📄 WAVE: Learning Unified & Versatile Audio-Visual Embeddings with Multimodal LLM
#多模态模型 #对比学习 #音频检索 #视频检索 #多任务学习
🔥 8.0/10 | 前25% | #音频检索 | #对比学习 | #多模态模型 #视频检索
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Changli Tang (清华大学)
- 通讯作者:Chao Zhang (清华大学)
- 作者列表:Changli Tang (清华大学), Qinfan Xiao (清华大学), Ke Mei (腾讯微信视觉), Tianyi Wang (腾讯微信视觉), Fengyun Rao (腾讯微信视觉), Chao Zhang (清华大学)
💡 毒舌点评
这篇论文最大的亮点在于“敢为人先”,首次将文本、音频、视频统一到同一个LLM嵌入空间,打破了传统双编码器的限制,其联合训练策略带来的跨模态性能提升也令人印象深刻。然而,其创新性更多体现在对现有技术(LLM backbone,分层融合,多任务训练)的精巧集成与验证,而非提出颠覆性的新概念,因此对于追求“首个”或“全新范式”的读者而言可能略显不足。
🔗 开源详情
- 代码:论文中提到代码和检查点将在
https://github.com/TCL606/WAVE发布。但当前论文PDF中未提供该链接。 - 模型权重:论文承诺将发布模型检查点(checkpoints)。
- 数据集:论文使用了多个公开数据集(如Panda-70M, MSR-VTT, AudioCaps等),但未提及发布新的数据集。
- Demo:论文中未提及在线演示。
- 复现材料:论文在Section 3.1, 3.2, 4.1, 4.2中详细描述了模型架构、训练流程、训练数据和超参数,提供了足够的复现信息。
- 论文中引用的开源项目:
- 基础模型:Qwen2.5-Omni (Xu et al., 2025)
- 音频编码器:BEATs (Chen et al., 2022b)
- 训练数据:WavCaps, AudioCaps, Clotho, Panda-70M等。
- 其他工具/模型:LoRA (Hu et al., 2022), InternVL-2.5-8B (Chen et al., 2024c) 用于重新标注。
📌 核心摘要
- 要解决的问题:现有的多模态嵌入模型多基于独立编码器,缺乏一个能同时处理文本、音频、视频,并将它们统一到同一语义空间的通用模型。这对于需要动态模态(如音视频)深度理解的跨模态检索和生成任务是一个瓶颈。
- 方法核心:提出了WAVE,一个基于Qwen2.5-Omni多模态大语言模型的统一音视频嵌入模型。其核心设计包括:1) 双音频编码器(语音+音频事件)全面捕获音频信息;2) 一种分层特征融合策略,聚合LLM多层隐藏状态以获得更鲁棒的表示;3) 联合多模态多任务训练策略,同时优化检索与问答任务。
- 与已有方法相比新在哪里:WAVE是首个能够为文本、静音视频、音频以及同步音视频输入生成统一嵌入的LLM-based模型。与现有双编码器模型(如CLIP系列)或专注图像的LLM嵌入模型(如VLM2Vec)不同,WAVE真正实现了对动态音视频模态的统一建模,并具备生成提示感知(prompt-aware)嵌入的能力。
- 主要实验结果:
- 视频理解:在MMEB-v2视频基准整体得分59.9%,全面超越LamRA、GME等开源模型,甚至优于工业级模型Seed-1.6-Embedding(55.3%)。
- 音频/音视频检索:在AudioCaps(文本到音频R@1: 44.2%)、Clotho(25.6%)、VGGSound(视频到音频R@1: 25.0%)等任务上达到SOTA。
- 提示感知能力:在视频问答任务中,使用单独问题作为提示时平均准确率达72.5%,远超使用通用提示(51.8%),显著优于其他嵌入模型。
- 消融实验:联合训练优于分别训练(7/8任务上提升);分层特征融合(All-layer MLP)优于单层池化(如在MSR-VTT上,视频检索R@1从54.7%提升至56.1%)。 主要实验结果见下表:
| 任务类别 | 基准 | 指标 | WAVE 7B | 最强基线/参考模型 | 参考值 |
|---|---|---|---|---|---|
| 视频嵌入 | MMEB-v2-Video Overall | Acc% | 59.9 | Seed-1.6-Embedding | 55.3 |
| MMEB-v2-Video RET | R@1 | 72.5 | Seed-1.6-Embedding | 60.9 | |
| LoVR (theme-to-clip) | R@25 | 66.0 | LamRA 7B | 60.2 | |
| 音频检索 | AudioCaps | R@1 | 44.2 | Reference Model | 42.2 |
| Clotho | R@1 | 25.6 | Reference Model | 21.5 | |
| 音视频检索 | VGGSound | R@1 | 25.0 | encoder-only | 10.3 |
| 音频问答 | MMAU | Acc% | 76.6 | Qwen2.5-Omni 7B | 71.5 |
| 视频问答 | MMEB-v2-Video QA (w/ questions) | Acc% | 72.5 | Seed-1.6-Embedding | 60.9 |
- 实际意义:WAVE提供了一个强大的基线模型,使得在单一模型中处理任意模态组合的检索、分类和问答成为可能,极大地推动了跨模态应用(如通用多模态搜索、内容理解)的发展。
- 主要局限性:论文未详细讨论模型在面对更复杂、更长或噪声更大的真实世界音视频场景下的鲁棒性。此外,其统一的嵌入空间是否能无缝支持所有下游生成任务(如图像生成)也未验证。
🏗️ 模型架构
WAVE的整体架构如图1所示,其核心是将多种模态的输入通过各自编码器转换为LLM可处理的token序列,再由LLM统一处理并生成统一的嵌入。
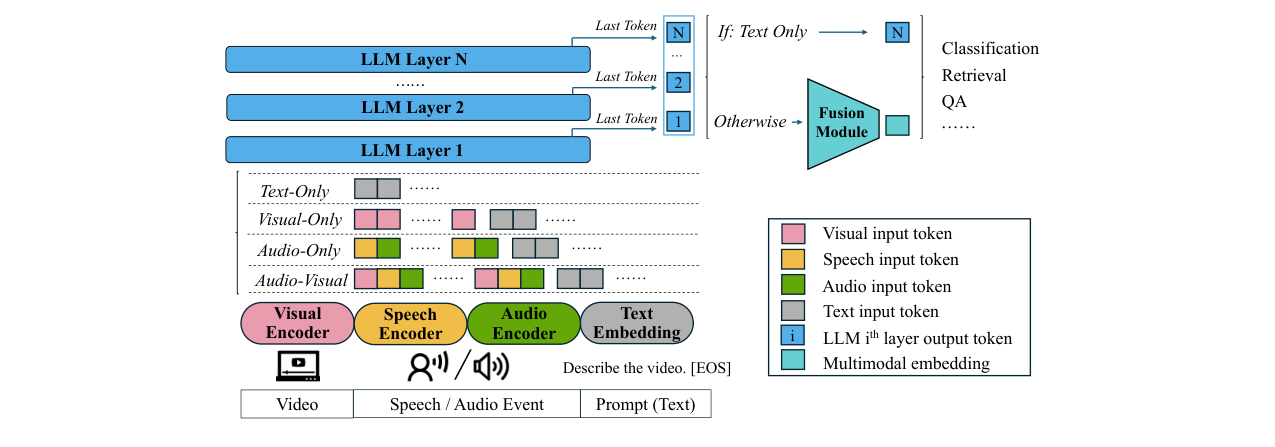
完整输入输出流程:
- 输入:支持四种配置:纯文本、纯视觉(视频)、纯音频、音视频同步。
- 编码:
- 视觉:预训练视觉编码器(来自Qwen2.5-Omni)提取视频帧特征,生成视觉token。
- 音频:采用双编码器设计。语音编码器(来自Qwen2.5-Omni,基于Whisper)处理语音信号;音频事件编码器(BEATs)处理非语音音频事件。两个编码器频率同步,输出token数量一致。
- 文本:使用LLM自带的文本嵌入层进行分词和编码。
- 输入序列构建:
- 对于音频输入,语音token与音频事件token以1:1比例交错排列。
- 对于音视频输入,视觉token序列和音频token序列被分成与采样帧数相同的片段,然后交错排列。
- 最后,文本提示token被追加到序列末尾,构成LLM的完整输入。所有多模态输入总是伴随一个文本提示作为指令。
- 位置编码:采用来自Qwen2.5-Omni的时间对齐多模态旋转位置编码,确保同一时间戳的语音、音频和视觉token共享相同的位置编码,实现精确的时序对齐。
- LLM处理与嵌入生成:
- 交错后的多模态token序列输入LLM(Qwen2.5-Omni 7B的backbone)。
- 分层特征融合:不局限于最后一层。模型聚合LLM所有层(共28层)的最后一个token的隐藏状态,并将其拼接。
- 融合模块:一个轻量级的两层MLP(带GELU激活)将拼接后的特征压缩并转换为最终的、统一的多模态嵌入。
- 对于纯文本输入,则采用标准的最后一token池化。
关键设计选择与动机:
- 双音频编码器:动机在于基础模型Qwen2.5-Omni的音频编码器源自Whisper,对非语音音频事件理解不足。引入BEATs作为专用音频编码器,与语音编码器互补,以全面捕获音频信号。
- 分层特征融合:动机来自观察(如Gou et al., 2025),即LLM不同层在视频理解中扮演不同角色。聚合所有层的信息可以兼顾低层感知线索和高层语义抽象,获得更鲁棒的表示。
- 交错输入与TMRoPE:确保音视频信息在输入LLM前就已在时序上对齐,便于模型学习跨模态关联。
💡 核心创新点
- 首个统一的音视频嵌入LLM:WAVE是第一个能够为文本、静音视频、音频和同步音视频生成统一语义空间嵌入的多模态LLM。与之前主要关注图像或仅对齐特定模态对的模型不同,WAVE实现了更广泛的“任意到任意”跨模态统一。
- 分层特征融合策略:提出了一种从LLM多个层提取最后token特征并通过轻量级MLP进行融合的方法。这比仅使用最后一层的隐藏状态(如传统last-token pooling)更有效,实验证明在检索任务上带来稳定增益。
- 联合多模态多任务训练框架:设计了一套同时优化检索(使用对称InfoNCE损失)和问答(使用对比交叉熵损失)任务的训练方案。消融研究证实,这种联合训练能促进跨模态知识迁移,在所有模态的任务上普遍提升性能。
🔬 细节详述
- 训练数据:
- 预训练阶段(BEATs对齐器):使用WavCaps、AudioCaps、Clotho中的音频数据,任务为音频描述生成。
- 主训练阶段:数据集及规模见下表。特别地,Panda-70M的1M视频使用InternVL-2.5-8B进行了重新标注。
| 任务 | 数据来源 | 模态对 (s, t) | 样本数 |
|---|---|---|---|
| 视频-文本检索 | Panda-70M | (视觉,文本) | 1.0 M |
| MSVD | (视觉,文本) | 24 K | |
| DiDeMo | (视觉,文本) | 8 K | |
| ActivityNet Captions | (视觉,文本) | 10 K | |
| MSR-VTT | (音视频,文本) | 180 K | |
| VATEX | (音视频,文本) | 260 K | |
| YouCook2 | (音视频,文本) | 10 K | |
| Shot2Story | (音视频,文本) | 530 K | |
| 视频-QA | LLaVA-Video-178k | (视觉,文本) | 100 K |
| 视频-音频检索 | AudioSet | (音频,视觉) | 1.7 M |
| VGGSound | (音频,视觉) | 182 K | |
| 音频-文本检索 | AudioCaps | (音频,文本) | 49 K |
| AudioSet-SL | (音频,文本) | 108 K | |
| Clotho | (音频,文本) | 19 K | |
| 总计 | - | - | 4.9 M |
- 损失函数:
- 检索任务:对称InfoNCE损失,公式见(1)-(3)。使用in-batch负采样,温度参数τ设为0.01。
- 问答任务:多分类交叉熵损失,公式见(4)-(5)。每个正确答案配备n个干扰答案。
- 训练策略:
- 预训练阶段:仅训练BEATs对齐器(两层MLP),其他组件冻结。训练3个epoch,使用128张H20 GPU。
- 主训练阶段:使用低秩适应对LLM骨干网络进行微调。LoRA模块秩为128,缩放因子2.0, dropout为0.05。视觉对齐器和LoRA模块可训练,其他冻结。学习率为2e-5,每设备batch size为1,总batch size为192(192张H20 GPU)。训练1个epoch,耗时约36小时。采用任务感知的数据采样器,确保每个mini-batch内的样本来自同一任务和数据源。
- 关键超参数:模型基于Qwen2.5-Omni 7B构建。LLM有28层。视频采样率2fps,最大128帧。音频重采样至16kHz。融合模块为两层MLP with GELU。
- 推理细节:所有检索任务使用固定提示“Please describe the video/audio”生成嵌入。问答任务则将具体问题作为提示生成嵌入,然后与所有答案选项的嵌入计算相似度进行选择。
- 正则化:在LoRA模块中应用了dropout(0.05)以防止过拟合。
📊 实验结果
论文在视频、音频、音视频以及跨模态问答任务上进行了全面评估。
- 主要性能对比 (视频域)
图:不同模型在MMEB-v2视频基准和LoVR基准上的性能对比。WAVE在所有子任务上均取得最佳或极具竞争力的结果。
| 模型 | MMEB-v2-Video Overall | CLS | QA | RET | MRET | LoVR (theme-to-clip) |
|---|---|---|---|---|---|---|
| LamRA 7B | 35.0 | 39.3 | 42.6 | 24.3 | 32.8 | 60.2 |
| GME 7B | 38.4 | 37.4 | 50.4 | 28.4 | 37.0 | 43.9 |
| CAFe 7B | 42.4 | 35.8 | 58.7 | 34.4 | 39.5 | - |
| Seed-1.6-Embedding | 55.3 | 55.0 | 60.9 | 51.3 | 53.5 | - |
| WAVE 7B | 59.9 | 57.8 | 72.5 | 54.7 | 50.8 | 66.0 |
- 主要性能对比 (音频/音视频域)
| 方法 | A-RET (AudioCaps R@1) | A-RET (Clotho R@1) | AV-RET (VGGSound R@1) | AV-RET (MusicCaps R@1) | A-QA (MMAU Acc%) | A-QA (MMAR Acc%) |
|---|---|---|---|---|---|---|
| Reference Model | 42.2 | 21.5 | 10.3 | 8.6 | 71.5 | 56.7 |
| encoder-only model | 未提供 | 未提供 | 10.3 | 8.6 | 未提供 | 未提供 |
| Qwen2.5-Omni 7B | 未提供 | 未提供 | 未提供 | 未提供 | 71.5 | 56.7 |
| WAVE 7B | 44.2 | 25.6 | 25.0 | 20.4 | 76.6 | 68.1 |
- 提示感知嵌入分析 在视频问答任务上,使用单独问题提示与使用通用提示的性能对比:
| 模型 | MMEB-v2-Video QA (w/ questions) | Average |
|---|---|---|
| WAVE 7B, w/ a common prompt | 51.8 | 51.8 |
| WAVE 7B, w/ separate questions | 72.5 | 72.5 |
| Seed-1.6-Embedding | 60.9 | 60.9 |
该结果表明,WAVE强大的指令跟随能力使其能根据具体问题生成高度相关的提示感知嵌入,这对QA任务至关重要。
- 消融实验
- 联合训练 vs 分别训练:
图:在不同模态任务上,联合训练模型与分别训练的专家模型的性能对比。联合训练在绝大多数任务上更优。
| 训练方式 | MMEB-v2-Video Overall | A-RET (AudioCaps) | AV-RET (VGGSound) |
|---|---|---|---|
| Separate | 58.2 | 42.5 | 24.0 |
| Joint | 59.0 | 44.2 | 25.0 |
- 特征融合方法:
| 方法 | 模态 | MMEB-v2-Video RET Average |
|---|---|---|
| Last token pooling (last layer) | V | 49.6 |
| All-layer last token weighted sum | V | 48.3 |
| All-layer last token MLP fusion | V | 50.5 |
| Last token pooling (last layer) | A+V | 54.7 |
| All-layer last token MLP fusion | A+V | 56.1 |
该结果证实,分层融合(尤其是MLP方式)比单层池化和简单加权求和更有效。
- 双编码器有效性分析
| 方法 | V-RET (YouCook2 R@1) | A-RET (AudioCaps R@1) | AV-RET (MusicCaps R@1) |
|---|---|---|---|
| Single speech encoder | 34.3 | 39.6 | 18.3 |
| Dual speech & audio encoders | 36.8 | 42.5 | 20.1 |
双编码器配置在音频相关任务上一致优于单编码器,证明了其互补性。
⚖️ 评分理由
- 学术质量:7.0/7:论文技术路线清晰,实验设计严谨,覆盖了从基线对比到深入消融的各个方面。在多个权威基准上达到SOTA,并公开了可复现的细节。其创新性体现在对现有技术的有效整合与验证上,虽然未提出全新的模型范式,但为统一的音视频嵌入提供了一个坚实、高性能的解决方案。
- 选题价值:1.5/2:统一的音视频嵌入是多模态AI的核心挑战之一,具有很高的前沿性和广泛的应用前景(如跨模态搜索、内容理解、生成式AI)。该工作直接针对此问题,并取得了显著进展,对学术界和工业界都有价值。
- 开源与复现加成:0.5/1:论文明确承诺将公开代码和模型权重,并提供了相当详细的训练数据、超参数和流程说明,这大大增加了工作的可复现性和影响力。但当前未提供具体链接,因此加成不是满分。