📄 XModBench: Benchmarking Cross-Modal Capabilities and Consistency in Omni-Language Models
#基准测试 #多模态模型 #音频问答 #跨模态 #模型评估
✅ 7.5/10 | 前25% | #基准测试 | #多模态模型 | #音频问答 #跨模态
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.7 | 置信度 高
👥 作者与机构
- 第一作者:Xingrui Wang (1. Advanced Micro Devices, 2. Johns Hopkins University)
- 通讯作者:Jiang Liu (Advanced Micro Devices)
- 作者列表:Xingrui Wang (Advanced Micro Devices, Johns Hopkins University), Jiang Liu (Advanced Micro Devices), Chao Huang (Advanced Micro Devices, University of Rochester), Xiaodong Yu (Advanced Micro Devices), Ze Wang (Advanced Micro Devices), Ximeng Sun (Advanced Micro Devices), Jialian Wu (Advanced Micro Devices), Alan Yuille (Johns Hopkins University), Emad Barsoum (Advanced Micro Devices), Zicheng Liu (Advanced Micro Devices)
💡 毒舌点评
亮点: 基准设计极其系统且具有诊断性,通过“模态平衡”的六种排列组合,像精密仪器一样能测量出模型对不同模态的“偏科”程度,这是超越简单平均分的深度评测。 短板: 论文将最强的闭源模型(Gemini)作为标杆,但自身并未提出新的模型或算法,因此更像一份详尽的“体检报告”而非“治疗方案”;同时,尽管承诺开源,但评测完全依赖现有模型,缺乏对新模型训练的直接指导细节。
🔗 开源详情
- 代码:论文中提供了代码仓库链接(https://github.com/XingruiWang/XModBench),承诺将开源评估工具。
- 模型权重:未提及。评测使用的是现有公开模型或闭源API模型。
- 数据集:承诺将开源数据集,论文中提供了“Dataset Card”链接(在图1中)。
- Demo:未提及。
- 复现材料:论文中提到了附录中包含人类评估细节、数据处理流程等,但未提供详细的超参数或完整训练/评测脚本。
- 论文中引用的开源项目:在数据构建和评测中引用了多个开源项目,如FireRedTTS(语音合成)、VGG-Sound(音频-视觉数据集)、STARSS23(空间音频数据集)、RenderedText(文本图像渲染)等。
📌 核心摘要
- 要解决什么问题:现有评测主要关注多模态问答的综合性能,但忽略了模型是否在不同模态输入(音频、图像、文本)下能保持答案的一致性,即是否具备真正的“模态不变推理”能力。
- 方法核心是什么:提出XModBench基准。其核心设计是将一个语义相同的问题,通过系统性地交换“上下文”和“选项”的模态(共6种组合),生成多组测试项。通过对比模型在不同模态配置下的表现,诊断其模态偏好、不平衡和一致性。
- 与已有方法相比新在哪里:XModBench是首个系统性覆盖音频、视觉、文本三模态间所有6种映射关系的基准。它引入了“模态差异”和“方向不平衡”两个量化指标,专门用于诊断跨模态对齐的缺陷。
- 主要实验结果如何:评估了12个模型。最强模型Gemini 2.5 Pro平均准确率为70.6%,但在空间推理(50.1%)和时间推理(60.8%)上表现最差。音频模态是普遍短板,当涉及音频时性能显著下降(模态差异ΔT vs. A达-49)。模型在将文本作为输出选项(如V→T)时表现优于输入(如T→V),显示存在方向不平衡。具体结果见下表。
| 模型 | 平均准确率 | 感知 | 空间推理 | 时间推理 | 语言理解 | 外部知识 | 标准差 |
|---|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | 70.6 | 75.9 | 50.1 | 60.8 | 76.8 | 89.3 | 11.7 |
| Qwen2.5-Omni | 58.6 | 75.5 | 38.4 | 32.3 | 74.1 | 72.8 | 10.1 |
| EchoInk-R1 | 59.2 | 75.8 | 36.6 | 37.1 | 73.3 | 73.3 | 11.3 |
| Human | 91.5 | 91.0 | 89.7 | 88.9 | 93.9 | 93.9 | 3.0 |
图4展示了不同模型在模态对(文本vs视觉, 文本vs音频, 视觉vs音频)之间的模态差异分数。负值越大,表明两个模态间表现差距越大,其中文本与音频的差距最为显著。
图5展示了模型在互逆模态配置(如文本→视觉 vs 视觉→文本)上的准确率差值。柱状图显示,多数模型在涉及文本的配对上存在明显的不对称性。
- 实际意义是什么:为评估和改进全模态大模型提供了一个基础性的诊断工具。揭示了当前模型普遍存在的音频处理短板、空间时间推理弱项以及模态间不对齐问题,为未来的模型训练(如使用更多交织数据)和数据收集指明了方向。
- 主要局限性是什么:基准评估高度依赖闭源模型,部分模型(如GPT系列)因API限制无法参与。基准构建依赖于已有数据集和合成数据,其覆盖范围和问题设计的多样性仍有扩展空间。
🏗️ 模型架构
本文提出的是一个评测基准(Benchmark),而非一个用于训练的神经网络模型。因此,其“架构”指的是基准本身的设计框架。
- 完整输入输出流程:输入是一个“模态平衡”的多项选择题。一个问题实例由一对语义绑定的
<上下文>和<候选答案>组成。通过将<上下文>和<候选答案>分别从音频(A)、视觉(V)、文本(T)中选择并组合,生成6种模态配置(A→T, A→V, T→A, T→V, V→A, V→T)。输出是模型从四个选项中选择的答案。 - 组件与数据流:该框架不涉及神经网络组件。其核心是问题生成与组织逻辑(如图1所示)。首先,从对齐的文本-图像-音频三元组出发,构建一个基础问题。然后,系统地通过模态置换,为同一个基础问题生成6个实例,分别用于评估不同方向的模态转换。最后,这6个实例与任务分类(感知、空间、时间、语言、知识)结合,构成完整的评测集。
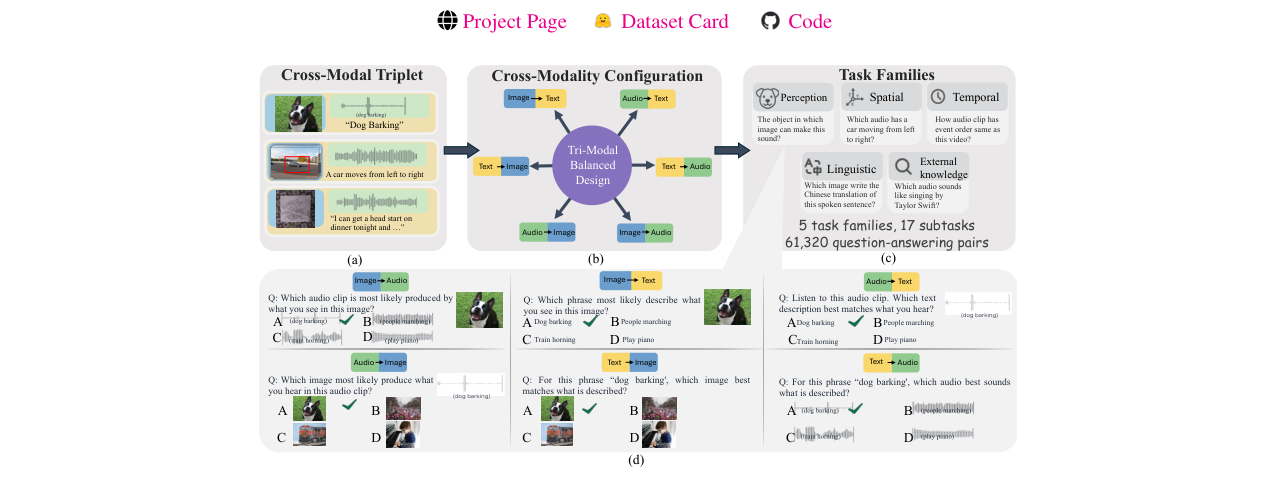
图1展示了XModBench的设计概览。 (a) 实例构建自对齐的三模态三元组; (b) 通过排列上下文和候选答案的模态,实例化为六种配置; (c) 覆盖五大任务领域和17个子任务; (d) 展示了在不同模态平衡设置下的选择题样例。
- 关键设计选择与动机:动机是量化模型的“模态不变推理”能力。设计选择是对称性与控制变量。通过保持语义内容不变,只改变模态形式,可以分离出模态本身对模型决策的影响,从而精确诊断模态偏好、差异和方向不平衡。这比仅报告总体平均分更有诊断价值。
💡 核心创新点
- 模态平衡的多模态问答设计:这是最核心的创新。不同于以往基准固定上下文或选项的模态,XModBench系统性地生成所有6种跨模态映射的实例,确保评估的公平性和诊断的细粒度。
- 跨模态一致性诊断指标:明确提出了“模态差异”(Modality Disparity)和“方向不平衡”(Directional Imbalance)两个量化指标。它们不再是简单的性能数字,而是直接反映模型内部表征对齐程度的度量。
- 覆盖全面的任务族与数据构建:构建了包含感知、空间、时间、语言、知识五大类、17个子任务的全面评测集。数据构建流程结合了现有数据集重标注、合成生成和网络收集,确保了任务的多样性和模态覆盖的完整性。
- 深入的失败案例与洞察分析:不仅报告数字,还通过生成模型推理链,对典型失败案例进行深入分析(如图6所示),直观展示了模态不一致的具体表现,并从中提炼出关于交织数据、任务覆盖和后训练影响的关键见解。

图6展示了两个失败案例。(a) Gemini 2.5 Pro能正确识别音频中的迪吉里杜管并匹配到正确文本,但无法匹配到正确的图像。(b) Qwen2.5-Omni在分析空间音频运动方向时,在音频→文本和文本→音频两种配置下给出了相反的答案。这揭示了跨模态推理中的不对称性。
🔬 细节详述
注意:本部分针对的是基准本身,而非一个训练模型。因此,模型训练相关的细节大多“未提供”。
- 训练数据:未提供模型训练数据。基准的数据构建过程如下:数据来源包括三类:1) 现有多模态数据集的重标注与扩展(如VGG-Sound, STARSS23);2) 合成或模型生成的内容(如用FireRedTTS生成语音, 渲染文本图像);3) 网络收集的样本(如歌手肖像、电影海报)。具体数据集名称见论文附录G引用。
- 损失函数、训练策略、关键超参数、训练硬件:均不适用于本基准,故“未提供”。
- 推理细节:被评测的模型使用各自的API或标准推理流程。论文未详细说明所有模型的具体推理超参数(如温度、beam size),但部分模型的评测设置在附录中有提及。
📊 实验结果
实验全面评估了12个模型在XModBench上的表现。
- 主要结果表格:见“核心摘要”部分的表格。
- 任务族分析:空间和时间推理是所有模型的短板。最强模型Gemini 2.5 Pro在空间推理上仅50.1%,时间推理60.8%,远低于其在感知(75.9%)和语言理解(76.8%)上的表现。
- 模态配置分析:视觉-文本组合性能最高(V→T可达88.6%),音频-文本组合次之,音频-视觉组合(无文本)性能最差,凸显了音频表征的脆弱性。
- 模态差异分析:如图4所示,音频与文本的差异(ΔT vs. A)最大,视觉与音频的差异(ΔV vs. A)次之,文本与视觉的差异(ΔT vs. V)最小。这表明音频是最大的性能瓶颈。
- 方向不平衡分析:如图5所示,在视觉-文本和音频-文本配对中,模型普遍在“文本→视觉/音频”配置下表现更好,在“视觉/音频→文本”配置下表现更差,表明存在以文本为中心的输出偏差。
- 三模态上下文测试:初步实验表明,同时提供音频和视觉上下文(A+V→T)相比单一最佳上下文,性能仅有小幅提升(如Gemini 2.5 Pro提升1.16%),说明当前模型尚未充分利用多模态互补信息。
- 与SOTA对比:论文本身未提出新模型,因此对比的是现有模型。结果显示闭源Gemini 2.5 Pro全面领先,开源模型中Qwen2.5-Omni和EchoInk-R1表现较强。
图2展示了XModBench中各类任务及其子任务的题目数量分布。感知任务占比最大,其次是空间推理和时间推理。
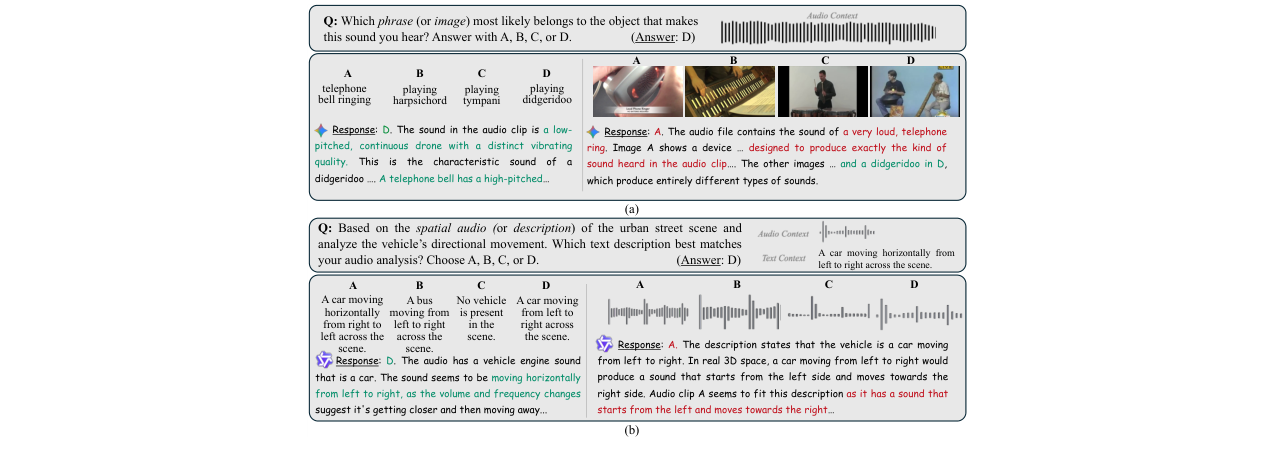
图8展示了Gemini模型在同时使用音频和视觉上下文(A+V → T)时的性能,并与单模态最佳结果(max(A, V) → T)进行比较。结果表明多模态上下文带来的提升有限。
⚖️ 评分理由
- 学术质量:6.5/7:创新性地提出了用于诊断跨模态一致性的系统性框架和指标,设计严谨,逻辑自洽。实验评估广泛且深入,数据分析多维度(任务、模态、方向、失败案例),证据链完整,可信度高。作为一篇评测论文,其质量属于上乘。
- 选题价值:1.8/2:选题精准切中当前全模态模型发展的核心瓶颈,具有很强的前瞻性和实用价值。该基准将直接推动模型在跨模态对齐、音频理解和鲁棒性方面的改进,对学术界和工业界的相关研究者都有重要意义。
- 开源与复现加成:0.7/1:承诺开源高质量数据集和评估工具,这对社区贡献巨大。但由于评测依赖现有模型(尤其是闭源API),且未提供复现其分析所需的完整脚本或模型权重,因此复现加成主要集中在数据集的使用上,而非完整的实验流程。