📄 Steering Autoregressive Music Generation with Recursive Feature Machines
#音乐生成 #自回归模型 #激活干预 #音频大模型 #可控生成
🔥 8.5/10 | 前25% | #音乐生成 | #自回归模型 #激活干预 | #自回归模型 #激活干预
学术质量 6.0/7 | 选题价值 1.8/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Daniel Zhao(University of California, San Diego)
- 通讯作者:未说明(从作者列表和邮箱格式推断,第一作者Daniel Zhao可能是主要联系人,但未明确标注)
- 作者列表:Daniel Zhao(University of California, San Diego)、Daniel Beaglehole(University of California, San Diego)、Taylor Berg-Kirkpatrick(University of California, San Diego)、Julian McAuley(University of California, San Diego)、Zachary Novack(University of California, San Diego)
💡 毒舌点评
这篇论文的亮点在于它成功地将RFM这一“老”概念嫁接到了音乐生成这个热门但控制困难的任务上,并通过精巧的层/时间调度设计实现了相当不错的控制效果,免去了训练或微调基础模型的巨大开销。不过,其控制能力严重依赖于在高度理想化的合成音乐数据集(SYNTHEORY)上训练的探针,当面对真实世界复杂多变的音乐纹理时,这些探针发现的“方向”是否依然稳健有效,论文并未给出足够有说服力的证据。
🔗 开源详情
- 代码:提供GitHub仓库链接:
https://github.com/astradzhao/music-rfm。 - 模型权重:未提及开源MusicGen-Large或训练好的RFM探针权重。
- 数据集:使用公开数据集SYNTHEORY、SONG-DESCRIBER、MusicBench。论文未提及提供或托管数据集。
- Demo:提供交互式演示项目主页:
https://musicrfm.github.io/controllable-music-rfm/。 - 复现材料:在论文正文中和附录(A-F节)中提供了详细的技术细节、算法伪代码(算法1)、超参数搜索空间(表8)、消融实验设置和公式。
- 论文中引用的开源项目:MusicGen (Copet et al., 2024), ENCODEC (Défossez et al., 2022), Essentia (Bogdanov et al., 2013), librosa (McFee & et al., 2023), CLAP (Wu et al., 2023)。
📌 核心摘要
- 问题:可控音乐生成极具挑战性,现有方法常需要模型微调或在推理时进行昂贵的优化,且可能引入听觉伪影。实现对生成音乐中精细的音乐理论概念(如特定音符、和弦)进行可解释、实时的控制是主要难题。
- 核心方法:提出MusicRFM框架,适配递归特征机器(RFM)来控制冻结的预训练音乐模型(MusicGen)。方法分三步:首先,在合成音乐数据集SYNTHEORY上,为模型的每一层训练轻量级RFM探针,通过平均梯度外积(AGOP)发现对应于特定音乐概念(如音符)的“概念方向”;然后,在推理时,通过前向钩子将这些方向注入到模型各层的残差流中,实时引导生成过程。
- 创新点:相较于现有方法,MusicRFM无需微调基础模型;它引入了层剪枝(Top-K或指数加权选择性能最佳的层进行注入)和时间调度(如线性衰减、正弦波等确定性调度,以及随机概率门控)等机制,以在控制精度和生成质量间取得平衡;同时支持多方向同时控制。
- 主要实验结果:
- 在探针分类任务上,MusicRFM(平均池化)在多个音乐概念类别上优于原始SYNTHEORY的FFN探针(见论文表1,平均精度0.942 vs 0.929)。
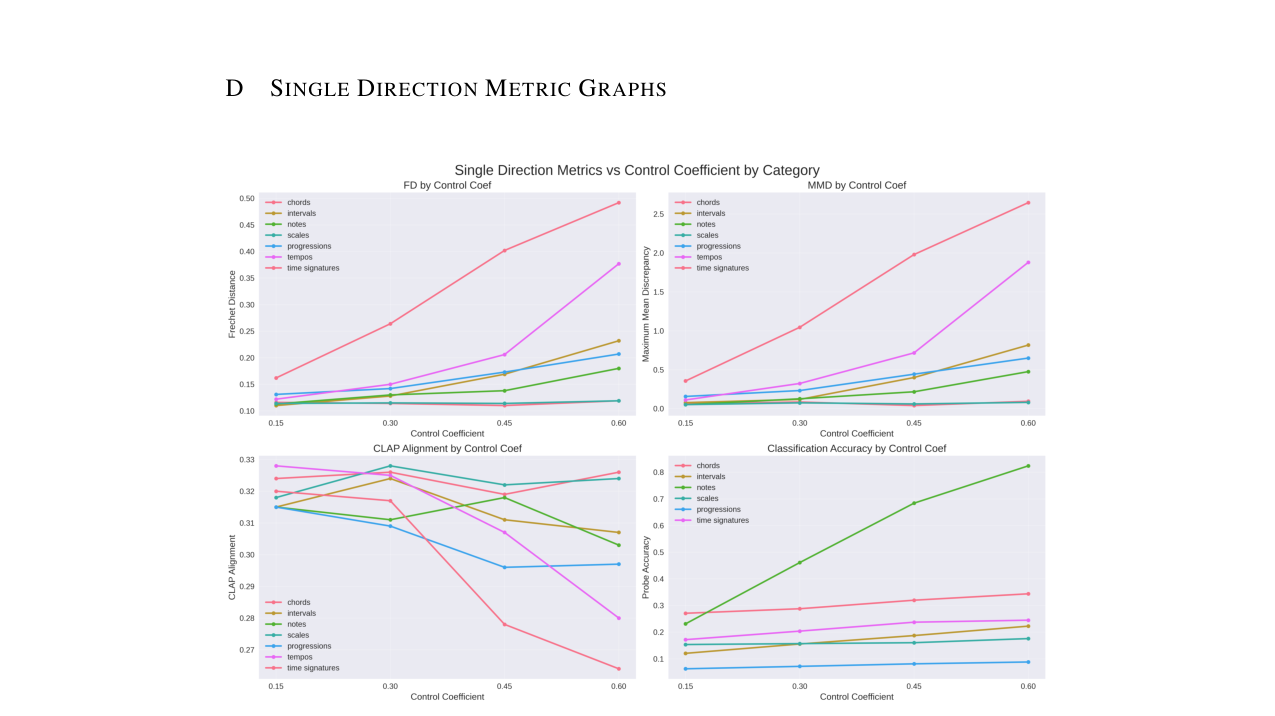
- 在单方向控制生成上,对于“音符”类别,控制系数η0从0.15增加到0.60时,目标音符的分类准确率从0.23提升至0.824,而文本提示一致性(CLAP分数)仅下降约0.02(见论文表2)。具体控制结果如下:
| 类别 (随机基准) | 控制系数 η0 | FD ↓ | MMD ↓ | CLAP ↑ | 探针准确率 ↑ |
|---|---|---|---|---|---|
| 音符 (0.083) | 0.15 | 0.113 | 0.052 | 0.315 | 0.231 |
| 0.30 | 0.130 | 0.127 | 0.311 | 0.461 | |
| 0.45 | 0.138 | 0.217 | 0.318 | 0.684 | |
| 0.60 | 0.180 | 0.476 | 0.303 | 0.824 | |
| 和弦 (0.250) | 0.15 | 0.116 | 0.063 | 0.324 | 0.271 |
| 0.60 | 0.119 | 0.095 | 0.326 | 0.344 |
- 听力测试(12名参与者)表明,MusicRFM在音乐属性控制得分上显著优于无控制和朴素RFM(见论文表3,以和弦为例:73.46 vs 59.71 vs 69.21)。
- 实际意义:为可控音乐生成提供了一个高效、可解释的新范式,仅需训练轻量探针,无需修改或微调庞大的基础生成模型,且支持实时、细粒度的多属性控制,有望应用于音乐制作和游戏音频等场景。
- 主要局限性:探针训练使用的均值池化丢失了时序信息,限制了其对音阶、和弦进行等强时序概念的控制效果;目前控制的概念局限于SYNTHEORY数据集定义的音乐理论属性,对音色、乐器等感知属性的控制有待拓展。
🏗️ 模型架构
本文的核心不是一个端到端的新生成模型,而是提出一个控制框架,作用于已有的冻结模型(MusicGen-Large)。整体架构是探针提取与推理时注入的两阶段流程。
探针训练阶段:
- 输入:音频片段(重采样至32kHz)。
- 特征提取:使用预训练的ENCODEC编码器将音频转换为离散token,然后输入冻��的MusicGen-Large模型(一个在ENCODEC token上训练的Transformer解码器)。
- 激活获取:对于每一层(共48层解码块),对模型生成的token隐藏状态进行均值池化,得到一个代表整段音频的层向量
x_i,l ∈ R^{d_l}。 - RFM探针训练:针对每个音乐概念(如“音符C#”)和每一层,使用上述层向量作为特征,训练一个轻量级RFM探针。训练过程迭代15次,核心是计算平均梯度外积(AGOP)矩阵并进行特征更新(公式1-3)。
- 输出:为每个概念在每一层提取出一个主特征方向
q_{l, j*}(AGOP矩阵的主特征向量)。
推理控制阶段:
- 基础模型:冻结的MusicGen-Large。
- 控制注入:在模型前向传播的每一步(生成每个token时),对选定的层
ℓ ∈ S,通过前向钩子将控制向量注入残差流:h'_{t,ℓ} = h_{t,ℓ} + η_ℓ(t) q_{ℓ,j*}。 - 控制调制:注入强度
η_ℓ(t)由三部分组成:- 层权重
w_ℓ:基于探针验证集性能计算。可选Top-K选择或指数加权方案。 - 时间调度
ϕ(t):确定性函数(如线性增减、正弦波),控制控制强度随生成步骤t的变化。 - 随机门控
ψ_p(t):伯努利概率p,决定每一步是否实际注入控制,以减少累积伪影。
- 层权重
- 多方向控制:可同时为同一层注入多个概念方向
q_{ℓ,j_m},每个方向有独立的系数和调度。
论文未提供整体架构图,主要流程通过文字和公式描述。
💡 核心创新点
- 首次将RFM适配于自回归音乐生成:将RFM这种从模型内部梯度中提取可解释方向并用于控制的方法,成功应用于MusicGen这一大型音频自回归模型。这是方法论上的迁移创新。
- 引入层级与时间感知控制机制:为了平衡控制效果与生成质量,创新性地设计了层剪枝(选择性注入)和时间调度(动态调节强度)策略。实验证明这比朴素的全层、恒定强度注入效果更好(见附录消融实验)。
- 支持多概念并行与错位控制:扩展框架以支持同时注入多个控制方向,并允许为不同概念设置不同的时间调度,实现了复杂场景下的联合或交替控制。
🔬 细节详述
- 训练数据:
- 探针训练:使用SYNTHEORY数据集(Wei et al., 2024),一个为研究音乐理论概念表示设计的合成数据集,包含7类属性(音符、和弦类型、音阶、和弦进行、音程、拍号、速度)。论文未提及具体样本数量,但提到在训练时因GPU显存限制,对“简单进行”类别每类使用了700个样本(数据集每类1100个),其他类别使用全部。
- 生成评估:使用SONG-DESCRIBER数据集中的250个提示进行评估,并在MusicBench(真实音乐语料库)上进行了迁移性测试。
- 损失函数:未使用传统损失函数。RFM探针训练的核心是核岭回归(KRR),通过求解线性系统
(K(X,X)+λI)α = y(公式5)得到预测器,并迭代计算AGOP矩阵(公式1)。 - 训练策略:
- RFM迭代:共15次迭代。每次迭代包括:在当前特征上训练KRR预测器 -> 计算AGOP矩阵M -> 特征更新
x^{(t+1)} = T^{(t)}x^{(t)}。 - 超参数搜索:使用贝叶斯优化,搜索空间见论文表8,包括核带宽、正则化参数、是否中心化梯度等。对于层探针和聚合模型分开搜索。目标是最大化验证集AUC(二分类)或精度(多分类)。
- RFM迭代:共15次迭代。每次迭代包括:在当前特征上训练KRR预测器 -> 计算AGOP矩阵M -> 特征更新
- 关键超参数:
- 控制系数
η_0:主要控制变量,在{0.15, 0.30, 0.45, 0.60}中选择。 - 层剪枝参数:Top-K中的K值;指数加权中的
κ(默认0.95)。 - 随机门控概率
p:默认为0.3。 - 时间调度函数:具体公式见附录E。
- 控制系数
- 训练硬件:论文未说明。
- 推理细节:在MusicGen-Large的48层解码块上通过前向钩子进行注入。解码策略未特别说明,沿用基础模型设置。
- 正则化或稳定训练技巧:
- 梯度中心化(公式6):在RFM迭代中,可选择对梯度进行中心化处理,以在高维设置中去噪。
- 随机门控:通过概率p间歇性地应用控制,避免过度控制导致的伪影积累。
- 层选择性注入:避免在性能差的层注入错误方向。
📊 实验结果
论文提供了多方面的实验结果,用以证明MusicRFM的有效性。
- 探针分类性能(表1):证明RFM作为探针工具的有效性。
| 模型 | 音符 | 音程 | 音阶 | 和弦 | 进行 | 拍号 | 速度 | 平均 |
|---|---|---|---|---|---|---|---|---|
| MusicRFM (均值池化) | 0.850 | 0.975 | 0.956 | 0.984 | 0.943 | 0.900 | 0.985 | 0.942 |
| RFM (最后token) | 0.734 | 0.743 | 0.546 | 0.866 | 0.811 | 0.771 | 0.959 | 0.776 |
| 线性探针 | 0.761 | 0.618 | 0.158 | 0.834 | 0.725 | 0.729 | 0.972 | 0.685 |
| 原始SYNTHEORY FFN | 0.866 | 0.972 | 0.905 | 0.989 | 0.901 | 0.905 | 0.965 | 0.929 |
结论:MusicRFM在音程、音阶、速度等多个类别上取得最佳,并在平均分上超越原始FFN探针。均值池化显著优于最后token池化。
单方向生成控制(表2):核心结果表。如上文“核心摘要”已详细列出“音符”和“和弦”类别的关键数据。整体趋势是:随着控制系数
η_0增大,控制准确率(Probe Acc.)提升,分布偏移(FD, MMD)增加,文本对齐(CLAP)基本稳定或小幅下降。外部评估指标(表4):使用外部工具(色度图、Essentia和弦检测、librosa起始点检测)验证控制效果,结果与探针评估趋势一致。
| 方法 / η0 | 音符主导率 (%) | 和弦主导率 (%) | 平均事件率 (events/s) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.15 | 0.30 | 0.45 | 0.60 | 0.15 | 0.30 | 0.45 | 0.60 | -0.60 | -0.15 | 0.15 | 0.60 | |
| MusicRFM | 18.50 | 34.47 | 52.50 | 66.47 | 24.40 | 28.40 | 30.50 | 35.00 | 20.97 | 26.24 | 30.48 | 31.65 |
| 提示+RFM | 53.57 | 67.83 | 78.23 | 85.13 | 26.60 | 27.80 | 27.30 | 33.60 | 19.02 | 22.43 | 31.66 | 32.51 |
| 仅提示 | 35.97 | 26.40 | 25.03 (慢), 30.63 (快) |
结论:RFM控制在音符任务上显著优于仅提示,结合提示效果最佳。速度控制上,RFM表现出与控制系数单调相关性。
听力测试(表3):主观评价显示MusicRFM在可懂度和控制准确性上均优于基线。
在真实音乐数据集MusicBench上的迁移(表5):证明在真实音乐上也存在可控制的属性方向,但控制难度增加。
| η0 | FD ↓ | MMD ↓ | CLAP ↑ | 准确率 ↑ |
|---|---|---|---|---|
| 0.15 | 0.424 | 0.478 | 0.315 | 0.148 |
| 0.30 | 0.495 | 0.908 | 0.308 | 0.264 |
| 0.45 | 0.576 | 1.563 | 0.276 | 0.479 |
| 0.60 | 0.717 | 2.615 | 0.247 | 0.619 |
- 时间控制与消融实验:
- 时间调度(表7 & 图1):不同时间调度(线性增减、指数衰减、正弦波等)生成的音乐,其探针softmax概率随时间变化的曲线(图1a)与预设调度高度吻合,证明了时间控制的精确性。交叉淡入淡出实验(图1b)也成功展示了两个音符概率的平滑过渡。
- 消融实验(附录C):对层剪枝(表9,表10)和随机注入概率(表11)进行了详尽消融。结果表明,指数层加权(κ=0.95)和适度的随机概率(p=0.3)在控制效果和生成质量间取得了最佳平衡。
(图7:展示了时间控制实验的结果。左图 (a) 显示在不同时间调度函数下,真实音符类别在探针softmax概率随生成步数的变化曲线,曲线形态与调度函数一致。右图 (b) 展示了在两个不同音符之间进行交叉淡入淡出时,它们对应的探针softmax概率随时间一升一降的过程。)
⚖️ 评分理由
- 学术质量:6.0/7:论文方法新颖,将RFM成功应用于音乐生成控制,提出了有效的层/时间控制机制,实验设计系统且充分,结果具有说服力。扣分点在于:1) 核心控制方向来源于合成数据探针,其在真实、复杂音乐分布下的鲁棒性未被充分验证;2) 理论深度一般,主要贡献在于工程适配和系统集成。
- 选题价值:1.8/2:可控生成是AI音频领域的核心挑战之一,本文提出的免微调、基于内部表示的控制范式具有很高的实用价值和启发性,与前沿研究高度相关。
- 开源与复现加成:0.8/1:提供了清晰的代码仓库和项目主页,并在论文中详细描述了训练配置、超参数搜索和消融实验设置,极大地便利了复现。未开源预训练模型权重是主要扣分项。