📄 UALM: Unified Audio Language Model for Understanding, Generation and Reasoning
#统一音频模型 #音频生成 #音频问答 #自回归模型 #多模态模型
🔥 8.5/10 | 前25% | #音频生成 | #自回归模型 | #统一音频模型 #音频问答
学术质量 6.0/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jinchuan Tian(卡内基梅隆大学,NVIDIA)
- 通讯作者:未明确标注,论文指出所有作者贡献相等(Equal Contribution)
- 作者列表:
- Jinchuan Tian(卡内基梅隆大学,NVIDIA)
- Sang-gil Lee(NVIDIA)
- Zhifeng Kong(NVIDIA)
- Sreyan Ghosh(NVIDIA,马里兰大学)
- Arushi Goel(NVIDIA)
- Chao-Han Huck Yang(NVIDIA)
- Wenliang Dai(NVIDIA)
- Zihan Liu(NVIDIA)
- Hanrong Ye(NVIDIA)
- Shinji Watanabe(卡内基梅隆大学)
- Mohammad Shoeybi(NVIDIA)
- Bryan Catanzaro(NVIDIA)
- Rafael Valle(NVIDIA)
- Wei Ping(NVIDIA)
💡 毒舌点评
亮点在于首次系统性地证明了一个基于自回归语言模型的音频模型,可以通过数据缩放和特定技巧(如CFG和DPO)在生成质量上追平甚至超越扩散模型,并进一步将其扩展为能进行文本-音频联合推理的统一模型,技术路线清晰且有效。短板则在于其宣称的“统一”模型,其核心的音频理解数据集(AF3)和大规模生成数据(30M)并未公开,这使得“统一训练”和“匹配专用模型性能”的结论在独立复现层面打了折扣,更像一个强大的NVIDIA内部能力展示。
🔗 开源详情
- 代码: 提供官方GitHub仓库链接:
https://github.com/NVIDIA/audio-intelligence/tree/main/UALM。 - 模型权重: 论文未提及公开预训练或后训练的模型权重。
- 数据集: 论文未提及公开其使用的30M音频生成数据集或用于UALM-Reason后训练的富描述数据集。
- Demo: 提供在线演示网页:
https://research.nvidia.com/labs/adlr/UALM。 - 复现材料: 论文在附录中详细提供了预训练、后训练及推理的所有超参数配置(表5、6、7),并说明了代码库,为复现提供了清晰的路线图。
- 论文中引用的开源项目: Qwen2.5 LLM, X-codec, BigVGAN, LAION-CLAP, OpenL3, PaSST, PANNs, AudioBox-Aesthetics, Stable-Audio-Open, ETTA, Audio Flamingo 3等。
📌 核心摘要
该论文旨在解决音频领域中理解、生成与推理任务相互割裂的问题。其方法核心是构建一个统一的音频语言模型(UALM),该模型基于一个预训练的文本LLM,并扩展了音频输入和输出能力。论文首先通过UALM-Gen证明了自回归语言模型在大规模数据(30M样本)、分类器自由引导(CFG)和直接偏好优化(DPO)等技术的支持下,其文本到音频生成质量可达到与最先进扩散模型相当的水平。接着,通过精心设计的数据混合比例和模态对齐训练策略,将理解、生成和文本推理任务统一到单个UALM模型中,并在各项任务上匹配了专用SOTA模型的性能。最后,提出了UALM-Reason,通过引入“富描述”作为中间表示,并设计了丰富化、对话和自我反思等多模态思维链,首次在音频研究中实现了涉及文本和音频的跨模态生成推理。实验结果表明,统一的UALM在音频生成(如AudioCaps数据集FD=65.87,CL=0.62)、音频理解(MMAU均值74.1%)和文本推理任务上均表现优异。其意义在于为构建具备感知、创造与反思能力的通用音频智能体提供了可行的架构和训练范式。主要局限性在于其依赖的大规模合成数据集未公开,且“富描述”的质量评估方法有待完善。
🏗️ 模型架构
UALM的架构以解码器Transformer(初始化自Qwen2.5-7B文本LLM)为核心,扩展了音频的输入与输出能力,其整体架构如图2所示。
输入端(音频理解): 采用“编码器-适配器-LLM”的标准范式。原始音频(16kHz单声道)先由一个预训练的音频编码器(来自AF3)处理,生成帧率为25Hz的连续表示。这些表示通过一个单层的MLP适配器进行对齐,然后作为嵌入向量输入到LLM中。此设计避免了将音频离散化带来的信息损失。
输出端(音频生成): 音频生成通过预测离散的音频编解码器(Codec)令牌实现。模型使用X-codec(帧率50Hz)将音频量化为离散令牌。每个音频帧通过残差向量量化(RVQ)产生8个令牌。为提高效率,采用了延迟模式(Delay Pattern),即在自回归生成的每一步并行预测同一帧的多个RVQ层令牌。生成的16kHz单声道波形会经过一个额外的增强VAE模块,将其上采样并增强为48kHz立体声波形,以提升感知质量。
统一建模: LLM的词表被扩展以包含音频编解码器的离散令牌。在训练时,模型的损失函数仅计算在输出令牌(无论是文本还是音频)上。一个音频帧的重要性被等同于一个文本令牌,其损失按令牌数(8)进行了缩放。通过序列打包(Sequence Packing)技术处理不同长度和模态的样本,稳定训练过程。
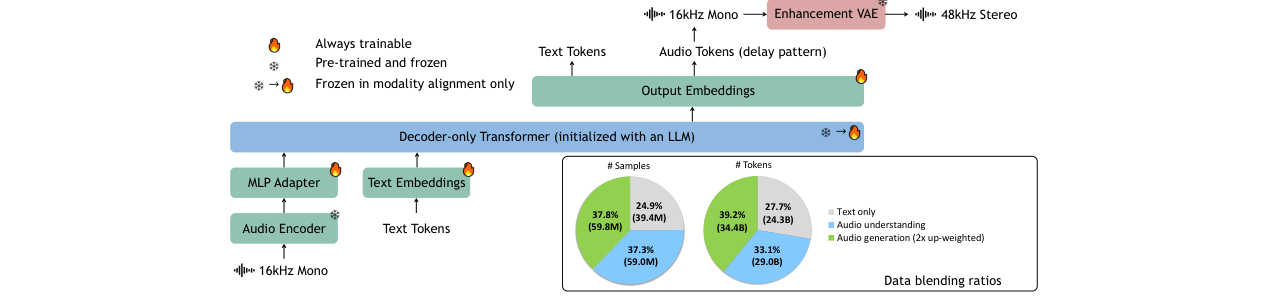
图2:UALM架构概览图。展示了从文本LLM扩展出音频输入(编码器-适配器)和输出(Codec令牌预测+增强VAE)的流程,以及多任务预训练的数据混合比例。
对于UALM-Reason,其架构核心是UALM,但通过后训练注入了生成推理能力。其关键创新在于引入了富描述(Rich Caption)作为中间表示(示例见图3),这是一种结构化的文本蓝图,包含关键词、时序布局和详细描述。模型能够执行丰富化(将简短用户提示转化为富描述)、对话(与用户交互以细化富描述)和自我反思(生成-理解-批判-再生成)等推理步骤。
💡 核心创新点
- 统一音频理解、生成与多模态推理的单模型(UALM): 这是论文最核心的贡献。之前的工作要么专注于理解(如AF3),要么专注于生成(如ETTA),而本文首次在一个自回归语言模型框架下,通过系统性的训练策略,同时实现了这三个能力,且性能不逊色于专用模型。
- 证明自回归语言模型可达到SOTA的音频生成质量(UALM-Gen): 论文系统性地挑战了“扩散模型在音频生成上优于自回归模型”的共识。通过发现并验证三个关键技术:需要比扩散模型多一个数量级的数据(30M)、必须使用分类器自由引导(CFG)、以及结合DPO进行后训练,成功使自回归模型在音频生成基准上达到了前沿水平。
- 音频领域的跨模态生成推理(UALM-Reason): 这是概念上的重大突破。论文定义了以“富描述”为核心的中间推理表示,并实现了丰富化、对话和自我反思三种推理模式。这使得模型不仅能“根据指令生成”,还能“理解模糊意图并细化”、“与用户协作创作”以及“自我批判和改进”,这是迈向更高阶音频智能的关键一步。
- 实用的多任务数据混合与训练策略: 论文详细探索了如何平衡理解、生成和文本推理任务的数据比例(生成数据2倍上采样以应对收敛慢),并设计了模态对齐阶段(仅训练适配器和嵌入)来稳定统一预训练。这些策略为训练复杂的多模态统一模型提供了有价值的实践经验。
🔬 细节详述
- 训练数据:
- 音频生成数据: 规模为30M个文本-音频对(约80k小时,17B令牌)。音频大多为10秒片段。文本描述大部分由开源的音频字幕模型(如Qwen-2.5-Omni, AF3)生成伪标签。数据来源包括Stable-Audio-Open, ETTA, AF3, AudioSetCaps。经过了去重、质量过滤(基于关键词和CLAP分数阈值0.25)。
- 音频理解数据: 与AF3相同,包含大量的推理样本。
- 文本推理数据: 包括来自数学和代码推理任务的21M样本,以及300万内部文本样本以增强常识。
- UALM-Reason后训练数据: 第一轮SFT使用250k内部富描述-音频对生成的750k样本;DPO使用60k偏好对。第二轮SFT结合第一轮数据和60k自我反思样本;DPO使用20k偏好对。
- 损失函数:
- 预训练/SFT: 标准交叉熵损失,仅作用于输出的文本或音频令牌。
- DPO损失: 公式(2)所示,优化偏好对(y_w, y_l)。在DPO训练中,会先对获胜样本进行一步交叉熵微调以稳定训练,并在DPO损失中联合优化获胜样本的交叉熵以防止模型偏离基础模型过远。
- 增强VAE损失: 由立体声MR-STFT损失、多尺度对数梅尔L1损失、LS-GAN对抗损失、特征匹配损失和KL散度正则化项组成,如公式(3)-(9)。
- 训练策略:
- UALM-Gen训练: 分两阶段。首先用交叉熵损失训练基础生成模型。然后进行DPO:先用交叉熵适应获胜样本,再进行DPO训练。
- UALM统一预训练: 分两阶段。1) 模态对齐阶段:冻结Transformer主体和音频编码器,仅更新MLP适配器和音频嵌入表,使用大批量、小步数(1.8k步)训练。2) 完整预训练阶段:解冻所有参数(除音频编码器),在混合数据上进行660k步训练,使用余弦学习率衰减和序列打包。
- UALM-Reason后训练: 采用两轮SFT-DPO课程。
- 关键超参数:
- 模型大小: UALM-Gen基于Qwen2.5-1.5B;UALM基于Qwen2.5-7B。
- 编码器/编解码器: 音频编码器帧率25Hz,滑动窗口30秒;X-codec帧率50Hz,RVQ层级n_q=8。
- CFG: 推理时使用,权重λ=3.0。
- 采样: 文本使用贪心搜索;音频使用top-k采样(k=20),温度1.0。
- 训练硬件: 预训练在16节点、每节点8张NVIDIA A100 80GB GPU的集群上进行,总计128张GPU。后训练规模较小,使用了32张或8张GPU。
- 推理细节: 如上所述,音频生成使用带CFG的top-k采样。生成的16kHz音频通过增强VAE升级为48kHz立体声。
📊 实验结果
主要实验结果表格:
表1:音频生成结果对比(关键指标)
| 模型 | 数据集 | FD↓ | KL↓ | IS↑ | CL↑ | AES↑ | OVL↑ | REL↑ |
|---|---|---|---|---|---|---|---|---|
| Ground Truth | SongDescriber | 0 | 0 | 1.88 | 0.48 | 7.20 | 4.10 | 4.03 |
| ETTA (SOTA扩散) | SongDescriber | 95.66 | 0.80 | 2.15 | 0.44 | 6.71 | 3.92 | 3.93 |
| UALM-Gen (Ours) | SongDescriber | 74.43 | 0.63 | 1.87 | 0.54 | 7.36 | 4.07 | 3.96 |
| UALM (Ours) | SongDescriber | 83.69 | 0.59 | 2.00 | 0.54 | 7.28 | 3.97 | 3.99 |
| Ground Truth | AudioCaps | 0 | 0 | 13.49 | 0.62 | 4.50 | 3.91 | 3.96 |
| ETTA (SOTA扩散) | AudioCaps | 80.13 | 1.22 | 14.36 | 0.54 | 4.51 | 3.73 | 3.94 |
| UALM-Gen (Ours) | AudioCaps | 75.14 | 1.19 | 14.52 | 0.65 | 5.08 | 3.79 | 3.92 |
| UALM (Ours) | AudioCaps | 65.87 | 1.35 | 15.62 | 0.62 | 4.92 | 3.89 | 3.86 |
| 注:FD越低越好,IS/CL/AES/OVL/REL越高越好。OVL/REL为5分制主观评分,95% CI ≈0.10。 | ||||||||
| 结论:UALM-Gen和UALM在多个客观指标(FD, CL, AES)上优于或匹配SOTA扩散模型ETTA。主观评分(OVL, REL)也具有竞争力。 |
表2:音频理解结果对比
| 模型 | 基础模型 | MMAU Sound↑ | Music↑ | Speech↑ | Mean↑ | MMAR Mean↑ |
|---|---|---|---|---|---|---|
| Audio Flamingo 3 | Qwen2.5 (7B) | 76.7 | 73.3 | 64.9 | 72.3 | 58.5 |
| Qwen2.5-Omni | Qwen2.5 (7B) | 76.8 | 67.3 | 68.9 | 71.0 | 56.7 |
| UALM (Ours) | Qwen2.5 (7B) | 77.9 | 77.6 | 66.7 | 74.1 | 55.2 |
| 结论:UALM在MMAU基准上取得了74.1%的平均准确率,超越了Audio Flamingo 3(72.3%)和Qwen2.5-Omni(71.0%),表明统一预训练未损害理解能力。 |
表3:文本能力对比
| 模型 | MMLU↑ | GSM8K↑ | HumanEval↑ | Mean↑ |
|---|---|---|---|---|
| Qwen2.5-7B-Instruct | 74.5 | 91.6 | 84.8 | 83.6 |
| UALM (Ours) | 71.6 | 92.1 | 81.1 | 81.6 |
| 结论:UALM相比其基座LLM(Qwen2.5-7B-Instruct)在文本任务上仅有轻微下降,证明其文本推理能力在多模态训练中得到了很好保持。 |
消融实验与分析:

图5:消融实验结果。a) CFG权重对CLAP分数的影响;b) 数据量缩减对CLAP分数的影响;c) DPO训练是否先适应合成数据对损失的影响;d) DPO中是否加入交叉熵正则项对模型偏移的影响。
- CFG的必要性(图5a): 不使用CFG时生成质量严重下降,λ=3.0为最优。
- 数据缩放(图5b): 数据量缩减至1/32时,CLAP分数大幅下降并出现过拟合,证明了大规模数据对自回归生成模型至关重要。
- DPO训练技巧(图5c,5d): 直接对合成数据进行DPO会导致损失飙升和性能下降。必须先进行一个适应阶段(用交叉熵微调获胜样本),并在DPO损失中加入获胜样本的交叉熵项,以稳定训练。

图6:统一预训练过程中,音频理解(a)和生成(b)能力随训练步数的变化。图中显示理解能力收敛远快于生成能力。
多模态推理评估(表4):
| 模型 | 丰富化 | 对话 | 自我反思 |
|---|---|---|---|
| UALM | 3.77 ± 0.11 | 3.92 ± 0.11 | 3.82 ± 0.11 |
| UALM-Reason | 4.01 ± 0.10 | 4.02 ± 0.10 | 4.04 ± 0.09 |
| 结论:在丰富化、对话和自我反思三种推理场景的主观评估中,UALM-Reason的得分均显著高于基础UALM模型,证明了多模态推理后训练的有效性。 |
⚖️ 评分理由
- 学术质量:6.0/7。论文创新性强,提出了统一音频多任务模型和生成推理的新范式。技术方案(数据缩放、CFG、DPO)的选择和验证过程扎实。实验设计全面,覆盖了生成、理解和推理的多个基准,并进行了细致的消融实验。主要不足在于关键数据集未公开,使得核心结论的完全复现依赖于作者的数据;此外,对于“推理”能力的定量评估仍较依赖主观打分。
- 选题价值:2.0/2。统一音频感知、生成与推理是该领域的核心目标和前沿方向,具有极高的研究价值和长期影响力。论文成功探索了这一方向并给出了有说服力的解决方案。
- 开源与复现加成:0.5/1。论文提供了代码链接和详尽的训练配置,复现友好。扣分点在于核心模型权重和大规模训练数据集均未公开,这严重影响了社区的独立验证和在此基础上的快速迭代。