📄 Unified Multi-Modal Interactive and Reactive 3D Motion Generation via Rectified Flow
#动作生成 #流匹配 #检索增强 #多模态 #扩散模型
✅ 7.5/10 | 前25% | #动作生成 | #流匹配 | #检索增强 #多模态
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Prerit Gupta (Purdue University, Department of Computer Science)
- 通讯作者:未说明(但Aniket Bera为最后作者,通常为通讯作者)
- 作者列表:Prerit Gupta (Purdue University), Shourya Verma (Purdue University), Ananth Grama (Purdue University), Aniket Bera (Purdue University)
💡 毒舌点评
亮点在于将交互和反应式双人动作生成统一到一个框架中,并创新性地为动作生成引入了基于LLM分解的检索增强生成,有效提升了语义对齐。短板在于该领域相对小众,实际应用场景(如VR/AR游戏)的验证可能有限,且模型参数量(456M)相比基线(224M)显著增大,提升了部署门槛。
🔗 开源详情
- 代码:论文明确承诺将开源代码(“Full code for this project… will be made open source… upon paper acceptance”),但未提供具体链接。
- 模型权重:承诺将提供训练好的检查点。
- 数据集:使用了InterHuman-AS、DD100、MDD三个公开数据集,论文中给出了获取参考。
- Demo:未提及在线演示。
- 复现材料:附录提供了详尽的LLM提示词设计、架构细节(公式)、损失权重配置、超参数选择等,复现信息充分。
- 引用的开源项目:SMPL模型(动作表示),CLIP(文本编码),Jukebox(音乐编码),GPT-4o(文本分解),FlashAttention(加速)。
📌 核心摘要
- 问题:生成真实、与上下文相关的双人3D动作,需同时支持交互式(双向协调)和反应式(单向响应)两种模式,且能融合文本、音乐等多种模态条件输入,是当前计算机图形学和具身AI的挑战。
- 方法:提出DualFlow,首个基于矫正流匹配(Rectified Flow)的统一框架。通过可切换的“双流块”架构,同一模型可处理交互与反应任务;引入专为双人动作设计的检索增强生成模块,利用GPT-4o分解文本为空间关系、身体动作和节奏三类描述,并结合音乐特征检索动作范例,以增强生成动作的语义准确性;采用对比矫正流匹配目标,提升运动嵌入与条件信号的对齐度。
- 创新:(1) 统一架构实现交互与反应任务的无缝切换;(2) 首个用于双人动作的RAG框架;(3) 结合同步损失的对比矫正流匹配,提升生成质量与采样效率。
- 实验结果:在MDD、InterHuman-AS、DD100三个数据集上进行广泛评估。在MDD的交互任务上,DualFlow(Both)的R-Precision@3达0.513,MMDist为0.513;在反应任务上,FID为0.686,R-Precision@3为0.471,均优于基线。相比InterGen,DualFlow仅需20步(2.5倍加速)即可达到更优的FID。
- 意义:为VR/AR、游戏、社交机器人等需要协调人际行为的领域提供了高效且高质量的多模态动作生成方案。
- 局限:在长序列生成时可能存在节奏偏移;反应模式下可能出现轻微的肢体穿插;RAG检索质量依赖于库的覆盖度与查询的清晰度。
🏗️ 模型架构
DualFlow是一个基于Transformer和矫正流匹配的统一生成框架,其核心是多模态条件注入与“双流块”架构设计。
输入输出流程:
- 输入:文本描述(经CLIP编码)、音乐特征(经Jukebox编码)、可选的初始/引导动作序列(如反应模式下的Actor动作)。对于RAG模块,还会从预建数据库中检索与输入相关的动作范例。
- 输出:生成双人动作序列(交互模式输出两人动作,反应模式仅输出反应者动作)。
主要组件:
- 多模态检索模块:利用LLM(GPT-4o)将输入文本分解为“空间关系”、“身体动作”、“节奏”三个子描述。分别使用CLIP或Jukebox编码这些子描述和音乐特征,与动作数据库中的对应嵌入计算相似度,检索Top-K个动作范例(见公式1)。检索结果被编码并拼接为检索潜在向量
zR。 - 条件编码器:文本
d和音乐m分别通过预训练模型(CLIP,Jukebox)编码,再经Transformer编码器和线性层投影为条件潜在向量zd和zm。 - DualFlow块(核心):由N个(默认20个)级联块组成。每个块内部结构如下(见图2):
- 多尺度时间卷积:使用不同卷积核大小(步幅7,11,21)的并行1D卷积提取不同时间尺度的特征,通过可学习门控
γk融合。 - 自注意力层:建模动作序列内部的时间依赖关系。
- 音乐交叉注意力:将动作特征与音乐潜在向量
zm对齐。 - 运动交叉注意力(交互模式)/ 因果交叉注意力(反应模式):在交互模式下,此层使两人的动作特征相互关注,实现协调;在反应模式下,此层替换为带有前瞻窗口L(默认10帧)的因果交叉注意力,使反应者动作仅关注引导者动作的历史及未来L帧,实现“预判性”反应。
- 检索交叉注意力:将动作特征与检索到的范例特征
zR进行交叉注意,注入语义引导。 - 前馈网络与层归一化:文本潜在向量
zd通过自适应层归一化注入每个块。
- 多尺度时间卷积:使用不同卷积核大小(步幅7,11,21)的并行1D卷积提取不同时间尺度的特征,通过可学习门控
- 任务切换:通过输入掩码实现。交互模式下,两个分支均激活;反应模式下,引导者分支被屏蔽,仅反应者分支在因果注意力条件下生成。
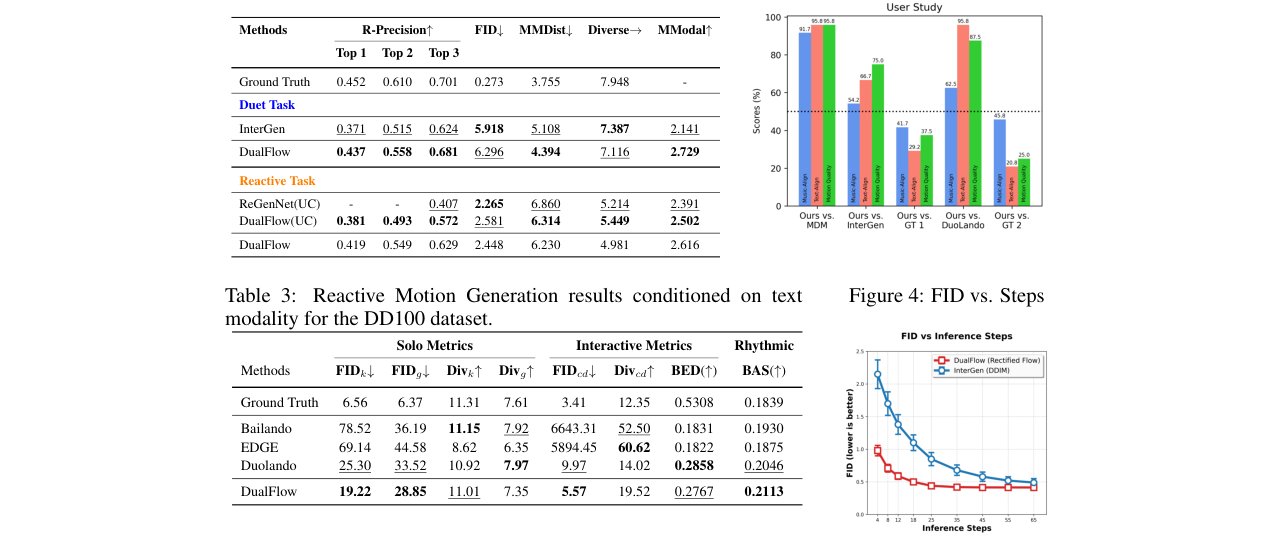
图2:DualFlow架构图。图(a)展示了整体流程,输入文本、音乐、双人动作,通过检索获取范例,经多个DualFlow块处理后输出动作。图(b)详细展示了单个DualFlow块的内部结构,包括多尺度卷积、自注意力、音乐交叉注意力、运动/因果交叉注意力和检索交叉注意力,并展示了交互和反应两种设置下的不同配置。
💡 核心创新点
- 统一的交互-反应生成架构:以往工作通常将交互式(双向协调)和反应式(单向响应)动作生成视为独立任务,使用不同模型。DualFlow通过可切换的注意力掩码机制(运动交叉注意力 vs. 因果交叉注意力+前瞻窗口),在单一模型中实现了两种模式的无缝切换,共享表征学习,提升了效率和灵活性。
- 面向双人动作的检索增强生成:首次为双人动作生成引入RAG。创新点在于使用LLM将动作文本描述结构化分解为空间关系、身体动作、节奏三个维度,并与音乐特征结合进行多方面检索。检索到的范例通过专门的交叉注意力层注入生成过程,为模型提供细粒度的交互式动作范例,显著增强了语义对齐。
- 对比矫正流匹配目标:将矫正流匹配(Rectified Flow)与对比学习相结合。矫正流匹配使生成过程为确定性的直线传输,比扩散模型采样更快更稳定。对比损失(公式3)在速度场空间中拉近语义相似动作(如共享风格、文本描述)的嵌入,推远不相似动作的嵌入,进一步强化了动作与条件信号的语义一致性。
🔬 细节详述
- 训练数据:
- 数据集:InterHuman-AS(50K+片段,文本条件),DD100(100个双人舞,音乐条件),MDD(10.3小时,文本+音乐双条件)。预处理包括使用SMPL模型表示动作为全局关节位置、速度、旋转和脚部接触(每帧262维)。
- 数据增强:未明确提及具体数据增强策略。
- 损失函数:
- 对比矫正流损失 (
L_CRF):由流匹配损失 (L_flow, 公式2) 和三元组对比损失 (L_triplet, 公式3) 加权组成,λ_triplet=0.1。 - 几何损失 (
L_geo):包括脚接触损失、关节速度损失、骨骼长度损失,λ_vel=30,λ_BL=10。 - 交互损失 (
L_inter):包括关节距离图损失、相对朝向损失,以及新增的同步损失 (L_sync, 公式6)。同步损失通过距离加权 (w_d) 和解剖学加权 (w_j) 强调关键关节对(如手、上身)的协调,λ_sync=5。 - 总损失:
L_total = L_CRF + λ_geoL_geo + λ_interL_inter。
- 对比矫正流损失 (
- 训练策略:
- 优化器:Adam,学习率
2e-4,权重衰减2e-5,1000步预热。 - 批大小:32。
- 训练轮数:5000 epochs。
- 调度:余弦β调度。
- 流匹配:使用200个积分步训练速度场
v_θ。 - 反应模式前瞻窗口:L=10帧。
- Classifier-Free Guidance:10%概率同时掩蔽文本和音乐,各20%概率单独掩蔽。
- 优化器:Adam,学习率
- 关键超参数:
- 模型深度:20个DualFlow块。
- 注意力头数:8。
- 潜在维度:512。
- 前馈网络维度:1024。
- 总参数量:456M。
- 训练硬件:未说明。
- 推理细节:
- 采样步数:20步(矫正流匹配采样),比InterGen的50步DDIM快2.5倍。
- 解码:从噪声
ε开始,沿直线路径积分到数据。 - Classifier-Free Guidance比例:未明确。
- 正则化技巧:Dropout率为0.1;所有交叉注意力层使用Flash Attention加速。
📊 实验结果
论文在三个数据集上进行了广泛的定量、定性及消融实验。
主要定量结果:
| 任务 | 数据集 | 方法 | R-Precision@1↑ | R-Precision@3↑ | FID↓ | MMDist↓ | Diversity→ | MModal↑ | BED↑ | BAS↑ | AITS(s)↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 交互 | MDD | InterGen(Both) | 0.105 | 0.302 | 0.426 | 1.532 | 1.380 | 1.352 | 0.385 | 0.185 | 1.92 |
| DualFlow(Both) | 0.185 | 0.513 | 0.415 | 0.513 | 1.392 | 1.467 | 0.286 | 0.179 | 1.24 | ||
| 交互 | InterHuman-AS | InterGen | 0.371 | 0.624 | 5.918 | 5.108 | 7.387 | 2.141 | - | - | - |
| DualFlow | 0.437 | 0.681 | 6.296 | 4.394 | 7.116 | 2.729 | - | - | - | ||
| 反应 | MDD | DuoLando(Both) | 0.078 | 0.219 | 0.698 | 2.113 | 1.371 | - | 0.395 | 0.224 | - |
| DualFlow(Both) | 0.189 | 0.471 | 0.686 | 1.056 | 1.203 | 1.473 | 0.215 | 0.226 | - | ||
| 反应 | DD100 | Duolando | - | - | 25.30 (FID_k) | - | 10.92 (Div_k) | - | 0.286 | 0.205 | - |
| DualFlow | - | - | 19.22 (FID_k) | - | 11.01 (Div_k) | - | 0.277 | 0.211 | - | ||
| 表1,表2,表3汇总:DualFlow在多个数据集和任务上,在语义对齐(R-Precision, MMDist)和生成质量(FID)等关键指标上达到或超越SOTA。在MDD交互任务中,R-Precision@3从InterGen的0.302大幅提升至0.513;在反应任务中,FID和MMDist也有显著改进。推理速度(AITS)比InterGen快约36%。 |
计算复杂度对比:图4展示了FID随采样步数的变化。InterGen需要50步才能达到较好FID,而DualFlow仅需20步即可达到更优值,体现了矫正流匹配的效率优势。
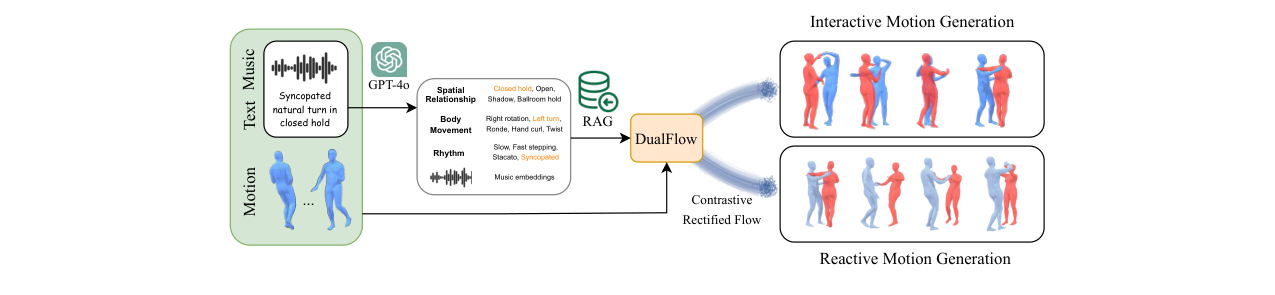
图4:不同模型FID随采样步数变化的曲线。DualFlow(20步)的FID明显低于InterGen在同等或更多步数下的FID。
消融实验(表4关键结果):
- 移除RAG(
w/o RAG):R-Precision@3从0.513降至0.498(交互),从0.471降至0.479(反应),FID升高,表明RAG对语义对齐和质量有贡献。 - 移除三元组损失(
w/o Ltriplet):R-Precision显著下降(如交互Top1从0.185降至0.158),说明对比学习对语义对齐至关重要。 - 移除同步损失(
w/o Lsync):MMDist升高(如反应从1.056升至1.112),协调性指标(BED)下降。 - 更细致的RAG消融(表7):发现交互任务中
k=5效果最佳,反应任务中k=3可能更优,且过度检索可能引入噪声。 - 同步损失消融(表8):证明了距离加权(
w_d)和解剖加权(w_j)的必要性。
定性结果:图5对比了DualFlow与基线在MDD数据集上的生成样本。
图5:定性结果对比。左侧为交互任务,右侧为反应任务。黑色圆圈标出了InterGen和DuoLando出现的问题(如手部扭曲、距离异常、旋转错误),而DualFlow生成的动作更平滑、协调,与文本描述和地面真值更匹配。
用户研究(图3):
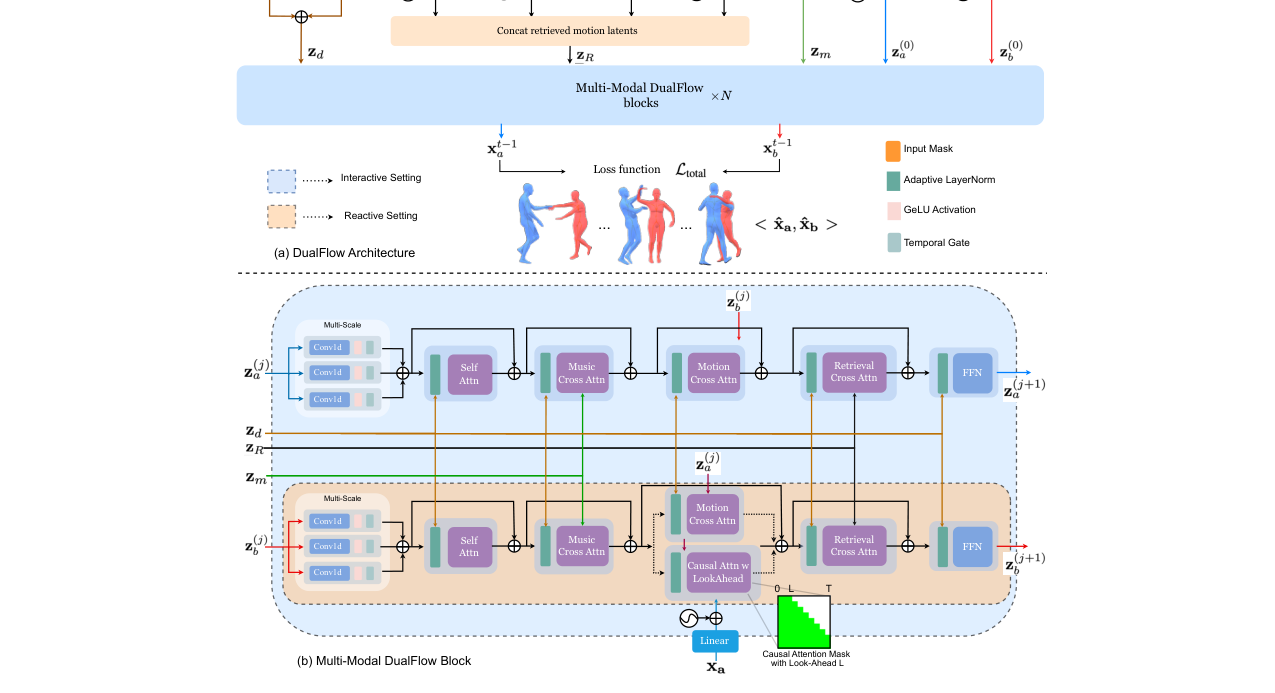
图3:用户研究结果。DualFlow在文本对齐度、节奏同步和整体质量三个维度上,均显著优于InterGen和DuoLando基线。
⚖️ 评分理由
- 学术质量:5.5/7。创新性明确:首次统一交互与反应任务,并将RAG和对比矫正流匹配创新性地应用于双人动作生成。技术实现看起来正确,架构设计合理。实验非常充分,在三个数据集上进行了定量、定性、消融和用户研究,并提供了详细的性能对比。证据可信,关键指标(如R-Precision、FID)有显著提升。扣分点在于整体创新属于增量改进而非范式颠覆,且模型参数量增大。
- 选题价值:1.0/2。选题(多模态双人动作生成)在图形学和动画领域是重要但相对细分的方向,对VR/AR、游戏有直接应用价值。然而,其与“音频/语音”读者的相关性很低,属于跨模态任务中的视觉部分。
- 开源与复现加成:1.0/1。论文明确承诺将公开全部代码和训练好的模型(B部分),并在附录中提供了详尽的训练细节、超参数配置、架构描述,复现信息非常充分。