📄 Scaling Speech Tokenizers with Diffusion Autoencoders
#语音识别 #语音合成 #扩散模型 #流匹配 #语音大模型
🔥 8.5/10 | 前25% | #语音识别 | #扩散模型 | #语音合成 #流匹配
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yuancheng Wang (Meta超级智能实验室、香港中文大学(深圳))
- 通讯作者:未明确说明(论文中注明“*Work done during an internship at Meta”,但未指明通讯作者)
- 作者列表:Yuancheng Wang(Meta超级智能实验室、香港中文大学(深圳)),Zhenyu Tang(Meta超级智能实验室),Yun Wang(Meta超级智能实验室),Arthur Hinsvark(Meta超级智能实验室),Yingru Liu(Meta超级智能实验室),Yinghao Aaron Li(Meta超级智能实验室),Kainan Peng(Meta超级智能实验室),Junyi Ao(Meta超级智能实验室、香港中文大学(深圳)),Mingbo Ma(Meta超级智能实验室),Mike Seltzer(Meta超级智能实验室),Qing He(Meta超级智能实验室),Xubo Liu(Meta超级智能实验室)
💡 毒舌点评
亮点:论文抓住了语音标记化器“既要压缩效率,又要重建质量,还要语义丰富”的“不可能三角”,用一个统一的扩散自编码器框架给出了一个极具竞争力的解,并在12.5Hz的极低帧率下将多项指标推向了新高度。短板:尽管提出了shortcut fine-tuning等解码加速方案,但扩散模型固有的多步采样本质仍是其在实时流式应用中的阿喀琉斯之踵,论文对此的解决方案(如轻量扩散头)效果有待更严苛场景的验证。
🔗 开源详情
- 代码:论文未提及具体代码仓库链接,但在附录D提供了详细的伪代码,并承诺在发表后发布。
- 模型权重:承诺在发表后发布预训练模型检查点(在公开研究数据集上)。
- 数据集:使用200万小时内部数据,未提及公开。
- Demo:提供了演示样例的链接 https://sitok-demo.github.io/。
- 复现材料:提供了非常详细的模型架构(附录A)、训练循环伪代码(附录D.2)、超参数(附录D.3)和评估协议。
- 依赖的开源项目:论文提到了依赖的开源项目或工具,如Llama Transformer架构、Vocos声码器、Whisper-large-v3用于评估。
📌 核心摘要
本文针对语音标记化器在低比特率下面临的语义编码、声学重建与压缩效率难以兼顾的核心问题,提出了Speech Diffusion Tokenizer (SiTok)。其核心是将向量量化与扩散自编码器进行端到端联合优化,使离散编码既能高度压缩,又与生成式解码器的分布显式对齐。与先前两阶段或仅依赖重建损失的方法相比,SiTok创新性地引入了CTC语义正则化,直接对量化后的潜在空间施加文本监督,迫使离散token保留丰富的语言结构。实验表明,在极端的12.5 Hz token率和200 bits/s比特率下,SiTok在语音重建(如WER 3.34, SIM 0.682)和下游理解任务(如ASR WER 4.95)上均显著优于强基线。此外,通过快捷微调技术,解码步骤可缩减至2-4步而几乎不损质量。该工作为构建统一的语音语言模型提供了一个高效且全面的接口,但其在流式生成和多语言支持上的潜力有待进一步挖掘。
🏗️ 模型架构
SiTok的整体架构是一个基于扩散自编码器的语音标记化器,其完整流程如下图所示。
- 输入:50 Hz, 128-bin的梅尔频谱图(通过堆叠连续4帧降至12.5 Hz)。
- 编码器 (Encoder):由16层因果Llama Transformer块组成,将下采样后的梅尔频谱图映射为连续潜在特征序列
z。 - 向量量化 (VQ):将连续特征
z映射到离散码本,产生离散索引序列q。默认配置为32维,65,536个条目,使用EMA更新。 - 扩散解码器 (DiT Decoder):核心创新组件。将离散索引
q反查回码本嵌入zq作为条件。该解码器为一个非因果的16层Transformer,通过替换RMSNorm为Adaptive RMSNorm来引入扩散时间步t。它学习预测一个速度场vϕ(xt, t, zq),用于将加噪样本xt = tx + (1-t)ε(ε为噪声)去噪回原始数据x,采用流匹配 (Flow Matching) 目标进行训练。 - CTC语义解码器 (CTC Decoder):一个4层因果Llama Transformer,接收量化后的嵌入
zq,预测文本token概率,通过CTC损失提供直接的语义监督。 - 输出重建:解码器重建的梅尔频谱图通过外部的Vocos声码器转换为24kHz的波形。
关键设计与数据流:
- 联合优化:与传统两阶段方法不同,SiTok的编码器、VQ和扩散解码器在同一个扩散损失和CTC损失下端到端训练,确保离散编码同时为重建和语义任务优化。
- 损失函数:总损失
L_total = L_rec + λ_ctc * L_ctc + L_vq,其中L_rec为流匹配的回归损失,L_ctc为CTC损失,L_vq为VQ承诺损失。
💡 核心创新点
- 基于扩散自编码器的联合训练框架:将向量量化与扩散模型解码器整合在一个端到端框架内。之前方法要么使用回归损失(L1/L2),要么采用两阶段训练。SiTok利用扩散模型显式建模低比特率量化引入的不确定性,在极低帧率下实现了更高质量的重建,实验证明扩散目标显著优于回归目标(表5)。
- 针对量化空间的CTC语义正则化:直接对量化后的离散token表征施加CTC损失监督。与先前依赖自监督特征对齐或额外语义编码器的方法不同,SiTok从原始语音直接学习并强制离散编码保留语言内容,这是其在极低比特率下仍保持强大理解和生成能力的关键。
- 高效的解码加速策略:引入快捷微调 (Shortcut Fine-tuning) 技术,使扩散解码器能够学习在极少步骤(如2或4步)内完成高质量去噪。同时探索了轻量扩散头设计,将解码器拆分为主干(只运行一次)和轻量头(迭代运行),大幅降低单步计算成本。
🔬 细节详述
- 训练数据:使用200万小时内部语音数据,以英语为主,包含原始语句长度及文本转录,未做切分预处理。
- 损失函数:
- 扩散重建损失 (L_rec):流匹配目标,预测速度场
vϕ与真实速度(x - ε)之间的L1距离。 - CTC语义损失 (L_ctc):连接时序分类损失,用于监督CTC解码器从
zq预测文本y。权重λ_ctc至关重要,最佳值为0.1(表5)。 - VQ损失 (L_vq):承诺损失。
- 扩散重建损失 (L_rec):流匹配目标,预测速度场
- 训练策略:
- 优化器:AdamW (β1=0.9, β2=0.999),权重衰减0.01。
- 学习率:8e-5,32k步warmup。
- 训练时长:约45万步(单epoch)。
- Batch策略:动态batch size,每个GPU上打包至总语音时长约300秒(对应约3750个token)。
- 关键超参数:默认模型为“L”配置:编码器16层,解码器16层,隐藏维度1536,中间层4096,16个注意力头。VQ:32维,65,536条目。
- 推理细节:默认16步扩散解码。通过快捷微调后,可降至4-8步,实时因子 (RTF) 从0.041(16步)降至0.013(4步)。使用token Classifier-Free Guidance (CFG) 可进一步提升质量。
- 正则化/稳定训练:使用EMA更新码本;在训练中随机丢弃所有输入token(概率10%)以支持CFG。
📊 实验结果
论文在重建、理解和生成任务上进行了全面评估。关键结果如下表所示。
表1:语音重建任务主要结果
| 模型 | FPS/TPS | CN | BR (kbps) | WER (↓) | SIM (↑) | UTMOS (↑) |
|---|---|---|---|---|---|---|
| Ground Truth | - | - | - | 2.14 | 0.730 | 3.53 |
| SiTok (CN=1) | 12.5/12.5 | 1 | 0.20 | 4.06 | 0.641 | 3.44 |
| + Decoder Finetuning | 12.5/12.5 | 1 | 0.20 | 3.79 | 0.682 | 3.48 |
| + Token CFG | 12.5/12.5 | 1 | 0.20 | 3.34 | 0.635 | 3.60 |
| SiTok (CN=4) | 12.5/50 | 4 | 0.70 | 2.80 | 0.660 | 3.46 |
- 结论:SiTok在0.2 kbps的极端比特率下仍具竞争力。解码器微调大幅提升说话人相似度,Token CFG显著降低WER。
表2:下游理解任务主要结果
| 模型 | FPS/TPS | CN/CS | BR (kbps) | CTC ASR (↓) | ASR (↓) | ER (↑) | SV (↓) | KS (↑) |
|---|---|---|---|---|---|---|---|---|
| Mimi | 12.5/100 | 8/2048 | 1.1 | - | 23.1 | 54.3 | 19.7 | 92.2 |
| GLM4-Voice | 12.5/12.5 | 1/16384 | 0.20 | - | 16.3 | - | - | - |
| SiTok (CN=1) | 12.5/12.5 | 1/65536 | 0.20 | 9.50 | 4.95 | 63.5 | 13.8 | 96.9 |
| SiTok (CN=4) | 12.5/50 | 4/16384 | 0.70 | 8.30 | 4.49 | 64.4 | 8.59 | 97.7 |
- 结论:SiTok在ASR、情感识别、说话人验证和关键词检测等所有任务上均超越现有方法,且在最低比特率下实现。
表5:消融实验(部分关键结果)
| 配置 | WER (↓) | SIM (↑) | ASR (↓) | 说明 |
|---|---|---|---|---|
| 扩散损失 (D) | 4.06 | 0.641 | 4.95 | 基线 |
| 回归损失 (R) | 4.66 | 0.587 | 6.06 | 扩散显著优于回归 |
| 无CTC (W.=0) | 33.0 | 0.495 | 29.4 | 无语义监督,性能崩溃 |
| CTC W.=0.1 | 4.06 | 0.641 | 4.95 | 最佳平衡点 |
| 1个码本 (CN=1) | 4.30 | 0.641 | 5.27 | 基线 |
| 4个码本 (CN=4) | 2.80 | 0.660 | 4.49 | 增加码本数,重建和理解均提升 |
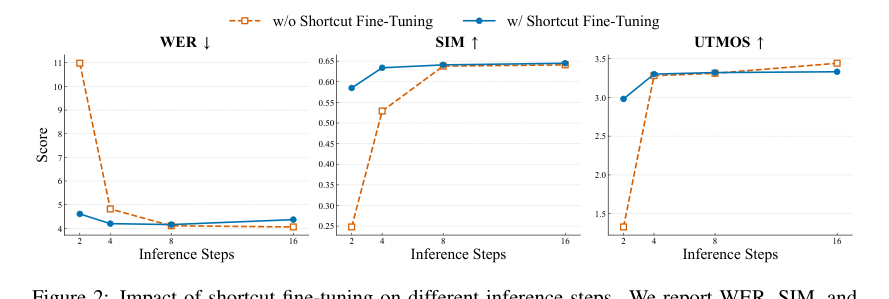
图2:快捷微调对不同解码步数的影响 图2:快捷微调前后,在不同解码步数下的WER、SIM和UTMOS得分对比]
- 结论:快捷微调在低步数(如2、4、8步)下显著提升WER和SIM,证明其能有效维持解码质量。
⚖️ 评分理由
- 学术质量:6.5/7。论文提出了解决语音标记化器核心矛盾的有效框架,创新点明确(联合扩散、CTC正则化)。技术实现正确,消融实验详尽,对比了多种基线(SpeechTokenizer, BigCodec, DualCodec等),结果可信。
- 选题价值:1.5/2。语音标记化是语音语言模型的关键基础,论文聚焦于低比特率这一具有挑战性和实用性的设置,对推动语音大模型发展有重要价值。
- 开源与复现加成:0.5/1。论文提供了详尽的架构、训练细节和伪代码(附录D),并承诺发布代码和模型,可复现性高。但未提及代码仓库、数据集(使用内部数据)和在线Demo的具体链接。