📄 SpeechOp: Inference-Time Task Composition for Generative Speech Processing
#语音增强 #语音分离 #扩散模型 #多任务学习 #零样本
✅ 7.5/10 | 前25% | #语音增强 | #扩散模型 | #语音分离 #多任务学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Justin Lovelace(Cornell University)
- 通讯作者:未明确说明(论文作者来自Cornell University和Adobe Research,从贡献描述看,Adobe Research团队的Rithesh Kumar, Jiaqi Su, Ke Chen, Zeyu Jin可能承担更多指导角色,但论文未明确标注通讯作者)
- 作者列表:
- Justin Lovelace(Cornell University)
- Rithesh Kumar(Adobe Research)
- Jiaqi Su(Adobe Research)
- Ke Chen(Adobe Research)
- Kilian Q Weinberger(Cornell University)
- Zeyu Jin(Adobe Research)
💡 毒舌点评
本文巧妙地将“资源过剩”的TTS模型改造为“资源匮乏”S2S任务的处理器,其提出的TC-CFG推理组合策略从原理上解释了如何优雅地融合不同生成任务的信号,避免了简单的分数平均带来的先验冲突。然而,论文的核心扩散架构(DiT+VAE)和多任务训练范式本身并无颠覆性创新,其真正亮点在于系统整合与工程设计,且在代码和模型开源方面显得较为吝啬,限制了社区的快速跟进与验证。
🔗 开源详情
- 代码:论文中提及项目网站
https://justinlovelace.github.io/projects/speechop用于展示音频样本,但未提供代码仓库链接。 - 模型权重:未提及是否公开预训练模型或微调后的权重。
- 数据集:使用的是公开数据集(MLS, LibriTTS, LibriTTS-R, LibriMix等),但论文中未提供专门整理的数据集或下载脚本。
- Demo:提供了音频样本演示网站,但无交互式在线Demo。
- 复现材料:附录中提供了详尽的模型架构参数、训练配置、采样配置、数据模拟流程等,为复现提供了很好的指导。未提及提供训练检查点、预处理脚本或环境配置文件。
- 论文中引用的开源项目:主要依赖的开源项目包括:ByT5文本编码器、DAC音频编解码器、Whisper/WhisperX ASR模型、以及评估中使用的PESQ、MCD、WavLM-TDCNN等工具。
- 开源计划:论文中未提及明确的代码或模型开源计划。
📌 核心摘要
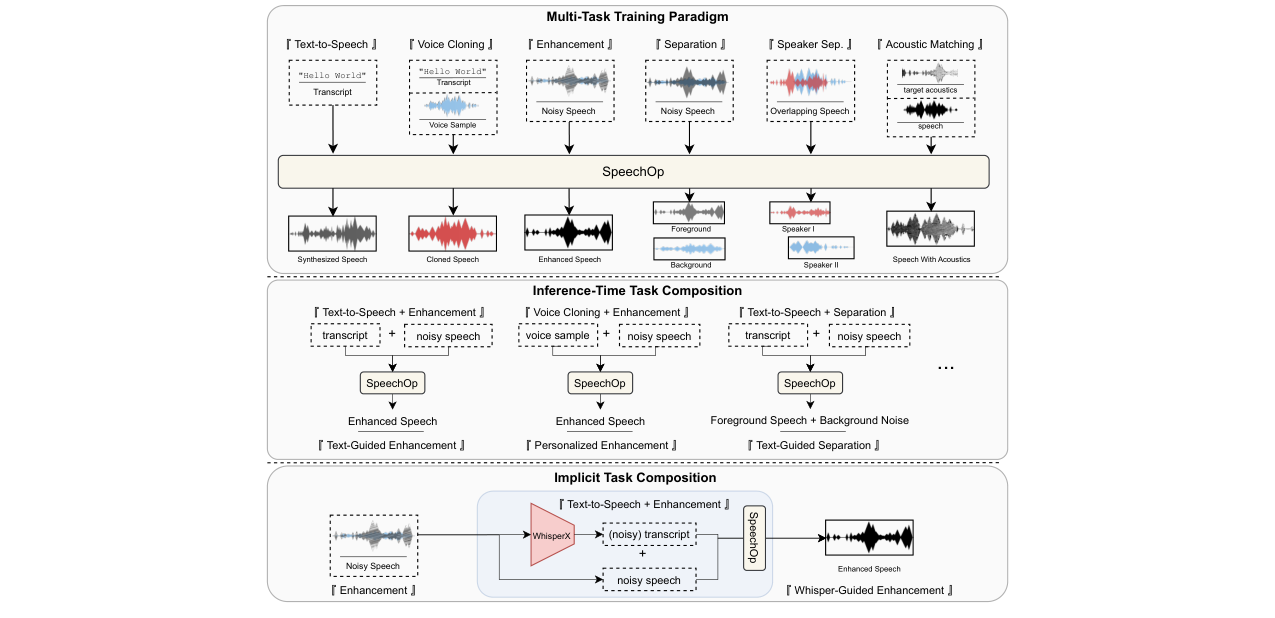
这篇论文针对语音到语音(S2S)处理任务(如语音增强、分离)因配对训练数据稀缺而导致内容与说话人信息易失真的问题,提出了一种名为SpeechOp的多任务潜在扩散模型。其核心思想是将一个在海量数据上预训练的TTS模型,通过适配训练转化为一个能执行多种S2S任务的通用语音处理器,并在推理时支持灵活的“任务组合”。与已有方法相比,新在三个方面:1)证明了TTS预训练能显著加速并提升S2S任务的训练与性能;2)提出了“任务组合分类器引导”(TC-CFG)策略,这是一种基于贝叶斯分解和无分类器引导原理的推理时组合方法,允许模型同时进行增强和文本引导,避免了简单分数平均的问题;3)设计了“隐式任务组合”(ITC)管线,利用Whisper等ASR模型生成的转录本,通过TC-CFG指导增强过程,无需在训练时提供转录本。主要实验结果显示:在零样本TTS和语音编辑上,SpeechOp超越或持平更强基线;在语音增强上,ITC将词错误率(WER)从基线模型的5.4%降至2.9%(相对降低46%),实现了SOTA的内容保留;在说话人分离的主观MOS评分上,SpeechOp显著优于SepFormer系列模型。该工作的实际意义在于提供了一个统一、灵活且高效的框架,能利用丰富的TTS数据知识来解决数据受限的S2S任务,并通过可调的TC-CFG在内容恢复和声学保真度间取得平衡。主要局限性是未提供代码和模型权重,其生成模型在客观信号保真度指标上仍逊于一些判别式方法。
🏗️ 模型架构
SpeechOp是一个基于潜在扩散的Transformer模型,旨在统一处理TTS和多种S2S任务。其整体架构和数据流如下图所示:
- 完整输入输出流程
- 输入:根据任务不同,输入可以是文本转录(TTS)、带噪语音(增强)、混合语音+说话人提示(分离)等。所有音频输入首先通过一个音频编码器压缩到潜在空间。
- 输出:生成的干净语音的潜在表示,再通过音频解码器还原为波形。
- 主要组件
- 音频编码器(Audio Encoder):一个8层的DiT架构(71M参数),负责将源音频(如带噪语音)编码为潜在表示。其输出通过逐帧相加(Frame-wise Mixing) 的方式直接与扩散过程中的噪声潜在变量
z_t融合,而非使用交叉注意力。这种设计保证了源与目标音频在帧级上的对齐,并能泛化到不同长度的序列。 - 扩散变换器(Diffusion Transformer, DiT):核心生成网络(419M参数,20层),负责在潜在空间进行去噪。它接收融合了源音频信息的噪声潜在变量
z_t、时间步t和任务嵌入(Task Embedding) 作为输入。对于TTS任务,它还通过交叉注意力机制接收文本编码器的输出。 - 文本编码器(Text Encoder):使用一个冻结的预训练ByT5-base模型,将文本转录编码为字符级表示,捕捉音素信息,通过交叉注意力指导DiT的生成过程。
- 任务嵌入(Task Embedding):一个可学习的嵌入向量,通过自适应归一化(AdaLN)层同时作用于音频编码器和DiT,使模型根据任务类型(如增强、分离、TTS)调整其行为。
- 关键设计选择与动机
- 两阶段训练:首先进行大规模TTS预训练,让模型学习自然语音的分布;然后进行多任务微调,引入S2S任务。这利用了TTS数据丰富的优势来初始化S2S任务。
- 音频编码器的逐帧相加:与附录F中的消融实验所示,这种简单且显式对齐的方式比交叉注意力更鲁棒,能更好地处理变长语音。
- 输入调节:对于需要提示的任务(如说话人分离),提示音频会与源音频拼接,共同输入音频编码器,以保持帧级对齐。
💡 核心创新点
- TTS预训练驱动的多任务S2S框架:首次系统性地证明并利用预训练TTS模型作为“基础模型”,通过适配训练转化为高性能、多任务的语音处理器(SpeechOp)。它解决了S2S任务数据不足的根本痛点,并实现了任务间的正向迁移(例如,S2S训练反过来提升了TTS质量)。
- 任务组合分类器引导(TC-CFG):这是论文理论贡献的核心。它基于贝叶斯规则和条件独立假设,将组合任务的得分函数分解为增强得分
∇z_t log p(z_t|y)和文本判别引导项∇z_t log p(w|z_t),后者通过CFG近似。这避免了直接平均TTS和增强模型得分(Score Averaging)所引入的先验冲突问题,实现了更优的任务组合。 - 隐式任务组合(ITC)管线:一个创新的应用流程,将强大的判别式ASR模型(Whisper)与生成式的SpeechOp模型在推理时通过TC-CFG无缝结合。它无需在训练时提供转录本,即可利用网络规模的ASR知识来指导增强,实现了鲁棒的内容保留,达到了SOTA。
- 灵活的语音处理组合:TC-CFG使得在推理时动态组合不同能力成为可能,例如“文本引导的增强”、“个性化的增强”(结合语音克隆)等,为语音处理开辟了新的应用场景。
🔬 细节详述
- 训练数据:
- TTS:结合MLS English(约44k小时,长语音)和LibriTTS(585小时,短语音),共约45k小时。音频重采样至48kHz,文本小写化。
- S2S任务:使用LibriTTS-R作为干净语音源,通过添加噪声、脉冲响应(来自DNS Challenge, EchoThief等数据集)动态模拟各种退化条件,生成5秒的配对数据。具体增强流程见附录D。
- 损失函数:
- 扩散模型训练目标:采用基于速度参数化(v-prediction)的去噪分数匹配(DSM)损失,并结合Sigmoid损失加权(偏置-2.5)以关注感知相关的噪声水平。
- 音频自编码器训练:重建损失(L1) + KL散度损失(权重0.1) + 对抗损失(使用复数STFT判别器)。
- 训练策略:
- 阶段一(TTS预训练):使用DiT骨干,训练400k步,批量大小4/GPU,AdamW优化器(lr=2e-4,权重衰减0.1),4000步warmup,梯度累积2步。
- 阶段二(多任务微调):在TTS模型基础上添加8层音频编码器,联合微调所有参数200k步,学习率降至1e-4,权重衰减0.01。TTS与S2S样本等概率采样,S2S内对增强和分离任务进行3倍上采样。
- 关键超参数:
- 模型规模:DiT(419M参数),音频编码器(71M参数),总计约490M。
- 音频编码器:将48kHz音频压缩为64维、40Hz的潜在表示(下采样1200倍)。
- 采样:使用SDE-DPM-Solver++(2M)采样器,256步。引导强度:S2S任务为1.5,零样本TTS为3.0(转录本和提示),语音编辑为2.0。
- 训练硬件:32块Nvidia A100 GPU。
- 推理细节:对于TTS和语音编辑,通过参考语音的语速估算输出时长。对于任务组合(ITC),TC-CFG的引导强度γ设为1.5,并在logSNR > -1.0时才启用TTS引导,以在噪声较大时优先依赖声学信息。
- 正则化/稳定训练:训练时随机丢弃条件信息(源音频和文本)10%,以支持无分类器引导。
📊 实验结果
论文在三个核心任务上进行了全面评估,以下是关键结果对比:
表1:零样本文本到语音(TTS)评估
| 模型 | 参数 | 训练数据 | WER ↓ | SIM ↑ | MOS-Q ↑ | MOS-N ↑ | MOS-VS ↑ | MOS-SS ↑ |
|---|---|---|---|---|---|---|---|---|
| DiTTo-TTS | 740M | ~56k hrs | 2.56 | .62 | 4.16±0.04 | 4.14±0.04 | 4.17±0.04 | 4.02±0.04 |
| VoiceCraft | 830M | ~69k hrs | 6.32 | .61 | 3.66±0.04 | 3.65±0.05 | 3.43±0.05 | 3.38±0.05 |
| CLaM-TTS | 584M | ~56k hrs | 5.11 | .49 | 3.67±0.04 | 3.70±0.04 | 3.69±0.05 | 3.54±0.05 |
| TTS Baseline (Ours) | 419M | ~45k hrs | 3.32 | .48 | 3.65±0.05 | 3.56±0.05 | 3.31±0.05 | 3.25±0.05 |
| SpeechOp (Ours) | 419M | ~45k hrs | 3.57 | .53 | 3.86±0.04 | 3.69±0.05 | 3.67±0.05 | 3.58±0.05 |
结论:SpeechOp在MOS各项指标上超越了更大或同规模的其他TTS模型(VoiceCraft, CLaM-TTS, XTTS),并接近更强的DiTTo-TTS,证明了多任务训练提升了TTS质量。
表3:语音增强结果(定量与主观)
| 模型 | PESQ ↑ | MCD ↓ | SpBS ↑ | WER ↓ | MOS ↑ |
|---|---|---|---|---|---|
| Noisy Source Audio | 1.12 | 11.22 | .888 | 3.3 | 1.78±0.07 |
| StoRm | 1.61 | 6.36 | .883 | 7.0 | - |
| SGMSE+ | 1.98 | 5.28 | .923 | 5.7 | 3.76±0.03 |
| HiFi-GAN-2 | 2.23 | 4.40 | .934 | 5.4 | 3.90±0.04 |
| SpeechOp (No Transcript) | 2.00 | 4.83 | .908 | 8.1 | 3.93±0.04 |
| +ITC (WhisperX) | 2.05 | 4.85 | .928 | 2.9 | 3.89±0.04 |
| +Speaker Personalization | 2.12 | 4.69 | .926 | 2.4 | - |
结论:SpeechOp的ITC管线在内容保留(WER)上取得了2.9%的最佳结果,相比HiFi-GAN-2(5.4%)相对降低46%。主观质量MOS与HiFi-GAN-2相当。

图6:不同说话人分离模型在多个数据集上的主观MOS评分对比。SpeechOp在所有数据集上均取得最高分。
表6:任务组合方法消融(使用黄金转录本)
| 模型 | PESQ ↑ | MCD ↓ | SpBS ↑ | WER ↓ |
|---|---|---|---|---|
| Noisy Source Audio | 1.12 | 11.22 | .888 | 3.3 |
| SpeechOp (No Transcript) | 2.00 | 4.83 | .908 | 8.1 |
| SpeechOp (TC-Avg) | 1.88 | 5.24 | .909 | 3.4 |
| SpeechOp (TC-CFG) | 2.06 | 4.83 | .931 | 2.1 |
结论:TC-CFG在所有指标上优于简单的分数平均(TC-Avg),尤其在WER上(2.1% vs 3.4%)和信号保真度上,证实了其理论优势。下图1D仿真直观展示了TC-CFG如何引导样本分布向目标模态集中,而不破坏增强模型的先验。

图4:1D高斯混合模型仿真,对比了无引导(b)、分数平均(c)和TC-CFG(d)的效果。TC-CFG能准确将分布引导向目标模式(对应正确文本),而不像分数平均那样使分布“弥散”。
⚖️ 评分理由
- 学术质量:5.5/7:论文有明确的痛点(S2S数据稀缺)、清晰的解决思路(迁移TTS预训练)、创新的方法(TC-CFG)、充分的实验验证。技术路线扎实,实验比较全面且包含关键消融。创新主要体现在方法整合与推理策略,而非底层模型架构的革命。
- 选题价值:1.5/2:语音增强和分离是语音处理领域长期存在的核心需求。该工作提出用TTS数据“反哺”S2S任务,并设计可组合的框架,具有明确的实用价值和启发意义,能引起相关领域研究者(尤其是生成式语音处理)的兴趣。
- 开源与复现加成:0.3/1:论文提供了极具价值的详细附录(架构、训练、评估细节)和在线音频样本,但未公开代码、模型权重或复现脚本。这对于一个强调可复现性和开源精神的顶级会议论文来说是显著的不足,因此只给予小幅加分。