📄 SongEcho: Towards Cover Song Generation via Instance-Adaptive Element-wise Linear Modulation
#音乐生成 #扩散模型 #数据集 #歌唱语音合成 #可控生成
🔥 8.5/10 | 前25% | #音乐生成 | #扩散模型 | #数据集 #歌唱语音合成
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Sifei Li(中国科学院自动化研究所MAIS、中国科学院大学人工智能学院)
- 通讯作者:Weiming Dong(中国科学院自动化研究所MAIS、中国科学院大学人工智能学院)
- 作者列表:
- Sifei Li(中国科学院自动化研究所MAIS、中国科学院大学人工智能学院)
- Yang Li(中国科学院自动化研究所MAIS、中国科学院大学人工智能学院)
- Zizhou Wang(中国科学院自动化研究所)
- Yuxin Zhang(中国科学院自动化研究所MAIS、中国科学院大学人工智能学院)
- Fuzhang Wu(中国科学院软件研究所ISRC)
- Oliver Deussen(康斯坦茨大学)
- Tong-Yee Lee(成功大学)
- Weiming Dong(中国科学院自动化研究所MAIS、中国科学院大学人工智能学院)
💡 毒舌点评
这篇论文精准地瞄准了“旋律保持”这一翻唱核心需求,并通过改进条件注入机制(IA-EiLM)和构建高质量数据集(Suno70k)给出了一个参数高效、效果显著的解决方案,理论与实验结合得相当扎实。不过,模型依然受限于底层基础模型(ACE-Step)对音色等细粒度控制的不足,且所用的AI生成数据集Suno70k在风格多样性、情感表达深度上可能与真实人类创作的音乐存在“域差距”,这或许会影响模型泛化到更复杂、更具表现力的真实翻唱场景。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/lsfhuihuiff/SongEcho_ICLR2026。
- ���型权重:论文中提到“Code, dataset, and demos are available at…”,但未明确说明是否开源经过训练的完整SongEcho模型权重。基于常见实践,可能开源了新增的IA-EiLM模块和旋律编码器权重。
- 数据集:Suno70k 数据集已公开,链接为 https://huggingface.co/datasets/nyuuzyou/suno。
- Demo:提供在线演示页面:https://vvanonymousvv.github.io/SongEcho_updated/。
- 复现材料:提供了详细的训练细节(第5.1节)、评估协议(第5.2节)、基线复现细节(附录C.1)和超参数设置,复现指导充分。
- 论文中引用的开源项目:
- 骨干模型:ACE-Step (Gong et al., 2025)
- 评估工具:mir_eval (Raffel et al., 2014), stable-audio-metrics, SongEval (Yao et al., 2025)
- 特征提取工具:RVMPE (Wei et al., 2023) 用于音高提取, Qwen2-audio (Chu et al., 2024) 用于标签生成, Whisper (Radford et al., 2023) + All-in-One (Kim & Nam, 2023) 用于歌词转录
- 基线方法:ControlNet (Zhang et al., 2023a), LoRA (Hu et al., 2022), MuseControlLite (Tsai et al., 2025)
- 论文中未提及开源计划:未明确提及开源训练好的完整模型权重和大规模的预训练骨干(ACE-Step)权重(ACE-Step本身可能是开源的)。
📌 核心摘要
- 要解决什么问题:在给定一段人声旋律和文本提示的条件下,生成同时包含新的人声演唱和和谐伴奏的完整歌曲(即翻唱歌曲),这要求模型在保持原旋律轮廓的同时进行风格重新诠释。
- 方法核心是什么:提出SongEcho框架,核心是实例自适应元素级线性调制。它扩展了FiLM为元素级线性调制,以实现对隐藏状态在时序上的精确对齐调制;同时引入实例自适应条件精炼模块,使旋律条件能根据生成模型当前的隐藏状态进行动态调整,而非静态注入。
- 与已有方法相比新在哪里:相比于使用交叉注意力(如MuseControlLite)或元素级相加(如ControlNet)的方法,EiLM提供了更灵活、时序对齐更直接的调制能力。IACR解决了传统条件编码与生成模型内部状态不兼容的问题,使条件融合更和谐。此外,论文开源了一个高质量的、带有丰富标注的AI歌曲数据集Suno70k。
- 主要实验结果如何:在Suno70k测试集上,SongEcho的RPA(0.708)、RCA(0.734) 和CLAP(0.324) 等指标均显著优于基线方法,FD(42.06) 和KL(0.112) 等音质指标也远优于其他方法,且可训练参数量(49.1M)仅为ACE-Step+ControlNet(1.6B)的3.07%。主观听测(MOS)在旋律保真度、文本一致性、音频质量和整体偏好上均获最高分。
- 实际意义是什么:推动了可控、高质量歌曲生成技术的发展,为音乐创作提供了新的AI辅助工具。所构建的开源数据集有助于解决歌曲AI研究中的数据稀缺和版权问题。
- 主要局限性是什么:(1)音色控制能力有限,仅支持基于性别调整,无法进行更细粒度的音色模仿或合成。(2)生成的翻唱是全局风格迁移,未模拟人类音乐家在翻唱时可能进行的局部创造性改编(如颤音、滑音、音符时值变化)。(3)训练依赖于AI生成的音乐数据集,可能存在与真实人类音乐在情感、表达力上的差异。
🏗️ 模型架构
SongEcho整体架构基于一个预训练的文本到歌曲模型(ACE-Step),它是一个线性扩散Transformer(DiT)。核心是在每个Transformer块中插入一个IA-EiLM模块,该模块位于自注意力层之后、前馈网络层之前,用于注入旋律控制信号。
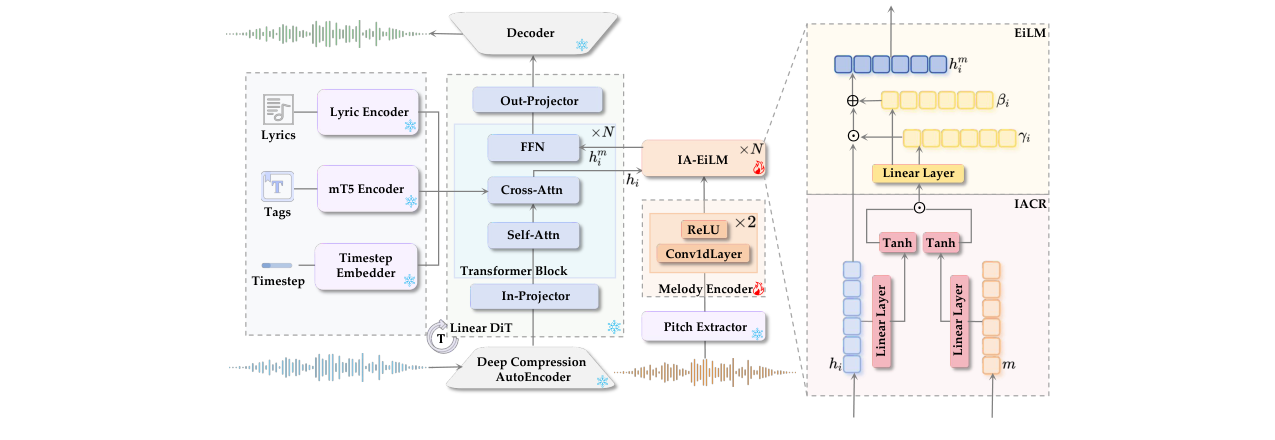
图2:SongEcho整体架构图。展示了以Linear DiT为骨干,通过IA-EiLM模块集成旋律控制信号的流程。
主要组件与流程:
- 输入:人声旋律序列(F0序列,通过RVMPE提取)、歌词、风格标签(Tags)。
- 特征提取:
- 旋律编码器(Melody Encoder):由1D卷积层构成,将F0序列编码为旋律特征
m。 - 歌词编码器(Lyric Encoder):处理歌词文本。
- 标签编码器(mT5 Encoder):处理风格标签。
- 音高提取器(Pitch Extractor):提取F0。
- 旋律编码器(Melody Encoder):由1D卷积层构成,将F0序列编码为旋律特征
- 条件精炼(IACR):
- IACR模块接收旋律特征
m和DiT第i层的隐藏状态hi。 - 通过线性层和tanh激活函数,以及元素级乘法(门控机制),计算出实例自适应的精炼条件
ci。这个过程使旋律条件能根据当前的生成上下文(hi)动态调整,而非固定不变。 - 论文中详细阐述了IACR的必要性(参见第3.2节的推导),指出静态条件在旋律控制任务中会导致优化问题欠定,而IACR通过让条件依赖于
hi解决了这个问题。
- IACR模块接收旋律特征
- 条件注入(EiLM):
- EiLM模块接收精炼后的条件
ci。 - 通过线性映射生成与隐藏状态
hi同维度的调制参数γi和βi。 - 执行仿射变换:
hm_i = (γi + 1) ⊙ hi + βi(采用零初始化策略)。这实现了对隐藏状态在每个时间步、每个特征维度上的精确、独立的调制。
- EiLM模块接收精炼后的条件
- 输出:经过多个Transformer块(每个块都包含IA-EiLM模块)处理后,由DiT解码并经Deep Compression AutoEncoder解码器输出最终的音频波形。
关键设计选择与动机:
- EiLM替代FiLM:标准FiLM对整个特征维度应用相同的缩放和平移,无法实现时序对齐。EiLM为每个时间步生成独立的调制参数,确保了旋律条件能在正确的时间点上生效。
- IACR实现自适应:直接将固定编码的条件注入会破坏模型已学得的内在结构。IACR通过交互学习,使条件信号“适配”模型当前状态,减少了特征冲突,提升了生成质量。
- 模块位置选择:IA-EiLM被置于FFN之前而非Self-Attention之前,是为了防止全局自注意力操作稀释或干扰已注入的局部旋律信息。消融实验(表5)也验证了此设计的优越性。
💡 核心创新点
- 提出IA-EiLM条件注入框架:这是一个由EiLM和IACR组成的端到端框架。EiLM扩展了FiLM,实现了元素级、时序对齐的线性调制,解决了现有交叉注意力方法计算冗余、间接对齐以及元素级相加方法调制灵活性不足的问题。IACR则引入了条件与隐藏状态的自适应交互,克服了传统静态条件编码与生成模型内部状态不匹配的缺陷,这是对条件表示学习的重要改进。
- 构建高质量开源歌曲数据集Suno70k:针对现有歌曲数据集规模小、质量参差不齐、版权受限的问题,论文从AI生成音乐中精心筛选、清洗、增强标注(使用Qwen2-audio生成标签),构建了一个约7万首、3000小时的高质量AI歌曲数据集,有效缓解了研究数据匮乏的问题。
- 参数高效的翻唱生成方案:在强大的预训练文本到歌曲模型(ACE-Step)基础上,仅需训练新增的IA-EiLM模块和旋律编码器,即可实现精确的旋律控制,可训练参数量不到基线方法的30%,体现了高效的迁移学习能力。
🔬 细节详述
- 训练数据:主要使用自建的Suno70k数据集,包含69,379首训练歌曲,来源于Suno.ai生成的AI音乐。经过多阶段处理:基于元数据过滤(去除不完整、非英语、超长样本)、使用SongEval进行质量评估(剔除低分样本)、使用Qwen2-audio生成增强标签(流派、人声类型、乐器、情绪,每首歌最多20个标签)。总时长约3000小时。
- 损失函数:使用标准的扩散模型训练目标(LFM),即预测噪声与真实噪声的均方误差,公式见论文公式(13)。未使用基于自监督学习模型的语义对齐损失。
- 训练策略:
- 优化器:AdamW (β1=0.9, β2=0.95, weight decay=0.01)。
- 学习率:1e-4,线性预热(warm-up)1000步。
- 批次大小:12(使用3张NVIDIA A100 GPU,每张GPU batch size=1,梯度累积步数=4)。
- 训练步数:30,000步。
- 关键超参数:
- 生成时长:最大240秒(与ACE-Step一致)。
- 旋律特征维度M:未明确说明,但由旋律编码器E的输出决定。
- 条件注入模块初始化:EiLM的线性层
fi初始化为零,确保训练从原始模型开始(类似ControlNet的zero-conv初始化)。
- 训练硬件:3张NVIDIA A100 GPU。
- 推理细节:使用ACE-Step原有的Classifier-Free Guidance (CFG) 采样器,引导尺度λ=15.0。论文附录表6对比了不同引导策略,确认原始CFG效果最佳。
- 正则化或稳定训练技巧:采用了零初始化策略(公式11),防止随机初始化参数在训练初期对隐藏状态造成噪声调制,提升训练稳定性。
📊 实验结果
论文在Suno70k和SongEval两个测试集上与基线方法进行了全面对比。主要基线为在相同ACE-Step骨干上实现的SA ControlNet(及其LoRA变体)和MuseControlLite。
主要对比结果(Suno70k测试集)
| 模型 | RPA↑ | RCA↑ | OA↑ | CLAP↑ | FD↓ | KL↓ | PER↓ | TP↓ |
|---|---|---|---|---|---|---|---|---|
| ACE-Step (原始模型) | - | - | - | 0.2930 | 73.53 | 0.2670 | 0.4168 | - |
| ACE-Step+SA ControlNet | 0.6209 | 0.6440 | 0.6858 | 0.2875 | 105.95 | 0.2019 | 0.3714 | 1.6B |
| ACE-Step+SA ControlNet+LoRA | 0.6214 | 0.6431 | 0.6833 | 0.2892 | 99.19 | 0.1850 | 0.3734 | 331M |
| ACE-Step+MuseControlLite | 0.5205 | 0.5346 | 0.5940 | 0.2977 | 72.04 | 0.2151 | 0.4194 | 189M |
| SongEcho (Ours) | 0.7080 | 0.7339 | 0.6952 | 0.3243 | 42.06 | 0.1123 | 0.2951 | 49.1M |
表1:在Suno70k测试集上的定量评估结果。SongEcho在旋律控制指标(RPA, RCA, OA)、分布匹配指标(FD, KL)、音频质量指标(PER)和文本-音频对齐指标(CLAP)上均显著领先,且可训练参数最少。
标签交换实验(验证控制能力解耦):随机交换测试集文本标签后(表2),SongEcho的旋律指标基本不变,CLAP分数略有下降(0.2674),说明旋律控制与文本控制基本解耦,且旋律本身隐含风格信息。
SongEval测试集结果(表3):在另一个更广泛的AI歌曲评估基准上,SongEcho同样全面超越基线。
主观评估(表4):在旋律保真度(MF)、文本一致性(TA)、音频质量(AQ)和整体偏好(OP)四个维度,无论是音乐背景听众还是非音乐背景听众,SongEcho均获得最高分。
消融实验(表5):
- 组件有效性:用元素级相加替换EiLM(w/ EA)且移除IACR,性能下降;加入EiLM(w/ EiLM, w/o IACR)后旋律指标提升;最终加入IACR后,所有指标(尤其是FD, KL等音质指标)大幅提升,证明了两个模块的协同效果。
- 模块位置:将IA-EiLM插入到Self-Attention层之前(IA-EiLM→Self-Attn)比插入到FFN之前性能下降,验证了设计选择。
- 数据效率:仅用100个样本训练效果较差,但1000个样本就能达到接近全量数据的效果,展示了方法的数据高效性。
图5:MuseControlLite在完整音频条件下的注意力图可视化,呈现清晰的对角线模式,说明其本质接近直接复制条件音频,而非灵活生成。
⚖️ 评分理由
- 学术质量:6.2/7:创新点明确(IA-EiLM框架),技术分析深入(对静态条件欠定问题的论证),方法设计合理且经过充分消融验证。实验全面,包括客观指标、主观听测、消融研究和多数据集验证,证据链完整可信。主要扣分点在于任务本身(翻唱生成)相对经典音乐生成任务(如文本到音乐)在通用性和影响力上可能稍弱,且方法高度依赖一个强大的预训练骨干模型。
- 选题价值:1.5/2:选题新颖且实用,抓住了音乐创作中的一个重要需求。提出的方法和构建的开源数据集对社区有实际贡献。潜在应用空间包括音乐教育、创作辅助、娱乐应用等。与音频/音乐研究人员的相关性高。扣分点在于任务偏向垂直应用,且面临音乐版权等现实挑战。
- 开源与复现加成:0.8/1:开源信息极为充分:提供了代码GitHub仓库链接、数据集Suno70k的获取方式(HuggingFace)、在线Demo页面。论文详细描述了训练设置、模型配置、评估协议,复现门槛较低。主要扣分点是未明确提及是否开源预训练的骨干模型(ACE-Step)权重(论文中模型ACE-Step为公开模型,但SongEcho自身仅开源微调后的IA-EiLM模块)。