📄 Speech World Model: Causal State–Action Planning with Explicit Reasoning for Speech
#语音情感识别 #因果图 #显式推理 #语音大模型 #多模态
✅ 7.5/10 | 前25% | #语音情感识别 | #因果图 | #显式推理 #语音大模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xuanru Zhou (浙江大学), Jiachen Lian (UC Berkeley) (论文明确标注两位作者贡献均等)
- 通讯作者:未明确说明
- 作者列表:Xuanru Zhou (浙江大学), Jiachen Lian (UC Berkeley), Henry Hong (UC Berkeley), Xinyi Yang (浙江大学), Gopala Anumanchipalli (UC Berkeley)
💡 毒舌点评
亮点是将认知科学的模块化思想形式化为一个可计算的因果图(WMA, ToM, SA, Prag),并利用其结构化先验显著提升了训练效率和推理能力,为“如何让语音模型像人一样思考”提供了一个新颖的框架。短板在于,该因果图的结构是预定义的,限制了模型对未见依赖关系的适应能力,且完全依赖合成标签训练指令微调阶段,可能成为性能上限的瓶颈。
🔗 开源详情
- 代码:论文中提及将开源代码,但未提供具体仓库链接。(原文:“we will open source the model and data”)
- 模型权重:论文中提及将开源模型,但未提供具体下载链接。
- 数据集:使用了MELD, IEMOCAP, SLURP, VoxCeleb四个公开数据集,并通过Vicuna生成了部分伪标签数据。未提及是否会发布生成的伪标签数据集。
- Demo:提供了Demo音频链接:http://bit.ly/4pBJuWP。
- 复现材料:提供了极其详尽的附录,涵盖模型架构细节(A.7)、训练配置(A.5)、损失函数与算法(A.2, A.8)、评估指标公式与算法(A.8)、数据集统计与标签空间(A.4)、以及用于指令微调的完整提示模板(A.5.2, A.9)。
- 论文中引用的开源项目:WavLM, distil-BERT, opensmile, Vicuna-13b-v1.5, LoRA, Llama3.1-8B, Qwen2-Audio。
📌 核心摘要
- 解决的问题:当前语音语言模型(SLMs)多为黑箱式级联架构,虽擅长内容分析,但在需要复杂推理的场景(如情感、意图推断)下表现薄弱,且推理过程不透明,易产生幻觉。
- 方法核心:提出“语音世界模型”(SWM),将语音理解分解为四个认知模块:世界模型激活(情境)、心智理论(说话者情绪)、言语行为(沟通功能)和语用意图(深层目的)。这些模块通过一个预定义的因果图连接,模拟人类语音感知中状态的因果依赖。系统首先训练此因果图以建立认知状态搜索空间,然后将其输出(各模块状态)作为显式提示,指导经过指令微调的语言模型生成逐步推理链和最终回复。
- 创新之处:与传统SLMs和基于思维链的启发式方法不同,SWM首次提出并实现了基于认知原理的图结构化语音理解模型。其创新在于:(1) 显式建模语音理解的因果动态,(2) 通过图结构实现半监督学习(从标注不全的数据中学习),(3) 将结构化状态作为“锚点”引导大语言模型进行更可靠、可解释的推理。
- 主要实验结果:
- 图评估:所提因果图相比随机图,训练速度快约5倍(2.07小时 vs. 10.39小时),且在因果效应(ACE/ICS)上更稳定。半监督设置下,未标注模块能通过因果结构被有效推断。
- 指令微调:在多项推理指标(Model-as-Judge评分)上,SWM显著超越了Qwen2-Audio等开源基线及CoT微调基线。在情感识别等任务上甚至超过GPT-4o,整体性能接近Gemini 2.5 Pro,但训练成本极低(仅20 GPU小时)。关键对比结果见下表。
| 模型 | 提示风格 | 总体M.J.分数 (0.6推理 + 0.4回复) ↑ | 推理分数 ↑ | 情感分类准确率 ↑ |
|---|---|---|---|---|
| 我们的模型 (SWM, Llama3.1-8b) | CoT | 7.81 | 7.84 | 66.26 |
| 我们的模型 (SWM, Qwen2-Audio) | CoT | 7.59 | 7.26 | 71.02 |
| Qwen2-Audio-CoT (基线微调) | CoT | 5.18 | 4.76 | 34.72 |
| Qwen2-Audio (开源) | CoT | 2.39 | 1.96 | 17.50 |
| Voxtral (开源) | CoT | 2.92 | 2.52 | 5.56 |
| GPT-4o (商业) | CoT | 7.41 | 6.98 | 45.16 |
| Gemini 2.5 Pro (商业) | CoT | 8.12 | 8.02 | 51.29 |
- 实际意义:为构建更高效、可解释且推理能力更强的语音AI系统提供了新范式。它证明了引入认知结构的先验知识,能让小模型以极低的成本获得与庞大商业模型竞争的能力。
- 主要局限性:(1) 当前仅使用四个模块,可能无法覆盖所有语音动态。(2) 因果图结构是预定义的,缺乏自适应性。(3) 依赖合成标签生成训练数据,可能引入偏差。
🏗️ 模型架构
SWM系统采用两阶段流水线架构,核心是因果图引导的显式推理。
整体流程:输入语音信号,经多模态编码与融合后,输入预先训练的因果图推理得到四个结构化状态(WMA, ToM, SA, Prag)。这些状态与原始语音/文本一起作为提示,输入经过指令微调的大语言模型,最终生成包含推理过程和回复的文本。
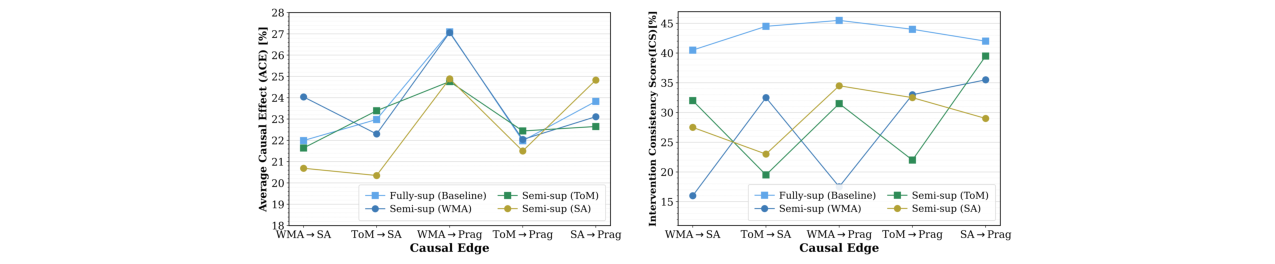
图2:Speech World Model系统流水线图。展示了“因果图引导的显式推理”过程,包括因果图训练和指令微调两个阶段。
主要组件详解:
输入与编码:
- 文本输入:转录文本通过distil-BERT编码器得到文本特征
h_text。 - 声学输入:原始语音通过预训练的WavLM提取特征,再经CNN-LSTM适配器得到声学特征
a。 - 韵律输入:通过opensmile提取88维韵律特征
z。 - 特征融合:采用门控融合机制将上述特征融合成统一的256维表示
g = ϕ(h_text, a, z)。
- 文本输入:转录文本通过distil-BERT编码器得到文本特征
因果图模块(核心创新): 因果图定义了四个模块间的因果关系:
WMA → SA,ToM → SA,WMA → Prag,ToM → Prag,SA → Prag。每个模块是一个独立的神经网络分类器。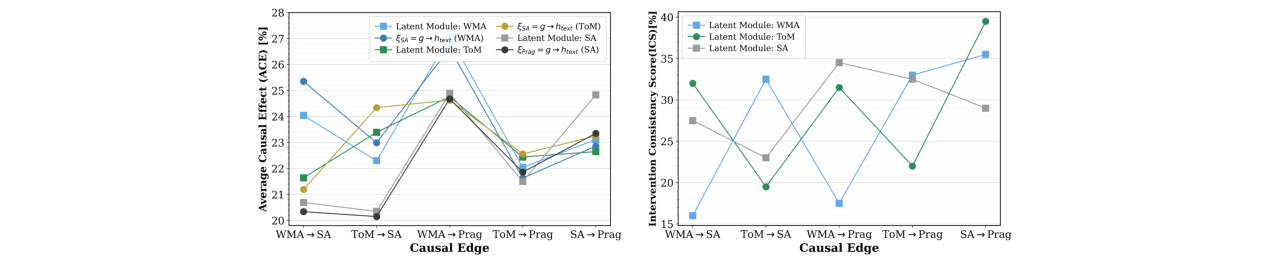
图3:两种世界模型的统一视角。展示了生成式世界模型(左)、本文提出的因果图(中)和语言世界模型(右)都可视为前向动力学模型。因果图提供了对语音状态动力学的显式、结构化表述。
- WMA模块:接收文本和声学特征,经时序自注意力+MLP,输出30个情境类别。
- ToM模块:接收融合特征
g,经时序自注意力+MLP,输出7种情绪类别。 - SA模块:作为
WMA和ToM的子节点,接收它们的状态输出以及融合特征(或文本特征),经残差MLP,输出24种言语行为类别。 - Prag模块:作为
SA,ToM,WMA的子节点,接收它们的状态输出及融合特征(或文本特征),经残差MLP,输出14种语用意图类别。 - 状态计算:对于节点v,其状态
S_v = softmax(W_v · ψ_v([ξ_v, {S_u}_{u∈Pa(v)}])),其中ξ_v是该节点使用的特征,{S_u}_{u∈Pa(v)}是其父节点状态。
因果图训练:
- 完全监督:所有模块均有标签,使用多任务交叉熵损失(公式3)。采用教师强制(公式4)训练边。
- 半监督:部分模块标签缺失。通过禁用缺失标签父节点的教师强制,让损失信号通过因果边反向传播,从而更新无标签父节点的参数(公式5,图4A)。
图4:不同训练场景下的梯度流对比。展示了(A)半监督因果图:梯度通过因果边反向传播到无标签父节点;(B)全监督因果图:损失局部应用,但因果结构指导梯度流;(C)全监督随机图:梯度传播冗余低效。
指令微调:
- 将因果图输出的状态
{S_WMA, S_ToM, S_SA, S_Prag}与指令和语音/文本输入拼接,作为提示送入LLM(如Llama-3.1-8B用于纯文本设置,Qwen2-Audio用于多模态设置)。 - 训练目标为生成包含
[REASONING]...[RESPONSE]...的目标序列y,损失为标准交叉熵(公式7,8)。
- 将因果图输出的状态
💡 核心创新点
- 认知启发的因果图模块化建模:首次将语音理解系统性地分解为四个认知模块(情境、情绪、行为、意图),并利用预定义的因果图明确建模其依赖关系。这超越了传统SLMs的“黑箱”集成和CoT的启发式搜索,为语音理解提供了结构化、可解释的内部状态表示。
- 结构化先验提升训练效率与半监督能力:因果图结构作为一种强先验,显著降低了模型学习依赖关系的难度。实验表明,其训练速度比无结构的随机图快约5倍。更重要的是,因果结构使得模型能够利用部分标注数据,通过反向传播推断缺失模块的标签,实现了有效的半监督学习。
- 显式推理引导生成以减少幻觉:通过将结构化的因果状态作为显式提示,引导LLM的推理过程,相当于为LLM提供了一个“思考脚手架”。这迫使模型基于可验证的认知状态进行推理,而非仅依赖统计相关性,从而在推理任务上(尤其是情感识别)取得了超越许多更大模型的性能,并显著减少了幻觉。
- 统一的世界模型视角:将生成式世界模型、语言世界模型和本文的因果图统一在“前向动力学模型”的框架下(图3),阐明了其工作的理论位置:因果图提供了一种显式的、结构化的动力学表示,用于约束和指导语言模型的前向推理。
🔬 细节详述
- 训练数据:使用MELD(情感对话)、IEMOCAP(情感交互)、SLURP(语音助手)、VoxCeleb(说话人识别)四个公开数据集,总计约12.5万条语音,约113小时。部分标签缺失,通过Vicuna-13b-v1.5生成伪标签补全(两阶段:标签补全与推理响应合成)。
- 损失函数:
- 因果图训练损失:多任务交叉熵损失
L_sup = Σ Σ m_i,v * CE(y_i,v, S_i,v),其中m_i,v表示标签是否可用。 - 指令微调损失:标准语言建模交叉熵损失
L_IT = -Σ log P_θ(y | Instr, ...)。
- 因果图训练损失:多任务交叉熵损失
- 训练策略:
- 因果图:使用AdamW优化器,学习率1e-3,30个epoch,批量大小32。教师强制概率
p=0.3。 - 指令微调:使用LoRA进行参数高效微调。Llama3.1-8B: 秩64,alpha 16,学习率5e-5,20个epoch,有效批量128。Qwen2-Audio: 秩16,alpha 32,学习率2e-4,20个epoch,有效批量16。采用余弦学习率调度。
- 因果图:使用AdamW优化器,学习率1e-3,30个epoch,批量大小32。教师强制概率
- 关键超参数:融合特征维度256。WMA、SA模块的MLP隐藏层256维;ToM、Prag模块的MLP隐藏层128维。
- 训练硬件:因果图训练在单块NVIDIA RTX A6000 GPU上完成(耗时约2小时)。指令微调在4块NVIDIA A6000 GPU上完成(纯文本设置19小时,多模态设置24.6小时)。
- 推理细节:指令微调阶段使用标准自回归解码。评估时使用Model-as-Judge方法,由GPT-4o作为评判模型打分。
- 正则化技巧:因果图训练中使用教师强制(公式4)平衡真实标签与模型预测的使用。指令微调中使用LoRA防止过拟合。
📊 实验结果
- 因果图评估(图评估) 主要验证所提因果图结构的有效性和效率。结果表明其收敛快、因果关系强且稳定。
| 方法 | 设置 | 节点质量 (准确率 %, ↑) | 边因果效应 | ||||
|---|---|---|---|---|---|---|---|
| WMA | ToM | SA | Prag | 平均ACE (%, ↑) | 平均ICS (%, ↑) | ||
| 因果图 | 全监督 | 69.4 | 73.5 | 65.3 | 81.4 | 23.57 | 43.29 |
| 半监督 (WMA潜变量) | 34.8 | 75.0 | 70.7 | 83.2 | 21.71 | 26.9 | |
| 半监督 (ToM潜变量) | 69.1 | 43.3 | 69.6 | 83.5 | 21.98 | 28.9 | |
| 半监督 (SA潜变量) | 69.3 | 77.0 | 34.4 | 82.5 | 21.65 | 29.3 | |
| 随机图 | 全监督 | 69.7 | 74.0 | 67.5 | 83.6 | - | - |
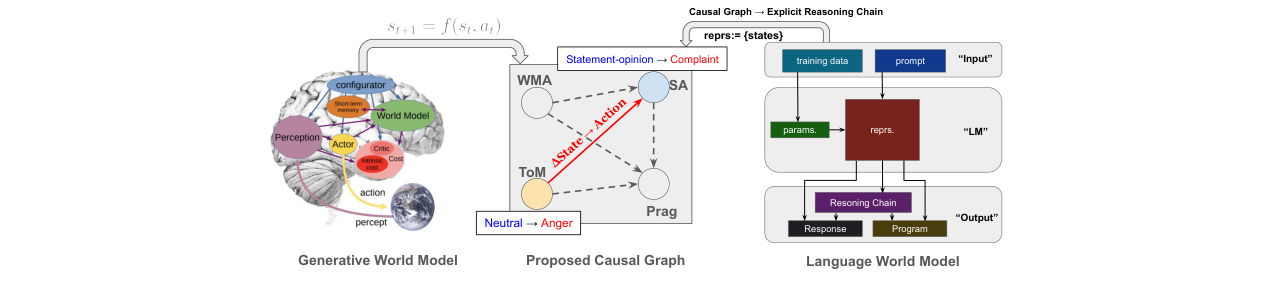
图5:因果边在不同监督设置下的ACE与ICS。展示了在完全监督和半监督设置下,每条因果边的平均因果效应(ACE)和干预一致性分数(ICS)。半监督时,无标签模块连接的边(如ToM→SA)的ACE会下降,但其他边(如WMA→SA)保持稳定,证明了模块解耦。
关键发现:
- 效率:因果图收敛时间(2.07h)远快于随机图(10.39h)。
- 稳定性:随机图的信息流随教师强制概率变化剧烈(表2),而因果图结构稳定。
- 半监督能力:当某个模块(如ToM)无标签时,其自身准确率下降,但其下游依赖模块(如SA)的准确率反而可能提升,且图整体因果效应得以保持,证明了因果图作为潜变量生成器的有效性。
- 语音理解与推理评估 与多个基线模型对比,评估最终系统的推理能力。SWM显著超越开源模型和CoT基线,接近商业模型。
| 模型 | 提示风格 | 总体M.J.分数 (0.6推理 + 0.4回复) ↑ | 推理分数 ↑ | 回复分数 ↑ | 情感提及率 EM ↑ | 情感分类准确率 EA ↑ | 推理长度 (词) |
|---|---|---|---|---|---|---|---|
| 我们的SWM (Llama3.1-8b) | CoT | 7.81 | 7.84 | 7.76 | 97.80 | 66.26 | 105.70 |
| 我们的SWM (Qwen2-Audio) | CoT | 7.59 | 7.26 | 8.08 | 91.80 | 71.02 | 104.64 |
| Qwen2-Audio-CoT (微调基线) | CoT | 5.18 | 4.76 | 5.82 | 92.11 | 34.72 | 102.44 |
| Qwen2-Audio (开源) | CoT | 2.39 | 1.96 | 3.04 | 6.11 | 17.50 | 21.19 |
| Voxtral (开源) | CoT | 2.92 | 2.52 | 3.52 | 10.89 | 5.56 | 71.42 |
| GPT-4o (商业) | CoT | 7.41 | 6.98 | 8.06 | 68.20 | 45.16 | 105.23 |
| Gemini 2.5 Pro (商业) | CoT | 8.12 | 8.02 | 8.28 | 82.47 | 51.29 | 112.62 |
关键发现:
- 仅用高质量CoT数据微调的Qwen2-Audio-CoT基线就已大幅超越原始开源模型,验证了数据质量的重要性。
- 在基线之上,引入因果图显式推理的SWM模型在推理分数、情感分类准确率等关键指标上实现了巨大提升(EA从34.72%提升至66.26%/71.02%),甚至在情感准确率上超过了GPT-4o(45.16%)和Gemini 2.5 Pro(51.29%)。
- 虽然总体M.J.分数略低于Gemini 2.5 Pro(7.81/7.59 vs 8.12),但论文强调SWM的训练成本极低(约20 GPU小时),体现了结构化先验带来的高效率。
- 消融研究(表5,表6)
- 融合机制:门控融合在节点准确率上平衡性最好,注意力融合在ACE上略优,Transformer融合虽然ACE高但节点准确率下降。
- 教师强制概率:性能对
p值(0.3-1.0)相对鲁棒,p=0.8时ACE和ICS最高。 - 边移除:移除
ToM→SA边导致SA准确率显著下降(从65.3%降至61.9%),验证了该因果连接的重要性。 - 半监督特征:当潜���量模块的子节点仅使用文本特征时,模型性能保持稳定,证明图能有效传播信息。
图6:不同融合机制和教师强制概率下的因果边效果。展示了完全监督设置下,不同设计选择对每条因果边ACE和ICS的影响。
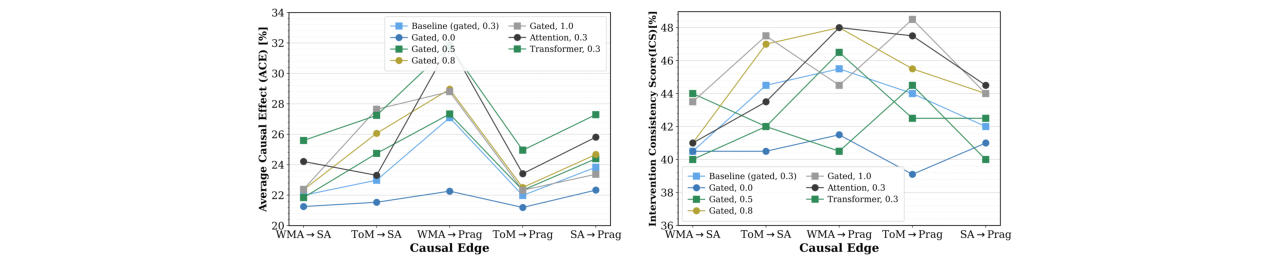
图7:移除特定因果边后的效果。展示了在完全监督设置下,移除 ToM→SA 或 WMA→SA 边后,相关因果边的ACE和ICS变化,用于验证边的重要性。
⚖️ 评分理由
- 学术质量:6.5/7 - 创新性高,将认知模型形式化为可计算的因果图,思路新颖且逻辑自洽。技术实现完整,从图建模、训练策略(含半监督)到指令微调形成闭环。实验设计全面,有充分的消融研究证明各组件有效性。主要扣分点在于:与最先进商业模型相比,整体性能仍有差距;部分图表仅展示关键趋势而未提供所有原始数据点。
- 选题价值:1.5/2 - 研究方向前沿,针对当前SLM推理能力弱、不可解释的核心痛点。其提出的框架具有启发性和扩展性,对提升语音AI的智能水平和可信度有潜在影响。与音频/语音领域的研究人员高度相关,为如何设计下一代语音理解模型提供了新视角。
- 开源与复现加成:0.5/1 - 论文明确承诺开源代码和数据(在致谢或未来计划部分提及),并提供了超详尽的附录(模型架构、超参数、评估指标计算、提示模板),复现友好性极高。扣0.5分是因为当前版本未提供具体的GitHub仓库链接或预训练模型权重下载地址,开源状态未完全落实。