📄 TangoFlux: Super Fast and Faithful Text to Audio Generation with Flow Matching and Clap-Ranked Preference Optimization
#音频生成 #流匹配 #偏好优化 #扩散模型 #开源模型
🔥 8.0/10 | 前25% | #音频生成 | #流匹配 | #偏好优化 #扩散模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Chia-Yu Hung (Nanyang Technological University, NTU)
- 通讯作者:Navonil Majumder (NTU), Soujanya Poria (NTU)
- 作者列表:Chia-Yu Hung (NTU), Navonil Majumder (NTU), Zhifeng Kong (NVIDIA), Ambuj Mehrish (Ca’ Foscari University of Venice), Amir Ali Bagherzadeh (Lambda Labs), Chuan Li (Lambda Labs), Rafael Valle (NVIDIA), Bryan Catanzaro (NVIDIA), Soujanya Poria (NTU)
💡 毒舌点评
这篇论文巧妙地将CLAP作为“裁判”来解决音频生成对齐中缺乏自动评价标准的痛点,提出的CRPO“自弈”优化思路确实让模型性能在迭代中不断提升,效果立竿见影。但依赖CLAP这个“裁判”本身的偏好(可能偏向特定音频风格或描述理解能力)进行优化,是否会让模型学会“讨好裁判”而非真正理解复杂、抽象的文本描述?这是CRPO框架需要面对的更深层问题。
📌 核心摘要
- 要解决什么问题:文本到音频生成模型面临对齐(Alignment)挑战,即生成内容与文本描述不完全匹配,存在事件遗漏、顺序错误甚至“幻觉”。主要瓶颈是构建偏好数据集(用于对齐训练)困难,因为音频领域缺乏像语言模型那样的标准化答案或现成奖励模型。
- 方法核心是什么:提出TangoFlux模型和CLAP-Ranked Preference Optimization(CRPO)框架。TangoFlux是基于流匹配(Rectified Flow)和Transformer架构的高效TTA模型。CRPO的核心是迭代式“自改进”:在每个训练迭代中,用当前模型为每个提示生成多个音频样本,利用CLAP(一个文本-音频联合嵌入模型)对这些样本按与文本的匹配度进行排序,从而自动构建偏好对(赢家-输家),再用改进的DPO损失(LCRPO)进行优化。
- 与已有方法相比新在哪里:a) 动态数据生成:不同于使用静态偏好数据集(如BATON, Audio-Alpaca),CRPO在每次迭代中都生成新的偏好数据,使模型能持续自我优化,避免在固定数据上过拟合。b) 代理奖励模型:成功验证了CLAP可作为有效的音频对齐代理奖励模型,解决了构建偏好数据的关键障碍。c) 优化目标改进:提出了LCRPO损失函数,在标准DPO损失(LDPO-FM)的基础上加入了赢家样本的流匹配损失作为正则项,以防止对齐过程中音频保真度的下降。
- 主要实验结果如何:TangoFlux(515M参数)在AudioCaps测试集上的多个客观指标(如CLAPscore: 0.480, FDopenl3: 75.1)和人类评估(整体质量OVL和相关性REL的z-score、Elo分数)上均优于之前的SOTA模型(如Tango 2, Stable Audio Open)。它在A40 GPU上生成30秒音频仅需3.7秒,速度优势明显。消融实验证明,CRPO动态生成的数据优于静态偏好数据集;LCRPO损失函数优于标准的LDPO-FM损失。
- 主要对比结果表(来自论文表1、表2、表3):
模型 参数量 生成时长 步数 FDopenl3↓ KLpasst↓ CLAPscore↑ 推理时间(s) Tango 2 866M 10s 200 108.4 1.11 0.447 22.8 Stable Audio Open 1056M 47s 100 89.2 2.58 0.291 8.6 TANGOFLUX (最终) 515M 30s 50 75.1 1.15 0.480 3.7 模型 z-score (OVL) z-score (REL) Elo (OVL) Elo (REL) :— :— :— :— :— Tango 2 -0.019 0.1602 1,419 1,507 SA Open 0.0723 -0.3584 1,444 1,268 TANGOFLUX 0.2486 0.6919 1,501 1,628 对齐方法 FDopenl3↓ CLAPscore↑ KLpasst↓ Elo (REL) :— :— :— :— :— TANGOFLUX-base (未对齐) 80.2 0.431 1.22 1,253 TANGOFLUX-baton (静态数据) 80.5 0.437 1.20 1,392 TANGOFLUX (CRPO动态数据) 75.1 0.480 1.15 1,520
- 主要对比结果表(来自论文表1、表2、表3):
- 实际意义是什么:提供了构建高效、可控、高质量文本到音频生成系统的可行路径。CRPO框架为多模态内容生成的对齐问题提供了一种通用的、可自动化的解决方案。开源模型和代码有助于社区进一步研究和应用。
- 主要局限性是什么:a) 对齐质量上限受限于作为代理奖励模型的CLAP的能力与偏见。b) 自动构建的偏好数据可能无法完全捕捉复杂、主观的人类偏好(如创意性、情感细微差别)。c) 模型对超长、超复杂或高度抽象的文本描述的生成能力仍有待验证。
详细分析
TangoFlux的整体架构和训练流程可概括为“预训练-对齐”两阶段,并包含一个创新的在线迭代对齐循环。
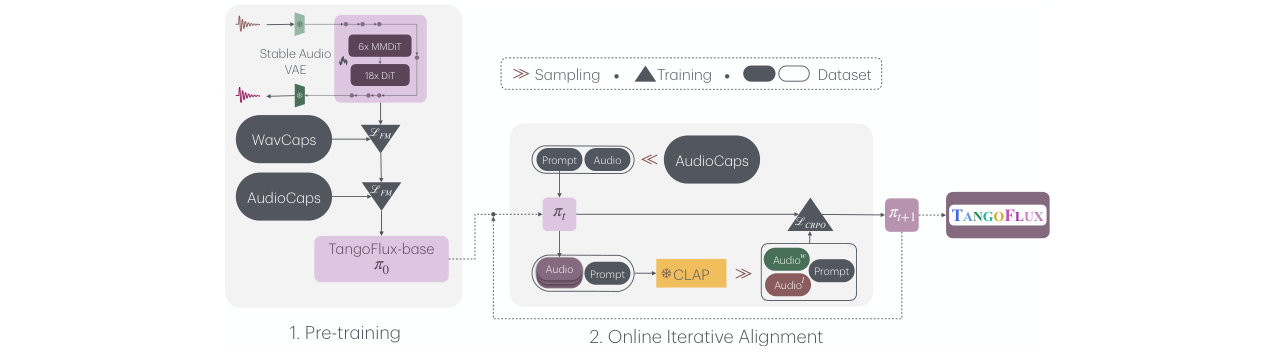
图1:TangoFlux的整体训练流程图。 该图清晰地展示了训练的两个主要阶段:1)预训练:使用WavCaps和AudioCaps数据集,通过流匹配损失(ℒFM)训练TangoFlux-base模型。2)在线迭代对齐(CRPO):这是论文的核心。从基线模型π₀开始,迭代地进行三个步骤:a) 采样:从提示库中采样一批提示,用当前模型πk为每个提示生成多个音频样本。b) 训练数据构建:使用CLAP模型对生成的音频进行评分和排序,为每个提示构建赢家-输家偏好对,形成数据集𝒟k。c) 训练:使用该数据集,结合流匹配损失(ℒFM)和DPO损失(ℒCRPO)将模型πk优化为πk₊₁。这个循环迭代进行,使模型持续自我改进。
模型架构细节:
- 骨干网络:采用混合Transformer架构,结合了6个多模态扩散Transformer(MMDiT) 块和18个扩散Transformer(DiT) 块。MMDiT块能更好地融合条件信息,而DiT块则更简洁高效,这种混合设计平衡了性能与扩展性。每个块有8个注意力头,隐藏维度128,总宽度1024,总参数量约515M。
- 条件控制:采用双重条件控制:
- 文本条件:使用预训练的FLAN-T5编码器对输入文本提示进行编码,得到文本嵌入
c_text。 - 时长条件:为了实现可变时长生成(最长30秒),使用一个小型神经网络将目标时长编码为时长嵌入
c_dur。关键在于,模型始终在固定长度(对应30秒音频)的潜空间上操作,c_dur明确控制其中多少部分用于存放实际音频内容,其余部分填充静音。
- 文本条件:使用预训练的FLAN-T5编码器对输入文本提示进行编码,得到文本嵌入
- 音频编码:使用来自Stable Audio Open的预训练变分自编码器(VAE)。它将44.1kHz的立体声波形编码为潜表示
Z,并在推理时将模型生成的潜表示解码回波形。VAE在TangoFlux训练期间保持冻结。 - 生成过程(流匹配):模型学习一个从噪声
x₀(高斯分布)到目标潜表示x₁的“速度场”u(x_t, t; θ)。在推理时,从纯噪声x₀开始,使用Euler求解器(或Heun求解器)沿着学习到的速度场迭代求解50步,最终得到干净的音频潜表示x₁,再经VAE解码得到音频。
CLAP-Ranked Preference Optimization (CRPO) 框架:
- 是什么:一种动态的、迭代式的偏好数据生成与模型对齐方法。它让模型在训练过程中持续生成自己的“教材”(偏好数据),并用它来优化自己。
- 之前方法的局限:之前为TTA模型对齐构建偏好数据主要依赖:a) 人工标注(如BATON),成本高、难以规模化;b) 静态合成数据集(如Audio-Alpaca),灵活性差,无法随模型进化。
- 如何起作用:在每次迭代中,用当前模型生成多个样本,用CLAP(作为代理奖励模型)自动排序构建偏好对,然后执行DPO优化。这形成了一个“生成-评估-优化”的闭环。
- 带来的收益:实验证明,由CRPO动态生成的数据集,在后续对齐训练中,性能显著优于使用静态的BATON和Audio-Alpaca数据集(见表3)。在线生成优于离线固定数据(见图2),避免了过早的性能饱和与退化。
针对流匹配的LCRPO损失函数:
- 是什么:在标准DPO-FM损失(LDPO-FM)的基础上,额外加入了赢家样本的流匹配损失(LFM)作为正则项。
- 之前方法的局限:直接将LLM上的DPO损失(LDPO-FM)应用于流匹配模型时,观察到赢家和输家的损失值会同时上升(见图4),这可能表明优化过度,导致生成音频偏离高质量的分布(奖励黑客问题)。
- 如何起作用:
ℒ_CRPO = ℒ_DPO-FM + ℒ_FM。额外的ℒ_FM项锚定了模型对赢家样本的建模能力,防止其在拉大赢家-输家差距的同时,自身质量也下降。 - 带来的收益:图3和图4表明,与仅使用LDPO-FM相比,LCRPO的损失增长更平稳,且在保持相似KL散度和FD的情况下,取得了更高的CLAP分数,优化过程更稳定。
高效且强大的文本到音频生成模型TangoFlux:
- 是什么:一个参数量适中(515M)、基于流匹配、支持可变时长、训练数据全公开的TTA模型。
- 之前方法的局限:许多高性能的TTA模型(如Stable Audio, MusicGen)使用私有数据训练;扩散模型通常需要大量去噪步数(100-200步),推理慢。
- 如何起作用:采用MMDiT/DiT混合架构和流匹配目标,流匹配相比扩散通常更高效(更少的采样步数达到更好质量)。通过时长条件控制实现变长生成。使用公开数据(WavCaps, AudioCaps)训练。
- 带来的收益:在仅需50步、3.7秒推理时间内,生成44.1kHz的30秒音频,并在多个基准上达到SOTA(表1),证明了其在效率和效果上的优势。
- 训练数据:
- 预训练数据:WavCaps数据集(约40万条音频及描述)。所有音频被处理为单声道,然后复制为伪立体声以兼容VAE。短于30秒的填充静音至30秒,长于30秒的中心裁剪至30秒。
- 微调数据:AudioCaps训练集(约4.5万条)。
- CRPO偏好数据:从AudioCaps训练集中随机采样20,000个提示,每个提示用当前模型生成5个音频,用CLAP(
630k-audioset-best检查点)对5个音频评分,选取最高分和最低分构成一对偏好数据。
- 损失函数:
- 流匹配损失(ℒ_FM):
ℒ_FM = E_{x₁,x₀,t} ||u(x_t, t; θ) - v_t||²,其中v_t = x₀ - x₁是真实速度。用于预训练和作为CRPO损失的一部分。 - DPO-FM损失(ℒ_DPO-FM):见公式(2)。通过对比赢家(
x_w)和输家(x_l)在模型θ和参考模型θ_r(固定为每轮迭代开始时的检查点)下的流匹配损失,来优化偏好排序。 - CLARPO损失(ℒ_CRPO):
ℒ_CRPO = ℒ_DPO-FM + ℒ_FM。ℒ_FM在赢家样本上计算。
- 流匹配损失(ℒ_FM):
- 训练策略:
- 预训练:在WavCaps上训练80个epoch。使用AdamW优化器(β1=0.9, β2=0.95),峰值学习率
5e-4,线性warmup 2000步。批次大小80(5个A40 GPU,每卡16)。 - 微调:在AudioCaps训练集上继续微调65个epoch,得到TANGOFLUX-base。
- 对齐(CRPO迭代):批次大小48,峰值学习率
1e-5,线性warmup 100步。每次CRPO迭代训练8个epoch,取最后一个epoch的检查点用于下一轮的数据生成。共进行5次迭代。
- 预训练:在WavCaps上训练80个epoch。使用AdamW优化器(β1=0.9, β2=0.95),峰值学习率
- 关键超参数:
- 模型参数:515M。
- 隐藏维度:1024。
- 注意力头数:8。
- 流匹配时间步
t采样:从logit-normal分布(均值0,方差1)中采样。 - 推理:Euler求解器, 50步,Classifier-Free Guidance (CFG) 比例=4.5。
- 训练硬件:5个NVIDIA A40 GPU。
- 推理细节:模型始终在30秒的固定潜空间上操作。通过时长嵌入控制生成内容占实际时长的比例。推理时,采样一个长度为30秒对应的潜空间噪声,经50步Euler积分得到潜表示,再经VAE解码为波形。若请求时长小于30秒,则取前对应时长的音频。
- 正则化/稳定技巧:在LCRPO损失中添加赢家样本的流匹配损失作为正则化项,以稳定优化过程,防止奖励黑客。
论文在AudioCaps测试集上进行了全面的客观和主观评估。
- 主要对比结果(客观指标):见下表。TangoFlux在大多数指标上取得最优,尤其在衡量音频-文本对齐的CLAPscore和衡量音频质量的FDopenl3上优势明显。推理速度也是其显著优势。
| 模型 | 参数量 | 生成时长 | 步数 | FDP ↓ | FDopenl3 ↓ | KLpasst ↓ | KAD ↓ | CLAPscore ↑ | IS ↑ | 推理时间(s) |
|---|---|---|---|---|---|---|---|---|---|---|
| ConsistencyTTA | 559M | 10s | 1 | 20.9 | 94.6 | 1.43 | 0.61 | 0.377 | 9.1 | <0.2 |
| AudioLCM | 160M | 10s | 1 | 19.2 | 107.4 | 1.58 | 0.56 | 0.363 | 10.2 | <0.2 |
| AudioLDM 2-large | 712M | 10s | 200 | 33.2 | 108.3 | 1.81 | 1.78 | 0.419 | 7.9 | 24.8 |
| Make-An-Audio 2 | 160M | 10s | 100 | 15.6 | 98.7 | 1.33 | 0.45 | 0.406 | 9.4 | 2.3 |
| EzAudio-XL | 874M | 10s | 200 | 15.8 | 84.7 | 1.20 | 0.15 | 0.460 | 10.8 | 12.2 |
| Stable Audio Open | 1056M | 47s | 100 | 42.6 | 89.2 | 2.58 | 4.15 | 0.291 | 9.9 | 8.6 |
| Tango | 866M | 10s | 200 | 24.5 | 107.9 | 1.20 | 1.71 | 0.407 | 7.8 | 22.8 |
| Tango 2 | 866M | 10s | 200 | 20.8 | 108.4 | 1.11 | 1.38 | 0.447 | 9.0 | 22.8 |
| GenAU-Full-L | 1.25B | 10s | 100 | 20.1 | 93.2 | 1.37 | 0.96 | 0.447 | 12.0 | 5.3 |
| AudioX | 1.1B | 10s | 250 | 25.2 | 77.6 | 1.56 | 1.30 | 0.380 | 10.0 | 9.6 |
| TANGOFLUX-base | 516M | 30s | 50 | 20.7 | 80.2 | 1.22 | 0.67 | 0.431 | 11.7 | 3.7 |
| TANGOFLUX | 516M | 30s | 50 | 20.3 | 75.1 | 1.15 | 0.60 | 0.480 | 12.2 | 3.7 |
- 主要对比结果(人类评估):在50个复杂提示上,由至少4名标注员进行0-100分的评分,评估整体音频质量(OVL)和文本相关性(REL)。指标包括z-score、排名和Elo分数。TangoFlux在所有指标上均领先。
| 模型 | z-scores | Ranking (Mean, Mode) | Elo | |||
|---|---|---|---|---|---|---|
| OVL | REL | OVL | REL | OVL | REL | |
| AudioLDM 2 | -0.3020 | -0.4936 | 3.5, 4 | 3.7, 4 | 1,236 | 1,196 |
| SA Open | 0.0723 | -0.3584 | 2.4, 1,3 | 3.3, 3 | 1,444 | 1,268 |
| Tango 2 | -0.019 | 0.1602 | 2.4, 2 | 1.9, 2 | 1,419 | 1,507 |
| TANGOFLUX | 0.2486 | 0.6919 | 1.7, 2 | 1.1, 1 | 1,501 | 1,628 |
- 关键消融实验:
- CRPO vs 静态偏好数据集(表3):使用CRPO动态数据对齐的TangoFlux,在CLAPscore(0.480 vs 0.437/0.448)和人类评估Elo分数上,显著优于使用BATON或Audio-Alpaca静态数据对齐的版本。
图2:在线CRPO与离线CRPO的训练曲线对比。 该图显示了5次迭代中CLAPscore、IS和KLpasst的变化。离线CRPO(使用固定数据)在第二轮后CLAPscore开始下降,KLpasst上升,表明过拟合和性能退化。在线CRPO(每轮生成新数据)的CLAPscore持续上升至第4轮,KLpasst持续下降,IS持续上升,证明了动态数据生成的必要性和有效性。
LCRPO vs LDPO-FM(图3,图4):
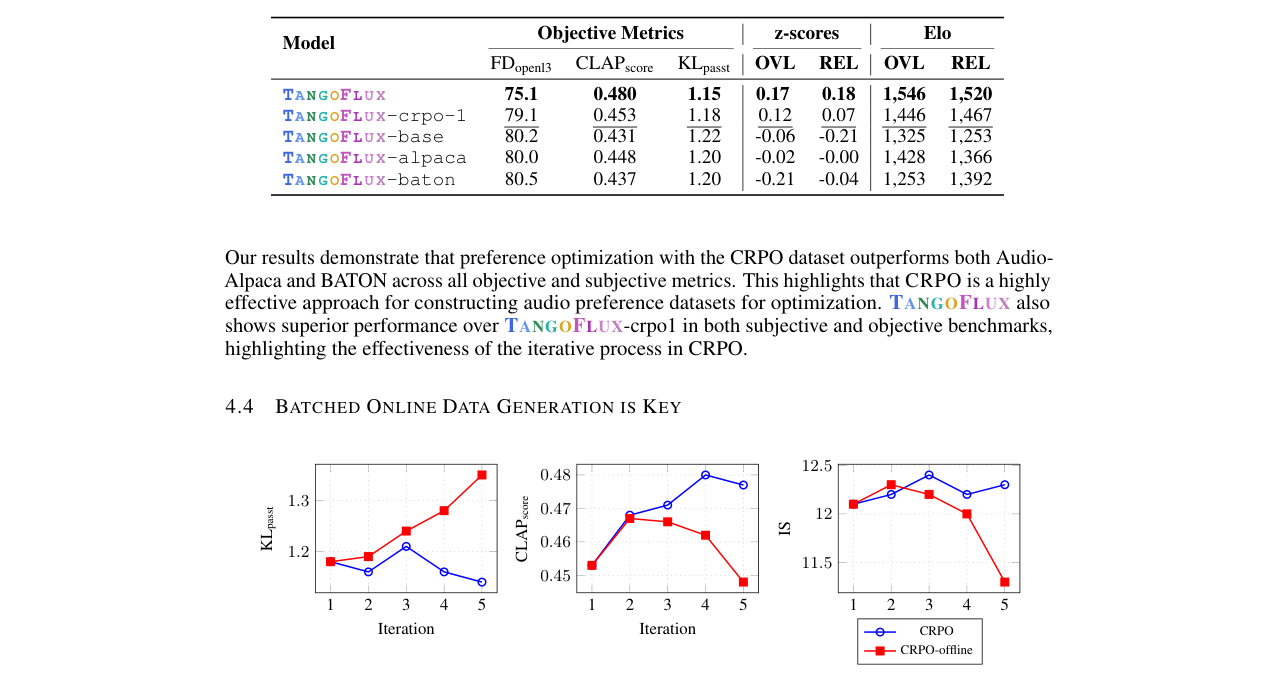
图3:LCRPO与LDPO-FM在不同迭代次数下的性能指标对比。 (a) CLAPscore:LCRPO持续提升且高于LDPO-FM。(b) FDopenl3:两者相近。(c) KLpasst:两者相近。表明LCRPO在提升对齐度(CLAPscore)的同时,能维持生成质量和多样性。
图4:LCRPO与LDPO-FM的赢家/输家损失随迭代次数的变化。 两种损失函数的赢家和输家损失都随迭代增加,且差值(margin)也在拉大。但LCRPO的损失增长更平缓、稳定,而LDPO-FM在迭代3后增长加速,可能暗示优化不稳定或过拟合。
- 其他重要实验:
- 每个提示生成音频数量(N)的影响(表4):N=5或10略优于N=2,但差异不大,需权衡计算成本。
- CLAP作为奖励模型的验证(表5):采用Best-of-N策略(N从1增加到15),CLAPscore提升,KLpasst下降,FDopenl3不变,证明CLAP能有效识别更对齐的样本,且不损害多样性/质量。
- CFG比例的影响(表6):存在权衡。CFG=3.5时CLAPscore最高(0.481),CFG=4.5或5.0时FDopenl3更低(75.1/74.6)。论文最终选择CFG=4.5。
- 求解器对比(表7):Euler求解器(50步)略优于Heun求解器(100步),CLAPscore 0.480 vs 0.474。
- 时长控制准确性(图5):生成的音频实际时长与请求时长高度匹配。
图6:不同模型CLAPscore与推理时间的对比曲线。 (a) CLAPscore vs Inference Time:TangoFlux在3.7秒(50步)时达到0.480,远超同时间点的其他模型。(b) FDopenl3 vs Inference Time:TangoFlux在3.7秒时FDopenl3为75.1,表现优异。这直观展示了其在效率-效果上的领先地位。
- 学术质量:6.0/7。论文的创新点(CRPO框架、LCRPO损失)设计合理,且通过严谨的实验(多基线对比、多角度消融、客观与主观评估相结合)得到了充分验证。技术细节描述清晰,论证逻辑连贯。不足之处在于模型架构本身不是最前沿的颠覆性设计,且对齐效果受限于CLAP这一代理模型。
- 选题价值:1.5/2。文本到音频生成是当前AI生成内容(AIGC)的重要前沿,具有巨大的创意产业应用潜力。本文直击该领域从“生成”到“可控、高质量生成”的关键瓶颈——数据高效的对齐方法,选题精准且重要。
- 开源与复现加成:+0.5。论文不仅承诺开源,更在细节披露上堪称模范,提供了从数据处理、模型配置、训练日志到评估脚本的全方位信息,极大地降低了学术界和工业界复现和跟进的门槛,对社区贡献巨大。
开源详情
- 代码:论文明确承诺将公开代码仓库链接(https://tangoflux.github.io/ 提供了项目主页和示例),但具体代码链接在论文提交时未提供,需待正式发布。
- 模型权重:论文明确承诺将开源模型权重。
- 数据集:训练所用数据集(WavCaps, AudioCaps)均为公开数据集。CRPO构建的偏好数据集由模型动态生成,非固定公开。
- Demo:提供了在线演示网站(https://tangoflux.github.io/),包含模型生成的音频样本对比。
- 复现材料:提供了极其详尽的附录,包括:完整的训练超参数(优化器、学习率、批次大小、轮数)、所有评估指标的实现细节、人类评估的指南和界面、复杂评估提示的生成模板、不同设置(CFG, N采样数)的消融实验结果等。
- 论文中引用的开源项目:依赖的主要开源组件包括:FLAN-T5(文本编码器)、CLAP(奖励模型, 来自
lukewys/laion_clap)、Stable Audio Open VAE(音频编解码器)、FLUX 模型架构设计。
🔗 开源详情
- 代码:论文明确承诺将公开代码仓库链接(https://tangoflux.github.io/ 提供了项目主页和示例),但具体代码链接在论文提交时未提供,需待正式发布。
- 模型权重:论文明确承诺将开源模型权重。
- 数据集:训练所用数据集(WavCaps, AudioCaps)均为公开数据集。CRPO构建的偏好数据集由模型动态生成,非固定公开。
- Demo:提供了在线演示网站(https://tangoflux.github.io/),包含模型生成的音频样本对比。
- 复现材料:提供了极其详尽的附录,包括:完整的训练超参数(优化器、学习率、批次大小、轮数)、所有评估指标的实现细节、人类评估的指南和界面、复杂评估提示的生成模板、不同设置(CFG, N采样数)的消融实验结果等。
- 论文中引用的开源项目:依赖的主要开源组件包括:FLAN-T5(文本编码器)、CLAP(奖励模型, 来自
lukewys/laion_clap)、Stable Audio Open VAE(音频编解码器)、FLUX 模型架构设计。
🏗️ 模型架构
TangoFlux的整体架构和训练流程可概括为“预训练-对齐”两阶段,并包含一个创新的在线迭代对齐循环。
图1:TangoFlux的整体训练流程图。 该图清晰地展示了训练的两个主要阶段:1)预训练:使用WavCaps和AudioCaps数据集,通过流匹配损失(ℒFM)训练TangoFlux-base模型。2)在线迭代对齐(CRPO):这是论文的核心。从基线模型π₀开始,迭代地进行三个步骤:a) 采样:从提示库中采样一批提示,用当前模型πk为每个提示生成多个音频样本。b) 训练数据构建:使用CLAP模型对生成的音频进行评分和排序,为每个提示构建赢家-输家偏好对,形成数据集𝒟k。c) 训练:使用该数据集,结合流匹配损失(ℒFM)和DPO损失(ℒCRPO)将模型πk优化为πk₊₁。这个循环迭代进行,使模型持续自我改进。
模型架构细节:
- 骨干网络:采用混合Transformer架构,结合了6个多模态扩散Transformer(MMDiT) 块和18个扩散Transformer(DiT) 块。MMDiT块能更好地融合条件信息,而DiT块则更简洁高效,这种混合设计平衡了性能与扩展性。每个块有8个注意力头,隐藏维度128,总宽度1024,总参数量约515M。
- 条件控制:采用双重条件控制:
- 文本条件:使用预训练的FLAN-T5编码器对输入文本提示进行编码,得到文本嵌入
c_text。 - 时长条件:为了实现可变时长生成(最长30秒),使用一个小型神经网络将目标时长编码为时长嵌入
c_dur。关键在于,模型始终在固定长度(对应30秒音频)的潜空间上操作,c_dur明确控制其中多少部分用于存放实际音频内容,其余部分填充静音。
- 文本条件:使用预训练的FLAN-T5编码器对输入文本提示进行编码,得到文本嵌入
- 音频编码:使用来自Stable Audio Open的预训练变分自编码器(VAE)。它将44.1kHz的立体声波形编码为潜表示
Z,并在推理时将模型生成的潜表示解码回波形。VAE在TangoFlux训练期间保持冻结。 - 生成过程(流匹配):模型学习一个从噪声
x₀(高斯分布)到目标潜表示x₁的“速度场”u(x_t, t; θ)。在推理时,从纯噪声x₀开始,使用Euler求解器(或Heun求解器)沿着学习到的速度场迭代求解50步,最终得到干净的音频潜表示x₁,再经VAE解码得到音频。
💡 核心创新点
CLAP-Ranked Preference Optimization (CRPO) 框架:
- 是什么:一种动态的、迭代式的偏好数据生成与模型对齐方法。它让模型在训练过程中持续生成自己的“教材”(偏好数据),并用它来优化自己。
- 之前方法的局限:之前为TTA模型对齐构建偏好数据主要依赖:a) 人工标注(如BATON),成本高、难以规模化;b) 静态合成数据集(如Audio-Alpaca),灵活性差,无法随模型进化。
- 如何起作用:在每次迭代中,用当前模型生成多个样本,用CLAP(作为代理奖励模型)自动排序构建偏好对,然后执行DPO优化。这形成了一个“生成-评估-优化”的闭环。
- 带来的收益:实验证明,由CRPO动态生成的数据集,在后续对齐训练中,性能显著优于使用静态的BATON和Audio-Alpaca数据集(见表3)。在线生成优于离线固定数据(见图2),避免了过早的性能饱和与退化。
针对流匹配的LCRPO损失函数:
- 是什么:在标准DPO-FM损失(LDPO-FM)的基础上,额外加入了赢家样本的流匹配损失(LFM)作为正则项。
- 之前方法的局限:直接将LLM上的DPO损失(LDPO-FM)应用于流匹配模型时,观察到赢家和输家的损失值会同时上升(见图4),这可能表明优化过度,导致生成音频偏离高质量的分布(奖励黑客问题)。
- 如何起作用:
ℒ_CRPO = ℒ_DPO-FM + ℒ_FM。额外的ℒ_FM项锚定了模型对赢家样本的建模能力,防止其在拉大赢家-输家差距的同时,自身质量也下降。 - 带来的收益:图3和图4表明,与仅使用LDPO-FM相比,LCRPO的损失增长更平稳,且在保持相似KL散度和FD的情况下,取得了更高的CLAP分数,优化过程更稳定。
高效且强大的文本到音频生成模型TangoFlux:
- 是什么:一个参数量适中(515M)、基于流匹配、支持可变时长、训练数据全公开的TTA模型。
- 之前方法的局限:许多高性能的TTA模型(如Stable Audio, MusicGen)使用私有数据训练;扩散模型通常需要大量去噪步数(100-200步),推理慢。
- 如何起作用:采用MMDiT/DiT混合架构和流匹配目标,流匹配相比扩散通常更高效(更少的采样步数达到更好质量)。通过时长条件控制实现变长生成。使用公开数据(WavCaps, AudioCaps)训练。
- 带来的收益:在仅需50步、3.7秒推理时间内,生成44.1kHz的30秒音频,并在多个基准上达到SOTA(表1),证明了其在效率和效果上的优势。
🔬 细节详述
- 训练数据:
- 预训练数据:WavCaps数据集(约40万条音频及描述)。所有音频被处理为单声道,然后复制为伪立体声以兼容VAE。短于30秒的填充静音至30秒,长于30秒的中心裁剪至30秒。
- 微调数据:AudioCaps训练集(约4.5万条)。
- CRPO偏好数据:从AudioCaps训练集中随机采样20,000个提示,每个提示用当前模型生成5个音频,用CLAP(
630k-audioset-best检查点)对5个音频评分,选取最高分和最低分构成一对偏好数据。
- 损失函数:
- 流匹配损失(ℒ_FM):
ℒ_FM = E_{x₁,x₀,t} ||u(x_t, t; θ) - v_t||²,其中v_t = x₀ - x₁是真实速度。用于预训练和作为CRPO损失的一部分。 - DPO-FM损失(ℒ_DPO-FM):见公式(2)。通过对比赢家(
x_w)和输家(x_l)在模型θ和参考模型θ_r(固定为每轮迭代开始时的检查点)下的流匹配损失,来优化偏好排序。 - CLARPO损失(ℒ_CRPO):
ℒ_CRPO = ℒ_DPO-FM + ℒ_FM。ℒ_FM在赢家样本上计算。
- 流匹配损失(ℒ_FM):
- 训练策略:
- 预训练:在WavCaps上训练80个epoch。使用AdamW优化器(β1=0.9, β2=0.95),峰值学习率
5e-4,线性warmup 2000步。批次大小80(5个A40 GPU,每卡16)。 - 微调:在AudioCaps训练集上继续微调65个epoch,得到TANGOFLUX-base。
- 对齐(CRPO迭代):批次大小48,峰值学习率
1e-5,线性warmup 100步。每次CRPO迭代训练8个epoch,取最后一个epoch的检查点用于下一轮的数据生成。共进行5次迭代。
- 预训练:在WavCaps上训练80个epoch。使用AdamW优化器(β1=0.9, β2=0.95),峰值学习率
- 关键超参数:
- 模型参数:515M。
- 隐藏维度:1024。
- 注意力头数:8。
- 流匹配时间步
t采样:从logit-normal分布(均值0,方差1)中采样。 - 推理:Euler求解器, 50步,Classifier-Free Guidance (CFG) 比例=4.5。
- 训练硬件:5个NVIDIA A40 GPU。
- 推理细节:模型始终在30秒的固定潜空间上操作。通过时长嵌入控制生成内容占实际时长的比例。推理时,采样一个长度为30秒对应的潜空间噪声,经50步Euler积分得到潜表示,再经VAE解码为波形。若请求时长小于30秒,则取前对应时长的音频。
- 正则化/稳定技巧:在LCRPO损失中添加赢家样本的流匹配损失作为正则化项,以稳定优化过程,防止奖励黑客。
📊 实验结果
论文在AudioCaps测试集上进行了全面的客观和主观评估。
- 主要对比结果(客观指标):见下表。TangoFlux在大多数指标上取得最优,尤其在衡量音频-文本对齐的CLAPscore和衡量音频质量的FDopenl3上优势明显。推理速度也是其显著优势。
| 模型 | 参数量 | 生成时长 | 步数 | FDP ↓ | FDopenl3 ↓ | KLpasst ↓ | KAD ↓ | CLAPscore ↑ | IS ↑ | 推理时间(s) |
|---|---|---|---|---|---|---|---|---|---|---|
| ConsistencyTTA | 559M | 10s | 1 | 20.9 | 94.6 | 1.43 | 0.61 | 0.377 | 9.1 | <0.2 |
| AudioLCM | 160M | 10s | 1 | 19.2 | 107.4 | 1.58 | 0.56 | 0.363 | 10.2 | <0.2 |
| AudioLDM 2-large | 712M | 10s | 200 | 33.2 | 108.3 | 1.81 | 1.78 | 0.419 | 7.9 | 24.8 |
| Make-An-Audio 2 | 160M | 10s | 100 | 15.6 | 98.7 | 1.33 | 0.45 | 0.406 | 9.4 | 2.3 |
| EzAudio-XL | 874M | 10s | 200 | 15.8 | 84.7 | 1.20 | 0.15 | 0.460 | 10.8 | 12.2 |
| Stable Audio Open | 1056M | 47s | 100 | 42.6 | 89.2 | 2.58 | 4.15 | 0.291 | 9.9 | 8.6 |
| Tango | 866M | 10s | 200 | 24.5 | 107.9 | 1.20 | 1.71 | 0.407 | 7.8 | 22.8 |
| Tango 2 | 866M | 10s | 200 | 20.8 | 108.4 | 1.11 | 1.38 | 0.447 | 9.0 | 22.8 |
| GenAU-Full-L | 1.25B | 10s | 100 | 20.1 | 93.2 | 1.37 | 0.96 | 0.447 | 12.0 | 5.3 |
| AudioX | 1.1B | 10s | 250 | 25.2 | 77.6 | 1.56 | 1.30 | 0.380 | 10.0 | 9.6 |
| TANGOFLUX-base | 516M | 30s | 50 | 20.7 | 80.2 | 1.22 | 0.67 | 0.431 | 11.7 | 3.7 |
| TANGOFLUX | 516M | 30s | 50 | 20.3 | 75.1 | 1.15 | 0.60 | 0.480 | 12.2 | 3.7 |
- 主要对比结果(人类评估):在50个复杂提示上,由至少4名标注员进行0-100分的评分,评估整体音频质量(OVL)和文本相关性(REL)。指标包括z-score、排名和Elo分数。TangoFlux在所有指标上均领先。
| 模型 | z-scores | Ranking (Mean, Mode) | Elo | |||
|---|---|---|---|---|---|---|
| OVL | REL | OVL | REL | OVL | REL | |
| AudioLDM 2 | -0.3020 | -0.4936 | 3.5, 4 | 3.7, 4 | 1,236 | 1,196 |
| SA Open | 0.0723 | -0.3584 | 2.4, 1,3 | 3.3, 3 | 1,444 | 1,268 |
| Tango 2 | -0.019 | 0.1602 | 2.4, 2 | 1.9, 2 | 1,419 | 1,507 |
| TANGOFLUX | 0.2486 | 0.6919 | 1.7, 2 | 1.1, 1 | 1,501 | 1,628 |
- 关键消融实验:
- CRPO vs 静态偏好数据集(表3):使用CRPO动态数据对齐的TangoFlux,在CLAPscore(0.480 vs 0.437/0.448)和人类评估Elo分数上,显著优于使用BATON或Audio-Alpaca静态数据对齐的版本。
在线与离线CRPO训练曲线对比] 图2:在线CRPO与离线CRPO的训练曲线对比。 该图显示了5次迭代中CLAPscore、IS和KLpasst的变化。离线CRPO(使用固定数据)在第二轮后CLAPscore开始下降,KLpasst上升,表明过拟合和性能退化。在线CRPO(每轮生成新数据)的CLAPscore持续上升至第4轮,KLpasst持续下降,IS持续上升,证明了动态数据生成的必要性和有效性。
LCRPO vs LDPO-FM(图3,图4): LCRPO与LDPO-FM在不同迭代次数下的性能指标对比] 图3:LCRPO与LDPO-FM在不同迭代次数下的性能指标对比。 (a) CLAPscore:LCRPO持续提升且高于LDPO-FM。(b) FDopenl3:两者相近。(c) KLpasst:两者相近。表明LCRPO在提升对齐度(CLAPscore)的同时,能维持生成质量和多样性。
图4:LCRPO与LDPO-FM的赢家/输家损失随迭代次数的变化。 两种损失函数的赢家和输家损失都随迭代增加,且差值(margin)也在拉大。但LCRPO的损失增长更平缓、稳定,而LDPO-FM在迭代3后增长加速,可能暗示优化不稳定或过拟合。
- 其他重要实验:
- 每个提示生成音频数量(N)的影响(表4):N=5或10略优于N=2,但差异不大,需权衡计算成本。
- CLAP作为奖励模型的验证(表5):采用Best-of-N策略(N从1增加到15),CLAPscore提升,KLpasst下降,FDopenl3不变,证明CLAP能有效识别更对齐的样本,且不损害多样性/质量。
- CFG比例的影响(表6):存在权衡。CFG=3.5时CLAPscore最高(0.481),CFG=4.5或5.0时FDopenl3更低(75.1/74.6)。论文最终选择CFG=4.5。
- 求解器对比(表7):Euler求解器(50步)略优于Heun求解器(100步),CLAPscore 0.480 vs 0.474。
- 时长控制准确性(图5):生成的音频实际时长与请求时长高度匹配。
不同模型CLAPscore与推理时间的对比曲线] 图6:不同模型CLAPscore与推理时间的对比曲线。 (a) CLAPscore vs Inference Time:TangoFlux在3.7秒(50步)时达到0.480,远超同时间点的其他模型。(b) FDopenl3 vs Inference Time:TangoFlux在3.7秒时FDopenl3为75.1,表现优异。这直观展示了其在效率-效果上的领先地位。
⚖️ 评分理由
- 学术质量:6.0/7。论文的创新点(CRPO框架、LCRPO损失)设计合理,且通过严谨的实验(多基线对比、多角度消融、客观与主观评估相结合)得到了充分验证。技术细节描述清晰,论证逻辑连贯。不足之处在于模型架构本身不是最前沿的颠覆性设计,且对齐效果受限于CLAP这一代理模型。
- 选题价值:1.5/2。文本到音频生成是当前AI生成内容(AIGC)的重要前沿,具有巨大的创意产业应用潜力。本文直击该领域从“生成”到“可控、高质量生成”的关键瓶颈——数据高效的对齐方法,选题精准且重要。
- 开源与复现加成:+0.5。论文不仅承诺开源,更在细节披露上堪称模范,提供了从数据处理、模型配置、训练日志到评估脚本的全方位信息,极大地降低了学术界和工业界复现和跟进的门槛,对社区贡献巨大。