📄 TripleSumm: Adaptive Triple-Modality Fusion for Video Summarization
#多模态模型 #音视频 #自注意力 #端到端 #基准测试
🔥 8.5/10 | 前25% | #视频摘要 | #多模态模型 | #音视频 #自注意力
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Sumin Kim(首尔大学), Hyemin Jeong(首尔大学), Mingu Kang(首尔大学)(表示同等贡献)
- 通讯作者:Yoori Oh†(首尔大学), Joonseok Lee†(首尔大学)(†表示通讯作者)
- 作者列表:Sumin Kim(首尔大学), Hyemin Jeong(首尔大学), Mingu Kang(首尔大学), Yejin Kim(首尔大学), Yoori Oh(首尔大学), Joonseok Lee(首尔大学)
💡 毒舌点评
论文提出了一个设计精巧的多模态视频摘要模型TripleSumm,其自适应帧级融合机制和引入的大规模三模态数据集MoSu是扎实的贡献,显著推动了视频摘要领域的多模态研究。然而,其核心创新点(自适应注意力融合)在多模态学习中并非前所未见,且在标准小数据集(SumMe/TVSum)上的绝对性能提升幅度有限,新数据集的“Most Replayed”监督信号本身的普适性也有待更广泛验证。
🔗 开源详情
- 代码:论文提供了GitHub代码仓库链接:
https://github.com/smkim37/TripleSumm。 - 模型权重:论文中未明确提及是否公开预训练模型权重。
- 数据集:MoSu数据集已公开,论文提供了获取方式。
- Demo:论文中未提及在线演示。
- 复现材料:论文在附录中提供了非常详细的超参数设置(表I)、摘要生成算法、数据预处理细节、评估协议说明以及各种消融实验的配置,复现信息充分。
- 论文中引用的开源项目:依赖了预训练模型CLIP、RoBERTa、AST以及用于生成文本描述的Qwen2.5-VL。
📌 核心摘要
- 要解决什么问题? 现有视频摘要方法通常采用静态或模态无关的融合策略,无法动态捕捉不同视频帧中视觉、文本和音频模态重要性的变化,导致理解复杂视频能力不足。同时,缺乏包含三模态特征的大规模基准数据集也阻碍了该领域的发展。
- 方法核心是什么? 论文提出了TripleSumm架构,其核心包括:a) 多尺度时间块,采用层次化的滑动窗口自注意力,从局部到全局捕捉视频的时序模式;b) 跨模态融合块,使用一个中性的“融合令牌”作为查询,动态地对三种模态的特征进行加权聚合,实现帧级别的自适应融合。
- 与已有方法相比新在哪里? 相比于现有模态静态或简单融合的方法,TripleSumm在帧级别动态地学习并分配各模态的权重。此外,论文首次提出了大规模、三模态的视频摘要基准数据集MoSu。
- 主要实验结果如何? TripleSumm在四个基准测试上均达到了SOTA性能。在提出的MoSu数据集上,其Kendall‘s τ和Spearman’s ρ分别达到0.351和0.472,大幅超越次优方法CFSum(0.277/0.374)。在Mr. HiSum,SumMe(TVT)和TVSum(TVT)数据集上,其全模型版本也均取得最优或并列最优的相关性指标。消融实验证实了三模态输入、层次化窗口和自适应融合机制的有效性。
- 实际意义是什么? 该工作推动了视频摘要向更符合人类多模态感知的方向发展,提出的MoSu数据集和TripleSumm模型为未来研究提供了可靠的基础和强大的基线,有助于从海量视频中高效提取关键信息。
- 主要局限性是什么? 论文指出,当前遵循的“帧重要性评分-分割-选择”流程并非端到端可训练,未来可探索直接学习选择连贯摘要片段的端到端模型。此外,数据集的监督信号基于聚合的“Most Replayed”数据,可能无法完全反映个体或多样化的用户需求。
🏗️ 模型架构
TripleSumm是一个用于视频摘要的端到端多模态模型,其整体架构如图2所示。其设计核心是将时序建模与跨模态融合解耦,并逐层进行“精炼-融合”的迭代处理。
完整输入输出流程:
- 输入:输入为经过预处理的视觉(V)、文本(T)、音频(A)三模态特征序列。
- 特征编码与对齐:使用预训练的编码器(如CLIP, RoBERTa, AST)提取各模态特征(公式1)。然后通过线性投影和层归一化,将它们映射到共同维度D的嵌入空间(公式2)。同时,通过平均聚合创建一个跨模态“融合令牌”嵌入(Ef)。最后,为所有嵌入添加时间位置编码(TPE)和可学习的模态嵌入(LME)以区分类别(公式3)。
- 交替精炼与融合:堆叠L层交替的“多尺度时间块”和“跨模态融合块”。
- 预测与输出:经过精炼的融合特征(Hf_CMF)通过预测头,输出每帧的重要性分数(S),最终通过分割和选择生成摘要视频。
主要组件详解:
- 多尺度时间块:此模块负责在每个模态内部独立进行时序建模。其核心是窗口化自注意力,限制注意力范围在以当前帧为中心的窗口w内,将复杂度从O(N²)降至O(wN)。“多尺度” 通过逐层增大窗口尺寸实现:早期层使用小窗口捕捉帧间细微变化,后期层使用大窗口乃至全局窗口捕捉长程依赖和整体叙事(如图2中MST模块所示)。
- 跨模态融合块:此模块负责在每个时间点独立进行跨模态交互。它将融合令牌(hf_i)作为查询(Query),将同时刻的三种模态特定令牌(hv_i, ht_i, ha_i)作为键(Key)和值(Value),通过交叉注意力机制动态计算并聚合信息(公式5-6)。这种设计使模型能够自由选择、加权当前帧最相关的模态信息,而不偏向任何特定模态。
关键设计选择:
- 分离式设计:将时序精炼(MST)和跨模态融合(CMF)完全分离到不同模块中,使得每个模块专注于学习一种正交模式,同时便于并行计算。
- 中性融合令牌:作为跨模态融合的查询,其初始状态是三种模态的简单平均,避免了以某一特定模态(如视觉)为中心查询可能引入的偏差。
- 参数共享:多尺度时间块在所有模态间共享参数,这不仅显著减少了参数量(约3倍),还让模型能从更多样的数据中学习通用的时序模式。

💡 核心创新点
自适应帧级多模态融合机制:
- 是什么:通过“跨模态融合块”和“融合令牌”,在视频的每一帧动态计算并分配视觉、文本、音频三种模态的权重,从而自适应地聚合最相关的信息。
- 局限与创新:之前的方法或使用固定权重(静态融合),或简单拼接/拼接,或以单一模态为中心进行注意力计算。TripleSumm的设计允许模型根据内容实时、自由地调整对不同模态的依赖,更符合人类理解视频时注意力随场景内容变化的认知过程。
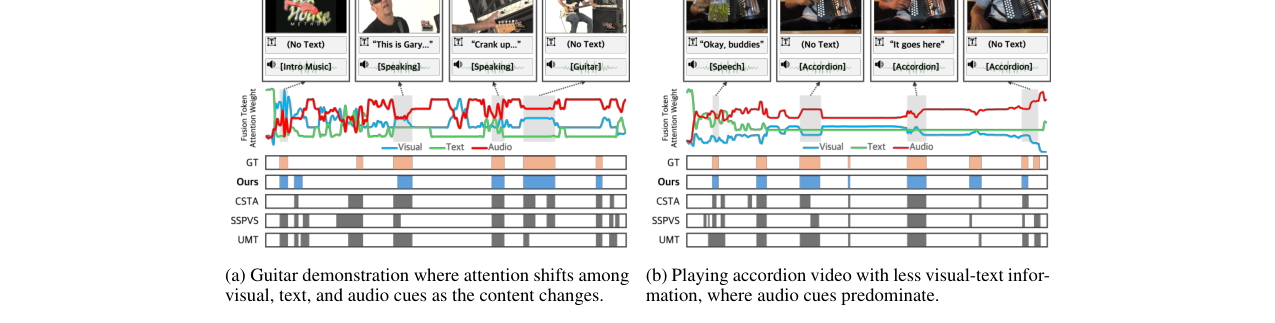
- 收益:消融实验(表4d)证实,“动态”融合显著优于“静态”和“全局”权重方法。在图3的定性分析中,模型能根据吉他演示、手风琴演奏等不同内容,正确分配对音频、视觉或文本的注意力,即便模态缺失也能稳健预测。
多尺度时间块:
- 是什么:采用层次化递增的窗口大小(如从5到N)进行窗口化自注意力,从局部到全局逐步捕捉时序信息。
- 局限与创新:标准自注意力计算量大,且固定窗口可能无法同时捕捉微细动作和宏观剧情。该设计通过渐进式扩大感受野,兼顾了效率与多粒度时序特征建模的需求。
- 收益:消融实验(表4b,表VI)表明,“由窄到宽”的策略(Local-to-Global)优于固定窗口或“由宽到窄”的策略,在保持计算效率的同时取得了最佳性能。
大规模三模态视频摘要数据集MoSu:
- 是什么:首个大规模提供视觉、文本、音频三模态特征的视频摘要数据集,包含52,678个来自YouTube-8M的视频,标注基于“Most Replayed”统计。
- 局限与创新:现有数据集(如SumMe, TVSum)规模极小且缺乏模态,或仅有视觉和文本(如MMSum)。MoSu填补了三模态、大规模、多样性基准的空白,为该领域的研究提供了可靠基础。
- 收益:在MoSu上的实验(表2)清晰地展示了多模态方法的优势,且该数据集的有效性通过迁移学习实验(表3中Ours(MoSu)行)得到了验证。
🔬 细节详述
- 训练数据:
- 主要数据集:MoSu(52,678视频,约4000小时),从YouTube-8M筛选,需满足有英文字幕、有音频、观看量>5万、时长>120秒的条件。
- 其他数据集:在外部基准测试中使用了Mr. HiSum(31,892视频), SumMe(25视频), TVSum(50视频)。对于没有文本/音频的基准,使用Qwen2.5-VL生成帧级文本描述,直接提取原始音频。
- 预处理:视觉特征:1 fps采样,CLIP编码(768维)。文本特征:提取带时间戳的转录,用RoBERTa编码句子级[CLS]向量并广播至对应时间段,无文本帧用默认向量填充。音频特征:以1秒间隔,取中心10秒音频段,用AST编码(768维)。
- 损失函数:预测帧分数向量与真实重要性分数向量之间的平方L2损失(公式7):$L(S, \hat{S}) = |S - \hat{S}|_2^2$。
- 训练策略:
- 优化器:AdamW。
- 学习率:初始$1 \times 10^{-4}$,使用余弦调度器。
- 批大小:64。
- 训练轮数:100 epochs。
- 数据划分:MoSu和Mr. HiSum使用官方划分。SumMe和TVSum使用5折交叉验证,论文中评估了传统的TV划分和更严格的TVT划分。
- 关键超参数:
- 模型架构:嵌入维度D=128。交错层数L=2,其中每层包含P=2个多尺度时间块和Q=2个跨模态融合块。注意力头数为4。预测头隐藏维度192。
- 窗口尺寸:采用Local-to-Global策略,4个时间块的窗口尺寸w依次为:5, 15, 45, N(全局)。
- Dropout:0.1。
- 训练硬件:所有实验在单块NVIDIA RTX A100 GPU上进行。
- 推理细节:
- 重要性评分:模型输出帧级分数$\hat{S}$。
- 摘要生成:使用核时序分割(KTS)将视频分割为连贯片段,计算每个片段的平均分数。然后在给定时长预算(如原始视频的15%)下,通过0/1背包问题选择总分最高的片段集合,按时间顺序拼接生成最终摘要。
- 正则化技巧:使用了层归一化(LN)和Dropout。
📊 实验结果
论文在多个基准上进行了广泛的实验,包括新提出的MoSu、大规模的Mr. HiSum以及经典的人工标注数据集SumMe和TVSum。
- MoSu数据集上的性能对比(表2)
方法 模态 τ ↑ ρ ↑ mAP50 ↑ mAP15 ↑ 参数量 ↓ GFLOPs ↓ VASNet V 0.151 0.219 64.49 31.05 8.13M 1.99G PGL-SUM V 0.151 0.218 64.97 30.63 5.31M 1.21G CSTA V 0.291 0.398 71.77 40.65 10.56M 11.37G A2Summ V, T 0.181 0.257 66.48 35.70 2.48M 1.35G UMT V, A 0.239 0.334 68.83 36.73 4.66M 1.39G CFSum V, T, A 0.277 0.374 70.97 38.20 19.83M 8.52G TripleSumm (Ours) V, T, A 0.351 0.472 74.72 44.42 1.37M 0.97G
结论:TripleSumm在所有指标上大幅超越现有方法,且参数效率极高(仅1.37M参数)。
- 外部数据集性能对比(表3)
数据集 方法 TVT TV TVT TV τ ρ τ ρ Mr. HiSum Ours (Visual) 0.187 0.258 - - Ours (Full) 0.258 0.352 - - SumMe CSTA 0.133 0.148 0.246 0.274 Ours (Full) 0.198 0.259 0.211 0.275 Ours (MoSu) 0.200 0.262 0.217 0.282 TVSum CSTA 0.168 0.221 0.194 0.255 Ours (Full) 0.198 0.259 0.211 0.275 Ours (MoSu) 0.200 0.262 0.217 0.282
结论:TripleSumm在Mr. HiSum上达到SOTA。在SumMe和TVSum上,全模型版本在严格的TVT划分下表现最佳,预训练在MoSu上(Ours(MoSu))可进一步提升在传统TV划分下的性能,证明了模型的迁移能力。
- 消融实验(表4)
- 模态组合(表4a):全三模态组合(V+T+A)性能最优(τ=0.351),证实了三模态的协同效应。音频模态单独使用略优于文本。
- 窗口策略(表4b):“由窄到宽”的Local-to-Global策略(w: 5,15,45,N)性能最佳,优于固定窗口或其他渐变策略。
- 模块作用(表4c):同时包含多尺度时间块(MST)和跨模态融合块(CMF)时性能最优。移除任一模块都会导致显著性能下降,其中移除MST影响更大。
- 融合方法(表4d):“动态”融合(帧级自适应)性能最好(τ=0.351),验证了核心假设。
- 定性分析
在吉他演示视频中,模型注意力在开头Logo(视觉)、旁白(文本)和演奏(音频)之间动态切换;在手风琴视频中,即使视觉和文本信息不足,模型也能主要依赖音频进行准确摘要。这直观展示了模型自适应融合的能力。
⚖️ 评分理由
- 学术质量:6.0/7。论文在技术设计上逻辑清晰,模块化强,实验非常充分,覆盖了新旧多个数据集、多角度消融和定性分析,证据可信。创新性体现在对现有多模态融合范式的系统性改进(自适应帧级融合、多尺度时序建模),而非提出全新的基础概念,因此属于扎实的增量式创新。
- 选题价值:1.5/2。视频摘要随短视频时代而愈发重要,多模态融合是必然趋势。该工作针对性地解决了模态动态性问题并���供了关键数据集,对推动多模态视频内容理解有积极意义。与音频/语音读者的相关性中等,因其证明了音频在视频理解中的重要性。
- 开源与复现加成:1.0/1。论文明确提供了代码仓库和MoSu数据集的链接,附录中详细列出了超参数、预处理步骤、评估协议等复现所需的所有关键信息,开源程度和文档完整性优秀。