📄 The Deleuzian Representation Hypothesis
#模型可解释性 #概念提取 #对比学习 #自监督学习 #基准测试
🔥 8.5/10 | 前25% | #模型可解释性 | #概念提取 | #对比学习 #自监督学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Clément Cornet (Université Paris-Saclay, CEA, List)
- 通讯作者:Clément Cornet (论文未明确标注通讯作者,根据单位信息推断)
- 作者列表:Clément Cornet (Université Paris-Saclay, CEA, List)、Romaric Besançon (Université Paris-Saclay, CEA, List)、Hervé Le Borgne (Université Paris-Saclay, CEA, List)
💡 毒舌点评
这篇论文将哲学思想(德勒兹的差异论)包装成了一个工程上简洁、实验上有效的概念提取新范式,确实超越了现有稀疏自编码器方法。其核心创新——聚类激活差异而非重建激活——思路清晰且有启发性。但最大的短板在于其评估高度依赖现有的有标签数据集(用于计算探针损失),对于真正无监督的、超越已知属性的“新概念”发现能力缺乏评估框架,且对语音/音频任务本身的方法论贡献有限。
🔗 开源详情
- 代码:提供。论文明确给出了代码仓库链接:https://github.com/ClementCornet/Deleuzian-Hypothesis。
- 模型权重:未提及。论文未公开其提取的概念向量词典或修改后的模型权重。
- 数据集:论文使用的数据集(ImageNet, WikiArt, IMDB, CoNLL-2003, AudioSet)均为公开数据集,并在附录B中给出了获取信息。
- Demo:未提及。
- 复现材料:提供了详尽的复现信息,包括实现细节(附录A:所有基线方法的超参数设置)、实验设置细节(附录B:数据集描述、模型版本、数据划分)、以及方法核心代码。
- 引用的开源项目:论文引用了多个开源项目/模型作为基线或工具,包括:scikit-learn (用于ICA)、ViT-Prisma (预训练SAE)、EleutherAI (预训练SAE)、OpenClip (CLIP实现)、PyTorch Hub (DinoV2)、HuggingFace上的多个模型(DeBERTa, BART, Pythia, AST)。
📌 核心摘要
- 问题:现有的稀疏自编码器(SAE)在提取神经网络内部可解释概念时面临训练困难、特征多义性以及依赖稀疏性作为可解释性代理等问题,需要一种更简单、更直接的概念提取方法。
- 方法核心:提出“德勒兹表征假说”,将概念定义为激活空间中数据样本之间的“差异”。具体方法是:随机采样激活差异向量,然后使用带有偏度逆权重(以促进多样性)的K-means聚类算法对这些差异进行聚类,聚类中心即为概念向量。
- 与已有方法的对比:与主流SAE方法(如重建+稀疏)不同,本方法不进行激活重建,而是直接识别和聚类“重复出现的差异”。它被形式化为一种无监督的判别分析,并在保持概念向量位于原始激活空间(便于无损引导)的同时,仅需一个可解释的超参数(概念数量k)。
- 主要实验结果:在涵盖视觉、语言、音频三个模态的五个模型和五个数据集上进行了广泛评估。结果显示,在探针损失(Probe Loss)指标上,该方法在13/20个任务中超越了所有SAE变体,其表现接近有监督的线性判别分析(LDA)基线。在跨运行一致性(MPPC)上也表现优异。关键实验数据对比如下表所示:
方法 CLIP (WikiArt Artist) DinoV2 (WikiArt Artist) DeBERTa (CoNLL-2003 NER) BART (CoNLL-2003 POS) AST (AudioSet) 平均排名 ↓ Deleuzian (Ours) 0.0119 0.0055 0.0665 0.2148 0.0164 1.65±0.85 Tk-SAE 0.0125 0.0096 0.0839 0.3478 0.0169 2.65±1.01 A-SAE 0.0130 0.0143 0.0775 0.3754 0.0169 3.20±1.72 LDA (监督基线) 0.0084 0.0044 0.0429 0.6326 0.0164 - - 实际意义:提供了一种更简洁、可解释性更强的概念提取工具,可用于分析模型内部表征、进行概念引导(Steering)以可控地修改模型行为(如图像风格迁移、文本生成控制),为理解和调试大规模神经网络提供了新途径。
- 主要局限性:方法的评估依赖于带有语义标签的数据集,可能无法评估与已知标签无关的“新颖”概念。假设概念可在线性方向上表示,这一假设可能在某些模型中不成立。引导效果虽为定性展示,但系统性量化仍需更多研究。
🏗️ 模型架构
该方法并非一个传统的神经网络架构,而是一个用于从预训练模型激活中提取概念的流程(Pipeline)。其核心流程如下:
- 输入:给定一个预训练模型(如CLIP、DeBERTa)及其在某个数据集上的激活向量集合(维度为D)。
- 差异采样:随机配对数据样本,计算它们激活向量之间的差值,形成一个差异向量集合 D。这步在近似“样本间的差异”分布。
- 偏度加权:对于每个差值向量,计算其在所有样本上投影值的偏度(skewness)。偏度高的差值向量被认为是冗余的。因此,为每个差值向量分配一个权重,该权重与其偏度成反比(1/偏度),以降低其在聚类中的影响力。
- 聚类:使用加权K-means聚类算法对加权后的差值向量进行聚类。算法旨在找到k个聚类中心,这些中心代表了“重复出现的差异模式”,即提取出的概念向量。
- 输出:k个概念向量,每个向量都位于原始模型的激活空间中,可直接用于下游任务如探针评估或概念引导。
与判别分析的联系:论文在理论上论证了该过程等价于一种无监督的线性判别分析(LDA)。在假设各类激活分布为各向同性的高斯分布时,两类样本的差值向量 xi - xj 正是最大化类间分离的最优方向。因此,聚类这些差值向量就是在寻找数据中反复出现的、最具判别力的“差异方向”。
概念引导:由于概念向量 ci 位于激活空间,对样本 x 进行引导只需线性操作:x_steered = x + α * ci。这避免了SAE方法中编码-解码带来的重建误差,实现了无损引导。

图2:概念提取方法流程概览图。展示了从模型激活中随机采样差异向量,经过偏度加权后,通过K-means聚类得到最终概念向量的过程。
💡 核心创新点
基于“差异”的概念定义:是什么:将“概念”定义为神经网络激活空间中表征样本间差异的方向,灵感来源于德勒兹的哲学思想。之前局限:SAE等方法基于“重建误差”,隐式地将概念视为表征激活空间主要方差(即普遍结构)的成分。如何起作用/收益:直接建模差异更贴近分类、判别等核心任务。实验证明这种视角下提取的概念在探针损失指标上优于基于重建的SAE,能更好地捕获与任务相关的语义属性。
偏度加权聚类以提升多样性:是什么:在对差值向量进行K-means聚类时,根据每个差值向量分布的偏度(第三阶矩)进行反向加权。之前局限:标准聚类易受少数极端值(高偏度)主导,导致概念冗余。如何起作用/收益:通过惩罚偏度高的差值方向,迫使聚类结果覆盖更多样的差异模式。消融实验(表3)证实,此步骤显著提升了概念的有效秩(多样性)并降低了最大成对余弦相似度(冗余度),是提升整体性能的关键组件。
无损的概念引导机制:是什么:利用概念向量位于原始激活空间这一特性,通过直接向量加减实现对模型内部表征的干预。之前局限:基于SAE的引导需要将激活投影到潜在空间(编码)、施加干预、再投影回激活空间(解码),两次投影不可避免地引入重建误差和信息损失。如何起作用/收益:实现了数学上精确可逆的引导操作,定性实验(如图4)展示了其对文本生成的因果影响力,为模型调试和可控生成提供了更干净的工具。
🔬 细节详述
- 训练数据:评估使用了五个标准数据集:ImageNet-100(图像分类)、WikiArt(图像艺术风格/流派/作者)、IMDB(文本情感)、CoNLL-2003(文本命名实体/词性/组块)、AudioSet(音频事件)。这些数据集用于提取概念并计算探针损失。
- 损失函数:方法本身无传统神经网络损失函数。其核心是K-means聚类,目标是最小化加权类内平方和(见公式d(di, ¯C))。探针损失用于评估提取概念的质量,为二元或多类逻辑回归的交叉熵损失。
- 训练策略:方法是非迭代学习的。差异采样、偏度计算、加权K-means聚类是一次性完成的流程。K-means的具体初始化和迭代次数未在主文说明。
- 关键超参数:概念数量k:唯一的可解释超参数,所有实验设定为6144。激活空间:分析均使用模型最后一个Transformer块的输出。
- 训练硬件:论文中未说明。
- 推理细节:概念提取是离线完成的。概念引导时,在模型前向传播过程中直接对中间层激活进行向量加法操作(
x + α*ci),然后继续后续前向传播。 - 正则化或稳定训练技巧:通过偏度逆权重(1/µ̃3)对K-means聚类进行正则化,以促进概念多样性并抑制冗余。通过将负偏度的差值向量取反(
-di),确保了权重始终为正。
📊 实验结果
主要结果:概念质量(探针损失) 论文在5个模型、5个数据集、多个任务上对比了多种方法。探针损失越低越好。下表总结了关键结果(完整表格见论文表1):
| 方法 | CLIP WikiArt (Artist↓) | DinoV2 WikiArt (Genre↓) | DeBERTa CoNLL (POS↓) | AST AudioSet (Median↓) | 平均排名 ↓ |
|---|---|---|---|---|---|
| Deleuzian (Ours) | 0.0119 | 0.1230 | 0.2148 | 0.0164 | 1.65 ± 0.85 |
| Tk-SAE | 0.0125 | 0.1360 | 0.3478 | 0.0169 | 2.65 ± 1.01 |
| Van-SAE | 0.0137 | 0.1531 | 0.2719 | 0.0177 | 4.65 ± 1.56 |
| LDA (监督) | 0.0084 | 0.0976 | 0.6326 | 0.0164 | - |
| 结论:Deleuzian方法在平均排名上显著优于所有SAE基线。在13/20个任务上取得最低的探针损失,其表现介于无监督SAE和有监督LDA之间,在多个任务上接近甚至超越LDA(如BART-POS任务)。 |
概念一致性(MPPC) 使用最大成对皮尔逊相关系数(MPPC)评估不同随机种子下提取概念的一致性,值越接近1越好。
| 数据集/模型 | CLIP-ImNet | CLIP-WA | DinoV2-ImNet | DeBERTa-IMDB | AST-AudioSet |
|---|---|---|---|---|---|
| Deleuzian (Ours) | 0.821 | 0.856 | 0.789 | 0.980 | 0.830 |
| Tk-SAE | 0.757 | 0.861 | 0.588 | 0.866 | 0.601 |
| Van-SAE | 0.840 | 0.918 | 0.603 | 0.986 | 0.837 |
| 结论:Deleuzian方法的概念一致性非常高,通常位列前两名。特别是在BART和AST模型上表现突出。 |
消融实验 在CLIP-WikiArt和DeBERTa-CoNLL上验证了三个关键设计的影响(见论文表3):
- 输入空间(差异 vs. 激活):使用激活差异(diff)作为输入,比直接使用原始激活(acts.)在探针损失和多样性上都有巨大提升。
- 聚类方法(K-means vs. SAE):K-means在差异上聚类,比TopKSAE在差异上训练,能获得好得多的探针损失和更高的多样性。
- 偏度加权(有 vs. 无):启用偏度加权后,概念的有效秩(多样性)从5.65/17.9大幅提升至182.0/124.4,最大成对余弦(冗余度)显著下降,同时探针损失进一步改善。
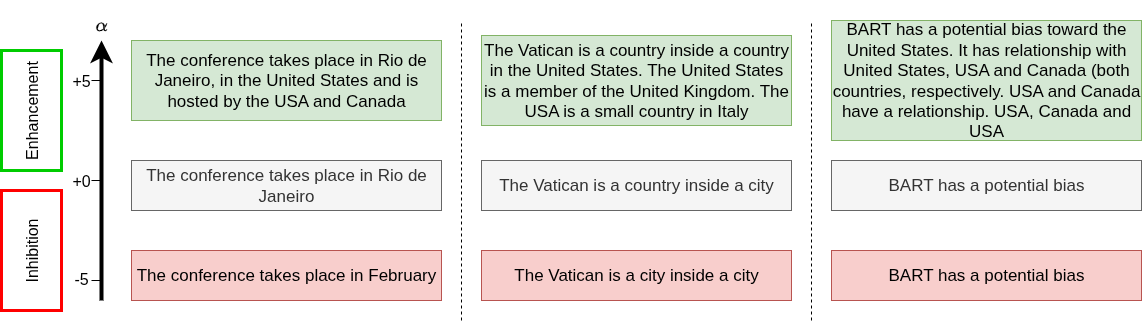
图5:不同概念数量下的性能曲线。展示了在CLIP-WikiArt-任务上,随着提取概念数量k从0增加到6144,Deleuzian方法的性能(1-探针损失)变化。曲线表明,仅需约2000个概念,其性能就已超越所有比较的基线方法。
⚖️ 评分理由
- 学术质量:6.5/7:创新:将哲学思想转化为一个简洁、可解释且有效的技术方案,视角新颖。技术正确性:方法流程清晰,与判别分析的理论联系合理,数学推导(如偏度加权、二次扩展)正确。实验充分性:实验设计非常全面,覆盖了三个模态、多个主流模型、大量任务和数据集,并与众多基线(包括多种SAE变体)进行了公平对比。评估指标(探针损失、MPPC)选择恰当,消融实验充分验证了各组件贡献。证据可信度:结果具有统计显著性(附录中给出了Wilcoxon检验p值),定性引导示例直观地展示了因果影响。
- 选题价值:1.5/2:前沿性:模型可解释性是当前AI安全与信任的核心议题,该工作为概念提取提供了新思路。潜在影响:方法简洁、易于复现且效果好,有潜力成为SAE之外的另一种标准工具,尤其适用于需要无损干预的场景。应用空间:可用于模型调试、偏见检测、可控生成(如图像风格、文本内容)等。与音频/读者相关性:论文包含音频任务(AST模型,AudioSet数据集),证明了方法的跨模态适用性,但其核心贡献在于通用的模型解释方法,而非针对音频任务的特定创新。
- 开源与复现加成:0.5/1:论文在可重复性声明中提供了明确的代码仓库链接(https://github.com/ClementCornet/Deleuzian-Hypothesis),并详细描述了方法实现和实验设置(附录A、B)。这大大增强了论文的可信度和可复现性。但未提及是否提供预训练好的概念词典或模型权重。