前提下,对视频中的特定实例及其关联音频进行精准、同步的编辑,适用于影视后期、短视频创作等场景。
- 主要局限性:a) 目前仅支持单实例顺序编辑,无法同时处理多个目标实例;b) 框架的音频代理模块依赖一组预设的外部模型,其性能受限于这些外部组件的质量和泛化能力。
🔗 开源详情
代码:论文中未提及代码链接
模型权重:论文中未提及AVI-Edit模型权重的公开下载链接。该框架的视频骨干基于Wan2.2-5B初始化。
数据集:论文构建了AVISet数据集(71k训练,1k验证,1k测试),但论文中未提及开源下载链接。
Demo:https://hjzheng.net/projects/AVI-Edit/
复现材料:论文中未提及公开的训练配置、检查点等具体复现材料。论文描述了训练细节(8x NVIDIA A800 GPUs, 160k steps),并在补充材料中提供了更多应用和方法细节。
论文中引用的开源项目:
- Wan2.2 (视频生成基础模型):论文中未提及具体链接。
- PySceneDetect (视频分割):论文中未提及具体链接。
- RAFT (光流估计):论文中未提及具体链接。
- Audiobox-aesthetics (音频质量评估):论文中未提及具体链接。
- Qwen-Omni (多模态模型,用于音频分类和过滤):论文中未提及具体链接。
- TalkNet (说话人检测):论文中未提及具体链接。
- Scribe (语音片段识别):论文中未提及具体链接。
- Grounded-SAM-2 (实例分割):论文中未提及具体链接。
- Qwen-VL (视觉语言模型,用于文本标注):论文中未提及具体链接。
- CLIP (用于评估):论文中未提及具体链接。
- ImageBind (用于音频-视频一致性评估):论文中未提及具体链接。
- SyncNet (用于唇音同步评估):论文中未提及具体链接。
- ElevenLabs (文本到语音/音效生成服务):论文中未提及具体链接。
- AvED (对比方法):论文中未提及具体链接。
- Ovi (对比方法):论文中未提及具体链接。
- VACE (对比方法,用于基线实验):论文中未提及具体链接。
- Hunyuan-Foley (对比方法,用于基线实验):论文中未提及具体链接。
- MovieBench (数据源):论文中未提及具体链接。
- Condensed Movies (数据源):论文中未提及具体链接。
- Short-Films-20K (数据源):论文中未提及具体链接。
- VGGSound (数据源):论文中未提及具体链接。
补充链接(自动提取):
- 代码仓库:https://github.com/Breakthrough/PySceneDetect
- 代码仓库:https://github.com/christophschuhmann/improved-aesthetic-predictor
- 代码仓库:https://github.com/jiaaro/pydub
🏗️ 模型架构
AVI-Edit是一个多组件协同的框架,其整体架构如图2所示。用户输入包括一个粗糙的实例遮罩(mask)、文本描述(text)和原始视频/音频。
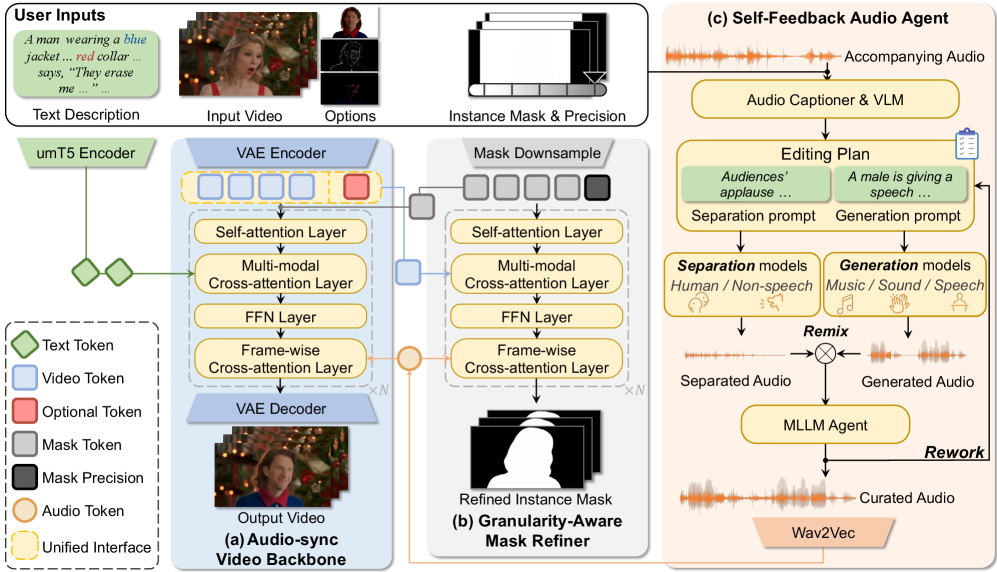
整体流程:
- 编码与初步生成:原始视频被VAE编码为潜变量
z。音频由自反馈音频代理处理,生成精炼的音频tokensa。用户提供的粗糙遮罩mask_p被送入粒度感知遮罩精炼器。 - 迭代精化与生成:在扩散模型的ODE求解过程中,粒度感知遮罩精炼器(图2b)与音频同步视频骨干网络(图2a)协同工作。在每个步骤
k:- GAMR接收上一步的遮罩
mask_p^(k-1)、精度因子p、视频tokens和音频tokensa,预测出本步精化后的遮罩mask_p^(k)。 - 视频骨干网络使用该精化遮罩
mask_p^(k)、噪声潜变量z_t、文本tokens和音频tokensa进行去噪预测,生成更清晰的视频潜变量。
- GAMR接收上一步的遮罩
- 输出:迭代完成后,经VAE解码得到编辑后的视频。同时,音频代理输出的音频作为最终的同步音频。
主要组件详解:
- 音频同步视频骨干网络:核心是修改后的视频扩散Transformer。它在标准的Transformer块(包含自注意力和文本交叉注意力)基础上,为每个块增加了帧级交叉注意力层,用于融合由音频代理提供的音频tokens
a。训练时使用流匹配目标(公式3)。 - 粒度感知遮罩精炼器(GAMR):其架构与视频骨干网络相似,但将文本交叉注意力替换为视频交叉注意力,以利用视觉语义。关键创新在于引入精度因子
p,它通过线性编码注入到每个Transformer块的自适应层归一化(AdaLN)和门控机制中(图7),以此调节模型对遮罩粗糙程度的理解。它使用遮罩精炼损失(公式6)进行训练。 - 自反馈音频代理:这是一个模块化的系统流程。它首先用音频描述模型理解原始音频,然后由多模态大模型(VLM)根据视频、遮罩和文本指令制定“分离”和“生成”的计划。接着,它从预定义的模型库(包括语音/非语音分离模型,以及文本到语音/音乐/音效生成模型)中选择合适模型执行,得到需要保留的音频成分
a_sep和新生成的音频成分a_gen,并将它们混合。混合音频由一个评判MLLM进行多维度质量评估,若未通过,则生成改进指令,驱动分离和生成模型进行修正,形成闭环迭代。
 图7详细展示了GAMR中精度因子p如何与时间步t结合,生成调制参数(γ, β, α),进而通过AdaLN和门控机制影响特征。
图7详细展示了GAMR中精度因子p如何与时间步t结合,生成调制参数(γ, β, α),进而通过AdaLN和门控机制影响特征。
💡 核心创新点
- 粒度感知遮罩精炼器(GAMR)与精度因子:这是实现精细空间控制的核心。不同于以往直接使用用户遮罩或仅进行简单掩码,GAMR引入了精度因子
p来显式建模遮罩的不确定性和粗糙程度。通过在扩散过程中迭代式地根据p精化遮罩,模型能自适应地从粗糙(如边框)输入中恢复出精确的实例轮廓,从而实现更准确的编辑区域定位,避免了对背景的意外修改。 - 自反馈音频代理:这是实现可靠时间控制和高质量音频生成的关键。它超越了简单的“文本生成音频”,设计了一个分离-生成-重混-修正(Separate-Generate-Remix-Rework) 的闭环流程。其创新在于:a) 利用大模型(VLM/MLLM)进行高层规划和质量评判,实现了流程的智能调度;b) 能够鲁棒地处理语音和非语音两类截然不同的场景;c) 通过反馈迭代,能自主优化生成的音频,确保其自然、真实且符合编辑意图。
- 构建大规模实例中心数据集AVISet:为训练和评估该任务,论文从多个来源收集并精心过滤、标注了71k训练、1k验证、1k测试的视频片段。每个片段都包含一个主要发声实例、其实例遮罩、场景文本描述,测试集还包括成对的编辑指令。这填补了该领域缺乏专用、高质量数据集的空白,是推动该方向研究的重要基础设施。
- 音频-视频同步的实例级编辑框架:将音频同步作为一等公民,并与实例级遮罩控制相结合,是整体框架层面的创新。它首次在统一框架内解决了“编辑特定对象同时保持/修改其声音”这一复杂需求,提供了从语音修改、外观改变到物体类别转换、动力学调整等多种应用可能性。
🔬 细节详述
- 训练数据:
- 数据集:AVISet,由作者构建。
- 来源:混合了MovieBench、Condensed Movies、Short-Films-20K、VGGSound等公开数据集以及部分YouTube视频。
- 规模:训练71k,验证1k,测试1k个片段,总计超过197小时,约10秒/片段,720P@24FPS。
- 预处理:使用PySceneDetect分镜头,RAFT过滤静态镜头,Audiobox-aesthetics和Qwen-Omni进行音频质量与内容过滤,TalkNet/Scribe处理语音片段,Grounded-SAM-2生成实例遮罩,Qwen-VL生成文本描述。
- 损失函数:
- 总损失:
ℒ = ℒ_fm + λ * ℒ_mask(公式9),其中λ=1.0。 - 流匹配损失(ℒ_fm):公式3,用于训练视频骨干网络预测速度场
v_t。 - 遮罩精炼损失(ℒ_mask):公式6,一种关注难例(边缘)的focal loss,用于训练GAMR。
- 总损失:
- 训练策略:
- 初始化:视频骨干网络和GAMR均从预训练的Wan2.2-5B权重初始化。
- 优化器:Adam,学习率
2×10⁻⁵。 - 训练硬件:8张NVIDIA A800 GPU。
- 训练步数:160k步。
- 分辨率:720p。
- VAE冻结:空间-时间VAE编码器/解码器在训练中被冻结。
- 关键超参数:
- GAMR训练中的focal loss超参:
α=0.25,γ=2.0。 - 遮罩精化的退化调度:对比了线性、常数、瞬时三种策略,瞬时退化(第一步使用初始
p,之后p设为1)效果最佳(Tab.5, IoU 76.23%)。 - 自反馈音频代理的质量评判阈值:
τ=7(满分10分)。
- GAMR训练中的focal loss超参:
- 推理细节:
- GAMR迭代精化:在ODE求解的每一步k,GAMR生成当前步骤的精化遮罩,供视频骨干网络使用。根据附录,采用“瞬时退化”策略。
- 音频代理效率:在200个测试样本上,平均每片段需要1.67次修正迭代,总处理时间约69.9秒(规划27.3秒,迭代循环42.6秒)。
- 正则化/稳定训练技巧:
- 使用预训练模型初始化是最大的稳定化技巧。
- 遮罩精炼使用Focal Loss缓解前景/背景不平衡问题。
- 论文未提及其他明确的正则化技巧(如dropout, weight decay等),推测沿用Wan2.2的默认设置。
📊 实验结果
论文在AVISet和AvED-Bench两个数据集上进行了全面评估。
表1:与当前最优方法的定量对比
| 方法 | AVISet | AvED-Bench | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FVD↓ | IS↑ | FC (%)↑ | TC (%)↑ | AC (%)↑ | Sync-C↑ | Sync-D↓ | FVD↓ | IS↑ | FC (%)↑ | TC (%)↑ | AC (%)↑ | |
| AvED | 362.06 | 1.108 | 94.81 | 23.82 | 23.21 | 1.67 | 11.85 | 422.41 | 1.114 | 94.77 | 24.68 | 20.38 |
| Ovi | 419.91 | 1.123 | 96.52 | 25.74 | 26.62 | 4.04 | 9.18 | 491.79 | 1.120 | 95.61 | 25.14 | 21.46 |
| VACE-Foley | 383.56 | 1.113 | 96.48 | 25.84 | 26.54 | 1.79 | 10.29 | 393.41 | 1.107 | 95.68 | 25.10 | 21.54 |
| AVI-Edit (Ours) | 299.19 | 1.125 | 96.72 | 26.09 | 26.90 | 4.15 | 9.21 | 337.00 | 1.124 | 95.76 | 25.22 | 21.57 |
关键结论:AVI-Edit在绝大多数指标上达到最优。在AVISet上,FVD(视觉质量)从基线最好的362.06大幅降低至299.19,Sync-C(同步性)从4.04提升至4.15。在AvED-Bench上同样显著优于其他方法。
表2:用户偏好研究结果(%)
| 方法 | AVISet | AvED-Bench | ||||
|---|---|---|---|---|---|---|
| AVS | TA | OP | AVS | TA | OP | |
| AvED | 2.40 | 3.20 | 1.60 | 3.60 | 4.80 | 4.00 |
| Ovi | 36.00 | 36.80 | 38.40 | 31.60 | 31.20 | 32.00 |
| VACE-Foley | 12.40 | 17.20 | 14.80 | 19.20 | 21.60 | 22.80 |
| AVI-Edit (Ours) | 49.20 | 42.80 | 45.20 | 45.60 | 42.40 | 41.20 |
关键结论:在人类评估的音视频同步(AVS)、文本对齐(TA)和总体偏好(OP)三个维度,AVI-Edit均获得最高投票率,表明其生成结果更符合人类感知。
表3:音频代理质量研究结果(%)
| 评级 | AF | RP | TAC |
|---|---|---|---|
| Perfect | 82.96 | 65.84 | 73.68 |
| Acceptable | 8.48 | 19.68 | 14.96 |
| Borderline | 6.32 | 9.12 | 7.60 |
| Failed | 2.24 | 5.36 | 3.76 |
关键结论:自反馈音频代理生成的音频质量很高,超过91%的音频在保真度(AF)上被评为“可接受”或“���美”。
消融研究(表4):
| 方法 | AVISet | AvED-Bench | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FVD↓ | IS↑ | FC (%)↑ | TC (%)↑ | AC (%)↑ | Sync-C↑ | Sync-D↓ | FVD↓ | IS↑ | FC (%)↑ | TC (%)↑ | AC (%)↑ | |
| w/o PF | 354.43 | 1.119 | 96.49 | 26.07 | 26.50 | 4.12 | 9.43 | 490.92 | 1.118 | 95.47 | 25.06 | 21.51 |
| w/o MR | 372.44 | 1.107 | 96.32 | 25.68 | 26.38 | 4.07 | 9.36 | 539.83 | 1.103 | 95.29 | 24.96 | 21.45 |
| w/o AA | 342.75 | 1.114 | 96.54 | 25.84 | 25.97 | 3.83 | 9.61 | 445.56 | 1.105 | 95.36 | 25.13 | 21.22 |
| AVI-Edit | 335.32 | 1.121 | 96.63 | 26.13 | 26.77 | 4.18 | 9.27 | 402.74 | 1.122 | 95.58 | 25.17 | 21.63 |
关键结论:移除任何核心组件(精度因子PF,遮罩精炼器MR,音频代理AA)都会导致性能下降,尤其是移除MR对视觉质量和一致性影响最大(FVD在AvED-Bench上从402.74飙升至539.83),验证了各组件的必要性。
定性对比(图3):展示了与AvED、Ovi和VACE-Foley的对比结果。AvED存在时序抖动,Ovi视觉不一致,VACE-Foley语音合成失败。而AVI-Edit生成的视频视觉上更连贯,编辑更准确,且音频与动作同步。
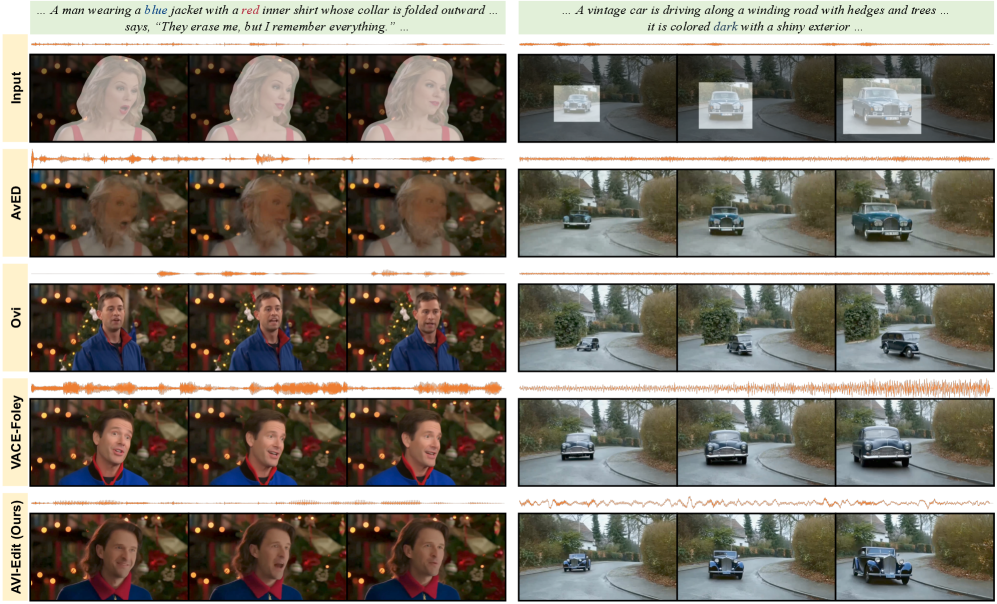
消融研究可视化(图4):直观展示了移除PF、MR和AA对编辑结果的影响。移除MR导致背景被意外修改;移除AA导致音画不同步。

⚖️ 评分理由
学术质量:6.5/7
- 创新性:提出GAMR和自反馈音频代理是显著的架构创新,有效解决了实例级遮罩精化和鲁棒音频生成两大难点。构建专用数据集AVISet是重要贡献。
- 技术正确性:方法设计合理,基于成熟的扩散模型和流匹配框架进行扩展。各模块间的协同工作逻辑清晰。
- 实验充分性:实验设计全面,包括定量对比、消融研究、用户研究、音频质量研究,覆盖多个数据集和评估维度。
- 证据可信度:定量结果有明显提升,消融实验证据链完整,定性结果具有说服力,用户研究结果一致。扣分点在于音频代理高度依赖外部模型库,其长期可用性和性能稳定性是一个潜在风险,论文对此讨论不足。
选题价值:1.5/2
- 前沿性:音频-视频同步编辑是视频生成领域一个新兴但至关重要的方向,论文直接针对其核心挑战。
- 潜在影响与应用空间:为专业视频编辑、短视频创作、虚拟人交互等提供了新的可能性,市场应用潜力较大。
- 读者相关性:对于从事多模态生成、视频理解与编辑的读者,此工作提供了直接的技术参考。对于专注于语音或纯音频研究的读者,其音频代理部分(尤其是非语音处理)也具有借鉴意义。扣0.5分是因为任务垂直,受众面相对通用基础模型较窄。
开源与复现加成:0.0/1
- 论文提供了项目主页,但未提及代码开源、模型权重发布或详细的复现脚本。附录中的训练细节虽详尽,但无法替代可直接运行的代码,因此复现门槛依然较高。加成取中性值0.0。