📄 Towards True Speech-to-Speech Models Without Text Guidance
#语音对话系统 #端到端 #大语言模型 #预训练 #流式处理
✅ 7.5/10 | 前25% | #语音对话系统 | #端到端 | #大语言模型 #预训练
学术质量 7.0/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xingjoint Zhao(复旦大学)
- 通讯作者:Xipeng Qiu(复旦大学)
- 作者列表:Xingjoint Zhao¹³(1.复旦大学,2.上海创新研究院,3.MOSI.AI),Zhe Xu¹²³,Luozhijie Jin¹²³,Yang Wang¹³,Hanfu Chen¹³,Yaozhou Jiang¹³,Ke Chen¹²³,Ruixiao Li¹²³,Mingshu Chen¹³,Ruiming Wang¹³,Wenbo Zhang¹²³,Qinyuan Cheng¹³,Zhaoye Fei¹³,Shimin Li³,Xipeng Qiu¹²³†
💡 毒舌点评
亮点:论文直击当前语音对话模型“伪端到端”(依赖文本指导)的痛点,提出的模态分层架构和冻结预训练策略,为在LLM中集成原生语音能力并保留文本智能提供了一个有原理性支撑且实验有效的解决方案。短板:尽管自称为“真”语音到语音模型,但其语音理解与生成的底层仍严重依赖于强大的文本LLM骨干和高质量的文本-语音配对数据,其“无文本指导”更多体现在生成阶段,训练阶段对文本的依赖并未摆脱;此外,对于更复杂的、富含副语言信息的开放式对话场景,模型的表现力有待进一步验证。
📌 核心摘要
本文旨在解决现有语音对话系统依赖文本中间环节导致的延迟增加、副语言信息丢失和表达力受限的问题。核心方法是构建一个真正的、无需文本指导的语音到语音大语言模型,其技术核心是模态分层架构(在Transformer顶层为文本和语音设置独立分支)与冻结预训练策略(第一阶段冻结预训练文本LLM,仅训练语音相关模块;第二阶段再联合微调)。与已有方法相比,其创新在于明确观察并利用了跨模态表示在模型深度上的演变规律(先融合后分化),并设计了对应的架构进行适配,同时通过冻结策略有效防止了文本能力的灾难性遗忘。主要实验结果表明:1)在口语问答任务上(如LlamaQA),模型的语音到语音(S→S)性能(63.67%)达到了与文本指导系统(GLM-4-Voice*:65.67%)可比的水平,并在WebQA上(36.71%)超越了后者(38.34%),在部分任务上取得SOTA;2)模型在文本能力基准(MMLU: 67.19, CMMLU: 69.53)上相比引入语音前的文本LLM(Qwen3-8B: MMLU 76.6, CMMLU 77.35)的下降幅度远小于SpiritLM等模型;3)语音编码器/解码器在WER、SIM等指标上具备竞争力。该工作为构建高效、富有表现力的端到端语音交互系统建立了新的范式。主要局限性在于训练依赖大规模、高质量的语音-文本数据(包括合成数据),且模型在复杂对话、长时交互和极端副语言场景下的能力尚未充分评估。
🏗️ 模型架构
本文提出的“真”语音到语音大语言模型架构,旨在从预训练的文本LLM出发,扩展其对语音的端到端理解与生成能力,同时保留原有的文本能力。其整体架构与数据流如下:
基础骨干:以Qwen-3-8B作为初始化的文本大语言模型骨干。
模态分层设计:这是架构的核心创新。模型主体是一个36层的Transformer。前32层作为共享层,用于处理文本和语音两种模态的输入,进行深度的跨模态融合。在第32层之后,隐藏状态被路由到两个独立的模态特化分支:
- 文本分支:由原有的最后4层(第33-36层)构成,负责预测文本token。
- 语音分支:由一个新引入的、并行的4层Transformer构成,负责预测语音token。 这一设计基于论文中的一个关键发现(如图2所示):在深层网络中,文本和语音的隐藏状态表示在经过中层融合后,会在顶层重新分化。模态分层设计正是为了适配这种特性,在共享层完成信息融合后,让不同模态在各自专用的输出层进行解码。
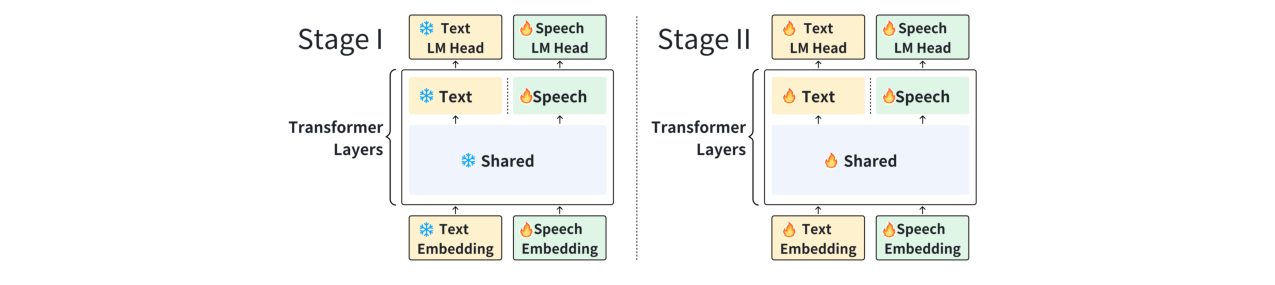
图2:文本与语音跨模态表示在模型不同层的相似度可视化。(a)-(d)展示了在第0、10、24、27层的余弦相似度热力图,黄色点为DTW采样点。可见相似度对角线在中间层出现,在顶层消退。(e)展示了相似度分数随层深变化的趋势:先上升(第0-10层),中间波动(第10-24层),最后下降(第24-27层)。这为模态分层设计提供了实证依据。
语音分词器:
- 编码器:基于GLM-4-Voice Tokenizer修改,将因果性从分块因果改为全因果以支持纯流式处理。训练目标为自动语音识别(ASR),以最大化语义信息保留。
- 解码器:采用流匹配(Flow-Matching)架构(源自CosyVoice 2)。通过压缩chunk大小来降低延迟,以适应流式对话场景。
训练策略:模型训练分为两阶段,整体策略如图3所示。
图3:模型架构与训练策略。图中清晰展示了36层Transformer在第32层的分支:一路通向文本特化的最后4层,另一路通向并行的4层语音特化分支。训练策略分为两阶段:Stage I冻结文本骨干(Qwen-3-8B),仅训练语音相关参数;Stage II进行联合训练。
- 阶段一(冻结预训练):冻结Qwen-3-8B骨干的所有参数,仅训练新引入的语音token嵌入、语音特化Transformer层和语音LM头。目标是初始化语音参数并与文本表示稳定对齐。
- 阶段二(联合训练):解冻整个模型(或部分层,论文默认全解冻)进行联合训练。同时,混入少量纯文本数据以缓解文本能力下降。
输入输出:模型接受纯文本或语音作为输入,并能生成纯文本或语音作为输出,由系统提示控制模态组合。
💡 核心创新点
- 提出并实现“真”语音到语音模型:与依赖文本指导(如GLM-4-Voice)或级联管道的系统不同,本文模型直接以语音作为输入和输出,避免了生成阶段对文本中间表示的依赖,从而在理论上能降低延迟并更好地保留副语言信息。
- 模态分层架构:基于对跨模态表示在Transformer中演变规律的实证分析(图2),设计了在顶层按模态分流的架构。该设计允许共享层充分融合多模态信息,而特化层负责高效、原生的模态生成,有效平衡了能力迁移与特化生成的需求。
- 冻结预训练策略:为解决将LLM扩展到新模态时常见的文本能力下降问题,采用了分阶段、带冻结的训练策略。第一阶段冻结强大的文本骨干,让语音模块“适配”其表示空间;第二阶段再微调,这比直接端到端训练更能保留原有知识。实验消融(表6)证明了该策略对保留文本能力的关键作用。
🔬 细节详述
- 训练数据:
- 预训练数据:总计约900万小时网络音频,经VAD筛选后约400万小时。分为两类:1) 交错数据(约164万小时):来自播客,经过ASR获取文本,并用CTC对齐切分为3-6秒的片段,音频与文本交错排列;2) 无监督数据(约230万小时):来自视频,直接使用完整音频。此外,使用CosyVoice 2 TTS系统从高质量文本语料(FineWeb-Edu)合成约15万小时的语音-文本对,以提升知识密度。
- 微调数据:基于多个开源文本SFT数据集,使用GPT-5 API进行文本适应(如转为TTS友好格式、控制长度),再使用Seed-TTS和MOSS-TTSD合成语音。用户侧使用多说话人声音,助手侧使用单一声音。通过ASR的WER(≥0.2)进行质量过滤。最终得到超过150万对问答对。
- 损失函数:论文未提供具体损失函数公式。从架构和训练目标推断,应为自回归语言模型损失:在文本分支预测下一个文本token的概率,在语音分支预测下一个语音token的概率,总损失为两者之和(或加权和)。
- 训练策略:
- 阶段一:约1个epoch,AdamW优化器,余弦学习率从
4e-4开始,批次大小2.2M tokens,权重衰减0.1,上下文长度14336。 - 阶段二:约2个epoch,学习率从
6e-5衰减至6e-6,批次大小2.8M tokens。混入0.1个epoch的纯文本数据。 - 监督微调:2个epochs,AdamW,学习率从
1e-5衰减至1e-6,批次大小8,最大上下文10240。采用四种模态组合(S→S, S→T, T→S, T→T)进行训练,以增强跨模态对齐。
- 阶段一:约1个epoch,AdamW优化器,余弦学习率从
- 关键超参数:骨干模型Qwen-3-8B(未明确层数,但架构为36层);语音分词器帧率12.5Hz,比特率175 bps(每秒);语音分支为4层Transformer。
- 训练硬件:论文中未说明具体使用的GPU型号、数量及训练时长。
- 推理细节:语音编码器为全因果,支持流式输入;语音解码器(流匹配)通过压缩chunk大小以降低延迟。生成时采用自回归方式。
- 正则化或稳定训练技巧:在第二阶段预训练和微调中混入文本数据以防止文本能力灾难性遗忘;在监督微调中采用多种模态组合以增强对齐。
📊 实验结果
论文在语音编码器、解码器、预训练模型和微调模型等多个层面进行了评估。
语音编码器评估(表2)
| 模型 | 帧率(Hz) | BPS | 流式 | WER (%) ↓ (test-clean) | WER (%) ↓ (dev-clean) | WER (%) ↓ (overall) |
|---|---|---|---|---|---|---|
| Mimi-8 | 12.5 | 1100 | × | 9.65 | 9.67 | 14.45 |
| XCodec2.0 | 50 | 800 | × | 14.17 | 13.82 | 20.07 |
| CosyVoice | 25 | 300 | × | 10.15 | 9.64 | 14.21 |
| CosyVoice 2 | 25 | 325 | × | 9.45 | 9.42 | 13.78 |
| GLM-4-Voice | 12.5 | 175 | Chunk(2s) | 6.59 | 6.07 | 9.17 |
| Ours | 12.5 | 175 | ✓ | 7.89 | 7.29 | 10.80 |
| 结论:本文编码器(Ours)在实现真正流式(✓)的同时,WER(10.80%)优于多数非流式编码器(如Mimi-8, CosyVoice 2),且仅略低于非纯流式的GLM-4-Voice。 |
语音解码器评估(表3)
| 模型 | 帧率 | Seed-TTS-Eval-EN | Seed-TTS-Eval-ZH | ||||
|---|---|---|---|---|---|---|---|
| WER ↓ | SIM ↑ | DNSMOS ↑ | WER ↓ | SIM ↑ | DNSMOS ↑ | ||
| CosyVoice | 25hz | 10.53 | 0.66 | 3.07 | 11.29 | 0.74 | 3.21 |
| CosyVoice 2 | 25hz | 4.63 | 0.68 | 3.09 | 3.11 | 0.75 | 3.22 |
| Ours | 12.5hz | 4.14 | 0.67 | 3.10 | 2.86 | 0.73 | 3.24 |
| 结论:解码器(Ours)在更低的帧率(12.5hz vs 25hz)下,在英语和中文基准上取得了更好的可懂度(WER↓)和感知质量(DNSMOS↑),说话人相似度(SIM)接近。 |
预训练模型评估(表4)
| 模型 | Speech | Text | ||||
|---|---|---|---|---|---|---|
| tS.C. | sS.C. | zh-tS.C. | zh-sS.C. | MMLU | CMMLU | |
| Moshi | 83.60 | 62.70 | - | - | 49.8 | - |
| GLM-4-Voice | 82.90 | 62.40 | 83.27 | 69.10 | 57.49 | 54.39 |
| SpiritLM | 82.90 | 61.00 | - | - | 36.90 | - |
| Ours | 84.87 | 63.17 | 90.32 | 71.94 | 67.19 | 69.53 |
| 结论:本文预训练模型在语音续写任务(StoryCloze)上达到或超越现有模型,同时在文本能力基准(MMLU, CMMLU)���显著优于SpiritLM和GLM-4-Voice,证明了冻结预训练策略在平衡两方面能力上的有效性。 |
监督微调模型评估(表5)
| 模型 | L. QA | T. QA | W. QA | UTMOS | |||
|---|---|---|---|---|---|---|---|
| S→T | S→S | S→T | S→S | S→T | S→S | ||
| 预训练模型 | |||||||
| GLM-4-Voice | 64.70 | 50.70 | 39.10 | 26.50 | 32.20 | 15.90 | - |
| 监督微调模型 | |||||||
| SpeechGPT* | - | 21.60 | - | 14.80 | - | 6.50 | 4.00 |
| Moshi | - | 21.00 | - | 7.30 | - | 9.20 | 2.81 |
| GLM-4-Voice* | 74.33 | 65.67 | 45.90 | 43.20 | 39.22 | 38.34 | 4.25 |
| Ours | 77.33 | 63.67 | 45.20 | 28.80 | 45.90 | 36.71 | 4.37 |
注:*表示S→S结果使用了文本指导。 | |||||||
| 结论:在口语问答任务上,本文模型(Ours)的S→S性能与强文本指导模型GLM-4-Voice处于可比范围,在LlamaQA和WebQA的S→T上甚至更优,在WebQA S→S上(36.71%)超越了GLM-4-Voice(38.34%)。在语音质量(UTMOS)上也表现优异。 |
消融实验(表6)
| 模型 | 分层 | Speech | Text | ||||
|---|---|---|---|---|---|---|---|
| tS.C. | sS.C. | zh-tS.C. | zh-sS.C. | MMLU | CMMLU | ||
| FP–Full | 4 | 85.20 | 63.12 | 90.21 | 72.10 | 66.50 | 69.15 |
| NF | 4 | 77.66 | 56.60 | 88.51 | 67.56 | 62.11 | 64.11 |
| NF–NoSplit | 0 | 77.12 | 55.80 | 88.72 | 67.02 | 60.97 | 63.73 |
| 结论:1) 模态分层(对比NF与NF–NoSplit)对语音和文本能力均有提升;2) 冻结预训练(对比FP–Full与NF)带来巨大增益,特别是在文本能力(MMLU: 66.50 vs 62.11)上;3) 不同解冻策略(FP-Full, FP-Shared, FP-Layerwise)差异较小。 |
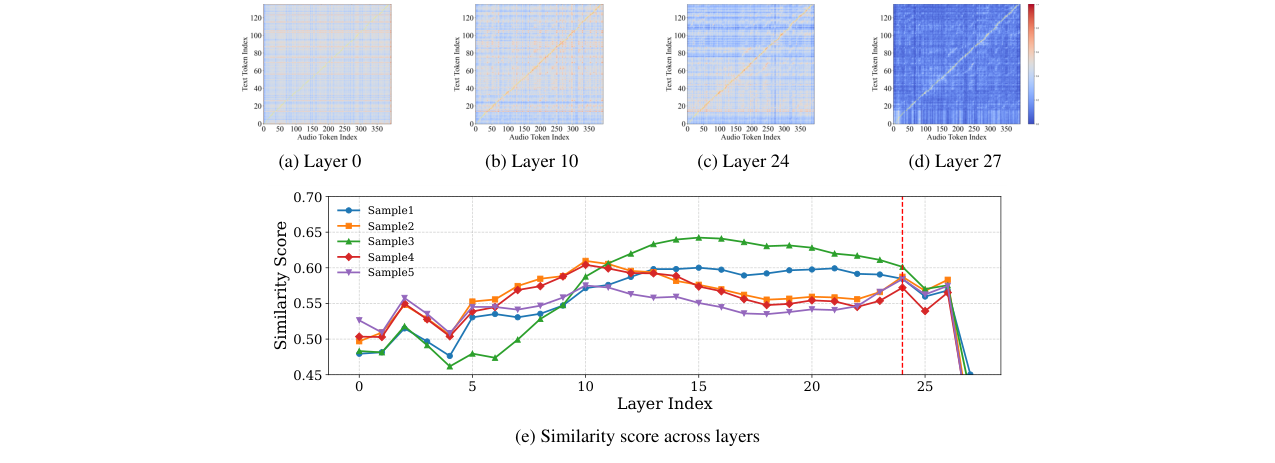
图5:消融实验结果可视化。图中对比了FP-Full、FP-Layerwise、FP-Shared、NF(不同分层数)和NF-NoSplit等多种配置在zh-sS.C.(中文语音续写)和CMMLU(中文文本理解)上的表现。可以清晰地看出,FP(冻结预训练)系列模型(图中上半部分点)在两项任务上普遍优于NF(无冻结)系列(下半部分点),直观验证了冻结预训练策略的有效性。
⚖️ 评分理由
- 学术质量:7.0/7:创新性明确(模态分层、冻结预训练),针对性地解决了一个实际问题。技术实现路径清晰,实验设计合理,包含了与当前主流文本指导模型(如GLM-4-Voice, Moshi)的对比和充分的消融研究,证据链相对完整。扣分点在于部分实现细节(如精确损失函数、超参数细节)未公开,且对模型在更复杂、更具挑战性的开放式对话和生成任务上的评估不足。
- 选题价值:2.0/2:选题非常前沿,直接针对语音对话系统向更自然、低延迟、高表现力演进的核心需求。提出的“真”语音到语音模型是行业公认的一个重要发展方向,具有很高的理论价值和广阔的落地前景,与音频/语音领域的研究者和工程师高度相关。
- 开源与复现加成:-0.5/1:论文明确承诺“will release our code and models”,这对社区是重大利好。但当前提供的文本中缺乏可立即访问的仓库链接、模型权重、完整的训练配置和硬件信息,使得读者无法在现有信息下完整复现,因此给予扣分。