📄 SNAP-UQ: Self-supervised Next-Activation Prediction for Single-Pass Uncertainty in TinyML
#音频分类 #自监督学习 #低资源 #模型评估
✅ 7.5/10 | 前25% | #音频分类 | #自监督学习 | #低资源 #模型评估
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Ismail Lamaakal(Mohammed First University, Multidisciplinary Faculty of Nador)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:
- Ismail Lamaakal*(Mohammed First University, Multidisciplinary Faculty of Nador)
- Chaymae Yahyati*(Mohammed First University, Multidisciplinary Faculty of Nador)
- Khalid El Makkaoui(Mohammed First University, Multidisciplinary Faculty of Nador)
- Ibrahim Ouahbi(Mohammed First University, Multidisciplinary Faculty of Nador)
- Yassine Maleh(Sultan Moulay Slimane University, Laboratory LaSTI) (*表示共同第一作者)
💡 毒舌点评
论文的亮点在于将“不确定性”这个通常需要复杂计算的概念,巧妙地转化为对网络内部“可预测性”的衡量,并以此构建了一个极度轻量、无需额外状态、完美适配MCU的单次推理方案,实用性极强。但其短板是“自监督”的标签略有牵强,更像是为不确定性估计任务设计的辅助回归损失;此外,论文对tap位置选择、rank大小等关键设计选择的敏感性分析不够深入,给实际部署时的调优留下了“黑箱”。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:https://github.com/Ism-ail11/SNAP-UQ。
- 模型权重:未提及是否公开预训练模型权重。
- 数据集:使用的是公开数据集(MNIST, CIFAR-10, TinyImageNet, SpeechCommands v2),论文未提及公开自定义数据集。
- Demo:未提及。
- 复现材料:提供了非常充分的复现材料。包括:完整的算法伪代码(Algorithm 1 & 2);附录中详细说明了数据集预处理(A)、训练/校准/构建细节(B)、基线调优(C)、腐蚀/OOD协议(D)和评估指标(F)。论文中列出了所有关键超参数及其选择范围。提供了代码仓库链接。
- 引用的开源项目:论文依赖TensorFlow Lite Micro、CMSIS-NN等TinyML工具链,并引用了多个基线方法的开源实现(如Temperature Scaling, Mahalanobis)。
📌 核心摘要
- 问题:在资源极端受限的微控制器(MCU)上部署的TinyML模型,缺乏轻量、实时的在线不确定性估计能力,难以检测数据分布偏移、模型错误或性能下降,影响了边缘设备的鲁棒性和可靠性。
- 方法核心:提出SNAP-UQ,一种基于“自监督下一层激活预测”的单次前向传播不确定性估计方法。在主干网络的少数几层(“tap点”)附加小型预测头,用低维投影预测下一层激活的统计量(均值和方差),通过实际激活与预测值之间的“惊讶度”(标准化预测误差)来量化网络内部动态的异常程度,多个tap点的惊讶度聚合后经轻量单调映射得到最终不确定性分数。
- 创新点:与依赖多次前向传播(如MC Dropout)、集成模型或依赖输出层置信度的方法不同,SNAP-UQ完全基于单次前向传播中网络内部层的动态变化构建不确定性信号,无需状态缓冲、额外分支或架构修改,且所有运算为整数友好型(int8量化),增量部署开销仅几十KB Flash和<2%额外计算。
- 主要实验结果:
- 可部署性:在Big-MCU和Small-MCU上,SNAP-UQ相比基线EE-ens和DEEP,Flash占用减少37%-57%,延迟降低24%-35%,能耗降低约20-30%,并在CIFAR-10任务的Small-MCU上,基线因内存溢出无法运行而SNAP-UQ仍可部署(见表1)。
- 监控与检测:在损坏数据流上,SNAP-UQ的精度下降检测AUPRC(如MNIST-C上0.66)优于所有基线(见表2),且随腐蚀严重度增加提升最快(见图2)。在故障检测(ID✓— ID×, ID✓— OOD)任务上,SNAP-UQ在多个数据集上取得最高或并列最高的AUROC(如SpeechCommands上ID✓— ID×为0.94,见表3)。
- 校准:在分布内(ID)数据上,SNAP-UQ的NLL、Brier Score和ECE相比基线BASE和温度缩放均有改善(见表4)。
- 实际意义:为TinyML生态系统提供了一种即插即用的在线监控工具,可在不增加显著资源开销的前提下,提升部署在MCU上的AI应用的可信度和安全性,适用于传感器漂移、环境变化等现实场景。
- 主要局限性:方法依赖于能访问和附加在主干网络的中间层激活上;使用对角/低秩协方差可能无法完全建模复杂的跨通道相关性;性能对tap点位置和投影器秩的选择有一定敏感性。
🏗️ 模型架构
SNAP-UQ的核心是为一个已固定的深度-D主干网络附加一个轻量级、无状态的不确定性估计模块。其整体流程如下:
输入:原始数据x。 主干网络:一个深度为D的神经网络(如DS-CNN, ResNet-8, MobileNetV2),将其映射为一系列中间激活 {aℓ} (ℓ=0..D),其中a0=x。分类器g输出类别后验概率pφ(y|x)。 不确定性估计模块(SNAP-UQ):
- 选择Tap点:从主干网络中选择一个包含2-3个层索引的小集合S(通常选一个网络中部层和倒数第二层)。
- 投影与预测:对于每个tap点ℓ∈S: a. 投影器Pℓ:将前一层的激活aℓ₋₁通过一个1×1卷积(对卷积网络)或线性层(对MLP)投影到一个低维空间,得到zℓ = Pℓ aℓ₋₁ ∈ R^{rℓ}(rℓ « dim(aℓ₋₁))。这步旨在提取对预测下一层激活有用的摘要信息。 b. 预测头gℓ:一个微小的int8线性层,以zℓ为输入,输出两个向量:下一层激活的预测均值μℓ和预测对数方差log σ²ℓ。
- 计算每层惊讶度: a. 在主干网络前向传播过程中获得实际激活aℓ。 b. 计算标准化残差:uℓ(x) = (aℓ - μℓ) ⊙ σ⁻¹ℓ。 c. 计算标准化平方误差(即能量项):q̄ℓ(x) = (1/dℓ) ||uℓ(x)||²₂。
- 聚合与映射: a. 将各tap点的惊讶度加权求和得到总体惊讶度:S(x) = Σ_{ℓ∈S} wℓ q̄ℓ(x)。 b. 可选地,与来自分类器输出的即时置信度代理信号m(x)(如1-最大概率、1-概率差)结合。 c. 通过一个离线拟合的、轻量级的单调映射(如3参数logistic或保序回归)将(S, m)映射为一个校准的不确定性分数U(x) ∈ [0, 1]。
输出:分类预测ŷ 和 可靠性评分U(x)。根据U(x)是否超过阈值τ,系统可以决定是输出预测还是拒绝(abstain)。
关键设计选择与动机:
- 深度方向预测而非输出置信度:动机是网络内部动态对分布偏移的敏感性往往早于softmax置信度变得不可靠之前。
- 无状态单次前向传播:完全为MCU设计,避免多次前向传播(高延迟)、状态缓冲(高内存)和额外退出分支(改变主干)。
- int8与LUT:确保所有算术在MCU上高效、可预测地执行,避免浮点运算。
- 对角协方差:简化计算,闭式评分,且通过归一化实现对缩放的不变性。
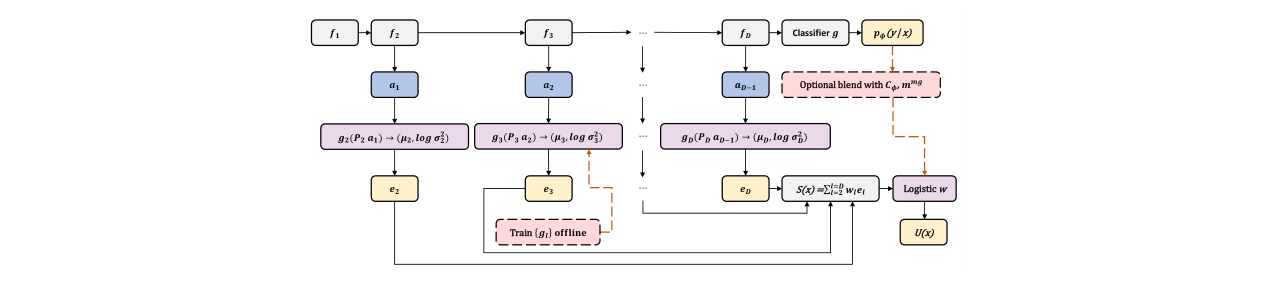
图1(来自第4页):SNAP-UQ流程图。此图清晰展示了方法的完整架构:主干网络 f₁…f_D 产生激活 a₁…a_D。在选定的层(a₁, a₂, a_{D-1})进行“tap”,每个tap使用投影器 Pℓ 和预测头 gℓ 输出统计量 (μℓ, log σ²ℓ)。计算每层惊讶度 eℓ,并聚合为 S(x)=Σwℓ eℓ。最后通过可选地与分类器置信度 (Cφ, mmg) 混合,经逻辑斯蒂映射得到最终不确定性 U(x)。虚线框内的训练步骤(offline训练gℓ)在推理时是不执行的。
💡 核心创新点
- 单次前向传播、无状态的不确定性估计:完全摒弃了MC Dropout、深度集成等需要多次前向传播的方法,也摒弃了早期退出等需要额外网络分支的方法。SNAP-UQ在一次标准前向传播中,利用网络固有的中间激活计算不确定性分数,推理开销极低,且不引入任何需要维护的状态(如缓冲区),完美契合MCU的内存和延迟约束。
- 基于网络内部动态(深度方向预测)的不确定性度量:创新性地将不确定性定义为网络层到层转换的“可预测性”。通过训练微型预测头来建模“给定aℓ₋₁,预测aℓ”的条件分布,然后用实际aℓ与预测分布的“惊讶度”(负对数似然)作为不确定性信号。这种方法比仅依赖最终softmax输出更早、更根本地捕捉到数据分布的变化。
- 为MCU极致优化的整数友好型实现:所有新增组件(投影器、预测头)均采用int8量化;避免在设备上计算指数运算,通过查表(LUT)近似exp(-0.5 log σ²);使用对角协方差和归一化确保计算稳定且对缩放不变。这些设计使得不确定性计算的增量Flash和MAC开销极小(仅几十KB,<2%)。
- 轻量级且无侵入性的集成方式:SNAP-UQ作为一个独立模块附加到已有主干网络上,不需要修改主干网络的架构或训练过程(除了共同训练新增的头)。这使其可以作为一种“插件”部署到现有的TinyML模型中,提高了实用性。
- 理论联系与不变性保证:论文提供了理论分析,证明了在假设条件下,深度方向惊讶度S(x)等价于条件负对数似然(似然解释),并与条件马氏距离相关(与无条件马氏距离方法对比),并且对仿射变换(如批归一化后的缩放)具有不变性。
🔬 细节详述
- 训练数据:
- 视觉:MNIST(60k/10k),CIFAR-10(50k/10k),TinyImageNet(100k训练,10k验证)。使用标准数据增强(随机旋转、平移、裁剪、翻转、颜色抖动等)。
- 音频:SpeechCommands v2(12类关键词)。从1秒音频提取40维Log-Mel特征,使用SpecAugment、随机时移、背景噪声混合等增强。
- 所有数据集划分出10%训练集作为开发集(dev split),用于调参、校准和阈值选择,测试集保持独立。
- 损失函数:
- 主任务损失:Lclf(交叉熵损失,带标签平滑等)。
- SNAP-UQ辅助损失(LSS):对于每个minibatch和每个tap点ℓ,计算负对数似然 nllℓ = ½Σ_i [ (aℓ,i - μℓ,i)²/σ²ℓ,i + log σ²ℓ,i ],再经维度归一化(除以dℓ)和加权求和(权重ωℓ)。
- 正则化损失(R):惩罚对数方差的L1范数和预测头权重的L2范数,防止方差极端化和过拟合。
- 总损失:L = Lclf + λ_SSLSS + λ_regR。λ_SS ∈ {1e-3, 5e-3, 1e-2}。
- 训练策略:
- MNIST:Adam优化器,lr=1e-3余弦衰减,batch size 256,50 epochs。
- CIFAR-10:SGD(动量0.9),lr=0.2余弦衰减,batch size 128,200 epochs,使用标签平滑和MixUp(仅Big-MCU)。
- TinyImageNet:SGD(动量0.9),lr=0.15余弦衰减,batch size 128,220 epochs。
- SpeechCommands:AdamW,lr=2e-3余弦衰减,batch size 256,80 epochs。
- 关键超参数:
- Tap点数量|S|:通常2或3个。
- 投影器秩rℓ:从{32, 64, 128, 160}中选择,取决于MCU预算。
- 辅助损失权重λ_SS:在验证集上从{1e-3, 5e-3, 1e-2}中选择。
- 方差参数化:σ² = softplus(ξ) + ε²,ε=1e-4,log σ² 被钳制到[log 1e-4, log 100]。
- 训练硬件:论文未提供具体GPU型号和训练时长信息。
- 推理细节:
- 使用单一前向传播,计算S(x)和U(x)。
- 可选与分类器置信度代理m(x)结合。
- 阈值τ在开发集上选定(如最大化F1分数或匹配目标覆盖率),然后固定。
- 整数运算:投影器和预测头权重存储为int8(含缩放因子),使用int32累加器。使用256项LUT近似exp(-0.5 log σ²)。
- 正则化与稳定技巧:方差下界软plus参数化、权重衰减、维度归一化防止宽层主导损失、可选梯度阻断(stopgrad)稳定小数据集训练。
📊 实验结果
论文评估了四个维度:MCU部署、流式监控、故障检测和ID校准。
表1:MCU可部署性对比
| 任务/平台 | 方法 | Flash (KB) ↓ | Peak RAM (KB) ↓ | Latency (ms) ↓ | Energy (mJ) ↓ |
|---|---|---|---|---|---|
| SpeechCmd / Big-MCU | BASE | 220 | 84 | 60 | 2.1 |
| EE-ens | 360 | 132 | 85 | 3.0 | |
| DEEP | 290 | 108 | 70 | 2.5 | |
| SNAP-UQ | 182 | 70 | 52 | 1.7 | |
| CIFAR-10 / Big-MCU | BASE | 280 | 128 | 95 | 3.7 |
| EE-ens | 540 | 190 | 110 | 4.1 | |
| DEEP | 680 | 176 | 125 | 4.6 | |
| SNAP-UQ | 292 | 120 | 83 | 3.3 | |
| SpeechCmd / Small-MCU | BASE | 140 | 60 | 170 | 6.0 |
| EE-ens | 320 | 104 | 240 | 8.6 | |
| DEEP | 210 | 86 | 200 | 7.3 | |
| SNAP-UQ | 118 | 51 | 113 | 4.7 | |
| CIFAR-10 / Small-MCU | BASE | 180 | 92 | 260 | 9.5 |
| EE-ens | OOM | OOM | OOM | OOM | |
| DEEP | OOM | OOM | OOM | OOM | |
| SNAP-UQ | 158 | 85 | 178 | 6.4 |
结论:SNAP-UQ在所有MCU场景下均显著降低了Flash、内存占用和延迟能耗。在Small-MCU的CIFAR-10任务中,集成基线因内存溢出(OOM)无法部署,而SNAP-UQ仍可运行。
表2:损坏流上的准确率下降检测(AUPRC↑,延迟↓)
| 数据集 | 方法 | AUPRC | 延迟(帧) |
|---|---|---|---|
| MNIST-C | BASE | 0.54 | 42 |
| EE-ens | 0.63 | 31 | |
| DEEP | 0.56 | 35 | |
| SNAP-UQ | 0.66 | 24 | |
| SpeechCmd-C | BASE | 0.52 | 67 |
| EE-ens | 0.59 | 55 | |
| DEEP | 0.58 | 57 | |
| SNAP-UQ | 0.65 | 41 |
结论:SNAP-UQ在检测分布偏移事件(准确率下降)上取得了最高的AUPRC和最短的检测延迟。
图2(来自第3页):不同腐蚀严重度下CIFAR-10-C的AUPRC对比图。横轴为腐蚀严重度(1-5),纵轴为AUPRC。图中显示,随着腐蚀严重度增加,SNAP-UQ(蓝色实线)的AUPRC提升速度最快,在高严重度下明显优于EE-ens(橙色虚线)和DEEP(绿色虚线)基线,表明其对严重分布偏移的敏感性更强。
表3:故障检测AUROC(越高越好)
| 方法 | ID✓— ID× | ID✓— OOD | ||||
|---|---|---|---|---|---|---|
| MNIST | SpCmd | CIFAR-10 | MNIST | SpCmd | CIFAR-10 | |
| BASE | 0.75 | 0.90 | 0.84 | 0.07 | 0.90 | 0.88 |
| MCD | 0.74 | 0.89 | 0.87 | 0.48 | 0.89 | 0.89 |
| DEEP | 0.85 | 0.91 | 0.86 | 0.78 | 0.91 | 0.92 |
| EE-ensemble | 0.85 | 0.90 | 0.85 | 0.85 | 0.90 | 0.90 |
| G-ODIN | 0.72 | 0.74 | 0.83 | 0.40 | 0.74 | 0.95 |
| HYDRA | 0.81 | 0.90 | 0.83 | 0.71 | 0.90 | 0.90 |
| QUTE | 0.87 | 0.91 | 0.86 | 0.84 | 0.91 | 0.91 |
| SNAP-UQ | 0.90 | 0.94 | 0.87 | 0.86 | 0.92 | 0.94 |
结论:SNAP-UQ在区分正确/错误预测(ID✓— ID×)和区分分布内/分布外样本(ID✓— OOD)任务上,在MNIST和SpeechCommands数据集上均取得了最优的AUROC,在CIFAR-10上也极具竞争力。
表4:ID校准(越低越好)
| 数据集 | 方法 | NLL ↓ | BS ↓ | ECE ↓ |
|---|---|---|---|---|
| MNIST | BASE | 0.285 | 0.012 | 0.028 |
| Temp. scaled | 0.242 | 0.010 | 0.022 | |
| SNAP-UQ | 0.202 | 0.008 | 0.016 | |
| SpeechCmd | BASE | 0.306 | 0.012 | 0.024 |
| Temp. scaled | 0.228 | 0.009 | 0.021 | |
| SNAP-UQ | 0.197 | 0.008 | 0.016 | |
| CIFAR-10 | BASE | 0.415 | 0.021 | 0.031 |
| DEEP | 0.365 | 0.017 | 0.015 | |
| SNAP-UQ+ | 0.363 | 0.017 | 0.021 |
结论:在MNIST和SpeechCommands上,SNAP-UQ在负对数似然(NLL)、布里尔分数(BS)和预期校准误差(ECE)上均优于基线。在CIFAR-10上,增强版的SNAP-UQ+(使用更大秩和低秩协方差校正)与强大的DEEP基线表现相当,但仅需单次前向传播。
⚖️ 评分理由
- 学术质量:5.5/7。创新性:提出了一种新颖的基于内部动态的不确定性度量范式,针对特定约束(TinyML)做了精心设计。技术正确性:方法理论有支撑,实现细节(量化、正则化)周全。实验充分性:评估全面,覆盖多个任务、平台和基线。证据可信度:实验在固定协议下进行,提供了置信区间。扣分点在于部分核心思想(如用辅助任务预测特征)并非首创,且对关键设计选择(如tap点)的消融研究可以更深入。
- 选题价值:1.5/2。问题重要:TinyML的可靠性是当前边缘AI落地的热点和难点。前沿性:将不确定性估计推向资源受限设备。实际应用:有明确的落地场景和价值。与读者相关性:高,论文直接评估了音频关键词检测任务。
- 开源与复现加成:0.5/1。代码已开源。论文提供了极其详细的复现信息(附录A-C),包括数据集处理、训练超参数、构建细节、基线调优网格等,足以复现核心实验。但未提供预训练权重或一键复现的脚本,因此给予+0.5分。