📄 TINY BUT MIGHTY: A SOFTWARE-HARDWARE CO- DESIGN APPROACH FOR EFFICIENT MULTIMODAL IN- FERENCE ON BATTERY-POWERED SMALL DEVICES
#多模态模型 #大语言模型 #端到端 #实时处理 #系统优化
✅ 7.0/10 | 前25% | #多模态模型 | #预训练 | #大语言模型 #端到端
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yilong Li(University of Wisconsin – Madison)
- 通讯作者:未明确说明(论文未标注通讯作者信息)
- 作者列表:Yilong Li (1), Shuai Zhang (2), Yijing Zeng (1), Chengpo Yan (1), Hao Zhang (1), Xinmiao Xiong (1), Jingyu Liu (1), Pan Hu (3), Suman Banerjee (1)。机构:(1) University of Wisconsin – Madison, (2) Amazon Web Services AI, USA, (3) Uber, USA。
💡 毒舌点评
这篇论文最硬核的地方在于作者真的自己画了PCB、焊了板子、写了底层驱动来验证他们的想法,这种“手工打造端到端系统”的匠心在AI论文里相当少见。但遗憾的是,其核心的“模型分解与动态调度”思想在边缘计算领域已有先例,且论文对模型量化后在特定下游任务上的精度损失分析不够细致,更像是一个优化效果显著的“系统集成报告”。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开经过特定适配或优化的模型权重。
- 数据集:使用公开数据集(InfoVQA, DocVQA, MMBench, MME)进行评测,但未提及是否提供新的数据集。
- Demo:提供了自制硬件原型的实物照片(图11),但未提及在线演示。
- 复现材料:提供了非常详细的硬件设计图(图4)、软件架构图(图3)、关键内核的实现思路和全面的性能评测数据,但这些属于设计文档,而非开箱即用的复现材料。
- 论文中引用的开源项目:llama.cpp, whisper.cpp, Piper, RKNN Toolkit2, Qualcomm AI Hub, PowerInfer-2, MLC-LLM。
📌 核心摘要
这篇论文旨在解决大型多模态模型(LMMs)在电池供电的小型边缘设备上高效运行的难题。现有部署方案通常将模型作为整体在单一加速器上执行,无法充分利用现代片上系统(SoC)中的异构计算单元(CPU, GPU, NPU),导致资源浪费和高延迟。
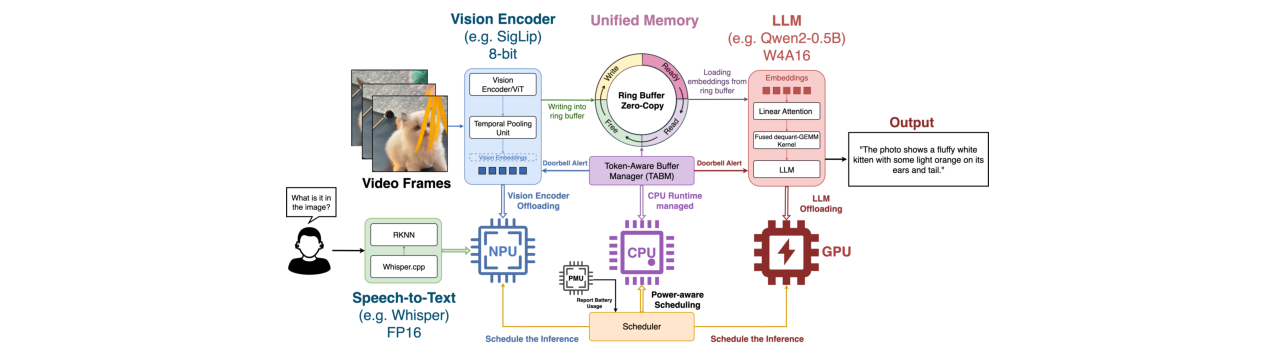
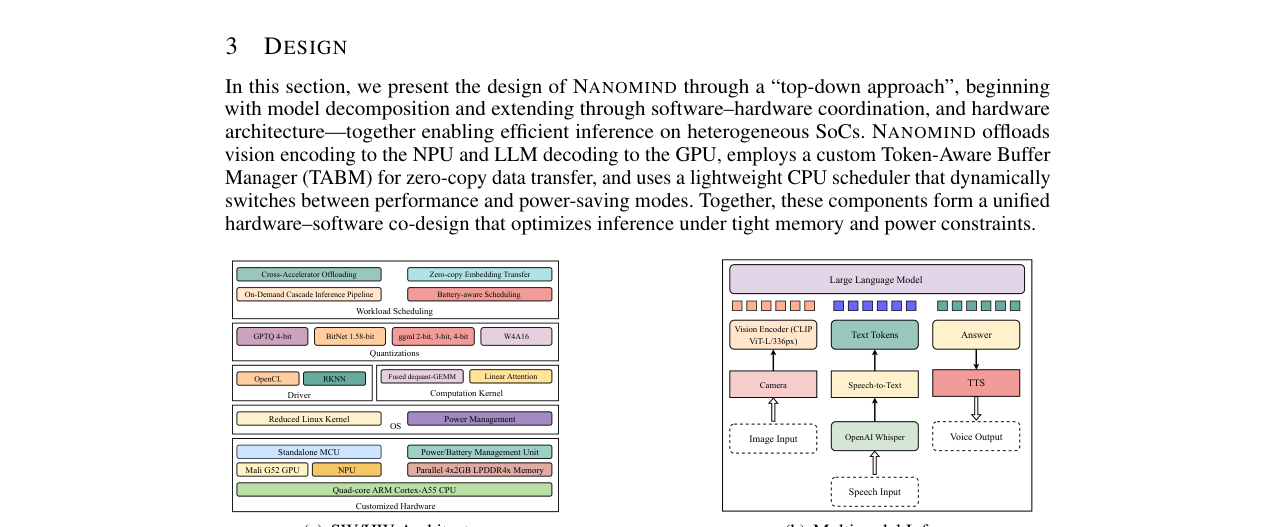
方法核心是提出一个名为NANOMIND的软硬件协同设计框架。其核心思想是将固有的模块化LMMs(如视觉编码器、投影器、语言解码器)分解为独立的“组件”,并根据各组件计算特性(如视觉编码适合NPU的低比特运算,语言解码适合GPU的并行浮点运算)和异构加速器的优势,进行动态跨加速器调度。同时,框架设计了Token感知缓冲区管理器(TABM)在统一内存架构下实现零拷贝数据传输,以及电池感知的执行模式。
与已有方法相比,新在以下几点:
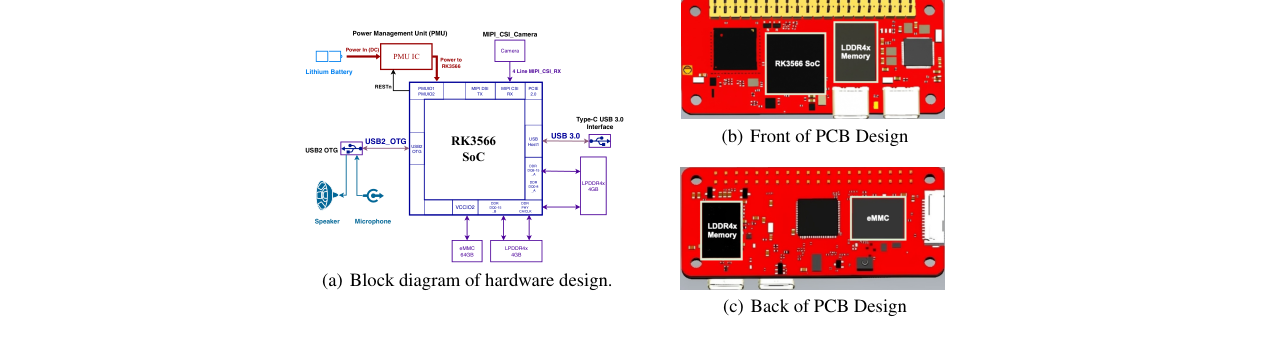
- 端到端软硬件协同设计:不仅停留在算法或软件层面,而是定制了硬件平台(基于RK3566 SoC,配备独立PMU)并开发了配套的底层计算内核和驱动。
- 模块级动态卸载:实现了跨NPU/GPU/CPU的细粒度任务调度,而非传统的层级卸载或单一加速器执行。
- 统一内存下的零拷贝优化:TABM设计有效解决了异构加速器间数据传输的瓶颈。
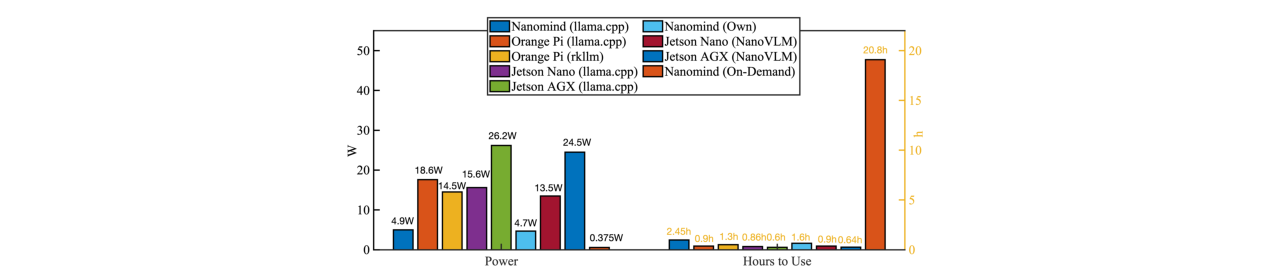
主要实验结果:在自制硬件原型上运行LlaVA-OneVision-qwen2-05B模型,与主流框架(如llama.cpp)相比,NANOMIND的能耗降低了42.3%,GPU内存使用减少了11.2%。在低功耗事件触发模式下,配合2000mAh电池,可实现长达20.8小时的运行时间(见图9)。在吞吐量方面,其定制的融合计算内核在Orange Pi 5 (RK3588)上运行Qwen2-1.5B模型时,性能优于llama.cpp、MLC-LLM等框架(见图7c)。
实际意义在于,它证明了通过深度的软硬件协同优化,在成本低廉(SoC价格<12美元)、功耗极低的小型设备上本地运行多模态大模型是可行的,为离线、隐私敏感的边缘AI应用提供了实用方案。
主要局限性是:1)框架的验证和性能提升高度依赖于作者定制的特定硬件平台(基于RK3566),在其他商用设备上的可移植性和性能优势需进一步验证;2)论文未深入讨论模型分解和量化对多模态任务(如复杂视觉问答)最终输出质量的影响;3)未提供开源代码或标准化模型,复现门槛较高。
🏗️ 模型架构
NANOMIND是一个系统级框架,其“模型架构”指的是它如何组织和运行一个多模态模型。其整体工作流程如论文图1所示。
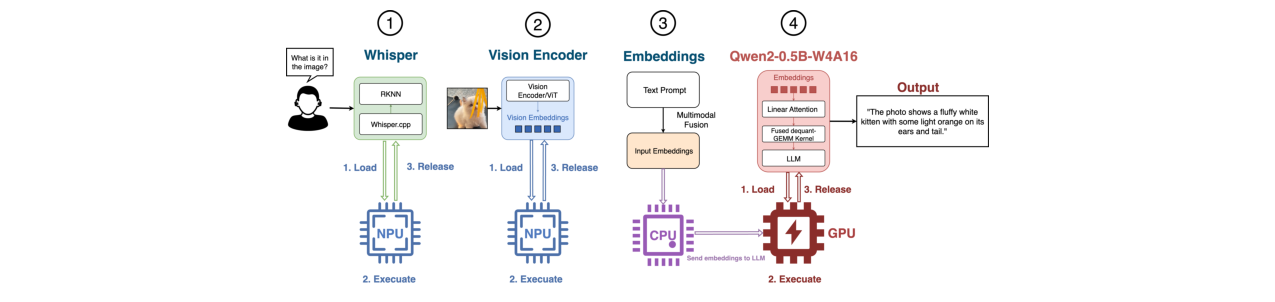
- 输入:摄像头图像和语音输入。
- 组件分解与加速器映射:
- 语音输入:由独立的Whisper-base模型(使用whisper.cpp)处理,转换为文本,运行在CPU上。
- 视觉编码:从VLMs(如LLaVA-OneVision, Qwen2-VL)中提取的视觉编码器(通常是SigLip ViT)被转换为RKNN格式,卸载到NPU上执行。输入图像被预处理为固定分辨率。
- 语言解码:VLM中的语言模型部分(如Qwen2-0.5B)被量化(如W4A16),卸载到GPU上运行。
- 数据流与交互:NPU产出的视觉嵌入向量和文本嵌入向量,通过Token感知缓冲区管理器(TABM) 管理的环形缓冲池,在统一内存中直接传递给GPU上的语言模型,实现零拷贝传输。TABM负责缓冲区的状态跟踪和同步。
- 输出:语言模型生成的文本答案,可通过Piper TTS系统转换为语音输出。
- 低功耗模式:在电池电量低时,系统切换到“按需级联推理”模式(见论文图2),每个模块(Whisper, ViT, LLM)遵循“加载→执行→释放”的生命周期,仅传递最小化输出,形成轻量级的级联执行链,以节省内存和功耗。
💡 核心创新点
- 异构加速器上的模块级动态卸载:核心创新在于打破了“模型整体运行于单一加速器”的范式。根据LMMs各组件(ViT, Projector, LLM)的计算特性(如ViT适合NPU的低比特整数运算,LLM的注意力机制适合GPU的并行浮点计算)和异构加速器的优势,进行动态任务分配和调度。这显著提高了SoC的整体资源利用率。
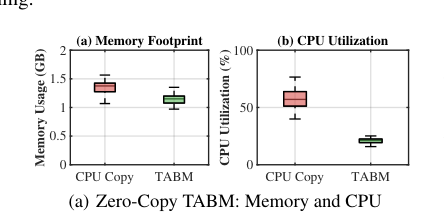
- 统一内存下的零拷贝嵌入传输机制(TABM):针对移动SoC统一内存架构(UMA)的特点,设计了轻量级的环形缓冲池和缓冲区管理器。它避免了传统框架(如llama.cpp在UMA下的实现)中CPU频繁管理数据拷贝带来的开销,实现了NPU与GPU之间的高效、低延迟数据流。
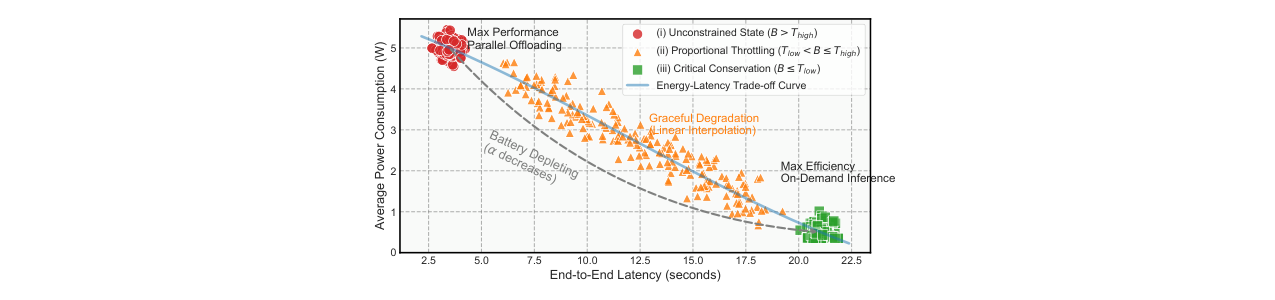
- 电池感知的自适应执行策略:引入了基于实时电池电量的三级性能管理模式(无约束、比例限流、关键保守)。系统能根据电池状态动态调整并行度、相机帧率和内存时钟,在性能和续航之间取得平滑权衡,这是实用的边缘AI系统设计。
- 定制软硬件协同设计:不仅设计了软件框架,还自行设计了硬件原型(基于RK3566的定制PCB,配备专用PMU)和底层计算内核(如融合的去量化-GEMM OpenCL内核),实现了从算法到硬件的完整优化闭环。
🔬 细节详述
- 训练数据:论文未提及模型训练数据,因为NANOMIND是一个推理框架,不涉及模型训练。它使用预训练并微调好的模型(如LLaVA-OneVision-Qwen2-0.5B)。
- 损失函数:未说明,因不涉及训练。
- 训练策略:未说明。
- 关键超参数:
- 模型:主要验证模型为LLaVA-OneVision-Qwen2-0.5B和Qwen2-VL-2B。
- 量化:GPU端LLM采用W4A16(4位权重,16位激活)量化,也支持更低比特(2/3位);NPU端ViT采用FP16或8位精度。
- 输入分辨率:视觉编码器输入被固定为384x384 (LLaVA-OneVision) 或 448x736 (Qwen2-VL)。
- 训练硬件:未说明(不适用)。
- 推理细节:
- 解码策略:论文未明确说明语言模型的解码策略(如贪心、采样)。
- 内核优化:在GPU上实现了融合的去量化-GEMM OpenCL内核,将反量化与矩阵乘法融合,减少内存流量;用线性注意力变体替代标准注意力以降低内存占用和长序列延迟。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
实验评估了NANOMIND在资源使用、吞吐量、能效等方面的表现。
内存使用对比:
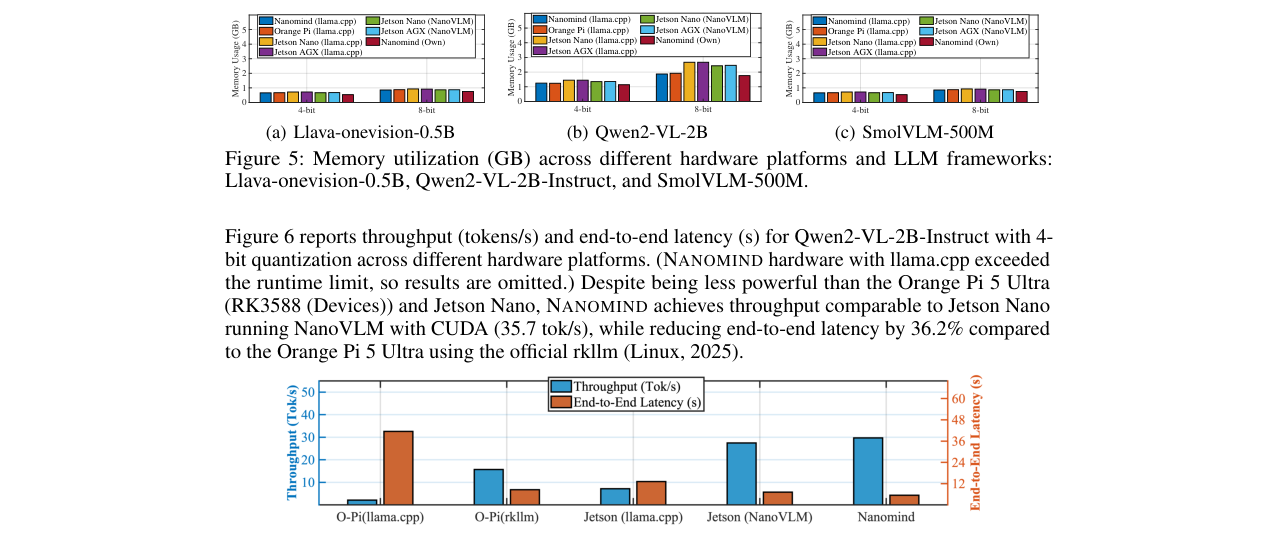
- 与llama.cpp在多个硬件平台(NANOMIND, Orange Pi 5, Jetson Nano/AGX)上运行多个VLM(LLaVA-OneVision-0.5B, Qwen2-VL-2B, SmolVLM-500M)进行了对比。
- 结果:NANOMIND(自有实现)在所有情况下内存使用均显著低于llama.cpp,也低于Jetson上的NanoVLM框架。例如,对于LLaVA-OneVision-0.5B(4-bit),llama.cpp在NANOMIND平台上使用约4.5GB内存,而NANOMIND自有实现仅使用约2.5GB(见图5a)。
吞吐量与端到端延迟:
- 在InfoVQA数据集上测试Qwen2-VL-2B-Instruct(4-bit)。
- 结果:NANOMIND(跨加速器调度)的吞吐量(约35 tok/s)与NVIDIA Jetson Nano(运行NanoVLM)相当。与性能更强的Orange Pi 5 Ultra(使用官方RKLLM)相比,NANOMIND的端到端延迟降低了36.2%(见图6)。
系统组件消融实验:
- 零拷贝TABM vs. 传统拷贝:TABM设计显著降低了内存使用和CPU利用率(图7a)。
- 视觉编码模型加速器对比:SigLip在NPU上的推理速度远快于GPU和CPU(图7b)。
- 融合内核性能:在Orange Pi 5 (RK3588)和RubikPi 3 (QCS6490)上运行Qwen2-1.5B-W8A8,NANOMIND的融合去量化-GEMM内核在纯GPU解码吞吐量上优于llama.cpp、MLC-LLM和PowerInfer-2(图7c)。
功耗与续航:
- 在自制硬件原型上,低功耗按需推理模式平均功耗为0.375W。
- 结果:配备2000mAh电池时,预计续航可达20.8小时(图9)。论文还展示了电池电量、延迟和功耗之间的权衡曲线(图8)。
⚖️ 评分理由
- 学术质量:5.5/7:论文在系统设计和工程实现上表现出色,提出了一个完整且创新的软硬件协同推理框架,并通过详实的实验(多平台、多模型对比)和自制硬件原型验证了其有效性,性能提升显著。技术正确性高。然而,其核心调度思想(异构卸载)并非独创,且对模型分解后各模块协同工作对最终输出质量的影响分析不够深入,更侧重于系统效率而非算法或模型本身的突破。
- 选题价值:1.0/2:在资源受限的边缘设备上运行多模态大模型是一个重要的前沿课题,对推动AI在隐私和离线场景的应用有实际价值。但论文工作高度聚焦于特定硬件平台(Rockchip SoC)上的系统集成与优化,对于广大从事模型算法研究的人员,其启发性相对有限。
- 开源与复现加成:0.5/1:论文提供了极其宝贵的硬件设计资料(PCB图)、软件架构图和详细的性能数据,具有很高的参考价值。但未开源任何代码、模型权重或标准化的评测脚本,使得完全复现其工作需要大量的硬件制作和底层开发工作,门槛较高。