📄 SmartDJ: Declarative Audio Editing with Audio Language Model
#音频编辑 #音频大模型 #扩散模型 #空间音频
🔥 8.5/10 | 前25% | #音频编辑 | #音频大模型 | #扩散模型 #空间音频
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zitong Lan(宾夕法尼亚大学WAVES实验室)
- 通讯作者:未明确说明(论文未指定通讯作者)
- 作者列表:Zitong Lan(宾夕法尼亚大学WAVES实验室)、Yiduo Hao(宾夕法尼亚大学WAVES实验室)、Mingmin Zhao(宾夕法尼亚大学WAVES实验室)
💡 毒舌点评
亮点:本文最大的亮点在于提出了“声明式”音频编辑的范式,并通过一个设计精巧的“ALM规划器+LDM编辑器”框架实现了它,同时配套构建了首个可扩展的声明式音频编辑数据集合成管道,形成了一个完整的技术闭环。 短板:实验完全依赖于合成数据集,虽然合成过程逼真,但真实世界中的复杂声场、噪声和语义歧义可能对ALM的推理和LDM的执行构成远超合成环境的挑战,其泛化能力在论文中未得到真实场景验证。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。但承诺在论文接受后发布代码。
- 模型权重:未提及是否公开预训练的ALM和LDM权重。但论文承诺发布预训练模型。
- 数据集:论文中未提及公开合成数据集的具体获取方式。但承诺发布合成数据集。
- Demo:未提及提供在线演示。
- 复现材料:提供了极其详细的实现细节,包括模型架构(层数、维度、参数量)、训练配置(学习率、批大小、优化器、训练步数/轮数)、数据合成流程(提示词模板、声学模拟参数),以及消融实验设置。附录非常完整。
- 论文中引用的开源项目:CLAP(用于音频编码)、FLAN-T5(用于文本编码)、Stable-Audio-Open(作为部分基线)、PyRoomAcoustics(用于声学模拟)、AudioSep(作为对比模型)、GPT-4o(用于数据合成)。
📌 核心摘要
- 要解决什么问题:现有音频编辑模型依赖于模板化指令(如“添加鸟鸣”),需要用户指定具体操作,无法理解用户高级的、声明式的意图(如“让这个声音听起来像在阳光明媚的森林里”)。同时,现有系统普遍局限于单声道音频,无法编辑空间信息。
- 方法核心是什么:提出SmartDJ框架。它包含两个核心组件:(1) 音频语言模型(ALM)作为规划器,接收原始音频和用户的高级声明式指令,输出一个原子编辑步骤序列(如“移除雨声”、“在左边添加鸟鸣”);(2) 潜在扩散模型(LDM)作为编辑器,按照ALM规划的步骤顺序,逐步执行编辑操作,最终生成目标立体声音频。
- 与已有方法相比新在哪里:首次实现了“声明式”音频编辑范式,将用户意图理解与音频信号操作分离。首次将音频语言模型的推理能力系统性地引入音频编辑流程。首次构建了支持立体声、包含声明式指令-原子操作-音频轨迹的配对数据集生成管道。首次系统评估了编辑操作对空间音频特性的影响。
- 主要实验结果如何:在声明式编辑任务和多种单步原子操作上,SmartDJ在各项客观指标(FD, FAD, LSD等)和主观用户偏好率上均显著优于端到端训练的Audit模型以及多种零样本基线(SDEdit, ZETA等)。例如,在声明式编辑任务中,SmartDJ的FAD得分为1.52,远优于最佳基线Audit的5.67;用户研究显示,在音频质量和与指令的对齐度上,SmartDJ的胜率在80%-95.5%之间(详见表1)。
框架 方法 训练 速度 FD↓ FAD↓ KL↓ LSD↓ CLAP↑ 无ALM Audit 是 2.07s 28.56 10.00 3.07 1.93 0.11 有ALM SDEdit 否 301s (74.6s) 19.66 3.71 3.25 2.22 0.17 Audit 是 11.6s (2.07s) 21.50 5.67 2.80 1.49 0.18 SmartDJ (ours) 是 13.1s (2.40s) 10.60 1.52 2.84 1.40 0.21 - 实际意义是什么:该工作为下一代智能、直观的音频编辑工具铺平了道路,有望革新VR/AR、游戏、影视制作等领域的音频后处理工作流,提升创作效率和沉浸感。
- 主要局限性是什么:整个框架的训练和评估完全依赖于合成数据集,其在真实、复杂、非结构化声场中的性能未被验证。ALM生成步骤的推理时间(约4.8秒)和多步编辑的累积时间(13.1秒)相比端到端方法仍有优化空间。框架对新增编辑操作类型的扩展需要重新训练。
🏗️ 模型架构
SmartDJ的框架由两个独立训练的核心模块组成:音频语言模型(ALM)规划器和潜在扩散模型(LDM)编辑器。其整体数据流与交互如图1和图2所示。

图1(原论文Figure 1):展示了SmartDJ的整体工作流程。左侧是原始立体声音频(包含猫叫、下雨声),用户输入声明式指令“让这段音频听起来像阳光明媚的森林”。顶部的ALM规划器分析音频和指令后,输出一系列原子编辑步骤(如“移除下雨声”、“添加树叶沙沙声”)。底部的LDM编辑器根据这些步骤,逐步对音频进行编辑,最终输出目标音频。
- 输入:原始音频波形
a₀和声明式指令P(自然语言)。 - ALM 规划器:
- 音频编码:使用预训练的CLAP模型将
a₀编码为音频嵌入向量zₐ。CLAP能够理解音频的语义内容。 - 指令编码:将指令
P进行分词和嵌入,得到文本嵌入序列。 - 序列生成:ALM的核心是一个大型语言模型(LLM),本研究基于AF2(一个音频语言模型),其内部使用Qwen2.5-3B作为LLM骨干。LLM以自回归方式,在音频嵌入
zₐ和指令嵌入的条件下,生成原子编辑步骤S = {s₁, s₂, ..., sₙ}的文本序列。训练时,使用LoRA对LLM的部分层进行高效微调。 - 输出:结构化的原子编辑步骤序列(自然语言文本)。
- 音频编码:使用预训练的CLAP模型将
- LDM 编辑器:
- 音频VAE:采用基于1D-CNN的连续VAE,将双通道立体声音频压缩为潜在表示
â,实现7.5倍的压缩。 - 编辑执行:对于ALM生成的每一个步骤
sᵢ,LDM执行一次条件扩散生成过程。它以前一步的音频潜在表示âᵢ₋₁和一个随机噪声潜在表示â'ᵢ的拼接作为输入,通过Diffusion Transformer(DiT)架构,在文本步骤sᵢ(由FLAN-T5编码)的交叉注意力条件下,去噪生成新的潜在表示âᵢ。 - 训练:LDM通过去噪损失
L_LDM进行训练,学习在给定编辑指令和当前音频状态下,预测添加的噪声。推理时使用DDIM采样和分类器自由引导(CFG)。 - 输出:经过编辑后的立体声音频潜在表示,最终解码为波形
aₙ。
- 音频VAE:采用基于1D-CNN的连续VAE,将双通道立体声音频压缩为潜在表示
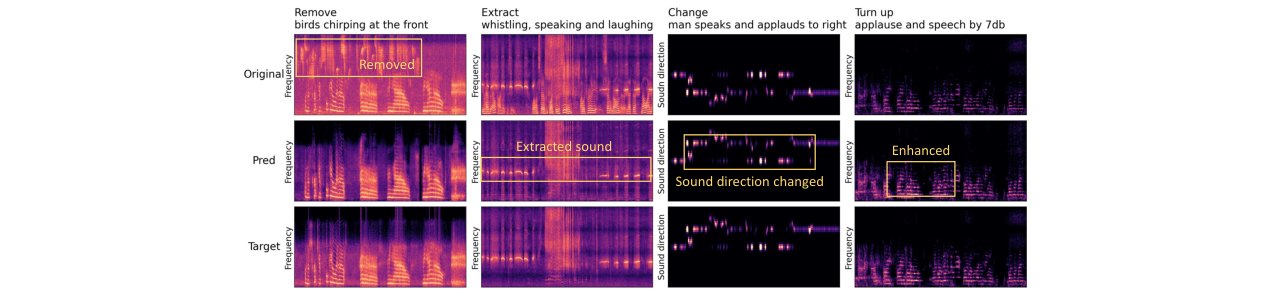
图3(原论文Figure 3):详细展示了ALM和LDM的内部架构。上方ALM部分:原始音频经CLAP编码为特征,与指令嵌入一同输入带有LoRA的LLM,自回归生成编辑步骤文本。下方LDM部分:展示了基于DiT的扩散模型如何以前一步音频潜在表示和噪声潜在表示作为输入,经文本条件(步骤描述)引导,通过多步去噪生成编辑后的潜在表示。图中还用红色和蓝色区分了可训练参数和冻结参数。
关键设计选择:
- 分离训练:ALM和LDM独立训练,使得用户可以在中间步骤检查并修改ALM生成的自然语言编辑计划,增强了可交互性和可控性。这也便于模块化替换和迭代。
- 原子操作设计:定义了包括添加、移除、提取、音量调整、改变方向、时间偏移、添加混响、调整音色在内的8种基本操作,覆盖了常见的音频编辑需求。
- 条件扩散:LDM以文本描述的编辑操作为条件,使其能精确执行每一步操作,而非一次性生成目标音频。
💡 核心创新点
声明式音频编辑范式:
- 是什么:用户只需用自然语言描述期望的音频场景(如“让它听起来像在图书馆”),系统自动分解并执行具体编辑操作。
- 局限:之前的音频编辑系统要么需要用户指定具体操作步骤(过程式),要么只能处理简单的模板指令。
- 如何起作用:通过引入ALM作为“规划器”,利用其多模态理解与推理能力,将高级语义指令映射到可执行的原子操作序列。
- 收益:极大提升了编辑的直观性和效率,降低了使用门槛,是音频编辑交互方式的重大革新。
ALM-LDM 分离式编辑框架:
- 是什么:将“理解-规划”与“执行-生成”解耦,由ALM负责前者,由专门训练的扩散模型负责后者。
- 局限:端到端模型试图一步到位,往往在复杂语义理解或精细操作控制上有所欠缺;纯LLM方案缺乏音频生成与编辑能力。
- 如何起作用:ALM输出的自然语言步骤作为LDM的明确指令,LDM则专注于在保持未编辑内容不变的前提下,高质量地执行每一步操作。
- 收益:兼具了LLM的强大推理能力和扩散模型的高质量生成能力。分离式设计提高了系统的可解释性、可交互性(可人工干预编辑步骤)和模块化程度。
可扩展的声明式音频编辑数据合成管道:
- 是什么:设计了一个“设计师-作曲家”管道来生成大规模训练数据。LLM作为“设计师”生成指令和操作,基于信号处理的“作曲家”渲染对应的音频。
- 局限:缺乏此类配对数据是制约该领域发展的主要障碍。
- 如何起作用:从公共数据集采样带标签的单事件音频,混合成场景。LLM(GPT-4o)根据这些标签生成声明式指令和分解的原子步骤。信号处理器根据步骤逐步调整音源参数(音量、方向等)并重新混合,生成每一步操作前后的音频对。
- 收益:提供了首个大规模、可控的声明式音频编辑数据集(240K训练对,1M单步操作数据),解决了监督学习的关键数据瓶颈。
🔬 细节详述
训练数据:
- 来源:合并自AudioCaps, VGGSound, FSD50k, ESC50, WavCaps等公共数据集。
- 预处理:将音频统一为10秒、24kHz采样率。使用GPT-4o-mini将描述转换为离散标签,仅保留单标签音频。使用CLAP模型过滤音频与标签相似度低于0.3的样本。
- 规模:通过合成管道生成240K对声明式编辑数据(指令+步骤+音频轨迹)用于训练ALM和评估。生成1M对单步操作数据(步骤、原始音频、编辑后音频)用于训练LDM。评估使用2K声明式数据对和3K单步操作数据对。
- 数据增强:合成过程本身通过随机采样音源、随机分配音量/方向、使用PyRoomAcoustics模拟不同房间混响(RT60在0.3s-1.2s)来引入多样性。
损失函数:
- ALM:标准的自回归语言建模损失
L_ALM,即最小化预测下一个token与真实token的交叉熵。 - LDM:去噪扩散模型的均方误差损失
L_LDM,目标是预测添加到潜在表示上的高斯噪声ε。
- ALM:标准的自回归语言建模损失
训练策略:
- ALM:初始化自AF2。冻结CLAP编码器和LLM主体。仅全量微调适配器层(音频表示转换层)并使用LoRA(秩=16)微调LLM的交叉注意力层。优化器:AdamW,学习率:1e-5。训练20个epoch,batch size 24。
- LDM:使用单步编辑数据训练。采用50K线性预热,余弦学习率衰减。优化器:AdamW,学习率:5e-5。训练50万迭代,batch size 256。使用速度预测和CFG重缩放技巧。10%的文本替换为空字符串以建模无条件生成。
关键超参数:
- ALM:基于AF2,包含3B参数的LLM(Qwen2.5-3B)。
- LDM(DiT):24个Transformer块,通道维度1024,16个注意力头,FFN维度4096,总参数量597M。
- VAE:潜在维度C=128,压缩比7.5x。
- 推理:LDM使用100步DDIM采样,引导尺度(CFG scale)为4,引导重缩放因子为0.8。
训练硬件:4块NVIDIA L40S GPU。
推理细节:ALM以自回归方式生成编辑步骤(平均耗时约4.8秒)。LDM对每个步骤进行独立推理(单步耗时约2.4秒)。总编辑时间约13.1秒。
正则化/稳定技巧:ALM训练中冻结大部分参数仅微调LoRA和适配器,防止过拟合和灾难性遗忘。LDM训练中使用CFG和速度预测提升生成稳定性。
📊 实验结果
论文在声明式指令编辑和单步原子操作两大类任务上进行了全面评估。
- 声明式指令音频编辑任务(整体流程评估)
- 基线方法:End-to-End Audit(无ALM);使用ALM输出步骤的多个零样本方法(SDEdit, DDIM Inversion, ZETA, AudioEditor)和有训练的方法(Audit with ALM)。
- 指标:FD, FAD, KL, LSD(与参考音频的差异,越低越好),CLAP(与指令的语义相似度,越高越好)。
- 关键结果(表1):
框架 方法 训练 速度 FD ↓ FAD ↓ KL↓ LSD↓ CLAP↑ 无ALM Audit ✓ 2.07s 28.56 10.00 3.07 1.93 0.11 有ALM SDEdit ✗ 301s (74.6s) 19.66 3.71 3.25 2.22 0.17 Audit ✓ 11.6s (2.07s) 21.50 5.67 2.80 1.49 0.18 SmartDJ (ours) ✓ 13.1s (2.40s) 10.60 1.52 2.84 1.40 0.21 - 结论:SmartDJ在FAD、FD、LSD等质量指标上显著优于所有基线,并且CLAP分数最高,表明其生成的音频与用户指令的语义对齐最好。虽然推理速度慢于端到端Audit,但质量提升巨大。
- 单步音频编辑操作评估
- 基线方法:SDEdit, DDIM Inversion, ZETA, AudioEditor, Audit。
- 关键结果(表2):展示了SmartDJ在Add(添加)、Remove/Extract(移除/提取)、Volume(音量调整)、Time(时间偏移)、Reverb(混响)、Timbre(音色调整)、Change Sound Direction(改变声源方向)等所有操作上,均显著优于基线,特别是在空间相关指标(GCC, CRW, FSAD)上优势明显。例如,在“改变声源方向”任务上,SmartDJ的GCC MSE为26.02,远低于次优基线ZETA的67.29。

图7(原论文Figure 7):展示了用户研究结果。在“声明式编辑质量”和“复杂编辑对齐度”上,SmartDJ对ZETA、AE、Audit的胜率分别为80%、95.52%、90.41%和87%、91.04%、93.15%。在单步任务上也表现出类似的优势。这证实了SmartDJ在实际听感上更受用户青睐。

图8(原论文Figure 8):展示了“往返编辑”实验结果。对音频进行5轮“添加声音A”和“移除声音A”的操作后,SmartDJ的输出与原始音频的LSD始终最低且最稳定,表明其在多轮编辑中能最好地保持未修改的内容,漂移最小。
- 消融实验
- ALM有效性:移除ALM,将框架改为端到端LDM,性能显著下降(FAD从1.53升至3.14)。证明ALM的中间推理至关重要。
- ALM选择:将ALM骨干从AF2换成LTU,性能略有下降但仍然合理,表明框架具有一定的通用性。
- 编辑顺序:比较“添加->修改->移除”、“随机顺序”和“移除->修改->添加”三种顺序,性能差异很小,说明ALM生成的步骤很少包含冲突操作。
- 与音频分离模型对比:在Extract操作上,SmartDJ与专用音频分离模型AudioSep性能相当(FD: 25.7 vs 27.1),展示了其在通用编辑框架下的竞争力。
⚖️ 评分理由
- 学术质量:6.5/7 - 论文提出了清晰且具有创新性的“声明式编辑”问题,并设计了一个逻辑严密、架构完整的两阶段解决方案。实验设计极为全面,从整体任务到细分操作,从客观指标到主观研究,并进行了深入的消融分析,充分支撑了其结论。主要扣分点在于对合成数据集的强依赖,这可能影响其在现实复杂场景中的鲁棒性。
- 选题价值:2.0/2 - 选题非常前沿且具有明确的应用价值。将LLM的推理能力引入音频编辑是一个重要的范式创新,有望催生新一代的智能音频创作工具,对相关产业有潜在变革性影响。
- 开源与复现加成:0.5/1 - 论文承诺开源,且附录提供了极其详尽的复现细节(模型参数、超参、数据处理流程),这是巨大加分。但当前未提供实际链接,且核心数据集为合成,因此加成有限。