📄 Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
#多模态模型 #在线处理 #记忆机制 #任务规划 #基准测试
✅ 7.5/10 | 前25% | #多模态模型 | #强化学习 | #在线处理 #记忆机制
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Lin Long (Zhejiang University, Bytedance Seed)
- 通讯作者:Yuan Lin (Bytedance Seed)
- 作者列表:Lin Long (Zhejiang University, Bytedance Seed)、Yichen He (Bytedance Seed)、Wentao Ye (Zhejiang University)、Yiyuan Pan (Robotics Institute, Carnegie Mellon University)、Yuan Lin (Bytedance Seed)、Hang Li (Bytedance Seed)、Junbo Zhao (Zhejiang University)、Wei Li (Bytedance Seed)
💡 毒舌点评
本文最大的亮点在于构建了一个“类人记忆”的闭环系统,并发布了极具针对性的评测集M3-Bench,直指当前智能体长期记忆能力评估的空白。但其记忆系统的动态更新与冲突解决机制(如权重投票)描述过于简略,实际大规模部署时的鲁棒性与效率存疑。
🔗 开源详情
- 代码:论文承诺开源代码,包括记忆化与控制流程、工具实现、演示数据合成流程等,代码仓库链接为
https://github.com/ByteDance-Seed/m3-agent。 - 模型权重:论文承诺公开记忆化模型(
memory-7b-sft)和控制模型(control-32b-rl)的检查点。 - 数据集:论文承诺公开完整的M3-Bench数据集(含所有机器人视角和网络视频、问答标注及评估脚本)。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详细的训练超参数(如DAPO参数见附录表14)、训练数据规模、评估脚本(使用GPT-4o自动评估器),以及在附录中提供了大量提示模板和实现细节,复现信息充分。
- 论文中引用的开源项目:InsightFace(人脸识别)、ERes2NetV2(说话人验证模型)、OpenAI text-embedding-3-large(文本嵌入)、Qwen2.5-Omni、Qwen3等。
📌 核心摘要
- 解决的问题:现有大型多模态智能体缺乏类似人类的、可持续积累和检索的长期记忆能力,难以在复杂、动态的真实环境中进行深度理解与推理。
- 方法核心:提出M3-Agent框架,包含“记忆化”和“控制”两个并行过程。记忆化过程持续处理音视频流,生成并更新实体中心(Entity-centric)的情景记忆和语义记忆,构建长期记忆图。控制过程则通过强化学习训练的策略模型,进行多轮推理并自主检索相关记忆以完成指令任务。
- 与已有方法相比新在哪里:不同于传统针对有限时长视频的离线理解方法,M3-Agent设计为在线处理无限长流;不同于标准检索增强生成(RAG)的单轮检索,其控制策略通过强化学习实现多轮迭代推理与记忆访问;其记忆结构以实体为中心,整合多模态信息(人脸、语音、文本),以维持跨时间的一致性和深度。
- 主要实验结果:在全新的M3-Bench(含100个机器人视角视频和920个网络视频)及VideoMME-long上,M3-Agent均取得最优。与最强基线(Gemini-1.5-pro + GPT-4o提示智能体)相比,M3-Agent在M3-Bench-robot、M3-Bench-web和VideoMME-long上分别提升了6.7%、7.7%和5.3%的准确率。消融实验证实了长期记忆(尤其是语义记忆)、强化学习训练和多轮推理的重要性。
| 方法 | M3-Bench-robot (All) | M3-Bench-web (All) | VideoMME-Long |
|---|---|---|---|
| Gemini-GPT4o-Hybrid (最强基线) | 24.0 | 41.2 | 56.5 |
| M3-Agent (本文) | 30.7 | 48.9 | 61.8 |
图7:M3-Bench与其他长视频问答基准(LVQA)的对比,展示了其在是否包含智能体、跨模态QA、人物理解QA和知识QA等维度上的独特性。
- 实际意义:为构建能持续感知、学习并推理的具身智能体提供了可落地的框架,并建立了评估此类智能体关键能力的标准。
- 主要局限性:记忆的增量更新与权重投票机制细节有待完善;视觉记忆的效率(如视频帧采样与特征提取)可能成为瓶颈;实验主要集中在问答任务,对连续任务执行的验证不足。
🏗️ 模型架构
M3-Agent的架构由核心多模态大语言模型(MLLM)和外部实体中心多模态长期记忆数据库组成,并驱动两个并行工作流:记忆化(Memorization)与控制(Control)。
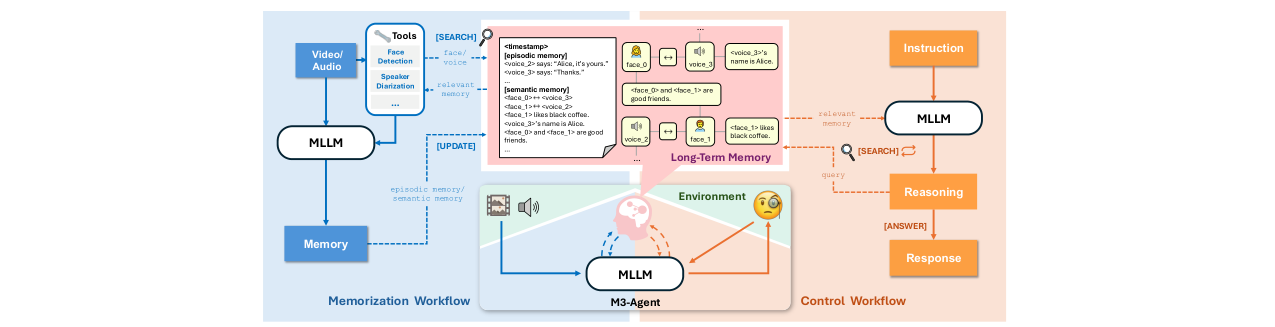
图1:M3-Agent整体架构示意图。展示了感知环境(视频/音频)后,记忆化过程(左侧)如何通过工具提取人脸、语音身份,并生成情景与语义记忆更新长期记忆图。控制过程(右侧)如何接收指令,并利用MLLM进行多轮推理,通过搜索工具检索相关记忆来生成最终回答。
- 长期记忆数据库
- 结构:一个实体中心的多模态图结构数据库。每个节点代表一个记忆项,包含ID、模态类型(文本/图像/音频)、原始内容、可靠性权重、向量嵌入及时间戳等元数据。节点通过无向边连接,表示逻辑关系(如属于同一实体)。这种结构支持基于时间戳的顺序检索和基于实体的关联检索。
- 更新机制:记忆化过程生成的新记忆项,若已存在则被“再激活”并增加其权重,否则创建新节点/边。推理时采用基于权重的投票机制解决冲突,权重高的条目优先。
- 检索工具:提供
search node(多模态查询,返回最相关的k个节点)和search clip(返回与查询最相关的记忆片段)两种工具。基于最大内积搜索(MIPS)实现,并设有相似性阈值(如文本t=0.5,人脸t=0.3)。
- 记忆化过程 (Memorization)
- 输入:实时视频流(分片处理,通常30秒一片)。
- 处理流程:
- 身份提取:使用工具(如InsightFace进行人脸识别,Gemini-1.5-Pro+ERes2NetV2进行说话人识别)从每一片中提取人脸和语音,通过聚类得到全局一致的
<face id>和<voice id>。 - 记忆生成:以提取的身份为锚点,使用多模态大模型(初始化为Qwen2.5-Omni)生成两类记忆:
- 情景记忆:记录具体的事件(如“
<face_0>对<voice_3>说:‘这是你的’”)。 - 语义记忆:提炼通用知识,包括身份等价关系(如“
<voice_3>对应<face_1>”)、人物属性、人际关系和从事件中抽取的常识。
- 情景记忆:记录具体的事件(如“
- 记忆更新:生成的记忆项被存储或激活于长期记忆图中,建立跨模态身份关联。
- 身份提取:使用工具(如InsightFace进行人脸识别,Gemini-1.5-Pro+ERes2NetV2进行说话人识别)从每一片中提取人脸和语音,通过聚类得到全局一致的
- 控制过程 (Control)
- 输入:用户指令(问题)和长期记忆。
- 处理流程(遵循Algorithm 1):这是一个由强化学习策略模型
πθ(初始化为Qwen3-32b)驱动的多轮交互循环:- 策略模型根据当前上下文(初始指令)生成响应,包含推理、动作(
[Search]或[Answer])和参数。 - 若动作为
[Search],则用参数作为查询,在长期记忆数据库中执行检索,将结果追加到上下文中,进入下一轮。 - 若动作为
[Answer],则输出内容并终止。 - 循环最多进行H轮(本文设为5轮)。
- 策略模型根据当前上下文(初始指令)生成响应,包含推理、动作(
- 关键设计:通过多轮迭代检索和推理,实现更精准、聚焦的记忆访问,超越了传统RAG的单次检索注入。
- 训练方法 记忆化模型和控制模型分开训练。记忆化模型通过监督微调(SFT)在合成的演示数据集上学习生成高质量记忆。控制模型则通过DAPO(一种强化学习算法) 在长期记忆环境中进行训练,奖励函数基于GPT-4o自动评估器对答案正确性的判断。
💡 核心创新点
- 类人双过程架构:提出了清晰分离的“记忆化”(持续感知与记忆构建)和“控制”(基于记忆推理与行动)两个过程,模拟了人类认知系统的核心环节。
- 实体中心的多模态长期记忆:创新性地将长期记忆组织为以实体(人物)为中心的图结构,通过跨模态(视觉人脸、听觉语音、文本)的强关联,解决了长期上下文中身份与属性的不一致问题。
- 基于强化学习的迭代推理与检索:将控制过程的检索-推理循环建模为序列决策问题,使用强化学习(DAPO)进行端到端优化,使智能体能进行多轮、自主的、任务导向的记忆检索,而非预定义的单次检索。
- 针对性的评测基准M3-Bench:填补了评估多模态智能体长期记忆与推理能力的空白,设计了涵盖人物理解、跨模态推理等高级认知能力的问题类型,并包含了真实的机器人视角数据。
🔬 细节详述
- 训练数据:
- 记忆化模型(memory-7b-sft):基于内部授权的视频集构建。首先将视频分割为30秒片段。使用混合策略合成演示数据:情景记忆由GPT-4o(视觉细节)和Gemini-1.5-Pro(事件摘要)联合生成;身份等价关系通过元片段(meta-clip)提取算法自动标注(准确率95.83%);其他语义记忆同样由GPT-4o和Gemini-1.5-Pro生成。共合成了10,952个训练样本和200个验证样本。
- 控制模型(control-32b-rl):环境由memory-7b-sft生成。训练QA数据集包含500个长视频(26,943个30秒片段)和2,736个问答对。
- 损失函数:
- 记忆化模型:标准交叉熵损失(监督微调)。
- 控制模型:DAPO损失(公式2)。这是一个基于近端策略优化(PPO)的RL损失,只在LLM生成的token上计算。奖励
R_i是二值的(GPT-4o评估答案正确为1,否则为0)。
- 训练策略:
- 记忆化:使用16张80GB GPU,训练3个epoch,学习率1e-5,批大小16。
- 控制:使用DAPO算法。从提示调优过的Qwen3-32b (
control-32b-prompt)初始化。每个问题生成G条轨迹进行策略更新。优化器参数(如clip范围epsilon_low,epsilon_high)见附录表14。
- 关键超参数:控制过程的最大推理轮数
H=5。记忆检索工具search clip在评估时返回最相关的2个片段。 - 训练硬件:记忆化训练使用16 GPU (80GB),控制训练硬件未明确说明,但训练了8B、14B、32B不同规模的模型。
- 推理细节:控制模型采用多轮自回归生成,直到输出
[Answer]动作。温度等采样参数未在正文中说明。 - 正则化/稳定训练技巧:未在正文中具体说明。
📊 实验结果
论文在M3-Bench-robot, M3-Bench-web和VideoMME-long三个基准上进行了全面评估。
主要对比实验结果(表4):
| 方法 | M3-Bench-robot | M3-Bench-web | Video-MME-Long | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ME | MH | CM | PU | GK | All | ME | MH | CM | PU | GK | All | ||
| Socratic Model | |||||||||||||
| GPT-4o | 9.3 | 9.0 | 8.4 | 10.2 | 7.3 | 8.5 | 21.3 | 21.9 | 30.9 | 27.1 | 39.6 | 28.7 | 38.8 |
| Online Video Understanding | |||||||||||||
| MA-LMM | 25.6 | 23.4 | 22.7 | 39.1 | 14.4 | 24.4 | 26.8 | 10.5 | 22.4 | 39.3 | 15.8 | 24.3 | 17.3 |
| Agent Method | |||||||||||||
| Gemini-GPT4o-Hybrid | 21.3 | 25.5 | 22.7 | 28.8 | 23.1 | 24.0 | 35.9 | 26.2 | 37.6 | 43.8 | 52.2 | 41.2 | 56.5 |
| M3-Agent | 32.8 | 29.4 | 31.2 | 43.3 | 19.1 | 30.7 | 45.9 | 28.4 | 44.3 | 59.3 | 53.9 | 48.9 | 61.8 |
| 表4:主要实验结果。M3-Agent在所有基准的总分上均显著优于所有基线。在人物理解(PU)和跨模态推理(CM)上优势尤为明显。 |
消融实验结果:
图5:消融实验结果示意图。该图直观展示了不同消融设置对模型性能的影响。
- 记忆化模型消融(表5):
- 将记忆模型替换为提示调优的Gemini(
memory-gemini-prompt)在M3-Bench-web上准确率下降2.6%,表明SFT记忆更优。 - 移除身份等价关系(
w/o equivalence)和语义记忆(w/o semantic memory)导致性能大幅下降(如在M3-Bench-robot上分别下降11.2%和17.1%),证明了实体关联和语义记忆的关键作用。
- 将记忆模型替换为提示调优的Gemini(
- 控制模型消融(表6):
- RL训练的模型(
control-32b-rl)显著优于提示调优的模型(control-32b-prompt),在M3-Bench-robot上提升10.0%。 - DAPO算法优于GRPO算法。
- 模型规模扩大带来性能提升(8b→14b→32b)。
- 去除“轮间指令”(即每轮检索后注入记忆并重新提示)或“推理”步骤都导致性能显著下降,验证了多轮迭代机制的必要性。
- RL训练的模型(
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一个完整且新颖的框架,将长期记忆、多模态处理、强化学习和智能体架构有机结合。实验设计充分,覆盖了自建基准和公开基准,并进行了细致的消融研究,证据链较完整。扣分点在于:记忆图的具体动态更新算法(如权重如何精确计算与衰减)描述不够深入;视觉特征提取(人脸识别、聚类)的细节和效率讨论稍显不足。
- 选题价值:1.5/2:长期记忆是构建真正自主智能体的核心挑战,本研究方向极具前沿性和应用潜力。论文提出的实体中心记忆结构切中当前多模态理解一致性保持的痛点。与音频/语音读者的关联性在于,其跨模态记忆融合了语音身份信息。
- 开源与复现加成:1.0/1:论文明确承诺将开源M3-Bench数据集、记忆化与控制模型权重、训练数据以及完整的代码库,这将极大促进该领域的后续研究和复现。