📄 TRIBE: TRImodal Brain Encoder for whole-brain fMRI response prediction
#多模态模型 #预训练 #Transformer #脑编码 #跨模态
🔥 9.5/10 | 前10% | #脑编码 | #预训练 | #多模态模型 #Transformer
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Stéphane d‘Ascoli(Meta AI)
- 通讯作者:未说明
- 作者列表:Stéphane d‘Ascoli(Meta AI)、Jérémy Rapin(Meta AI)、Yohann Benchetrit(Meta AI)、Hubert Banville(Meta AI)、Jean-Rémi King(Meta AI)
💡 毒舌点评
亮点在于其工程与科学的完美结合:它不仅是竞赛刷榜利器,更通过严谨的消融实验证明了“多模态整合”在高级联合皮层的关键作用,为构建统一认知模型提供了方法论和实证支持。短板则是其对数据和算力的极度依赖(80小时/被试fMRI,128 GPU特征提取)以及仅在4名被试上验证的结论,这在一定程度上限制了其普适性的即时说服力。
🔗 开源详情
- 代码:提供了代码仓库链接:
https://github.com/facebookresearch/algonauts-2025。 - 模型权重:论文中未提及是否公开TRIBE模型或特征提取模型的权重。
- 数据集:使用了公开的Courtois NeuroMod数据集(CC0许可),并说明为Algonauts 2025竞赛选择了4名被试的子集。
- Demo:论文中未提及在线演示。
- 复现材料:提供了极其详尽的复现信息,包括完整的超参数表(表3)、数据处理流程、评估指标定义、训练细节(优化器、学习率调度、SWA、模态丢弃等),以及硬件规格。
- 论文中引用的开源项目:明确列出了使用的开源模型和工具,包括:Llama 3.2(Meta)、Wav2Vec-Bert 2.0(Hugging Face)、V-JEPA 2(Meta, Apache协议)、x-transformers包(MIT协议)、nilearn(BSD协议)、PyTorch。
📌 核心摘要
- 要解决的问题:传统神经科学研究局限于单模态、单脑区的碎片化模型,而现有的脑编码模型存在线性映射假设过强、仅支持单主体训练、且大多局限于单模态刺激输入三大限制,阻碍了构建统一的全脑认知模型。
- 方法核心:提出TRIBE,一种深度神经网络,它将文本(Llama 3.2)、音频(Wav2Vec-Bert)和视频(V-JEPA 2)基础模型的预训练表征作为输入,通过一个Transformer编码器来建模其时间动态和跨模态整合,最终预测全脑的fMRI反应。
- 新在哪里:与之前工作相比,TRIBE首次实现了同时是非线性的、多主体的、多模态的端到端脑编码。它超越了简单的线性映射,并允许在多个被试的数据上联合训练一个共享模型。
- 主要实验结果:TRIBE在Algonauts 2025脑编码竞赛中获得第一名(267个团队),平均Pearson相关系数为0.2146,显著领先第二名(见表1)。消融实验表明,多模态模型(0.31)显著优于最佳单模态模型(视频0.25),且这种优势在前额叶、顶叶等高级联合皮层最为明显(见图4)。模型能够预测所有1000个脑区,并在多种高度分布外的电影上展现出鲁棒性(见表2)。
- 实际意义:为神经科学提供了一个统一的建模框架,使得从多模态自然刺激预测全脑活动成为可能,有望推动对知觉、理解等认知过程的整体性研究,并为“计算机实验”提供新工具。
- 主要局限性:当前模型基于粗粒度的脑区分割(1000个区域),损失了精细的空间信息;仅使用了fMRI数据,无法捕捉快速的神经电活动;目前仅在4名被试上进行训练和验证。
🏗️ 模型架构
TRIBE的整体架构旨在将三种模态的刺激信息融合,并预测全脑的BOLD响应。其流程可概括为:特征提取 -> 多模态融合 -> 时序建模 -> 全脑预测。
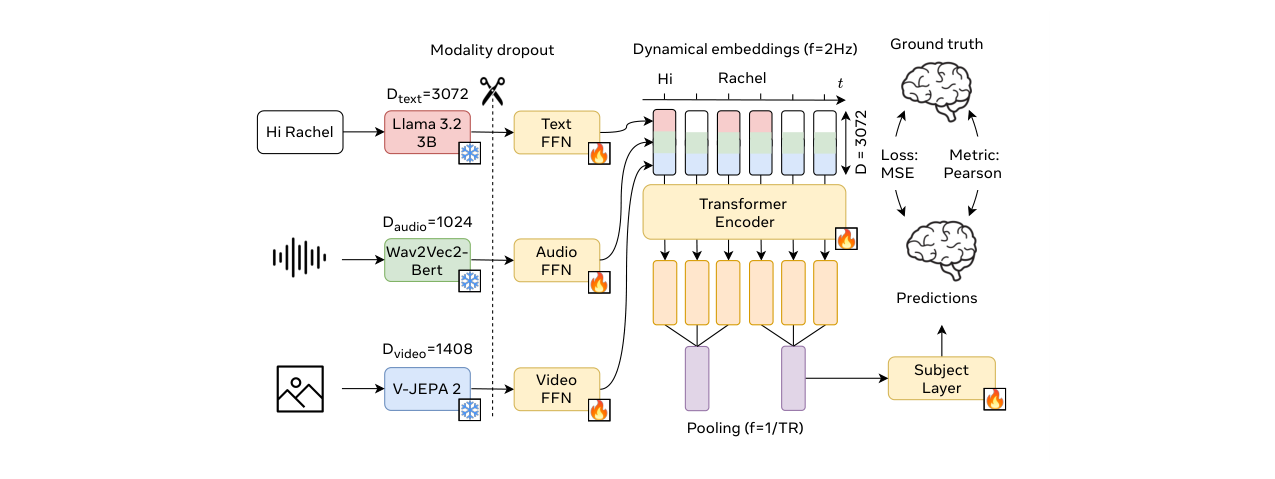
如图2所示,该模型架构图展示了从多模态输入到预测输出的完整流程。
- 输入:视频剪辑、对应的音频文件和带时间戳的文本转录稿。
- 单模态特征提取:
- 文本:将每个词及其前1024个词上下文输入Llama-3.2-3B,提取中间层(相对深度0.5-1)的词嵌入,按2Hz时间网格对齐并求和,得到时间序列。
- 音频:将60秒音频块输入Wav2Vec-Bert-2.0,提取中间层(0.5-1)的隐藏表示,并从50Hz重采样至2Hz。
- 视频:以2Hz频率,每次输入过去4秒的64帧到V-JEPA 2,并对所有patch token进行空间平均,提取中间层(0.5-1)的特征。
- 模态内压缩与融合:对每个模态,将其Transformer的中间层特征分成两组(相对深度0.5-0.75和0.75-1.0),各组内对层维度取平均,得到两个时间步长的嵌入。随后将这两个嵌入在维度上拼接,并通过一个线性层映射到共享维度D=1024,再经过层归一化。最后,将三个模态的特征在序列维度上拼接,形成形状为
[3 * N, 1024]的多模态嵌入序列。 - 时序建模(Transformer编码器):为多模态嵌入序列加入可学习的位置编码,然后输入一个8层8头的Transformer编码器。这使模型能够捕捉不同时间步以及不同模态之间的信息交互。
- 输出:Transformer的输出经过自适应平均池化,将序列压缩回与fMRI TR(1.49秒)对齐的长度(即
N个时间点)。最后,通过一个主体条件层(为每个被试学习独立的线性投影层),将N个时间点的嵌入同时映射到1000维的脑区预测目标上。损失函数为预测值与真实fMRI信号之间的均方误差。
💡 核心创新点
- 端到端的多模态联合编码:TRIBE直接联合处理来自文本、音频和视频的原始特征,通过一个统一的网络学习模态间的动态整合。之前的模型多为单模态,或对多模态结果仅作简单线性组合,无法学习复杂的跨模态交互,而TRIBE在高级联合皮层(如前额叶)显著超越了最佳单模态模型(图4b)。
- 非线性的时序动态建模:使用Transformer替代传统的线性映射(如岭回归)或简单的循环网络,来建模刺激特征与大脑响应之间复杂的、非线性的时间对应关系。消融实验显示,移除Transformer会使性能从0.31骤降至0.23(图6a)。
- 跨主体的联合训练范式:通过引入“主体条件层”,使得一个共享的主体无关模型能够在所有被试的数据上联合训练,从而利用大脑间的共性信息并提高模型泛化能力。训练时每个主体的投影层独立,预测时共享模型主体。联合训练比单独训练每个主体性能提升约0.02(图6a)。
🔬 细节详述
- 训练数据:使用Courtois NeuroMod数据集,包含6名被试观看大量自然视频(电视剧《老友记》、四部电影)产生的fMRI数据。本工作选取其中4名被试。预处理后,全脑体素信号被映射到MNI152标准空间,并使用Schaefer图谱划分为1000个非重叠皮层区域,每个区域产生一个fMRI时间序列。信号按每个扫描会话(约15分钟)进行z-score标准化。数据划分中,确保相同的视频在所有被试中被保留用于验证,防止数据泄露。
- 损失函数:使用均方误差(MSE) 作为损失函数,直接最小化预测的BOLD信号与真实信号之间的差异。评估指标为预测信号与真实信号之间的皮尔逊相关系数。
- 训练策略:
- 优化器:AdamW。
- 学习率:初始学习率
10^{-4},在前10%的步数内线性预热,之后遵循余弦衰减调度。 - Batch size:16。
- 训练轮数:最多15轮,并采用早停法(基于验证集皮尔逊分数)。
- 正则化与泛化:使用随机权重平均(SWA),在验证指标接近平台期后,对每个epoch结束时的模型权重进行平均。训练时引入模态丢弃(Modality Dropout):以概率p(默认0.2)随机屏蔽每个模态的输入(置零),但确保至少保留一个模态,以鼓励模型不过度依赖单一模态并提升鲁棒性。
- 关键超参数:
- 模型总参数量:980M(可训练部分)。基础特征提取模型:Llama-3.2-3B(3B参数)、Wav2Vec-Bert-2.0(600M参数)、V-JEPA 2(700M参数)。
- 输入频率
f = 2 Hz,预测窗口长度N = 100TR(对应约149秒)。 - Transformer编码器:8层,8个注意力头,隐藏维度与输入特征一致。
- 模态特征压缩:每个模态分2层组(相对深度0.5-0.75和0.75-1.0),每组内平均,然后拼接。
- 集成:训练M=1000个模型进行集成,每个模型使用不同的初始化种子和超参数组合(见表3),最终对每个脑区根据验证集分数对模型进行加权平均(温度0.3)。
- 训练硬件:特征提取在128个32GB V100 GPU上耗时24小时。TRIBE模型本身的训练在单个32GB V100 GPU上耗时24小时。
- 推理细节:推理时,模型以滑动窗口方式处理输入的连续时间序列,并为每个TR预测一个1000维的响应向量。由于Transformer和主体条件层的设计,整个预测窗口(N个TR)可以同时输出,这使得推理过程非常高效。
📊 实验结果
TRIBE的评估主要在Algonauts 2025竞赛的两个阶段进行,并进行了详细的内部消融分析。
主要竞赛结果
| 排名 | 平均得分(mean ± std) | Subject 1 | Subject 2 | Subject 3 | Subject 5 |
|---|---|---|---|---|---|
| 1 (Ours) | 0.2146 ± 0.0312 | 0.2381 | 0.2105 | 0.2377 | 0.1720 |
| 2 | 0.2096 ± 0.0283 | 0.2353 | 0.2046 | 0.2268 | 0.1718 |
| 3 | 0.2094 ± 0.0215 | 0.2233 | 0.2072 | 0.2271 | 0.1798 |
| 4 | 0.2085 ± 0.0267 | 0.2295 | 0.2003 | 0.2300 | 0.1743 |
| 5 | 0.2055 ± 0.0291 | 0.2306 | 0.2010 | 0.2240 | 0.1662 |
表1:Algonauts 2025竞赛排行榜前五名。TRIBE以显著优势获得第一。
在不同电影上的泛化性能
| 是否分布外(OOD) | 电影名称 | 平均得分(mean ± std) | Subject 1 | Subject 2 | Subject 3 | Subject 5 |
|---|---|---|---|---|---|---|
| ✗ | Friends Season 7 | 0.3195 ± 0.0289 | 0.3419 | 0.3239 | 0.3346 | 0.2775 |
| ✓ | Pulp Fiction | 0.2604 ± 0.0137 | 0.2765 | 0.2611 | 0.2431 | 0.2610 |
| ✓ | Princess Mononoke | 0.2449 ± 0.0572 | 0.2816 | 0.2507 | 0.2851 | 0.1623 |
| ✓ | Passe-partout | 0.2323 ± 0.0525 | 0.2763 | 0.2587 | 0.2370 | 0.1573 |
| ✓ | World of Tomorrow | 0.1924 ± 0.0323 | 0.2210 | 0.1606 | 0.2196 | 0.1686 |
| ✓ | Planet Earth | 0.1886 ± 0.0380 | 0.1483 | 0.2029 | 0.2331 | 0.1699 |
| ✓ | Charlie Chaplin | 0.1686 ± 0.0551 | 0.2249 | 0.1289 | 0.2080 | 0.1128 |
表2:模型在不同分布条件下的性能。即使是高度分布外的无声电影、动画和自然纪录片,模型仍能获得可观的分数。
多模态消融实验
| 模型 | 验证集皮尔逊得分 |
|---|---|
| 仅文本 (T) | 0.22 |
| 仅音频 (A) | 0.24 |
| 仅视频 (V) | 0.25 |
| 音频+文本 (A+T) | ~0.28 (从图4a估算) |
| 音频+视频 (A+V) | ~0.29 (从图4a估算) |
| 文本+视频 (T+V) | 0.30 |
| 三模态 (A+T+V) | 0.31 |
图4的消融实验结果图清晰地展示了:多模态模型(尤其是三模态组合)在平均编码得分上显著优于任何单模态模型,验证了模态互补性的重要性。
模型组件消融实验
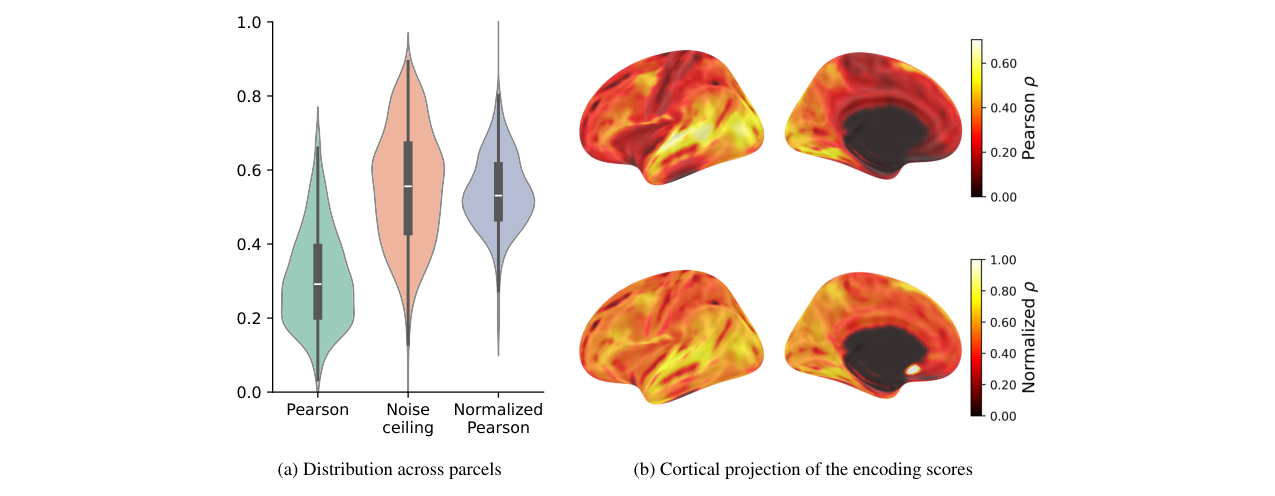
图6a的消融实验结果图展示了:移除“多主体训练”或“Transformer”组件都会导致模型性能下降,其中移除Transformer的影响尤为巨大(从0.31降至0.23),证实了非线性时序建模和跨主体学习的关键作用。
⚖️ 评分理由
- 学术质量:6.5/7 - 创新性明确,系统性地解决了现有脑编码模型的三大痛点;方法设计合理,技术细节清晰;实验极为充分,既有大规模竞赛的端到端验证,也有深入的消融分析(模态、模型组件、超参数缩放律)和神经科学意义的探索(模态在脑区的分布);所有结论都有坚实的数据支撑(表1、表2、图4、图6)。
- 选题价值:1.8/2 - 选题直指“构建整合性大脑认知模型”这一神经科学的终极目标之一,属于高度前沿和重要的方向。其方法不仅适用于fMRI,其框架思想可扩展至其他神经成像模态,对AI与认知神经科学的交叉领域有显著推动作用。
- 开源与复现加成:1.0/1 - 论文提供了完整的代码仓库链接(https://github.com/facebookresearch/algonauts-2025),并公开了所有关键的超参数设置(表3)、数据集使用信息(Courtois NeuroMod, CC0许可)和训练细节。这使得研究社区能够高度可信地复现其结果,是开源科学实践的典范。