📄 WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
#多模态模型 #基准测试 #音频问答 #视频理解 #模型评估
✅ 7.0/10 | 前25% | #音频问答 | #基准测试 | #多模态模型 #视频理解
学术质量 6.5/7 | 选题价值 7.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Jack Hong(小红书公司)
- 通讯作者:Weidi Xie(上海交通大学)
- 作者列表:Jack Hong(小红书公司)、Shilin Yan(小红书公司)、Jiayin Cai(小红书公司)、Xiaolong Jiang(小红书公司)、Yao Hu(小红书公司)、Weidi Xie(上海交通大学)
💡 毒舌点评
这篇论文最大的亮点在于它指出了一个残酷的现实:现有最强的多模态大模型在需要同时理解声音和画面的真实世界场景中,表现最好的也只达到了65.1%的准确率,离可靠应用还差得远。然而,它的短板也同样明显:作为一个评测基准论文,它更像是为其他研究者“立规矩”和“出考卷”,本身在模型架构或训练方法上的原创性贡献有限。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:公开。论文明确说明WorldSense数据集已公开发布,可在其项目主页和GitHub/HuggingFace获取。
- Demo:未提供在线演示链接。
- 复现材料:提供了详细的评估设置(如帧采样方法、API使用)、评估Prompt模板(附录A.4)和数据集统计信息,足以复现其评估实验。
- 论文中引用的开源项目:引用了多个被评估的开源模型,如OneLLM, VideoLLaMA2, Qwen2-VL, LLaVA-OneVision等,以及数据集来源FineVideo和MusicAVQA。
- 开源计划:论文中未提及除数据集之外的额外开源计划。
📌 核心摘要
该论文旨在解决当前多模态大语言模型(MLLM)评估中忽略音频模态、场景简单、任务单一的问题。为此,作者提出了WorldSense,这是首个专注于评估MLLM对真实世界音视频同步内容进行全模态理解的基准测试。该基准的核心创新在于设计了紧密耦合音视频的任务,使得单独依赖任一模态都无法正确回答问题。它包含1662个来自8大领域、67个子类别的音频同步视频,以及3172个跨越26种认知任务的高质量多选题QA对。所有问答对由80名专家标注员多轮校对,确保质量。实验对众多开源和闭源模型进行了广泛评估。结果表明,现有模型在真实世界场景下面临巨大挑战,最佳模型Gemini 2.5 Pro的准确率仅为65.1%,而许多开源音视频模型的表现甚至接近随机猜测(约25%)。消融研究证实了原始音频信号比文本转录包含更多信息(如韵律、情感),对提升理解至关重要。该基准旨在推动更全面的多模态理解研究,为构建能够整合上下文信息的模型提供平台。主要局限性在于其采用的多选题格式限制了对模型生成能力的评估。
🏗️ 模型架构
本文未提出一个新的模型架构,而是设计了一个用于评估现有模型的基准框架。其核心是评估流程,如下:
- 输入:一个音视频同步的视频片段及其对应的多选题。
- 评估范式:模型需要同时处理视频帧、原始音频(可选)和问题文本,然后从给定的选项中选择正确答案。
- 关键组件:数据集本身(视频库和QA对)是核心“架构”。数据收集流程从FineVideo等来源开始,经过分类筛选、音视频相关性计算和人工审核,最终得到1662个高质量视频片段。QA标注流程则结合了专家标注和MLLM自动验证,确保问题需要多模态信息才能回答。
- 数据流:视频被处理为帧序列和音频波形/频谱,与问题文本一起输入模型,模型输出答案选择。评估通过准确率来衡量。
论文中并未提供一个整体的模型架构图,但描述了其评估和标注的流水线,其流程图如下:

图3:该图展示了WorldSense基准测试的数据收集与QA标注质量控制流水线。左侧是视频数据收集与筛选过程,从源视频库中经过领域筛选、音视频相关性及动态内容评估,最终得到1662个片段。右侧是问答对标注与质控流程,包括专家标注、语言清晰性、多模态必要性、难度评审以及使用MLLM进行自动验证的闭环过程。
💡 核心创新点
- 全模态整合的评估范式:首次提出一个专门评估模型整合视觉和音频能力的基准。之前的工作要么只关注图像(如OmniBench),要么音频与视觉关联较弱,或仅限于字幕任务。WorldSense设计的问题要求同时理解音视频才能回答,真正测试“全模态”感知。
- 内容与任务的多样性:基准覆盖8个主要领域和67个子类别,视频平均时长约141秒,并包含26种不同的认知任务,从基础感知到高级推理。这比之前聚焦于特定领域(如音乐)或任务(如字幕)的基准更为全面。
- 高质量与高难度的标注:所有QA对由80名专家标注,并经过多轮人工和MLLM交叉验证。这确保了问题的清晰度、必要性和适当的难度,避免了自动标注可能带来的低质量问题。
🔬 细节详述
- 训练数据:本文是评估基准,不涉及模型训练。评估使用的视频数据主要来自FineVideo数据集和MusicAVQA数据集。
- 评估设置:对三类模型进行评估:开源音视频模型(如OneLLM, VideoLLaMA2)、开源视频模型(如Qwen2-VL, LLaVA-OneVision)、闭源商业模型(如GPT-4o, Gemini 2.5 Pro)。
- 关键超参数/配置:对于商业模型GPT-4o和Claude 3.5 Sonnet,均匀采样16帧;对于Gemini 1.5 Pro,通过官方API上传原始视频文件。所有开源模型严格遵循其官方推荐的预处理流程。
- 训练硬件:所有实验在NVIDIA A100 GPU上进行。
- 推理细节:采用匹配法提取答案,评估指标为准确率。
- 正则化/技巧:未说明(评估论文不涉及)。
📊 实验结果
论文通过多个表格和图表展示了详尽的实验结果。
主要结果(Table 2):各类模型在WorldSense基准上��整体表现。开源视频模型最高仅达40.2%(LLaVA-Video)。令人惊讶的是,多数开源音视频模型表现更差,接近随机猜测(如VideoLLaMA2为25.4%)。商业模型中,仅处理视觉的GPT-4o(42.6%)与Claude 3.5 Sonnet(34.8%)表现中等,而能处理全模态的Gemini 2.5 Pro达到最高的65.1%,但仍不理想。
| 方法 | LLM规模 | 技术/科学 | 文化/政治 | 日常生活 | 影视 | 表演 | 游戏 | 体育 | 音乐 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| 开源音视频模型 | ||||||||||
| Unified-IO-2 XXL | 7B | 27.1 | 31.7 | 23.9 | 23.7 | 25.5 | 23.7 | 25.7 | 27.3 | 25.9 |
| VITA-1.5 | 7B | 38.2 | 35.9 | 34.3 | 39.8 | 41.2 | 32.6 | 34.7 | 39.9 | 36.9 |
| Qwen3-Omni | 7B | 58.7 | 60.5 | 54.5 | 53.8 | 55.4 | 46.8 | 48.8 | 52.2 | 54.0 |
| 开源视频模型 | ||||||||||
| Qwen2-VL | 7B | 33.5 | 29.0 | 28.4 | 33.6 | 30.3 | 32.3 | 34.7 | 38.5 | 32.4 |
| InternVL2.5 | 8B | 43.7 | 40.9 | 34.6 | 39.7 | 37.8 | 36.2 | 39.4 | 41.1 | 39.1 |
| 商业模型 | ||||||||||
| GPT-4o | - | 48.0 | 44.0 | 38.3 | 43.5 | 41.9 | 41.2 | 42.6 | 42.7 | 42.6 |
| Gemini 2.5 Pro | - | 64.9 | 66.0 | 65.8 | 68.1 | 69.7 | 65.7 | 63.5 | 61.3 | 65.1 |
细分任务与音频类型分析:图4展示了模型在不同任务类型上的性能,揭示出模型在音频相关任务、空间推理、计数和情感理解任务上普遍表现不佳。图5显示不同模型在语音、环境音、音乐三类音频上的性能不一致。
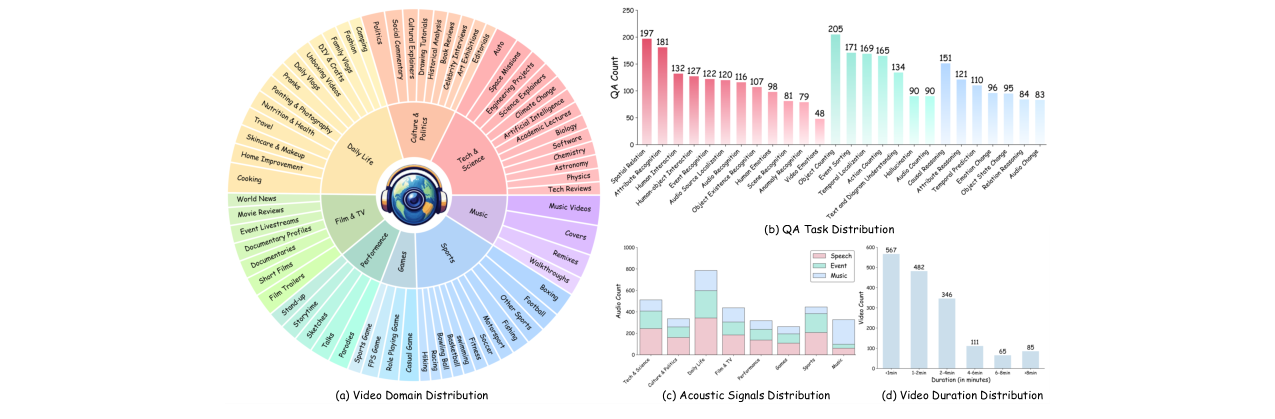
图4:不同模型在26种任务类别上的性能细分。可以观察到,所有模型在“音频识别”、“音频计数”等音频相关任务上性能普遍较低,且在“情感”、“空间推理”等需要复杂多模态推理的任务上也面临挑战。
消融实验 - 视觉信息的影响(Table 3):提供视觉信息(视频帧)通常能提升以音频输入为主的模型的性能。例如,Gemini 1.5 Pro从纯音频的34.6%提升到加视频的48.0%。
消融实验 - 音频信息的影响(Table 4):对于支持全模态的模型,原始音频信号比文本字幕更能提升性能。例如,Gemini 1.5 Pro在语音类问题上,从纯视频34.4%提升至加字幕39.3%,再提升至加原始音频48.0%,凸显了声学特征(如语调、情感)的价值。对于纯视频模型,添加字幕也能显著提升性能(Table 5)。
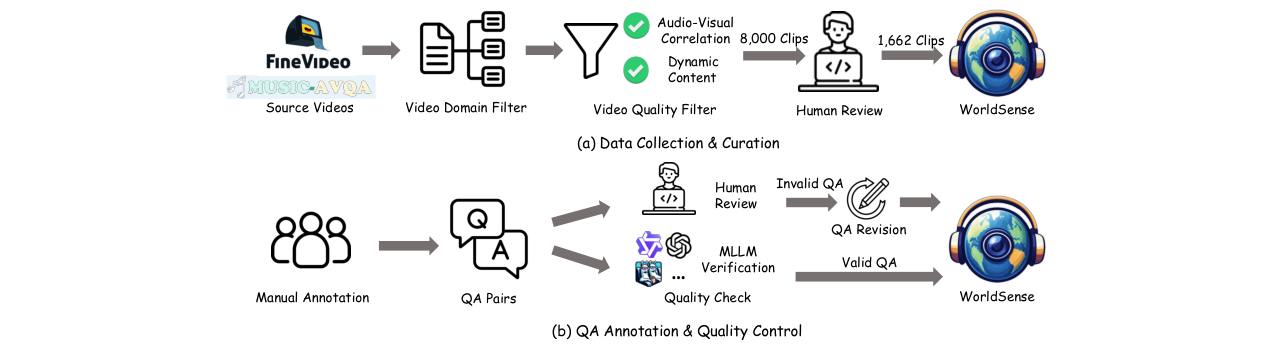
图5:现有模型在不同音频信号类型上的性能差异。图中显示,即便是最强的模型(如Gemini 1.5 Pro),在处理环境音事件相关问题时,其准确率也明显低于处理语音或音乐问题。
错误分析(Figure 6, 7):对Gemini 1.5 Pro的错误样本分析显示,主要错误类型为音频理解错误和推理错误,其次为视觉理解错误。案例展示了模型在读取视觉细节(时钟时间)和理解音乐情绪变化上的失败。
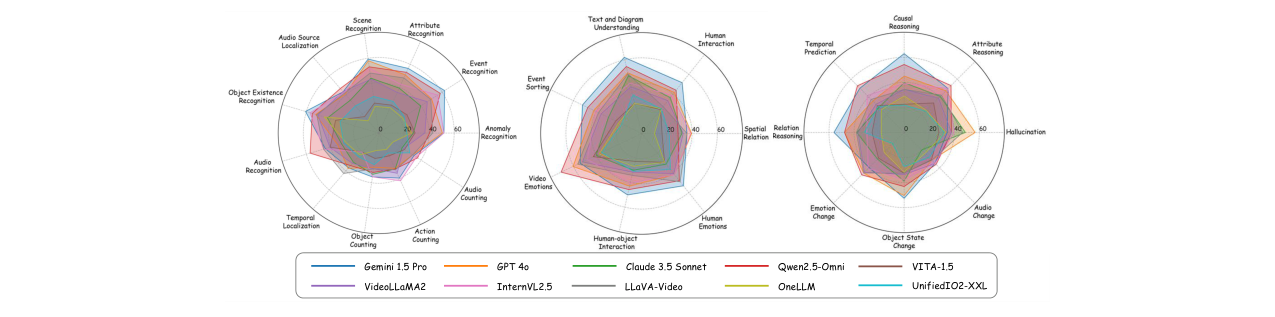
图6:采样自每个任务的5个错误案例的错误类型分布。大部分错误源自“音频理解错误”和“推理错误”。

图7:两个失败案例。左图显示模型因错误识别钟表时间(视觉理解错误)导致回答错误。右图显示模型误解了古筝乐曲的节奏情绪变化(从“激昂”到“舒缓”误判为“舒缓”到“激烈”),属于音频理解错误。
⚖️ 评分理由
- 学术质量:6.5/7:论文贡献了一个设计严谨、标注高质量的评测基准,实验全面,分析深入。但作为一篇基准论文,其创新性主要体现在评测框架的构建上,而非提出解决多模态融合难题的新方法。技术正确性高,实验结果可信,为领域提供了重要的诊断工具和性能下限。
- 选题价值:1.5/2:选题非常前沿且必要。随着多模态模型发展,真实世界理解需要音视频协同。WorldSense填补了这一评估空白,其揭示的现有模型局限性对指导未来研究方向和实际应用部署(如辅助技术、人机交互)有重要参考价值。
- 开源与复现加成:+1.0/1:论文公开了完整的数据集(WorldSense)和详细的评估协议,使其他研究者能够完全复现其评估结果。这是对社区的重要贡献。然而,未提供基准本身之外的代码或模型,因此复现限于“评估复现”层面。