📄 STITCH: Simultaneous Thinking and Talking with Chunked Reasoning for Spoken Language Models
#语音对话系统 #流式处理 #自回归模型 #语音大模型 #端到端
🔥 8.5/10 | 前25% | #语音对话系统 | #流式处理 | #自回归模型 #语音大模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Cheng-Han Chiang(National Taiwan University, Microsoft GenAI)
- 通讯作者:Xiaofei Wang(Microsoft)
- 作者列表:Cheng-Han Chiang(National Taiwan University, Microsoft), Xiaofei Wang(Microsoft), Linjie Li(Microsoft), Chung-Ching Lin(Microsoft), Kevin Lin(Microsoft), Shujie Liu(Microsoft), Zhendong Wang(Microsoft), Zhengyuan Yang(Microsoft), Hung-yi Lee(National Taiwan University), Lijuan Wang(Microsoft)
💡 毒舌点评
亮点在于将人类“边想边说”的模式形式化为一个可计算的交错生成框架,并在几乎不增加首包延迟的前提下显著提升了数学推理任务的准确率,堪称“偷时间”的艺术。短板在于对生成的“思考链”本身的质量和可靠性缺乏更深入的分析,且实验场景集中于英文数学题,对更复杂对话场景的泛化能力有待验证。
🔗 开源详情
- 代码:论文提供了项目主页链接
https://d223302.github.io/STITCH,但未明确说明完整代码库的开源链接。论文中提到使用LlamaFactory进行微调。 - 模型权重:未提及公开发布微调后的STITCH模型权重。
- 数据集:论文中用于微调和测试的部分数据集(如语音数学数据)已发布在Hugging Face (
https://huggingface.co/datasets/dcml0714/speech_math),但完整的训练数据集(约40万条)未整体公开,需按论文描述的步骤从原始数据集构建。 - Demo:项目主页包含动画和演示。
- 复现材料:附录中提供了详细的训练YAML配置、数据构造prompt、评估脚本等,复现细节较为透明。
- 引用的开源项目:LlamaFactory (LlamaFactory), GLM-4-Voice (THUDM/glm-4-voice-9b), Cosyvoice (语音解码器), Whisper (用于转写评估), Kimi-Audio-Evalkit (OpenAudioBench评估)。
📌 核心摘要
这篇论文旨在解决当前语音语言模型(SLM)缺乏内部推理能力的问题。人类在说话前通常会进行内部思考,而现有SLM直接生成回答。作者提出了STITCH方法,通过交替生成不发声的推理token块和可发声的文本-语音token块,实现了SLM的“同时思考和说话”。其核心创新在于利用语音解码器播放一个音频块(tchunk秒)所需的时间,远长于模型生成该块对应token所需的时间(ttoken秒),因此模型可以利用播放时的“空闲时间”生成下一个推理块,从而将推理延迟隐藏在语音播放过程中。与传统方法“先完整推理再说话”相比,STITCH显著降低了延迟;与不推理的基线相比,在五个数学推理数据集上准确率平均提升超过15%,同时在非推理任务上性能相当。例如,在GSM8K数据集上,STITCH-S的准确率(56.72%)远高于无推理基线(35.73%)。其实际意义在于为构建更智能、响应更及时的语音对话系统提供了新思路。主要局限性是推理链的质量和完整性依赖于训练数据构造,且当前实验环境相对单一。
🏗️ 模型架构
论文的模型基于GLM-4-Voice-9B这一交错文本-语音生成的SLM架构进行微调。核心创新是在原有的交错文本-语音生成流程中,引入了新的“推理token”类型,并设计了两种新的交错生成范式(STITCH-R和STITCH-S)。
整体流程为:用户输入语音被编码为语音token,输入到SLM骨干网络(一个Transformer模型)。SLM以自回归方式生成三种token:不发声的推理token(用于内部思考)、发声的文本token(作为语音内容的转写)以及语音token(由语音解码器合成为音频波形播放给用户)。
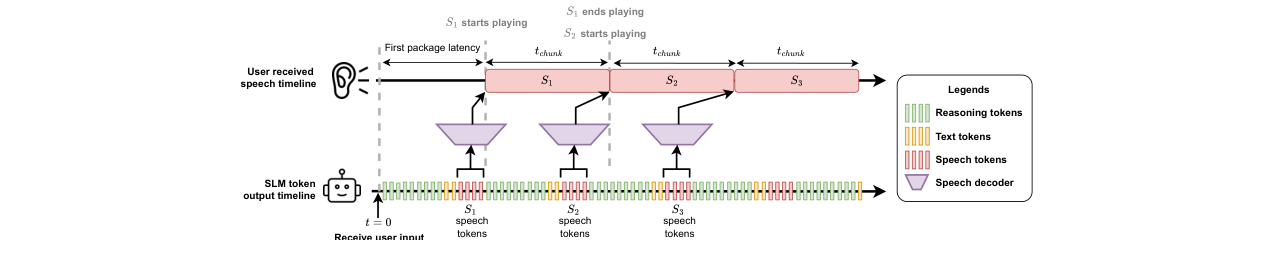
图1展示了STITCH-R的生成时序。模型首先生成第一块推理、文本和语音token。语音token被送入语音解码器,合成持续tchunk秒的音频并开始播放。在播放期间,SLM利用空闲时间生成下一个推理块,随后继续生成下一个文本-语音块。只要生成一轮token的时间(ttoken)小于音频播放时间(tchunk),音频就能无缝衔接播放。
论文对比了四种生成模式,其token序列构成如下图所示:
图2展示了:(a)原始GLM-4-Voice的交错文本-语音生成;(b)TBS(先完整推理,再交错生成);(c)STITCH-R(推理-文本-语音交错,推理优先);(d)STITCH-S(文本-语音-推理交错,说话优先)。STITCH-R和STITCH-S的关键区别在于第一个生成的token块类型,这直接影响了首包延迟。
关键设计选择与动机:
- 引入独立的推理token:与文本token(对应语音转写)功能分离,专门用于模拟内部思维链,使思考过程更结构化。
- 分块交错生成:将长推理链分割为固定长度的块(Nreason=100),并与文本-语音块交错,从而将推理时间“溶解”到语音播放的后台,实现延迟隐藏。
- STITCH-S实现零额外首包延迟:通过先生成第一个文本-语音块再开始推理,其首包延迟与无推理的基线完全相同(Ntext + Nspeech tokens),但后续块的生成已基于部分推理,从而在不增加感知延迟的情况下提升了回答质量。
💡 核心创新点
- 首次在语音语言模型中实现不发声的内部推理:以往的SLM(如GLM-4-Voice, Thinker-Talker)在生成回答前没有明确的、独立的推理步骤。STITCH填补了这一空白,模拟了人类“先想后说”的认知过程。
- 基于时间隐藏的交错生成框架(STITCH):提出了一种利用语音播放空闲时间进行推理的工程化解决方案。通过精确计算和设计token生成速率与音频播放时长的关系,将推理延迟从用户感知的首包延迟中剥离出去。
- STITCH-S:延迟-性能的帕累托改进:通过调整交错顺序,实现了在完全不增加首包延迟的前提下,显著提升复杂推理任务的准确率。这为实时性要求高的对话系统提供了极具吸引力的升级路径。
🔬 细节详述
- 训练数据:构建了一个约40万条的训练集
D_TBS,包含三种任务:通用对话(VoiceAssistant400K)、数学推理(Tulu-3系列,约22万条)、知识问答(NQ, TriviaQA,约7万条)。数据构造过程包括:使用GPT-4o为对话数据生成推理链;为数学/知识问答数据合成语音输入,并利用Ground Truth构造推理链和口语化回答。 - 损失函数:标准的自回归语言建模交叉熵损失,用于预测序列中下一个token(无论是推理token、文本token还是语音token)。
- 训练策略:对GLM-4-Voice-9B的骨干Transformer进行全参数微调,冻结语音编码器和解码器。使用LlamaFactory工具,优化器为AdamW,学习率1e-5,余弦调度,warmup比例0.1,批量大小64(32卡 x 每卡2样本 x 梯度累积8步),训练2个epoch。使用DeepSpeed ZeRO-2进行分布式训练,精度为bf16。
- 关键超参数:Ntext=13, Nspeech=26(沿用GLM-4-Voice设置), Nreason=100。语音token持续时间tchunk约2秒,对应A100 GPU上可生成约160个token,因此100个推理token有充足的时间窗口。
- 训练硬件:32张A100-80GB GPU,训练约17小时。
- 推理细节:生成时,STITCH-R先输出100个推理token,再交替生成文本-语音块。STITCH-S先输出文本-语音块,再交替输出推理块。直到生成结束符[EOR]。支持在推理时调整每次生成的推理块长度N’_token(60-100),通过提前插入[EOPR]符号实现,无需重训练。
📊 实验结果
论文在五个数学推理QA数据集和三个非推理数据集上进行了评估,使用准确率(通过GPT-4o判断)和GPT-4o评分。
主要性能对比(数学推理任务):
| 模型/配置 | 首包延迟(token) | 训练用推理 | 推理用推理 | AddSub | MultiArith | SinglEq | SVAMP | GSM8K | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| GLM-4-Voice | Ntext+Nspeech | - | ✘ | 59.42 | 62.00 | 71.00 | 44.00 | 29.00 | 53.08 |
| No Reasoning | Ntext+Nspeech | ✘ | ✘ | 66.06 | 70.69 | 77.98 | 64.43 | 35.73 | 62.98 |
| TBS | N_full+Ntext+Nspeech | ✔ | ✔ | 79.82 | 85.63 | 89.91 | 75.29 | 64.94 | 79.12 |
| STITCH-R | Nreason+Ntext+Nspeech | ✔ | ✔ | 78.90 | 88.51 | 93.58 | 73.83 | 58.70 | 78.70 |
| STITCH-S | Ntext+Nspeech | ✔ | ✔ | 81.65 | 87.93 | 91.74 | 72.15 | 56.72 | 78.04 |
关键发现:
- 推理大幅提升数学QA性能:TBS(先完整推理)比无推理基线平均准确率高16.14%,在GSM8K上近乎翻倍(64.94% vs 35.73%)。
- STITCH几乎无性能损失:STITCH-R与TBS的平均准确率差距仅0.42%,证明分块交错推理有效。
- STITCH-S实现延迟与性能兼得:其首包延迟与无推理基线完全相同,但平均准确率比无推理基线高15.06%,在GSM8K上高19.99%。这是最令人兴奋的结果。
非推理任务性能:STITCH-R和STITCH-S在非推理任务(如TriviaQA, AlpacaEval)上性能与无推理基线相当或略有提升,表明引入推理机制不会损害模型在其他任务上的通用能力。
语音质量与人类评估:自动评估(UTMOSv2)和GPT-4o流畅度打分显示,STITCH生成的语音质量和文本流畅度与基线相当。人类评估表明,在响应速度感知上,STITCH-S > STITCH-R > TBS ≈ No Reasoning。
图3展示了两个关键消融实验:(a, b) 推理时调整每次生成的推理token数量(N’_token)对性能的影响,表明当N’_token ≥ 80时性能可恢复到N_reason=100时的90%以上;(c) 使用不同外部模型(如Llama系列)为STITCH-R生成推理链,显示更强的推理模型能带来更好的最终回答准确率,证明STITCH确实利用了推理内容。
推理长度分析:在GSM8K上,STITCH-R平均生成约322个推理token(3.22个块),而文本块约有5.72个。这意味着推理过程通常在语音生成结束前就已完成。
图4展示了人类评估的界面,用于对比两个模型响应同一问题的速度感知。
⚖️ 评分理由
- 学术质量:6.5/7:创新性突出,首次将不发声推理引入SLM并设计了巧妙的工程实现;技术方案正确且经过充分实验验证;实验设计全面,覆盖了不同任务、不同设置,并包含人类评估;证据链完整可信。扣分点在于对推理链本身质量(如推理正确性)的分析较浅,且实验集中于英文数学QA。
- 选题价值:1.5/2:选题前沿,直击当前SLM缺乏复杂推理能力的痛点;潜在影响大,为构建更智能的语音助手奠定了基础;与音频/语音读者高度相关。扣分点在于应用场景目前主要局限于问答,对更自由的对话场景影响有待观察。
- 开源与复现加成:0.5/1:论文提供了详细的超参数、训练配置(LlamaFactory YAML)、数据构造方法和部分代码链接(项目主页),复现信息较为充分。但未提及模型权重的公开发布计划,这降低了完全复现的可行性。