📄 Toward Complex-Valued Neural Networks for Waveform Generation
#语音合成 #复数神经网络 #生成对抗网络 #声码器 #计算优化
🔥 8.0/10 | 前25% | #语音合成 | #复数神经网络 | #生成对抗网络 #声码器
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Hyung-Seok Oh(高丽大学人工智能系)
- 通讯作者:Seong-Whan Lee(高丽大学人工智能系)
- 作者列表:Hyung-Seok Oh(高丽大学人工智能系)、Deok-Hyeon Cho(高丽大学人工智能系)、Seung-Bin Kim(高丽大学人工智能系)、Seong-Whan Lee(高丽大学人工智能系)
💡 毒舌点评
亮点:论文工作非常系统,不仅提出了复数域生成器与判别器的完整GAN框架,还针对性地设计了相位量化层作为归纳偏置,并给出了计算图级别的效率优化(分块矩阵),形成了一个从理论动机到工程实现闭环的扎实工作。短板:复数网络带来的参数量与显存开销(约翻倍)是其难以回避的“阿喀琉斯之踵”,论文虽通过分块矩阵优化了训练时间,但在推理吞吐量和多卡训练支持上仍显不足,这限制了其在大规模工业部署中的即时吸引力。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/hs-oh-prml/ComVo。
- 模型权重:提供预训练模型权重,可通过论文提供的主页链接获取:https://hs-oh-prml.github.io/ComVo/。
- 数据集:使用公开的LibriTTS和MUSDB18-HQ数据集。
- Demo:论文主页提供音频样本演示:https://hs-oh-prml.github.io/ComVo/。
- 复现材料:论文提供了非常详细的训练配置表(表20),包括所有超参数、数据设置、损失权重、硬件信息等。附录中也包含了各基线模型的实现来源(表17)和评估指标的来源(表18)。
- 论文中引用的开源项目:
- Vocos:作为基础架构进行改编。
- HiFi-GAN, BigVGAN, iSTFTNet:作为主要对比基线。
- APNet, APNet2, FreeV:作为幅相预测声码器的对比基线。
- Matcha-TTS:用于TTS管线评估的声学模型。
- UTMOS, auraloss, PESQ, cargan:用于客观评估的指标工具。
📌 核心摘要
- 解决的问题:现有的基于逆短时傅里叶变换(iSTFT)的声码器(如Vocos)虽然效率高,但普遍使用实值神经网络(RVNN)将复数谱的实部和虚部作为独立通道处理,这限制了模型捕捉实虚部之间内在耦合结构的能力。
- 方法核心:提出ComVo,一个完全在复数域内运行的GAN声码器。其生成器和判别器(cMRD)均使用原生复数算术层。同时引入了相位量化层,将连续相位离散化为有限等级,作为稳定训练的归纳偏置。此外,提出了分块矩阵计算方案,将复数乘法融合为单次矩阵乘法,以减少冗余操作,提升训练效率。
- 创新之处:据作者称,这是首个将复数神经网络(CVNN)同时应用于生成器和判别器的iSTFT-based vocoder。与先前实值方法独立处理实虚部或简单拼接通道相比,该方法在复数域内进行端到端的对抗训练,能提供更结构化的反馈。相位量化和分块矩阵计算是两个重要的辅助创新。
- 主要实验结果:在LibriTTS数据集上,ComVo在多数客观指标上超越了HiFi-GAN、iSTFTNet、BigVGAN和Vocos等强基线,MOS得分(4.07)与基线持平。在MUSDB18-HQ音乐数据集上,ComVo也取得最佳客观分数和竞争力的主观分数。消融实验表明,复数生成器与复数判别器的组合(GCDC)效果最佳;相位量化在Nq=128时带来最佳感知质量提升;分块矩阵方案在保持性能的前提下将训练时间减少了25%。
| 模型 | UTMOS ↑ | MR-STFT ↓ | PESQ ↑ | Periodicity ↓ | V/UV F1 ↑ | MOS ↑ | CMOS ↑ |
|---|---|---|---|---|---|---|---|
| GT | 3.8712 | - | - | - | - | 4.08 ± 0.04 | 0.14 |
| HiFi-GAN | 3.3453 | 1.0455 | 2.9360 | 0.1554 | 0.9174 | 4.00 ± 0.05 | -0.09 |
| iSTFTNet | 3.3591 | 1.1046 | 2.8136 | 0.1476 | 0.9243 | 3.98 ± 0.05 | -0.04 |
| BigVGAN | 3.5197 | 0.8994 | 3.6122 | 0.1181 | 0.9418 | 4.05 ± 0.05 | -0.05 |
| Vocos | 3.6025 | 0.8856 | 3.6266 | 0.1061 | 0.9522 | 4.05 ± 0.05 | -0.02 |
| ComVo | 3.6901 | 0.8439 | 3.8239 | 0.0903 | 0.9609 | 4.07 ± 0.05 | 0 |
表2:在LibriTTS数据集上的客观与主观评估结果(关键行数据) 5. 实际意义:证明了复数神经网络在音频波形生成任务中相对于实值网络的表示优势,为处理复值信号(如频谱)提供了更自然的建模范式。分块矩阵方案为优化复数运算在现有深度学习框架中的实现效率提供了实用思路。 6. 主要局限性:复数参数存储导致内存占用翻倍,增加了模型大小和显存需求。论文在单卡上实验,多GPU并行训练下的性能和稳定性未充分验证。相位量化层的直通估计器(STE)近似可能在某些任务上引入优化挑战。
🏗️ 模型架构
ComVo是一个基于GAN的iSTFT波形生成器,其核心是使生成器和判别器均在复数域内操作。
整体输入输出流程:
- 输入:梅尔频谱图(实值),首先将其转换为复数表示(虚部初始化为0)。
- 生成器:输入复数梅尔频谱,通过复数卷积层和复数ConvNeXt块序列进行处理,在第一个复数卷积后立即进行相位量化。生成器最终输出复数STFT谱图。
- 逆短时傅里叶变换(iSTFT):将生成器的复数输出转换为时域波形。
- 训练:判别器(cMRD和MPD)对生成波形和真实波形进行判别,通过对抗损失、特征匹配损失和梅尔频谱重建损失来训练整个系统。
主要组件:
- 复数生成器:架构改编自Vocos,但所有卷积和归一化层均为复数实现。
- 复数ConvNeXt块:基本构建模块,包含复数深度卷积、复数层归一化、复数GELU激活、复数逐点卷积和残差连接。其设计保持了ConvNeXt的布局,但操作均在复数域。 相位量化层:位于生成器初始复数卷积之后。它将输入复数特征的相位θ离散化为Nq个等级:θq = (2π/Nq) round(Nqθ/(2π)),然后用量化后的相位和原始幅度重构复数特征。通过直通估计器(STE)保证可微性。
- 复数多分辨率判别器(cMRD):在复数域操作的判别器。由多个在不同STFT分辨率下的子判别器组成,直接对复数频谱图进行判别。损失函数分别应用于输出的实部和虚部。
- 多周期判别器(MPD):在波形域操作的实值判别器,与HiFi-GAN等一致,提供互补的周期性结构监督。
- 分块矩阵计算:一种计算优化方案,将复数线性变换(如卷积)表示为一个2x2的实值块矩阵乘法(见公式3、4),从而减少独立操作数,提升GPU计算效率。
架构图:
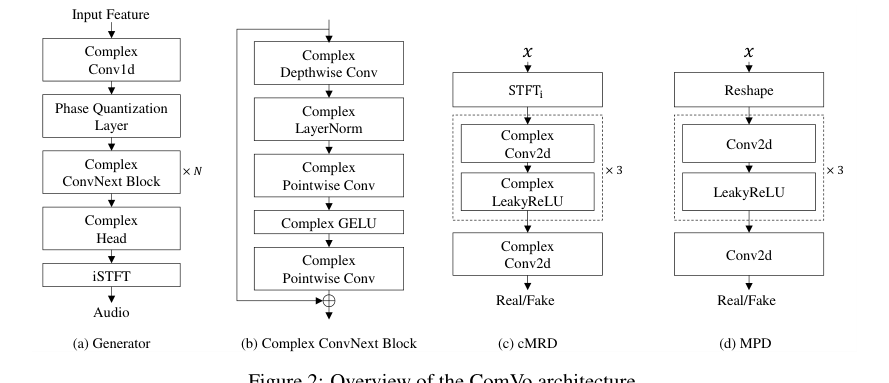
图2:ComVo架构概览。 (a)生成器:输入梅尔频谱,经过初始复数卷积、相位量化层、多个复数ConvNeXt块,最终输出复数频谱,经iSTFT得到波形。(b)复数ConvNeXt块内部结构。(c)复数多分辨率判别器(cMRD):由多个子判别器处理不同分辨率的复数频谱。(d)多周期判别器(MPD):处理波形段。
设计动机:核心动机是克服实值网络独立处理复数谱实虚部的局限性。复数网络能更自然地建模幅度和相位的耦合关系。相位量化作为归纳偏置,旨在稳定训练初期不稳定、自由变化的相位,引导网络学习更一致的相位模式。分块矩阵方案则是为了解决复数运算在自动微分框架中的效率问题。
💡 核心创新点
- 复数域GAN对抗框架:首次将复数神经网络(CVNN)同时应用于iSTFT vocoder的生成器与判别器。此前的工作(如Vocos)虽然预测复数谱,但使用实值网络处理。本工作使整个对抗训练(包括判别器的损失反馈)都在复数域进行,提供了更结构化的监督信号。
- 相位量化层:提出了一种针对复数特征的结构化非线性变换。它通过离散化相位角度,作为一种强正则化手段,减少了中间表示中不必要的相位波动,提升了合成质量的稳定性(尤其是听感自然度),而不仅仅是优化谱重建误差。
- 复数计算的分块矩阵优化:将复数权重矩阵与输入向量的乘法,重构为一个2x2实值块矩阵与实虚部拼接向量的乘法(公式3、4)。这减少了操作数,降低了计算图的复杂度(特别是反向传播),在不牺牲模型性能的前提下,将训练时间减少了25%。
🔬 细节详述
- 训练数据:
- 数据集:LibriTTS (train-clean-100, train-clean-360, train-other-500子集),24kHz采样。
- 预处理:FFT大小1024,跳数256,汉宁窗长度1024。计算100个梅尔频带、最大频率12kHz的梅尔频谱图。
- 损失函数:
- 判别器损失:MPD使用铰链损失(公式14)。cMRD的损失分别对输出的实部和虚部应用铰链损失(公式15)。 生成器损失:包括梅尔频谱L1损失(公式16)、来自MPD和cMRD的对抗损失(公式17, 18)、以及特征匹配损失(公式19, 20)。总损失(公式21)为加权和:λMel LMel + λMPD (LMPD_G + LMPD_FM) + λcMRD (LcMRD_G + LcMRD_FM)。权重:λMel=45,λMPD=1.0,λcMRD=0.1。
- 训练策略:
- 优化器:AdamW,β1=0.8,β2=0.9。
- 学习率:初始2e-4,使用余弦调度器。
- 批量大小:16(基准模型),32(大模型)。
- 训练步数:1M步。
- 段长:16384采样点。
- 硬件:单卡NVIDIA A6000 GPU。训练时长:基准模型138小时(使用分块矩阵后)。
- 关键超参数:
- 生成器模型维度:512(基准),1536(大型)。
- 中间维度:1536(基准),4608(大型)。
- 层数:8。
- 相位量化等级Nq:128。
- MPD周期:[2, 3, 5, 7, 11]。
- cMRD/MRD的FFT大小:[512, 1024, 2048]。
- 推理细节:论文未特别说明解码策略、温度、beam size等,标准iSTFT流程。
- 正则化或稳定训练技巧:相位量化层是关键的正则化技巧。使用了铰链损失和特征匹配损失来稳定GAN训练。
📊 实验结果
- 主要对比实验(LibriTTS):如上文核心摘要中的表2所示。ComVo在UTMOS、MR-STFT、PESQ、Periodicity、V/UV F1等客观指标上均优于所有基线(HiFi-GAN, iSTFTNet, BigVGAN, Vocos)。主观MOS得分与最强的BigVGAN和Vocos持平(4.07 vs 4.05),CMOS为0(参考系)。
- 跨数据集评估(MUSDB18-HQ音乐):在表格3和表4中,ComVo同样在所有客观指标上取得最佳或并列最佳,并在主观SMOS评估中获得平均最高分(3.89),显示了良好的泛化能力。
| 模型 | MR-STFT ↓ | PESQ ↑ | Periodicity ↓ | V/UV F1 ↑ |
|---|---|---|---|---|
| HiFi-GAN | 1.1909 | 2.3592 | 0.1804 | 0.9004 |
| iSTFTNet | 1.2388 | 2.2357 | 0.1815 | 0.9102 |
| BigVGAN | 0.9658 | 3.2391 | 0.1388 | 0.9340 |
| Vocos | 0.9307 | 3.2785 | 0.1369 | 0.9361 |
| ComVo | 0.8776 | 3.5220 | 0.1304 | 0.9384 |
表3:在MUSDB18-HQ数据集上的客观评估结果
- 消融实验与可视化:
- 复数建模影响:表5显示,仅使用cMRD(复数判别器)比使用MRD(实值判别器)能获得更好的谱指标(PESQ更高)。完整的生成器-判别器复数组合(GCDC)优于所有部分实值组合。
- 相位量化影响:表6显示,与无量化(Nq=0)相比,Nq=128的量化在保持较低MR-STFT误差的同时,显著提升了UTMOS和PESQ,降低了周期性伪影。
- Grad-CAM可视化:图3对比了不同生成器-判别器配置下,判别器的注意力热图。实值MRD的注意力分散,而复数cMRD的注意力能更集中地对齐语音相关的频谱结构。

图3:Grad-CAM可视化对比。 每行对应一个cMRD子判别器,每列对应不同的生成器(GR/GC)-判别器(DR/DC)配置。可以观察到,使用复数判别器(GRDC, GCDC)时,注意力区域与语音频谱结构对齐更准确。
- 计算效率分析:
- 表7对比了原生PyTorch复数实现与分块矩阵实现。后者将生成器和判别器反向传播图的节点数分别减少了55%和67%,总训练时间从183小时降至138小时(减少25%),而MR-STFT误差相当。
- 图1(在结果部分未直接引用但内容相关)展示了实值网络(RVNN)和复数网络(CVNN)在合成简单复数分布样本上的对比,CVNN生成的样本更贴合目标分布。
图1:真实分布与RVNN、CVNN生成样本的对比。 直观展示了复数网络在建模复数值内在结构时的潜在优势。
- TTS管线评估:在表8中,将ComVo与Matcha-TTS声学模型结合,在TTS流程中取得了最高的UTMOS(3.4403)和可比的MOS(3.92),证明其作为声码器的集成能力。
- 计算开销与推理速度:表9显示,ComVo的参数量(13.28M)与基准接近,但内存占用(101.24MB)约为实值iSTFT模型的两倍(因其存储复数参数)。推理吞吐量(xRT)为819.02,低于Vocos(4657.65)但高于基于上采样的HiFi-GAN(259.08)和BigVGAN(158.07)。表10证明,在匹配内存占用下(GCDR vs. GRDR 2x),复数建模的质量增益仍优于单纯增大实值模型。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个完整、自洽的复数域GAN vocoder框架,创新点清晰(复数架构、相位量化、计算优化)。实验设计全面,对比了多种强基线,进行了深入的消融研究,并在多个数据集上验证。技术实现正确。不足之处在于,对于复数网络优势的理论解释稍显单薄,主要依赖于受控实验的观察;相位量化层的理论动机可以更深入地与信号处理理论结合。
- 选题价值:1.5/2:研究处于神经音频生成的前沿,解决的是一个具体但重要的技术痛点(复数谱建模)。复数建模是一个有潜力但相对小众的提升方向,其价值已被这篇系统性的研究所证实。对于关注语音合成质量极限、相位建模或计算效率的研究者和工程师有明确价值。
- 开源与复现加成:1.0/1:论文提供了极其完善的复现材料,包括代码仓库、预训练模型、详细的超参数配置(表20)、评估工具链接。这几乎达到了该领域的开源标杆水平,极大地降低了复现门槛。