📄 WearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
#基准测试 #多通道 #语音大模型 #音频问答
🔥 8.0/10 | 前25% | #基准测试 | #麦克风阵列 | #多通道 #语音大模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zhaojiang Lin(Meta),Yong Xu(Meta),Kai Sun(Meta)(论文明确标注三位为共同第一作者:Joint first author)
- 通讯作者:未明确说明(但Zhaojiang Lin提供了联系邮箱zhaojiang@meta.com)
- 作者列表:Zhaojiang Lin(Meta),Yong Xu(Meta),Kai Sun(Meta),Jing Zheng(Meta),Yin Huang(Meta),Surya Teja Appini(Meta),Krish Narang(Meta),Renjie Tao(Meta),Ishan Kapil Jain(Meta),Siddhant Arora(Carnegie Mellon University,标注工作在Meta完成),Ruizhi Li(Meta),Yiteng Huang(Meta),Kaushik Patnaik(Meta),Wenfang Xu(Meta),Suwon Shon(Meta),Yue Liu(Meta),Ahmed A Aly(Meta),Anuj Kumar(Meta),Florian Metze(Meta),Xin Luna Dong(Meta)
💡 毒舌点评
亮点在于首次针对可穿戴场景定义了多通道、自我中心语音助手评测标准,数据基于真实AI眼镜采集,任务设计紧贴现实痛点(如侧向对话拒绝)。短板是数据集规模相对有限(3.8k样本),且评估的大部分现有SLLM只能基于波束成形后的单通道音频输入,未能充分验证多通道架构的潜力,论文中提出的MC WearLlama也仅是案例研究,非核心贡献。
🔗 开源详情
- 代码:提供数据集代码仓库链接:
https://github.com/facebookresearch/wearvox。 - 模型权重:未提及公开任何模型权重(包括论文中评估的商业模型和案例研究的WearLlama模型)。
- 数据集:WearVox数据集通过上述GitHub仓库公开。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详细的基准任务提示(附录A.1)、LLM评判提示(附录A.2)、数据采集细节(附录A.3)和分布统计(附录A.4),但未提供完整的训练细节、配置、检查点或超参数设置。
- 论文中引用的开源项目:论文中引用的开源模型/框架包括:Whisper ASR、Llama 3.3 70B(用作LLM评判)、Llama-4-Scout、Conformer、BEST-RQ、AudioChatLlama、SeamlessM4T。
📌 核心摘要
这篇论文旨在解决现有语音助手评测基准忽略可穿戴设备特有挑战(如自我中心音频、运动噪声、区分设备指令与背景对话)的问题。核心方法是提出了WearVox,首个专门针对可穿戴场景的基准数据集,包含3,842条通过AI眼镜采集的多通道自我中心音频录音,涵盖五类任务(搜索问答、闭卷问答、工具调用、侧向对话拒绝、双向语音翻译)及多样化室内外声学环境。与已有基准相比,WearVox首次引入了多通道音频、丰富的说话人角色(佩戴者、对话伙伴、旁观者)和真实世界噪声环境。实验评估了多个先进的语音大语言模型,发现当前最先进模型在嘈杂户外环境性能显著下降,准确率在29%至59%之间。一个案例研究表明,基于多通道输入的SLLM(MC WearLlama)相比单通道版本,在抗噪声和区分设备指令方面表现出显著优势,侧向对话拒绝准确率从85.6%提升至93.9%。该工作填补了可穿戴语音AI评测的空白,揭示了空间音频线索对上下文感知助手的重要性。主要局限在于数据集规模仍属中等,且提出的多通道模型仅为案例研究,未成为可直接复用的开源SOTA模型。
🏗️ 模型架构
论文本身的核心贡献是提出WearVox基准数据集和评测框架,而非一个全新的端到端模型架构。然而,论文在案例研究中详细描述了为对比单/多通道效果而构建的WearLlama系列模型架构。
SC WearLlama (单通道 WearLlama):
- 架构:基于Llama-4-Scout-17B-16E大语言模型,前端连接一个1B参数的Conformer语音编码器(使用BEST-RQ预训练)。
- 输入:仅处理经过波束成形的单通道音频(
c_x)。 - 流程:Conformer编码器将80ms的音频帧转换为音频嵌入,通过一个音频到文本(A->T)投影层后,与文本提示嵌入一起输入LLM解码器生成文本响应。
MC WearLlama (多通道 WearLlama):
- 架构:与SC版本共享相同的Conformer编码器和Llama-4-Scout-17B-16E LLM主干。
- 输入:同时处理两个通道:通道0(c0,通常信噪比最高) 和波束成形后的单通道(cx)。
- 流程:两个通道的音频分别通过共享权重的Conformer编码器和A->T投影层,产生两组音频嵌入。这两组嵌入以交错的方式与文本嵌入一起输入LLM解码器。这种设计使模型能够从原始多通道音频中捕获空间线索。
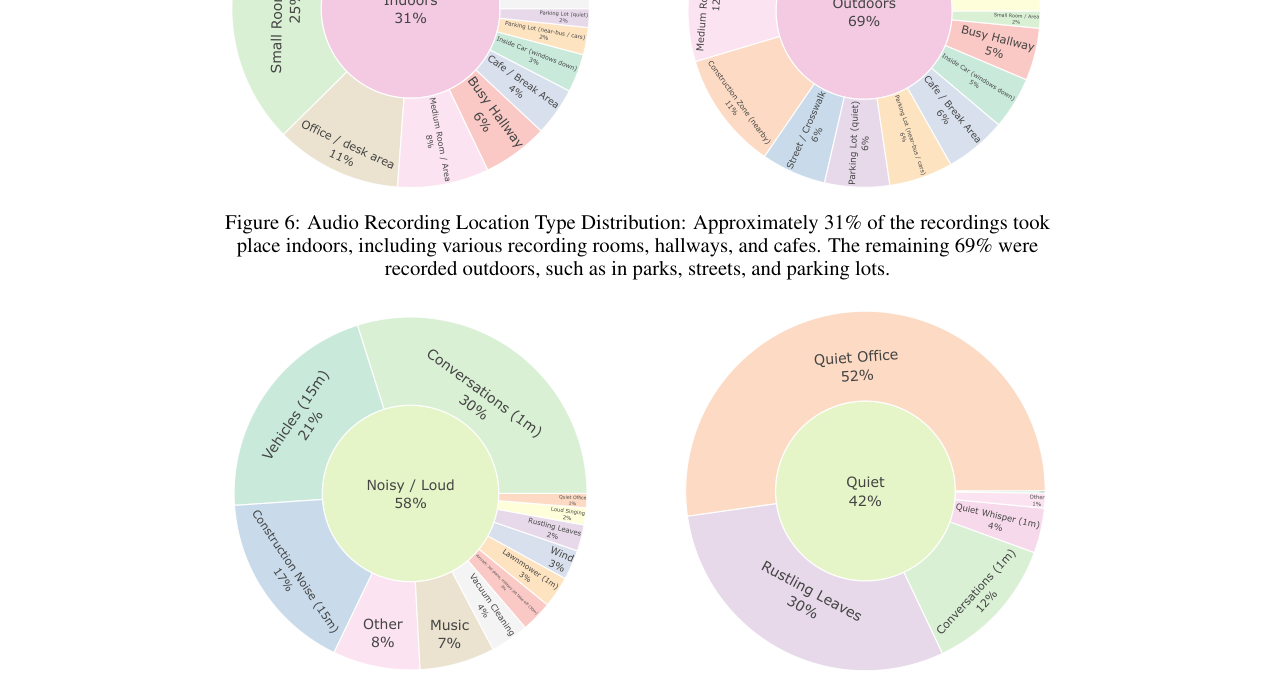
图2(来自论文):展示了SC WearLlama仅处理波束成形通道(cx),而MC WearLlama同时处理通道0(c0)和波束成形通道(cx)并交错输入LLM的架构区别。
💡 核心创新点
- 首个可穿戴专用语音助手基准(WearVox):现有基准(如VoiceBench, Spoken-CoQA)主要基于干净或通用对话音频,忽略了可穿戴设备特有的自我中心视角、多通道音频、快速交互及需区分设备指令与背景语音等挑战。WearVox首次系统性地引入了这些要素,为评估真实世界可穿戴语音助手提供了标准化测试平台。
- 多通道音频输入的案例研究与价值验证:论文不仅提出了基准,还通过构建MC WearLlama案例,首次实验性地证明了在SLLM中直接利用多通道原始音频相比仅使用波束成形单通道音频,能显著提升模型在噪声环境下的鲁棒性(特别是在侧向对话拒绝和工具调用任务上)。这指明了未来可穿戴语音模型设计的一个重要方向。
- 揭示当前SLLM在真实可穿戴场景下的性能瓶颈:通过大规模评测,论文量化发现当前顶尖SLLM(包括GPT-4o Audio, Gemini 2.5 Flash等)在WearVox基准上的准确率普遍不高(29%-59%),且在户外嘈杂环境下性能大幅下降。这直接指出了将现有语音大模型应用于可穿戴设备时存在的巨大差距和挑战,为后续研究设定了明确的改进目标。
🔬 细节详述
- 训练数据:
- 对于WearVox基准本身:数据通过招募母语者在真实场景(室内/室外)使用AI眼镜录制。脚本来自CRAG和Head-to-Tail数据集(用于QA),或基于场景由标注员使用LLM辅助生成多轮对话(用于其他任务)。录制鼓励自然对话,而非严格朗读。
- 对于MC WearLlama模型:训练数据来自多个来源,包括:1) 来自SeamlessM4T的伪标签ASR数据;2) 使用AudioChatLlama方法从ASR音频生成的语音QA数据;3) 使用内部TTS将文本指令数据转换为的语音QA数据。未使用WearVox数据进行训练。
- 损失函数:MC WearLlama采用标准的下一token预测损失(标准监督微调损失):
L_SFT = -Σ log P(t_O_i | TI, SI, t_{<i}; θ)。 - 训练策略:论文中未详细说明学习率、warmup、batch size、优化器、训练步数等超参数。仅提到遵循AudioChatLlama的语音对齐方法进行训练。
- 关键超参数:LLM主干为Llama-4-Scout-17B-16E;语音编码器为1B参数Conformer;音频采样率12.5Hz(每80ms一个嵌入)。
- 训练硬件:未说明。
- 推理细节:对于基准测试,单通道输入的模型先使用波束成形将多通道音频转为单通道。MC WearLlama处理两个通道的交错嵌入。具体解码策略(如温度、beam size)未在正文中详述。
- 数据增强:为训练MC WearLlama,将单通道音频模拟为五通道录制。方法包括:使用真实环境录制的房间脉冲响应(RIR)进行卷积以模拟空间多样性;在随机信噪比(-5dB至40dB)下添加室内噪声;引入不同重叠比例的旁观者语音,模拟真实声学条件。
📊 实验结果
论文报告了在WearVox基准上的主要评测结果,以及单/多通道模型的对比案例研究。
表2:主要基准测试结果(Turn-based任务准确率%, Speech Translation为Session-based得分)
| Baselines | Search Grounded QA | Closedbook QA | Tool Calling | Side Talk Rejection | Turn-based Micro-avg | Speech Translation |
|---|---|---|---|---|---|---|
| Gemma 3n | 29.4 | 20.4 | 5.7 | 59.9 | 29.7 | 14.8* |
| Kimi-Audio | 10.1 | 31.5 | 63 | 47.0 | 43.6 | 41.8* |
| Qwen2.5-Omni | 35.8 | 29.8 | 7.3 | 60.4 | 33.1 | 43.9* |
| GPT-4o Audio | 50.5 | 59.4 | 8.9 | 66.0 | 43.1 | 76.0 |
| GPT-5 w/ Whisper | 57.8 | 70.6 | 35.7 | 73.8 | 57.8 | 92.9* |
| Gemini 2.5 Flash | 49.0 | 46.8 | 44.4 | 88.2 | 59.8 | 50.3 |
| Gemini 2.5 Flash Thinking | 48.8 | 61.4 | 68.1 | 91.4 | 71.3 | 70.1 |
注:表示输入音频被截断。
关键发现:开源模型(<8B参数)表现普遍较弱。GPT-5 w/ Whisper在搜索问答和闭卷问答上表现最佳,但在工具调用上因不擅长结构化输出而较弱。Gemini 2.5 Flash在开启“思考”模式后性能大幅提升(整体Turn-based准确率从59.8%升至71.3%),但带来了显著的延迟增加(平均TTFT从1592ms增至5546ms)。
表4:单通道(SC)与多通道(MC)WearLlama案例研究对比(Turn-based任务准确率%)
| Baselines | Search Grounded QA | Closedbook QA | Tool Calling | Side Talk Rejection | Turn-based Micro-avg |
|---|---|---|---|---|---|
| SC WearLlama | 43.3 | 42.5 | 58.5 | 85.4 | 61.9 |
| MC WearLlama | 43.3 | 42.2 | 63.9 | 93.9 | 66.4 |
关键发现:MC WearLlama在工具调用(+5.4%)和侧向对话拒绝(+8.5%)任务上显著优于SC版本,整体准确率提升4.5%,证明了多通道音频在分离指令和抗噪方面的优势。在两项QA任务上两者性能接近。
图3:声学环境对模型性能的影响(Turn-based任务)
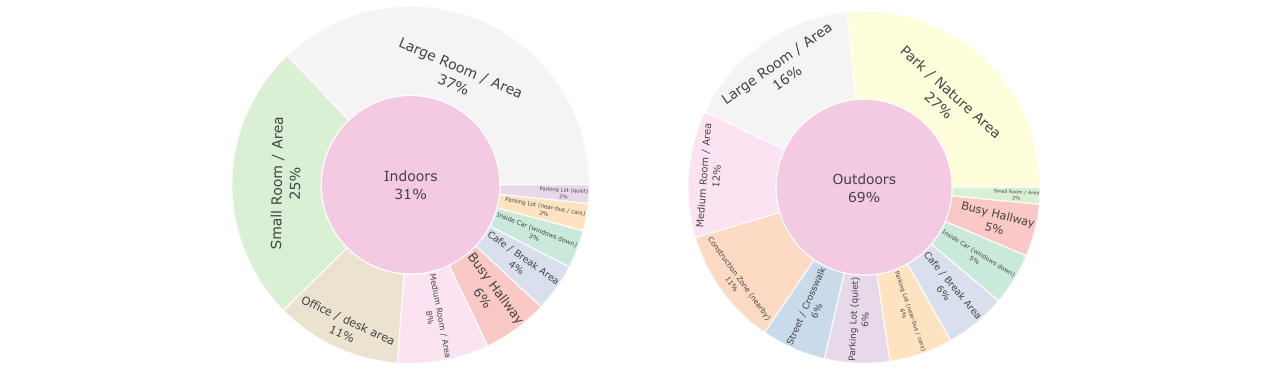
图3(来自论文):展示了不同模型在室内/室外、安静/嘈杂环境下的准确率对比。关键结论:1)大多数模型在户外和嘈杂环境下性能下降;2)Gemini 2.5 Flash Thinking表现出极强的噪声鲁棒性;3)MC WearLlama在户外嘈杂环境下的鲁棒性显著优于SC WearLlama。
表3:部分模型的任务响应延迟(TTFT, ms)
| Task | Gemini 2.5 Flash | Gemini 2.5 Flash Thinking | GPT-4o Audio |
|---|---|---|---|
| Closedbook QA | 1368.69 | 2287.76 | 1220.22 |
| Search Grounded QA | 1526.56 | 9194.94 | 1867.66 |
| Speech Translation | 2138.11 | 11321.49 | 7523.24 |
| Side Talk Rejection | 1306.62 | 2176.97 | 1341.04 |
| Tool Calling | 1404.69 | 2084.19 | 1289.99 |
关键发现:推理增强(思考模式)以大幅增加延迟为代价换取性能提升,这在对实时性要求高的可穿戴场景中是一个重要权衡。
⚖️ 评分理由
- 学术质量:6.0/7。论文提出了一个填补重要空白的基准,问题定义清晰,数据采集和任务设计具有现实意义。实验评估了多个前沿模型,并进行了有说服力的多通道案例研究。但基准规模(3.8k样本)相对有限,且多通道模型部分仅为案例研究,非完整、优化的SOTA方案,整体创新深度有进一步提升空间。
- 选题价值:1.5/2。针对可穿戴设备这一快速发展的领域,定义标准化评测基准具有很高的前沿性和实际应用价值,对推动可穿戴语音AI研究有明确指导意义,与音频/语音领域读者高度相关。
- 开源与复现加成:0.5/1。论文公开了WearVox数据集代码仓库(
https://github.com/facebookresearch/wearvox),提供了数据集获取方式和任务提示等复现细节。但未公开MC/SC WearLlama模型权重或训练代码,因此复现性加成有限。