📄 SumRA: Parameter Efficient Fine-tuning with Singular Value Decomposition and Summed Orthogonal Basis
#语音识别 #迁移学习 #参数高效微调 #多语言 #低资源
✅ 7.5/10 | 前25% | #语音识别 | #迁移学习 | #参数高效微调 #多语言
学术质量 5.8/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Chin Yuen Kwok(南洋理工大学 数字信任中心 & 计算与数据科学学院)
- 通讯作者:Yongsen Zheng(南洋理工大学 数字信任中心 & 计算与数据科学学院)
- 作者列表:
- Chin Yuen Kwok(南洋理工大学 数字信任中心 & 计算与数据科学学院)
- Yongsen Zheng(南洋理工大学 数字信任中心 & 计算与数据科学学院)
- Jia Qi Yip(南洋理工大学 计算与数据科学学院)
- Kwok-Yan Lam(南洋理工大学 数字信任中心 & 计算与数据科学学院)
- Eng Siong Chng(南洋理工大学 数字信任中心 & 计算与数据科学学院)
💡 毒舌点评
亮点:论文巧妙地将“模型平均”的思想压缩到了单一LoRA适配器的初始化阶段,通过将多个奇异向量求和来构建更“博学”的冻结矩阵A,这个想法精巧且实现简单。短板:实验验证仅限于多语言ASR,作者自己也承认对需要“局部”知识适应的任务(如NLU)无效,这让人怀疑该方法是普适的参数高效技巧,还是一个仅对特定任务类型(全局风格/口音迁移)有效的“特解”。
🔗 开源详情
- 代码:论文中未提及任何代码仓库链接(如GitHub)。
- 模型权重:论文中未提及是否会公开训练好的适配器(B矩阵)或完整模型。
- 数据集:使用了公开的Common Voice MASR数据集(Mozilla),并说明了获取方式(网址),但未提供处理后的数据脚本。
- Demo:论文中未提及提供在线演示。
- 复现材料:提供了较详细的训练超参数(优化器AdamW、调度器ReduceLROnPlateau、batch size=4、epochs=2、验证频率等)和模型配置(适配器位置、α设置)。但缺乏如随机种子、具体的层归一化实现细节、SVD计算库(如PyTorch的
torch.linalg.svd)的版本或参数设置等。 - 论文中引用的开源项目:引用了Whisper(模型)、SpeechBrain(学习率调度器实现)、Common Voice(数据集)、多个作为对比基线的PEFT方法(LoRA, PiSSA, CorDA等)的开源实现或论文。
- 总结:论文中未提及明确的开源计划(代码、模型、完整复现脚本)。
📌 核心摘要
- 要解决什么问题:在参数高效微调(PEFT)中,低秩适应(LoRA)及其变体(如LoRA-FA)在面对数百万个个性化适配器(如多语言/多用户ASR)时,仍面临显著的存储开销挑战。现有基于SVD的初始化方法(如PiSSA)仅使用前几个主导奇异向量,限制了冻结矩阵A的影响范围。
- 方法核心是什么:提出SumRA方法。核心是改进LoRA中冻结矩阵A的初始化:通过对预训练权重矩阵进行SVD分解,将得到的多个(而非仅前几个)奇异向量按特定策略(如交错求和、贪心求和)求和后,分配到矩阵A的每一行中。这样,A能同时编码更广泛的模型知识,且在微调时被冻结,仅更新矩阵B,从而大幅降低每个任务的存储成本。
- 与已有方法相比新在哪里:
- 相比标准LoRA:不再随机初始化A,而是利用预训练权重的结构化知识;同时冻结A,参数效率更高。
- 相比LoRA-FA:解决了其随机初始化A的局限性,用有意义的SVD向量初始化。
- 相比PiSSA/CorDA:关键创新在于求和策略。PiSSA仅用主导奇异向量初始化,而SumRA将更多的奇异向量(包括非主导的)压缩进A,使其能影响模型知识中更广阔的部分。此外,提出的“平衡求和”策略(贪心求和)避免了重要奇异向量聚集在同一行导致的干扰。
- 主要实验结果如何:在低资源多语言ASR任务上验证了有效性。使用Whisper-large-v2模型,以秩32、每任务仅0.4M额外参数(相比LoRA的7.7M)在Common Voice数据集的5种新语言上微调,SumRA将平均词错误率(WER)从LoRA的37.69%降至34.09%(相对降低约9.6%)。消融实验表明,贪心/交错求和策略优于简单的分块求和。下表为关键结果(Whisper-small, rank=32):
| 方法 | 额外参数 | Esperanto WER | Interlingua WER | Frisian WER | Meadow Mari WER | Kurmanji Kurdish WER |
|---|---|---|---|---|---|---|
| LoRA | 7.7M | 23.39% | 15.31% | 39.34% | 40.63% | 48.51% |
| SumRA | 3.9M | 20.77% | 13.38% | 33.37% | 36.30% | 44.47% |
- 实际意义是什么:为大规模部署个性化或语言特定的语音模型提供了一种更高效的存储方案。通过共享一个精心初始化的冻结矩阵A,系统可以仅为每个新任务存储一个小型的矩阵B,从而显著降低内存和存储成本,对于云端多租户ASR服务有潜在价值。
- 主要局限性是什么:方法的有效性高度依赖于“全局适应”的假设(如适应整体口音或风格)。作者指出,对于仅需学习局部新知识(如新增少量术语)的适应任务,该方法优势有限。此外,该方法在NLU任务上的初步实验效果不佳,进一步证实了其适用范围的局限性。
🏗️ 模型架构
本文主要提出一种新的LoRA适配器初始化策略,而非一个全新的神经网络架构。其核心在于对LoRA模块中矩阵A的初始化方式进行了创新设计,并改变了其在微调过程中的更新策略。下面结合图示详细说明。
整体流程:
- 预训练模型:使用如Whisper这样的预训练语音模型,其包含编码器和解码器。在微调时,解码器中的每个前馈和注意力层的线性变换权重矩阵
W0是固定的。 - LoRA适配器插入:在每个
W0旁并联一个低秩适配器,计算更新量ΔW = BA,其中B和A是可训练/可初始化的低秩矩阵(B为d×r,A为r×k,r << min(d, k))。 - 前向传播:输出
h = W0x + BAx(x为输入)。
SumRA的创新点:
- 初始化矩阵A:不再随机初始化。对预训练权重
W0进行SVD分解:W0 = UΣV^⊤。将Σ^(1/2) V^⊤(一个k×k矩阵)重塑并求和,生成一个r×k的矩阵作为A的初始值。每个奇异向量(V^⊤的一行)被加权(乘以√σ)后,求和分配给A的一行。 - 冻结矩阵A:在微调过程中,矩阵A被冻结,仅更新矩阵B。这与标准LoRA(A和B都更新)和LoRA-FA(A随机初始化后冻结)不同。
- 求和策略:为避免重要奇异向量集中在同一行造成干扰,提出了“交错求和”和“贪心求和”策略,确保每行A所承载的奇异值总和(负载)尽可能平衡。
下图直观对比了不同初始化策略:标准LoRA从正态分布初始化A;PiSSA从主导奇异向量初始化A;而SumRA将多个奇异向量求和后初始化A,从而让A能影响更广的知识子空间。
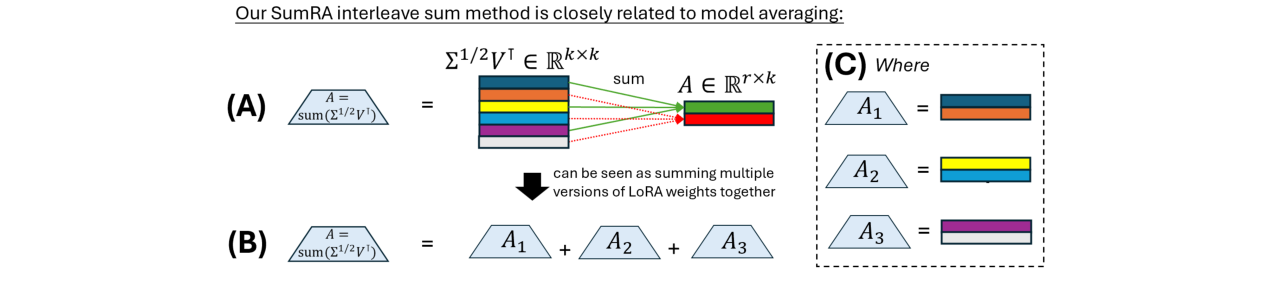
图2:展示了LoRA矩阵A的不同初始化策略。A) 从正态分布采样;B) PiSSA方法,取前r个奇异向量;C) 每个奇异向量对应一个概念子集,单一向量限制了行的影响范围;D) SumRA方法,将多个行(向量)求和到A的每一行,以覆盖更广的概念范围。
求和策略细节:图3展示了如何将 Σ^(1/2) V^⊤ 的行(奇异向量)分配到A的各行中。朴素的“分块求和”会将最大的奇异值聚集在一起,导致干扰。提出的“交错求和”和“贪心求和”能更均匀地分配重要向量。
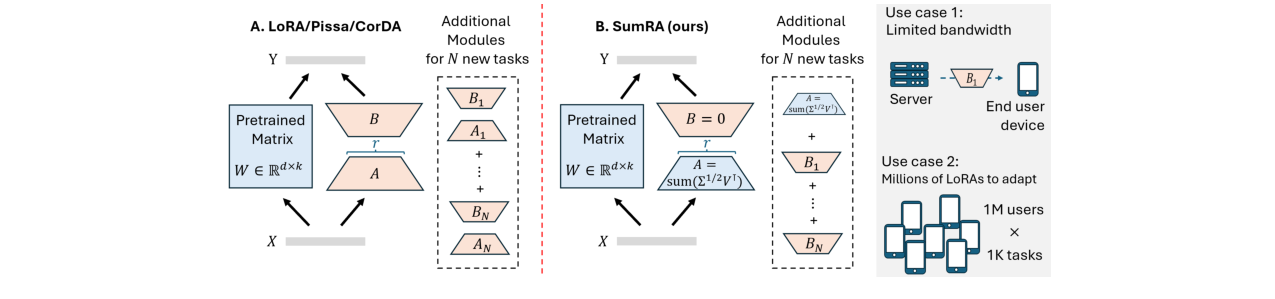
图3:展示了三种将奇异向量压缩到矩阵A的策略。A) 分块求和(不理想);B) 交错求和;C) 贪心求和。后两者能更均匀地分配重要的奇异向量。
与模型平均的联系:论文指出,SumRA可以看作是“模型平均”的一种高效实现。在微调前,将多个不同初始化(使用不同奇异向量子集)的LoRA模型在权重层面进行平均,与SumRA将多个向量求和到单个A中的效果类似,但后者只需一次训练。
图5:解释了SumRA的交错求和方法可视为对三个不同初始化LoRA模型的权重进行求和平均,但更高效。
存储优势:由于矩阵A在所有任务间共享且冻结,每个新任务只需额外存储一个矩阵B。这与标准LoRA(存储A和B)或为每个任务存储全新A的LoRA-FA相比,存储开销显著降低。
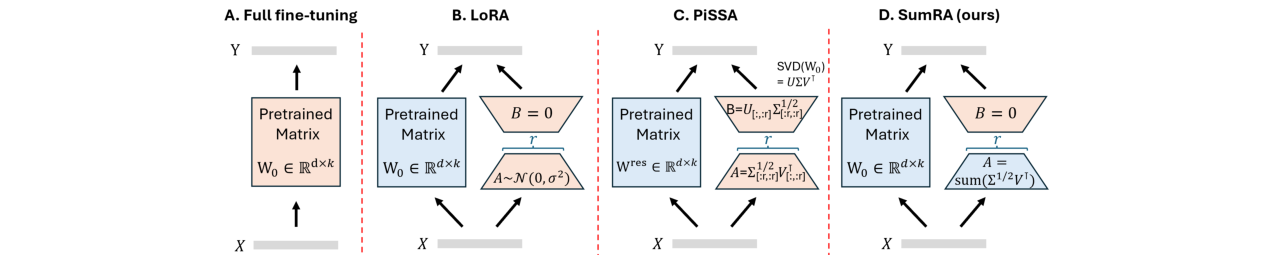
图4:对比了LoRA/PiSSA/Corda与SumRA在内存成本上的差异。SumRA允许在不同任务间共享冻结的A矩阵,从而降低了存储开销。
💡 核心创新点
基于SVD求和的矩阵A初始化策略:
- 是什么:将预训练权重SVD分解得到的多个(而非仅前几个)奇异向量,按特定策略求和后,作为冻结矩阵A的初始值。
- 之前方法的局限:PiSSA等方法仅使用前
r个主导奇异向量初始化A,其表达空间局限于模型的一小部分知识。LoRA-FA则随机初始化A,完全忽略了预训练知识。 - 如何起作用:通过求和,A的每一行可以同时编码多个奇异向量的方向信息,从而使其初始状态就能影响模型知识中更广阔的子空间。
- 收益:在下游任务微调中,模型可以从一个更“全面”的初始点开始适应,提高了性能,尤其是在需要全局知识迁移的任务上。实验显示在低资源ASR上WER显著下降。
平衡奇异向量负载的求和策略(贪心求和):
- 是什么:一种将奇异向量分配到A各行的策略,旨在最小化每一行所承载的奇异值总和(负载)的最大值。
- 之前方法的局限:朴素的分块求和会导致重要(大奇异值)向量聚集在同一行,造成“破坏性干扰”。
- 如何起作用:贪心求和策略按奇异值从大到小的顺序,每次将当前向量分配给当前负载最小的行。该策略被证明在数学上能最小化最大行负载。
- 收益:平衡了各奇异向量的重要性分布,减少了初始化时的干扰,提升了模型的优化效率和最终性能。消融实验证实了其优于分块求和。
冻结矩阵A以提升参数效率:
- 是什么:在微调过程中,冻结初始化好的矩阵A,仅更新矩阵B。
- 之前方法的局限:标准LoRA需要同时存储和更新A和B,在任务数量巨大时存储开销仍可能很高。
- 如何起作用:A作为共享的、任务无关的特征投影基(由SVD知识初始化),B负责学习特定任务的权重更新。
- 收益:每个任务仅需存储一个与B相关的文件,将存储成本从
O(任务数 r (d + k))降低至O(任务数 d r + r k),其中rk的A是共享的,实现了接近50%的参数节省。
🔬 细节详述
- 训练数据:使用Common Voice MASR数据集的一个子集。选取了5种预训练模型(Whisper)未见过的语言:世界语(Esperanto)、草场马里语(Meadow Mari)、中库尔曼吉库尔德语(Kurmanji Kurdish)、弗里斯兰语(Frisian)和国际语(Interlingua)。每种语言的数据划分为:训练集10小时,验证集1小时,测试集1小时。
- 训练策略:
- 基础模型:Whisper-small 和 Whisper-large-v2。
- 适配器位置:解码器中的所有前馈层和注意力层的线性变换层。
- 优化器:AdamW。
- 学习率调度:ReduceLROnPlateau(SpeechBrain实现的一种变体)。
- 训练轮数:2个epoch。
- 批次大小:4。
- 验证频率:每1/8个epoch验证一次。
- α设置:LoRA中的缩放因子α等于秩r。
- 可训练参数:仅适配器模块(B矩阵)和层归一化层的参数。
- 关键超参数:
- 秩(r):主要对比了r=2和r=32两种设置。
- 额外参数量:以Whisper-large-v2, r=32为例,标准LoRA需存储约34.3M参数(A+B),而SumRA只需存储约17.6M参数(仅B)。
- 训练硬件:论文中未说明具体的GPU型号、数量和训练时长。
- 推理细节:采用贪心解码策略,未使用beam search。
- 对比基线:包括未适配的Whisper、全参数微调(FT)、标准LoRA、VeRA、LoRA-FA、DoRA、PiSSA、CorDA。
- 评估指标:词错误率(WER,越低越好)。
📊 实验结果
实验围绕多语言ASR展开,主要在Whisper模型和Common Voice数据集的5种语言上进行。
- 主要结果对比(表2) 论文提供了在不同模型(Whisper-small, Whisper-large-v2)和不同秩(r=2, 32)下的全面对比。下表摘录了关键对比(Whisper-large-v2, r=32):
| 方法 | 额外参数 | Esperanto WER | Interlingua WER | Frisian WER | Meadow Mari WER | Kurmanji Kurdish WER | 相对LoRA改进 |
|---|---|---|---|---|---|---|---|
| LoRA | 34.3M | 14.42% | 8.67% | 24.75% | 32.39% | 37.72% | 基线 |
| PiSSA | 34.3M | 13.00% | 8.82% | 22.43% | 29.97% | 34.26% | - |
| CorDA | 34.3M | 13.13% | 9.18% | 22.96% | 29.20% | 36.33% | - |
| SumRA | 17.6M | 12.41% | 8.17% | 22.27% | 27.19% | 34.21% | -14%~-9.3% |
关键结论:
- SumRA在几乎所有的语言和模型设置上都取得了最佳(或并列最佳)的WER。
- 以Whisper-large-v2, r=32为例,SumRA相比标准LoRA,在参数量减少约49%(34.3M → 17.6M)的情况下,将平均WER从37.69%降低到34.09%,相对改进约9.6%。在Esperanto语言上,WER从14.42%降至12.41%,相对改进达14%。
- SumRA在低秩(r=2)设置下的优势尤为明显,例如在Whisper-large-v2上,将Esperanto的WER从LoRA的15.96%降至14.55%。
- 消融实验(求和策略对比,表3) 在Whisper-small, r=32设置下,对不同的求和策略进行了消融实验。
| 方法 | 额外参数 | Esperanto WER | Interlingua WER | Frisian WER | Meadow Mari WER | Kurmanji Kurdish WER |
|---|---|---|---|---|---|---|
| LoRA | 7.7M | 23.39% | 15.31% | 39.34% | 40.63% | 48.51% |
| SumRA (分块求和) | 3.9M | 21.68% | 13.91% | 35.38% | 37.35% | 47.30% |
| SumRA (交错求和) | 3.9M | 20.77% | 13.38% | 33.37% | 36.30% | 44.47% |
| SumRA (贪心求和) | 3.9M | 20.73% | 13.16% | 33.91% | 37.53% | 44.72% |
关键结论:
- 所有SumRA策略都优于基线LoRA。
- 交错求和和贪心求和显著优于朴素的分块求和,验证了平衡奇异向量负载的重要性。
- 贪心求和与交错求和性能接近,在多数语言上略有优势。
- 数据规模影响(表4) 在Esperanto语言上测试了SumRA在不同数据量(10h, 50h, 100h)下的表现。
| 方法 | 10h WER | 50h WER | 100h WER |
|---|---|---|---|
| FT | 18.89% | 15.31% | 13.62% |
| LoRA | 23.39% | 15.20% | 13.28% |
| SumRA (冻结矩阵A) | 20.77% | 14.49% | 13.39% |
| SumRA (训练矩阵A) | 20.14% | 13.75% | 13.02% |
关键结论:
- 在低资源(10h)下,SumRA(冻结A)相比LoRA优势最明显(23.39% → 20.77%)。
- 随着数据量增加,所有方法性能提升,SumRA的优势依然存在但相对缩小。
- 如果微调时也训练矩阵A,可以获得进一步的性能提升,但代价是参数效率下降。
⚖️ 评分理由
- 学术质量:5.8/7:创新点明确(SVD求和初始化),理论动机清晰(扩展影响空间),技术实现正确。实验设计系统,包含多维度对比(不同基线、不同模型、不同秩)、详尽的消融实验(求和策略)和不同数据规模分析,数据充分,结论可信。主要局限在于普适性论证不足,仅在多语言ASR上验证,且作者自认对局部适应任务无效,这削弱了其作为通用PEFT方法的力度。
- 选题价值:1.5/2:研究聚焦于大规模个性化部署的实际痛点(存储成本),提出的共享冻结矩阵方案直接针对此问题。多语言和低资源ASR是语音识别领域持续关注的重要方向,论文成果对该领域的实用化有积极意义。扣分源于应用场景的相对垂直。
- 开源与复现加成:0.0/1:论文未提供代码仓库链接,也未承诺开源。训练细节(优化器、学习率调度、batch size等)描述较为完整,但一些关键实现细节(如精确的贪心求和算法流程、SVD在PyTorch中的具体实现方式)未明确说明,给完整复现带来不确定性。因此,复现加成分为0。