📄 StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
#语音识别 #语音大模型 #鲁棒性 #流式处理
🔥 8.0/10 | 前25% | #语音识别 | #预训练 | #语音大模型 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yuhan Song(北京大学计算机科学学院,多媒体信息处理国家重点实验室)
- 通讯作者:Linhao Zhang(张林浩,未提供机构,推测为微信AI基础模型技术中心)、Houfeng Wang(王厚峰,北京大学计算机科学学院,多媒体信息处理国家重点实验室)
- 作者列表:Yuhan Song(北京大学计算机科学学院,多媒体信息处理国家重点实验室)、Linhao Zhang(未说明具体机构)、Chuhan Wu(微信AI基础模型技术中心)、Aiwei Liu(微信AI基础模型技术中心)、Wei Jia(微信AI基础模型技术中心)、Houfeng Wang(北京大学计算机科学学院,多媒体信息处理国家重点实验室)、Xiao Zhou(微信AI基础模型技术中心)
💡 毒舌点评
这篇论文精准地抓住了现有语义语音分词器在噪声下“一碰就碎”的痛点,并提出了一个巧妙且工程友好的“位级投票”解决方案,实验结果对比非常亮眼,是解决一个实际问题的好工作。然而,其多分支结构在训练时引入的额外计算成本和复杂性未被深入讨论,且对“共识损失”的理论依据和不同变体的探索也显得较为基础。
🔗 开源详情
- 代码:提供GitHub仓库链接
https://github.com/Tencent/StableToken,论文中声明代码将公开。 - 模型权重:论文中声明模型检查点将在接受后公开。
- 数据集:训练使用的主要开源数据集列表已公开(表7)。评估使用FLEURS、LibriSpeech、CHiME-4、ESD、SEED-TTS等公开数据集。
- Demo:论文中未提及在线演示。
- 复现材料:提供了训练超参数(表8)、噪声增强配置(表9)、模型详细架构描述、消融实验设置(附录C)等详尽信息。
- 论文中引用的开源项目:骨干网络使用了Whisper-large-v3,对比基线包括HuBERT、NAST、R-Spin、SpeechTokenizer等。
📌 核心摘要
本文旨在解决当前语义语音分词器在面对微小声学扰动(即使语音清晰可辨)时输出序列极不稳定的问题,这种不稳定性严重增加了下游语音大语言模型的学习负担。论文指出问题的根源在于两个方面:脆弱的单路径量化架构和仅监督最终转录文本的遥远训练信号。为此,作者提出了StableToken,一种基于共识机制的鲁棒分词器。其核心方法包含两个相互协同的部分:(1) Voting-LFQ模块,一种多分支量化器,每个分支独立处理输入并生成二进制表示,最后通过位级多数投票机制聚合成一个稳定的输出;(2) 噪声感知共识训练策略,在训练时为部分分支提供带噪声的输入(多视图),并通过一个共识损失强制所有分支的表示保持一致,从而显式地学习对噪声不变的特征。实验表明,StableToken在单元编辑距离(UED)指标上取得了当前最优结果,相对于最佳基线(S3 Tokenizer,26.17%)将平均UED降低了60%以上至10.17%,同时保持了高质量的音频重建能力。这种基础稳定性的提升直接转化为下游语音大模型在语音识别(ASR)、语音情感识别(SER)和文本到语音(TTS)任务上的鲁棒性收益,尤其在严重噪声下性能优势显著。主要局限性在于,多分支的数量选择是经验性的,且论文未深入探讨其在不同硬件上的实际推理效率开销。
🏗️ 模型架构
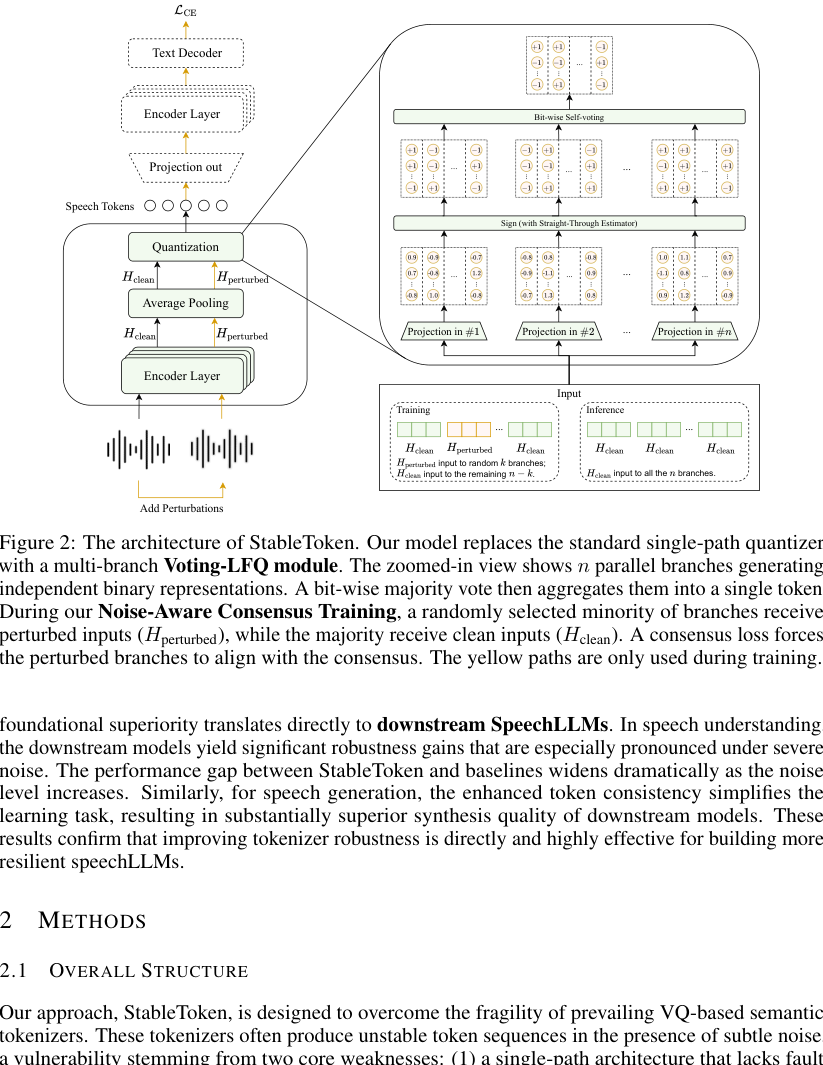
StableToken的整体架构建立在端到端ASR模型的基础之上,以Whisper-large-v3编码器为骨干网络。其核心创新在于将传统的单路径量化器替换为Voting-LFQ(投票式无查找量化)模块。
完整流程:输入语音波形经过预训练的Whisper编码器处理,得到隐藏状态序列,再通过平均池化下采样为紧凑表示h。这个h被送入Voting-LFQ模块。该模块包含n个并行的线性投影层,每个分支生成独立的投影向量p_i,随后通过符号函数(Straight-Through Estimator使其可微)二值化为B_i。在训练时,最终token通过对所有分支的B_i进行位级平均,再取符号得到;在推理时,则是严格的位级多数投票。
关键组件:
- 多分支量化器:由n个独立的线性投影层构成,为同一输入创建多个“视角”,这是实现冗余和共识的基础。
- 位级聚合与投票:这是实现鲁棒性的核心机制。训练时采用平均(提供平滑梯度),推理时采用多数投票(提供纠错能力)。由于选择奇数个分支,任何一位只有0或1两个值,多数投票能容忍少于半数的分支在该位出错。
- 噪声感知共识训练:在训练时,随机选择少于半数的分支(k < n/2)接收经过增强的含噪语音特征,其余分支接收干净特征。通过计算一个“共识损失”,强制所有分支(包括含噪分支)的预量化表示p_i向所有分支的平均值靠拢,从而让干净分支成为稳定的锚点,引导模型学习噪声不变性。
设计选择动机:单路径架构在量化边界附近缺乏容错性,一个小扰动可能导致完全不同的输出token。多分支投票机制通过冗余和位级纠错,从根本上提升了架构的鲁棒性。而噪声感知训练则提供了直接的中间监督信号,解决了传统ASR损失对中间token稳定性不敏感的问题。
💡 核心创新点
- 位级多数投票量化架构:不同于传统的单路径量化或token级集成,提出在二进制表示的“位”层面进行冗余计算和多数投票。这使得即使多个分支在token级别产生错误,只要底层比特错误是稀疏的,仍能恢复正确token,实现了更细粒度的错误纠正。
- 噪声感知共识训练范式:设计了一种新的多视图训练策略,通过向部分分支注入噪声并利用共识损失进行监督,显式地训练模型忽略与语义无关的声学扰动,从而学习到更鲁棒的离散表示。该策略与多分支架构深度耦合,架构为训练信号提供了结构,训练信号又释放了架构的潜力。
- 同时实现鲁棒性与保真度:在大幅提升噪声鲁棒性(UED降低60%+)的同时,论文证明StableToken在音频重建质量(WER和MOS)上也达到了SOTA水平,打破了“鲁棒性”与“重建质量”难以兼得的潜在认知。
🔬 细节详述
- 训练数据:在150k小时的多样化语音语料上预训练分词器,具体数据集列表见论文附表7,包括LibriSpeech、GigaSpeech、Emilia等开源数据及内部数据。
- 损失函数:总损失为加权和,公式为
L_total = L_ASR + λ1 L_consensus + λ2 L_commitment + λ3 * L_codebook。其中:L_ASR:交叉熵损失,用于ASR任务。L_consensus:共识损失,计算每个分支的预量化向量p_i与所有分支平均值p_all的L2距离,权重λ1=0.25。旨在使含噪分支对齐到干净共识。L_commitment:承诺损失,鼓励编码器隐藏状态接近量化后的表示,权重λ2=0.25。L_codebook:码本熵损失,促进码本均匀使用,权重λ3=1.0。
- 训练策略:使用AdamW优化器,OneCycleLR学习率调度,最大学习率
1.5e-5,warmup步数1000,权重衰减0.01,梯度裁剪1.0。训练步数未明确说明。 - 关键超参数:码本大小
2^13=8192(二进制表示维度d=13),帧率25Hz,主实验中投票分支数n=5。训练时使用噪声增强的语音(高斯、粉红、棕色噪声、比特压缩、真实噪声),噪声强度范围见附表9。 - 训练硬件:未说明。
- 推理细节:推理时对所有n个分支输入相同的干净语音,进行位级多数投票生成最终token。对于超过30秒的音频,采用分块处理策略。
- 正则化:通过码本熵损失和承诺损失进行正则化。噪声增强本身也是一种数据增强正则化。
📊 实验结果
Tokenizer层面鲁棒性对比(表1)
模型 平均UED% (↓) 相对于最佳基线的相对降低 S3 Tokenizer (最佳基线) 26.17 - R-Spin (最佳SSL基线) 16.48 37.0% StableToken (Ours) 10.17 61.1% 论文在多种合成和真实噪声条件下均取得显著更低的UED,且使用更大的码本(8192 vs. 4096)使得结果更具说服力。 下游语音理解任务(ASR)结果
- 噪声条件下的WER (图3上排,数值见正文描述):在CHiME-4测试集(真实噪声)上,StableToken的WER(35.90%)比次优基线(GLM-4-Voice,51.08%)相对降低约30%。在合成和真实噪声下,随着SNR降低,StableToken的优势逐渐扩大。
- 具体数值(表3,ASR部分):
| Tokenizer | CHiME-4 Test-Real WER (%) | CHiME-4 Test-Simulated WER (%) |
|---|---|---|
| CosyVoice | 54.63 | 47.71 |
| CosyVoice2 | 59.83 | 55.01 |
| GLM-4-Voice | 51.08 | 43.09 |
| StableToken | 35.90 | 30.61 |
图表显示,在干净语音(Original)下各模型性能接近,但在噪声增强后,基于StableToken的模型WER上升最慢,鲁棒性优势明显。
下游语音情感识别(SER)结果(图3下排):在多种噪声下,基于StableToken的模型分类准确率始终高于基线,且随噪声增强优势扩大。
下游语音合成(TTS)结果(表3,TTS部分):
| Tokenizer | SEED-TTS-EN WER (%) | SEED-TTS-EN MOS | SEED-TTS-ZH WER (%) | SEED-TTS-ZH MOS |
|---|---|---|---|---|
| CosyVoice | 7.80 | 3.52 | 8.73 | 3.47 |
| CosyVoice2 | 7.22 | 3.75 | 9.89 | 3.37 |
| GLM-4-Voice | 6.19 | 4.19 | 5.26 | 3.85 |
| StableToken | 4.43 | 4.12 | 3.02 | 4.08 |
StableToken在合成语音的可懂度(WER)上显著优于所有基线,同时在自然度(MOS)上也具有竞争力。
- 消融实验(表4):证明了共识损失和噪声感知训练的必要性。移除共识损失后,真实OOD噪声的UED从10.96%增至17.43%;进一步移除噪声感知训练,WER也显著上升。
⚖️ 评分理由
- 学术质量:6.0/7。论文问题定义清晰,创新点(位级投票、共识训练)明确且有效,技术方案设计合理。实验非常充分,覆盖了tokenizer自身指标、多种下游任务(理解、生成)、多种噪声条件,并进行了细致的消融研究。数据对比鲜明,证据可信。扣分点在于,对于多分支投票的理论优势(如与集成学习的比较)分析不够深入,且对“共识损失”的其他形式(如余弦相似度)未做深入探讨。
- 选题价值:1.5/2。提升语音表示的鲁棒性是构建实用语音大模型的关键瓶颈之一,本文直接针对这一核心痛点。研究成果可广泛应用于噪声环境下的语音理解、生成与交互,具有明确的工程应用价值和学术影响力。
- 开源与复现加成:0.5/1。论文明确承诺公开代码和模型权重(GitHub链接已提供),并提供了详细的训练超参数、数据集列表、噪声配置等复现信息,透明度很高。但因其为会议论文(ICLR 2026),目前代码/模型可能尚未完全发布,故给予部分加分。