📄 RoboOmni: Proactive Robot Manipulation in Omni-modal Context
#机器人操作 #多模态模型 #端到端 #数据集 #语音对话系统
✅ 7.5/10 | 前25% | #机器人操作 | #端到端 | #多模态模型 #数据集
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Siyin Wang(复旦大学、上海创新研究院)
- 通讯作者:Jinlan Fu(未说明具体机构,对应邮箱jinlanjonna@gmail.com),Xipeng Qiu(复旦大学、上海创新研究院)
- 作者列表:
- Siyin Wang(复旦大学、上海创新研究院)
- Jinlan Fu(国家大学新加坡)
- Feihong Liu(复旦大学)
- Xinzhe He(复旦大学)
- Huangxuan Wu(复旦大学)
- Junhao Shi(复旦大学、上海创新研究院)
- Kexin Huang(复旦大学)
- Zhaoye Fei(复旦大学)
- Jingjing Gong(上海创新研究院)
- Zuxuan Wu(复旦大学、上海创新研究院)
- Yu-Gang Jiang(复旦大学)
- See-Kiong Ng(国家大学新加坡)
- Tat-Seng Chua(国家大学新加坡)
- Xipeng Qiu(复旦大学、上海创新研究院)
💡 毒舌点评
这篇论文的亮点在于其极具前瞻性的选题——让机器人从多模态对话和环境音中“听出”意图并主动询问,而非被动接受指令,这比单纯提升操作成功率更有意义。然而,其真实世界评估仅在单一机器人平台(WidowX 250S)上进行,且失败分析显示执行错误(如抓取失败)占比过半,凸显了当前端到端模型在感知推理与底层控制能力之间的巨大鸿沟,离“家庭管家”的理想距离尚远。
🔗 开源详情
- 代码:论文提供了GitHub仓库链接:
https://github.com/OpenMOSS/RoboOmni,表明计划开源。 - 模型权重:论文中提到“make all our datasets and code publicly available”,暗示模型权重也可能开源,但未明确说明具体开源哪些检查点。
- 数据集:明确将开源OmniAction数据集和OmniAction-LIBERO基准。
- Demo:论文中未提及在线演示。
- 复现材料:论文在第5.1节详细说明了训练细节(硬件、批大小、学习率、训练时长等),并在附录中提供了数据构建、基线模型、失败分析等补充信息,复现信息较为充分。
- 论文中引用的开源项目:论文依赖或对比了多个开源项目,包括OpenVLA, π0, NORA, LIBERO, Open-X Embodiment, Whisper, Qwen2.5-Omni, DINOv2, SigLIP, PaliGemma, FAST+分词器等。
📌 核心摘要
- 问题:现有VLA模型主要依赖明确的文字或语音指令,但真实人机交互中,用户意图往往隐含在对话、语气、环境音等多模态上下文中,机器人需要具备主动推理和确认的能力。
- 方法核心:提出RoboOmni框架,采用Perceiver-Thinker-Talker-Executor四模块端到端架构,直接处理原始音频(语音+环境音)和视觉输入,通过统一的token空间联合建模,实现意图识别、语音交互和动作生成。
- 创新之处:1)定义了“跨模态上下文指令”新范式;2)设计了端到端的多模态感知-推理-交互-执行框架,避免了级联系统的信息损失;3)构建了首个大规模、多说话人、多声音事件的机器人操作数据集OmniAction(140k episodes)。
- 实验结果:在OmniAction-LIBERO-TTS模拟基准上,RoboOmni平均成功率85.6%,大幅超越最强基线NORA(25.9%)。在真实人类语音指令(OmniAction-LIBERO-Real)上,成功率76.6%,优于π0(73.8%)。消融实验显示,移除音频、视觉或副语言线索会显著降低意图识别准确率(从88.89%降至11.11%-58.89%)。
- 实际意义:推动了更自然、主动的人机协作机器人发展,其方法和数据集对多模态具身智能研究有重要价值。
- 主要局限:真实世界评估场景和机器人平台单一;执行层面的失败率(如抓取、定位)仍较高,表明底层控制能力是瓶颈;生成对话和动作的长期连贯性与复杂性有待进一步验证。
🏗️ 模型架构
RoboOmni是一个端到端的多模态大语言模型框架,其整体架构如图4所示。其设计旨在将感知、推理、交互和执行统一在一个自回归生成模型中。

图4:RoboOmni的Perceiver-Thinker-Talker-Executor架构概览。模型接收视觉、音频和文本对话历史,通过统一的token空间进行处理,最终输出语音交互和机器人动作。
具体组件如下:
- Perceiver(感知器):负责多模态输入编码。它包含针对视觉和音频的专用编码器(如使用Qwen2.5-Omni的编码器)。在每一时间步,接收视觉帧、音频片段和对话历史,分别编码为视觉隐层表示、音频隐层表示和文本token,然后将它们拼接成一个统一的表示
Xt = [vt; st; ct],作为后续Thinker的输入。 - Thinker(思考器):核心推理引擎,基于大语言模型骨干网络。它处理来自Perceiver的统一多模态表示,并在联合词汇空间
V ∪ A(V为文本词汇表,A为动作token集合)中自回归地生成输出序列。该序列可以交错包含文本token、语音表示和动作token,从而实现跨模态的统一推理。 - Talker(对话器):语音生成组件。它接收Thinker生成的高层语义表示和文本token,通过分层架构将其转换为自然的语音波形,用于与人进行语音交互。
- Executor(执行器):动作生成组件。它利用FAST+分词器将连续的机器人动作向量
at ∈ R^7(如7自由度控制)编码为离散的动作token序列rt ⊂ A。在生成时,Thinker自回归地预测动作token序列,然后由Executor将这些token解码回可执行的机器人命令。
数据流与交互方式:所有模态的输入首先被编码并统一到token空间,Thinker作为中央处理器进行联合推理,并决定是生成对话文本(通过Talker转为语音)还是生成动作序列(由Executor解码为控制指令)。这种设计实现了从原始感知到认知再到行动的闭环。
💡 核心创新点
- 提出“跨模态上下文指令”新问题:明确指出当前VLA模型在指令类型(仅显式)和来源(仅文本/ASR转写)上的局限,定义了需要从语音、环境音和视觉的融合中推理隐式意图的新任务。这比现有研究更贴近真实世界交互。
- 端到端的Omni-modal VLA框架(RoboOmni):不同于级联的“感知-规划-控制”流水线或仅处理文本指令的VLA模型,RoboOmni在单一自回归模型中统一了多模态感知(语音、环境音、视觉)、认知推理、语音对话和动作执行。这避免了ASR转写带来的信息损失(如语调、情感、说话人身份),并减少了模块间接口的信息损耗。
- 构建大规模专用数据集OmniAction:为解决缺乏主动意图识别训练数据的问题,构建了包含14万集、5千+说话人、2.4千事件声、640背景音和6种上下文指令类型的大规模数据集。其构建流程(图3)创新性地结合了文本脚本生成、多TTS语音合成、声音事件与背景音插入以及多轮验证。
- 引入交互式确认机制:模型在推理出模糊或潜在意图后,不是直接执行,而是生成语音向用户进行澄清和确认(如“Would you like me to…?”),实现了更安全、协作式的主动机器人辅助。
- 系统性的评估体系:不仅评估了操作成功率,还专门设计了意图识别准确率、交互能力定性评估、推理速度对比等多维度指标,并在模拟(OmniAction-LIBERO)和真实世界环境中进行了验证。
🔬 细节详述
- 训练数据:
- 数据集名称:OmniAction。
- 来源:基于Open-X Embodiment数据集中的轨迹进行改造和扩充。
- 规模:141,162集(episodes),覆盖112种技能(如pick-place, open/close)和748种物体。
- 构建过程:三阶段流程(图3):1)文本脚本:使用GPT-4o将原子指令改写为包含6种上下文指令类型的多轮家庭对话;2)听觉实现:使用多种TTS引擎(MOSS-TTS、CosyVoice、Gemini-TTS)进行语音合成,模拟多说话人(包括重叠语音),插入非语言事件和环境背景音;3)验证:人工评估,确保意图可恢复性(98.7%一致性)。
- 预处理与增强:音频采样率为16kHz,视觉输入分辨率224x224。数据增强主要体现在数据集构建过程中,通过多样化的说话人音色、非语言事件和背景噪声实现。
- 损失函数:论文中未明确说明具体损失函数公式。根据其自回归生成范式,训练目标应为最大化生成序列的似然度。对于对话生成部分,优化
L_chat(θ) = -E[log pθ(y|X)];对于动作生成部分,优化L_act(θ) = -E[log pθ(r|X)]。最终总损失是两者之和:L(θ) = L_chat(θ) + L_act(θ)。 - 训练策略:
- 预训练:在OmniAction数据集上进行大规模预训练。使用64个A100 GPU训练10天,总计约15,360 A100小时。批大小512,学习率5e-5,训练10个epoch,前1000步进行warm-up。
- 有监督微调(SFT):在下游任务上微调,使用8个A100 GPU,训练1万-3万步,学习率5e-5。
- 关键超参数:
- 模型骨干:基于Qwen2.5-Omni(3B或7B参数版本,论文未明确指出具体使用哪个,但实验比较了二者)。
- 动作分词:FAST+分词器,码本大小A=2048。
- 动作块长度:N=6。
- 输入图像分辨率:224×224。
- 音频采样率:16,000 Hz。
- 训练硬件:大规模预训练使用64个NVIDIA A100 GPU;SFT使用8个NVIDIA A100 GPU。
- 推理细节:
- 解码策略:自回归生成。对于文本,逐token生成;对于动作,生成长度为N(N=6)的chunk。
- 推理速度比较:在单个RTX 4090 GPU上测量,RoboOmni的推理延迟仅为ASR+OpenVLA基线的0.49倍(图10),显示出端到端模型的效率优势。
- 正则化或稳定训练技巧:论文中未明确提及。
📊 实验结果
主要对比实验(模拟环境OmniAction-LIBERO-TTS): 论文在4种任务套件(Spatial, Goal, Object, Long-Horizon)和6种上下文指令类型上进行了评估,对比了“真值文本提示”和“语音经ASR转写为文本提示”两类基线。结果如表1所示。
| 任务套件 | 方法 | 成功率(%) |
|---|---|---|
| Spatial (平均) | Ground-truth Textual Prompt (NORA) | 49.8 |
| Audio→ASR→Text Prompt (NORA) | 56.5 | |
| RoboOmni (本文) | 93.0 | |
| Goal (平均) | Ground-truth Textual Prompt (NORA) | 12.5 |
| Audio→ASR→Text Prompt (NORA) | 16.3 | |
| RoboOmni (本文) | 85.8 | |
| Object (平均) | Ground-truth Textual Prompt (NORA) | 6.3 |
| Audio→ASR→Text Prompt (NORA) | 13.8 | |
| RoboOmni (本文) | 84.0 | |
| Long (平均) | Ground-truth Textual Prompt (NORA) | 32.3 |
| Audio→ASR→Text Prompt (NORA) | 51.0 | |
| RoboOmni (本文) | 79.5 | |
| 总体平均 | Ground-truth Textual Prompt (最强基线) | 16.3 |
| Audio→ASR→Text Prompt (最强基线) | 25.9 | |
| RoboOmni (本文) | 85.6 |
关键结论:RoboOmni在所有任务套件和指令类型上均大幅领先所有文本和ASR基线模型。基线模型在处理Goal和Object等语义模糊的任务时成功率骤降,而RoboOmni保持了高水平性能(85.8%和84.0%),证明了其处理复杂上下文的能力。
真实环境评估(OmniAction-LIBERO-Real): 评估真实人类录制语音指令下的性能,结果如表2所示。
| 方法 | Spatial | Goal | Object | Long | 平均 |
|---|---|---|---|---|---|
| OpenVLA | 51.6 | 38.2 | 38.0 | 32.4 | 40.1 |
| NORA | 2.0 | 5.6 | 26.8 | 35.4 | 17.4 |
| π0 | 86.0 | 60.0 | 70.0 | 79.0 | 73.8 |
| RoboOmni (本文) | 89.0 | 71.6 | 75.1 | 75.0 | 76.6 |
关键结论:RoboOmni(76.6%)在真实语音指令下超过了以鲁棒性著称的π0模型(73.8%),并远超其他ASR+VLA基线。
意图识别能力评估: 在专门的意图识别任务上(图7a),RoboOmni准确率达88.89%,显著高于ASR+GPT-4o(55.56%)和Qwen2.5-Omni-7B(50.00%)。
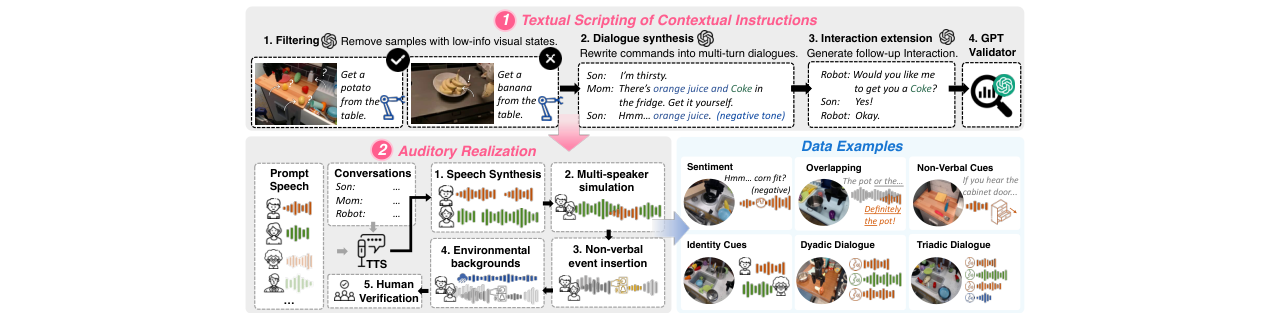
图7a:不同模型在意图识别任务上的准确率对比。RoboOmni展现了最强的跨模态意图推理能力。
消融实验(表3): 分析了不同输入模态对意图识别的影响。
| 设置 | 准确率(%) |
|---|---|
| Full Input (本文) | 88.89 |
| 无视觉输入 | 58.89 |
| 无音频输入 | 11.11 |
| 无副语言线索 | 50.56 |
关键结论:音频是提供核心指令信息的关键,视觉为场景理解提供必要上下文,副语言线索(语气、情感、非语言声音)对消歧有重要作用。
训练效率分析(图8): 比较了在OmniAction上预训练后再微调与从零开始训练的收敛速度。预训练模型在约2k步内即可达到接近90%的准确率,而从零训练模型在20k步后仅达到约30%且不稳定。

图8:预训练+微调与从零开始训练在不同指令类型上的收敛曲线对比。预训练提供了强大的泛化先验,显著加速和稳定了下游任务适应。
推理效率分析(图10):

图10:不同级联管线与RoboOmni的单次推理延迟对比。RoboOmni将延迟降低至ASR+OpenVLA基线的一半(0.49倍)。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个定义清晰且重要的新问题(跨模态上下文指令),并给出了一个完整、创新的解决方案(RoboOmni框架和OmniAction数据集)。技术路线合理,实验设计全面,包括了模拟/真实环境、多种基线对比、消融实验和多维度分析(成功率、意图识别、交互、效率)。证据可信,数据充分。扣分点在于:1)真实世界评估的机器人平台和场景较为单一,泛化性证明稍弱;2)失败分析显示执行层错误占比高,表明框架在“思考”和“行动”的衔接上仍有明显短板;3)对Talker模块(语音生成)的训练细节和效果评估不够详细。
- 选题价值���1.5/2:选题非常前沿,直击当前VLA模型与真实人机交互需求之间的关键差距。从被动执行到主动推理,是提升机器人智能水平的重要方向。其研究成果对具身智能、人机交互领域有显著的推动潜力,应用空间广阔。
- 开源与复现加成:0.5/1:论文承诺开源数据集(OmniAction)、模型权重和代码(GitHub链接已提供),并详细描述了训练细节(GPU、学习率、步数等),这极大地促进了研究的可复现性。数据集构建流程描述清晰。扣分点在于:1)未明确开源的是预训练模型还是最终微调模型;2)具体的超参数配置和训练脚本细节需待代码公开后验证。