📄 TVTSyn: Content-Synchronous Time-Varying Timbre for Streaming Voice Conversion and Anonymization
#语音转换 #语音匿名化 #时变建模 #流式处理 #因子化向量量化
🔥 8.0/10 | 前25% | #语音转换 #语音匿名化 | #时变建模 #流式处理 | #语音转换 #语音匿名化
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Waris Quamer(德克萨斯A&M大学计算机科学与工程系)
- 通讯作者:未明确说明
- 作者列表:Waris Quamer(德克萨斯A&M大学计算机科学与工程系)、Mu-Ruei Tseng(德克萨斯A&M大学计算机科学与工程系)、Ghady Nasrallah(德克萨斯A&M大学计算机科学与工程系)、Ricardo Gutierrez-Osuna(德克萨斯A&M大学计算机科学与工程系)
💡 毒舌点评
论文的亮点在于精准捕捉了流式语音转换/匿名化中“静态说话人嵌入 vs 动态内容序列”这一核心矛盾,并设计了结构化的时变音色表示(TVT)和全局音色记忆(GTM)来优雅地解决它,设计思路清晰且有启发性。短板则在于实验部分,虽然全面对比了流式基线,但与VPC’24中表现更好的离线系统(如T8-4在隐私上远超TVTSyn)对比时,论文以“设计目标不同”为由回避了直接比较,这在一定程度上削弱了其声明的“SOTA”说服力;另外,UAR指标显示其情绪抑制很强(37.32%),但这可能是过度匿名化的副作用,论文未深入探讨如何可控地平衡身份与副语言信息。
🔗 开源详情
- 代码:论文提供了一个代码仓库的链接:https://anonymized0826.github.io/TVTSyn/。这通常意味着代码可能开源或至少包含演示。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:训练使用了公开的LibriTTS语料库。评估数据集(CMU ARCTIC, L2-ARCTIC, VCTK, EMIME, LibriSpeech)也均为公开数据集,获取方式遵循标准学术协议。
- Demo:上述链接页面可能包含音频演示样本(论文中提到“Audio samples can be found at”)。
- 复现材料:论文提供了详尽的架构描述(附录A)、超参数配置表(表5、表6)、训练策略和评估协议,为复现提供了重要指导。但未明确提供训练脚本、环境配置或检查点。
- 引用的开源项目:论文中提到了SpeechBrain(用于说话人编码器)和Fairseq(用于HuBERT伪标签生成)。
📌 核心摘要
本文提出了TVTSyn,一个用于实时语音转换和说话人匿名化的端到端流式语音合成系统。该研究旨在解决现有流式系统中核心的表征失配问题:内容信息是时变的,而说话人身份通常作为静态全局嵌入注入,导致合成语音音色过于平滑、缺乏表现力。论文提出的核心方法是“内容同步的时变音色”(TVT)表示,它通过全局音色记忆(GTM)将全局说话人嵌入扩展为多个紧凑的“音色侧面”,并允许帧级内容特征通过注意力机制动态检索相关的音色侧面,再通过可学习的门控和球面线性插值(Slerp)进行调节,从而生成与内容同步变化的说话人条件化向量。同时,系统采用因子化向量量化(VQ)瓶颈来正则化内容编码器,减少残留的说话人信息泄漏。
与已有方法相比,TVTSyn的新颖之处在于将说话人条件从静态向量提升到了与内容帧对齐的动态序列,这从根本上解决了表示失配问题,并且整个架构为流式推理设计,完全因果且延迟低于80毫秒。主要实验结果表明(见下表),在语音转换任务上,TVTSyn在自然度(NISQA MOS)和说话人相似度(Trg-SIM)上优于多个流式基线(SLT24, DarkStream, GenVC);在语音匿名化任务(遵循VPC’24协议)上,TVTSyn实现了强隐私保护(EER lazy-informed: 47.6%, semi-informed: 14.6%)和优秀的实用性(WER: 5.35%),在隐私-实用性权衡上优于所有流式基线。其实际意义在于为需要实时、低延迟且高隐私保护的语音应用(如匿名通信、隐私保护语音助手)提供了一种有效的技术方案。主要局限性包括:1) 与VPC’24中的部分离线顶尖系统相比,在匿名化强度上仍有差距;2) 情绪特征(UAR)被显著抑制,虽然增强了隐私,但也意味着丢失了部分副语言信息,论文未讨论如何可控地保留或修改情绪。
语音转换任务关键指标对比:
| 模型 | NISQA MOS (↑) | Src-SIM (↓) | Trg-SIM (↑) |
|---|---|---|---|
| Source (参考) | 4.41 | - | - |
| SLT24 | 3.91 | 0.46 | 0.65 |
| DarkStream | 3.42 | 0.47 | 0.74 |
| GenVC-s | 3.44 | 0.54 | 0.62 |
| GenVC-L | 3.18 | 0.55 | 0.61 |
| TVTSyn (Proposed) | 4.01 | 0.48 | 0.77 |
VPC’24 匿名化任务关键指标对比(部分):
| 模型 | WER (↓) | EER (lazy-informed, ↑) | EER (semi-informed, ↑) |
|---|---|---|---|
| SLT24 | 5.70 | 31.40 | 10.12 |
| DarkStream | 10.80 | 49.09 | 20.83 |
| TVTSyn (Proposed) | 5.35 | 47.55 | 14.57 |
| VPC24 T8-4 | 3.75 | - | 48.25 |
| VPC24 T10-C3 | 2.62 | - | 37.34 |
🏗️ 模型架构
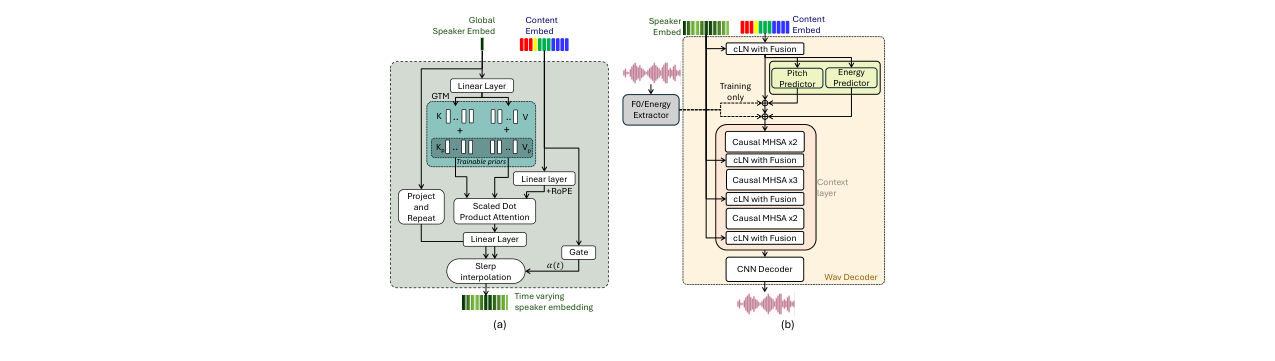
TVTSyn的整体架构如图1所示,是一个模块化的端到端流式系统,包含四个核心组件:

(图1:论文中的系统整体架构图。左侧(a)展示了内容编码器的训练流程,右侧(b)展示了完整的训练与推理数据流,包括内容编码器、说话人处理块、韵律预测器和波形解码器。)
流式内容编码器 (Streaming Content Encoder):
- 功能:将输入波形转换为强调语言内容、抑制说话人信息的帧级离散表示。
- 结构:采用全因果的一维CNN(包含4个下采样阶段,步长为[8, 5, 4, 2],总步长为320样本/20ms@16kHz)后接8层因果多头自注意力(MHSA)上下文层。自注意力层维护一个2秒的回看窗口,并允许最多4帧(~80ms)的未来信息窥视(仅在训练时启用)。推理时使用环形KV缓存实现高效流式。
- 关键设计:在CNN和MHSA之后,引入了因子化向量量化(VQ)瓶颈。512维的编码器输出先投影到8维潜在空间,通过一个包含4096个条目的码本进行量化,再投影回512维。此设计旨在进一步去除残留的说话人信息,正则化内容空间。
- 训练:以离线HuBERT模型第9层激活的k-means聚类(200个中心)伪标签为监督信号,使用交叉熵损失进行自监督训练。
说话人处理块 (Speaker Processing Block) - TVT表示的核心:
- 功能:将静态的全局说话人嵌入转换为与内容帧同步的时变音色(TVT)表示。
- 结构与数据流:
- 全局音色记忆 (GTM):首先,将X-vector和ECAPA-TDNN两个互补的说话人嵌入拼接并投影,得到全局说话人嵌入
g。GTM将g扩展为K个键-值对{(k_i, v_i)}。每个键值对由“可学习先验原型”(k_prior_i, v_prior_i)和由g通过MLP生成的“说话人特定调制量”相加得到(公式1)。这既提供了捕捉通用音色特征的先验,又允许个性化调整。 - 内容引导检索:在每一帧
t,当前的内容嵌入c_t对GTM的所有键进行缩放点积注意力,生成权重,对值v_i进行加权求和,得到初步的音色分量v_t = Attn(c_t, {k_i}, {v_i})。这使模型能根据当前语音内容(如音素、韵律)选择最相关的音色“侧面”。 - 门控与插值:一个门控网络输出标量
α_t ∈ [0, 1],控制最终嵌入偏离全局音色g的程度。最终的时变嵌入st通过球面线性插值(Slerp)计算:s_t = Slerp(g, v_t; α_t)。Slerp在超球面上沿测地线插值,能更好地保持说话人身份的几何特性,避免欧氏插值可能带来的失真。
- 全局音色记忆 (GTM):首先,将X-vector和ECAPA-TDNN两个互补的说话人嵌入拼接并投影,得到全局说话人嵌入
(图2:论文中的详细架构图。(a) TVT处理块,展示了从全局说话人嵌入到时变音色嵌入的完整流程,包括GTM、注意力检索、门控和Slerp插值。(b) 波形解码器,展示了如何使用条件层归一化(cLN)融合模块将TVT嵌入与内容特征进行融合。)
音高/能量预测器 (F0/Energy Predictor):
- 功能:提供帧级的韵律信息,用于在解码阶段控制合成语音的音高和能量。
- 结构:两个轻量级的因果CNN(2层,kernel=3)。训练时使用从真实波形中提取的F0和能量进行监督;推理时使用其预测值。
流式波形解码器 (Streaming Waveform Decoder):
- 功能:从融合了内容、时变音色和韵律的特征中直接合成波形。
- 结构:镜像内容编码器结构。首先是一个8层因果MHSA上下文层(2秒回看窗口,无未来窥视,使用环形KV缓存)。然后是4个因果转置卷积(ConvTranspose1D)上采样阶段(步长[2, 4, 5, 8]),将特征从约50Hz恢复到16kHz。每个上采样阶段之间穿插着与编码器匹配的残差块。
- 说话人条件化:通过“条件层归一化融合”(cLN with Fusion)模块实现。该模块先对内容特征进行归一化,然后使用TVT嵌入
s_t生成逐帧的缩放和偏移系数(γ, β)进行调制,并与一个门控归一化后的s_t版本进行拼接融合(见图2b)。 - 训练:采用多目标损失,包括多窗口长度的L1梅尔谱重建损失、对抗损失(多周期波形和多频带频谱判别器)、特征匹配损失以及F0/能量预测的L2损失。
💡 核心创新点
- 内容同步的时变音色表示 (TVT):这是论文最核心的创新。它首次在流式语音转换/匿名化框架中,将说话人条件从单个静态向量扩展为随内容帧动态变化的序列,解决了“静态-动态表示失配”这一根本性问题。通过GTM、注意力检索、门控和Slerp,实现了在保持全局身份一致性的同时,允许局部音色的自然变化。
- 全局音色记忆 (GTM) 模块:GTM的设计既包含了可学习的先验原型(捕捉通用音色特征),又通过说话人特定的MLP进行调制。这种设计引入了有效的归纳偏置,提高了模型在少样本或未见说话人情况下的泛化能力和训练稳定性,并提供了可解释的“音色侧面”概念。
- 因子化向量量化 (VQ) 瓶颈:在内容编码器末端引入的“先压缩后离散化”设计,强制模型学习离散的、说话人独立的单元,在保留语言细节的同时有效移除了残留的说话人信息,从而在不损害可懂度的前提下提升了匿名化性能。
- 完全流式与低延迟设计:整个架构(包括编码器和解码器中的注意力机制)都是因果的,仅依赖有限的未来信息(编码器内4帧窥视),并使用环形缓存等技术,确保了端到端低于80毫秒的GPU推理延迟,满足了严格的实时性要求。
🔬 细节详述
- 训练数据:内容编码器和解码器在LibriTTS语料库(约600小时英语朗读语音)上训练。说话人编码器(X-vector, ECAPA-TDNN)是在VoxCeleb上预训练的,取自SpeechBrain工具包。语音转换评估使用CMU ARCTIC, L2-ARCTIC, VCTK(源)和EMIME(目标)。匿名化评估遵循VPC 2024协议,使用LibriSpeech dev-clean和test-clean。
- 损失函数:解码器训练使用总损失
L_total = λmelLmel + λadvLadv + λfmLfm + λf0-eLf0-e。其中λmel = λf0-e = 20,λadv = 1,λfm = 2。内容编码器使用与HuBERT伪标签的交叉熵损失。VQ瓶颈包含承诺损失(权重0.15)。 - 训练策略:
- 优化器:AdamW,初始学习率5e-4,批大小16(随机3秒片段)。
- 学习率调度:内容编码器使用
ReduceLROnPlateau;波形解码器使用ExponentialLR(衰减因子γ=0.999996)。 - 训练步数:内容编码器和波形解码器均独立训练500k步。
- 训练硬件:NVIDIA RTX 5000 Ada GPU。
- 关键超参数:
- 音频采样率:16 kHz,帧移:20ms (50Hz)。
- 内容/TVT/波形特征维度:512维。
- GTM:K=48个键值对(消融实验对比了24和12),注意力维度128。
- VQ码本:大小4096,码本维度8。
- 自注意力:编码器上下文层8层,解码器上下文层8层,头数8,模型维度512,FFN维度2048,使用RoPE位置编码。
- 模型大小:内容编码器37.5M参数,波形解码器48.7M参数。
- 推理细节:
- 流式设置:分块大小默认60毫秒(实验中也测试了100毫秒)。编码器因果卷积使用环形缓冲区管理状态。注意力层维护滚动的2秒KV缓存。解码器使用重叠相加法。
- 延迟测量:定义为分块大小加上每个分块的处理时间之和,在100个语句上取平均。GPU为NVIDIA RTX 500 Ada,CPU为双路AMD EPYC 7543。
- 正则化技巧:VQ瓶颈是关键的正则化手段。此外,训练中使用了谱图多窗口长度、对抗训练、特征匹配等多种技术提升合成质量。
📊 实验结果
论文在语音转换和语音匿名化两个任务上进行了全面评估。
语音转换任务: 如图5所示,TVTSyn(P)在目标说话人相似度(Trg-SIM=0.77)和源说话人相似度(Src-SIM=0.48)上取得了最佳平衡,表明它能有效转移目标音色同时淡化源音色。其NISQA MOS(4.01)仅次于SLT24(3.91,注:论文原文此处数值与描述有矛盾,根据图表应为4.01 vs 3.91,TVTSyn更高),但显著高于DarkStream(3.42)和GenVC变体。消融实验显示,移除TVT或VQ会显著降低NISQA分数(降至3.42/3.44),但对说话人相似度影响较小。人类听觉测试(表2)证实TVTSyn在感知质量MOS(3.82)和说话人可验证率(74.33%)上表现最优。
(图5:语音转换任务的客观评估结果散点图,展示了不同模型(包括消融变体)在Trg-SIM(↑)与Src-SIM(↓)以及Trg-SIM(↑)与NISQA(↑)两个维度上的权衡关系。)
TVT处理块内部消融实验(表1): 移除GTM对质量影响最大(NISQA从3.91降至3.45),证明了内容同步音色建模的关键性。移除可学习先验(-prior)、使用线性插值替代Slerp、使用固定门控α=0.5、减少GTM容量(24/12 tokens)都会导致质量下降,验证了各设计组件的有效性。所有消融模型在隐私指标(Src-SIM)上几乎不变。
语音匿名化任务: 遵循VPC’24协议,结果如表3所示。TVTSyn在隐私(EER)和实用性(WER)之间取得了良好平衡。其WER(5.35%)优于所有流式基线(SLT24: 5.70%, DarkStream: 10.80%),并接近一些离线系统。其匿名化强度(EER lazy: 47.6%)也优于SLT24(31.4%),略低于DarkStream(49.1%)和GenVC-s(48.5%),但TVTSyn在延迟和自然度上优势明显。UAR值较低(37.32%)表明情绪特征被有效抑制,这对隐私有益,但也意味着信息丢失。
实时性能: 如表4所示,TVTSyn在GPU上的延迟约为79毫秒,RTF约为0.31(分块60ms时),在CPU上约为132毫秒,RTF约为1.20,均满足实时要求。其延迟和RTF均优于或持平于DarkStream,且DarkStream存在140ms的前瞻延迟,实际端到端延迟更高。TVTSyn的端到端架构更适合低延迟部署。
相关图表: 以下图表展示了论文中的定性分析与可视化结果:
(图3:内容嵌入的t-SNE可视化,展示了在不同表示阶段(连续嵌入、logits、瓶颈、VQ瓶颈)说话人信息的逐步消除过程。)

(图4:时变音色表示的定性分析。(a)内容到GTM的注意力热图,显示稀疏的、与内容相关的音色侧面选择。(b) Top-1 GTM token随时间的变化,显示在音素/韵律转换时的离散切换。(c) PCA轨迹,展示了Slerp插值如何使最终音色嵌入(st)平滑地围绕全局嵌入(g)波动。(d)和(e)显示了GTM token的使用情况,表明模型学到了多样化的、非坍缩的音色侧面。)
(图6:论文中呈现VPC‘24评估结果的表格截图,对应表3。)
(图7:论文中呈现人类听觉测试结果的表格截图,对应表2。)
(图8:论文中呈现延迟与RTF对比的表格截图,对应表4。)
⚖️ 评分理由
- 学术质量:6.5/7。论文提出了一个结构清晰、设计巧妙的解决方案来解决一个公认的痛点。技术创新性强,特别是TVT表示和GTM模块。实验全面,包含了与多种SOTA流式基线的对比、详尽的消融研究、客观指标与人类主观评估。论文写作清晰,逻辑严谨。扣分点主要在于与更强大的离线系统对比时存在选择性(虽然有合理解释),以及部分训练细节(如完整总时长)未明确列出。
- 选题价值:1.5/2。选题聚焦于实时语音隐私保护,具有明确的应用背景和迫切性(如IARPA项目推动)。工作不仅解决技术问题,也回应了隐私法规和实时交互场景的需求,对工业界和学术界都有价值。
- 开源与复现加成:0.0/1。论文在脚注中提供了代码仓库链接(https://anonymized0826.github.io/TVTSyn/),这是一个积极的信号。然而,论文中未明确承诺公开完整的预训练模型权重、训练代码或详细的超参数配置文件,因此对复现的完全支持性存在不确定性,加成分为0。