📄 Resp-Agent: An Agent-Based System for Multimodal Respiratory Sound Generation and Disease Diagnosis
#音频分类 #多模态模型 #流匹配 #数据增强 #生物声学
🔥 9.0/10 | 前10% | #音频分类 | #多模态模型 | #流匹配 #数据增强
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Pengfei Zhang (香港科技大学(广州))
- 通讯作者:Li Liu (香港科技大学(广州), avrillliu@hkust-gz.edu.cn)
- 作者列表:Pengfei ZHANG (香港科技大学(广州)), Tianxin Xie (香港科技大学(广州)), Minghao Yang (香港科技大学(广州)), Li Liu* (香港科技大学(广州))
💡 毒舌点评
亮点:这篇论文最漂亮的地方在于它提出了一个“分析-生成”闭环的智能体系统,用LLM(Thinker-A2CA)动态决定“合成什么”来弥补诊断器的短板,把数据增强从一个被动的预处理步骤变成了主动的、对抗性的课程学习,这个系统设计思想很有启发性。 短板:不过,整个系统有点像个精心组装的乐高,依赖多个重型组件(LLM, BEATs, Longformer, 流匹配模型),对于呼吸音这个相对垂直的应用场景,其工程复杂度和算力需求是否与性能增益完全匹配,值得商榷。另外,生成的“合成临床音频”虽然用于训练有效,但缺乏真实生理细节的验证,其临床保真度仍需医生在严格双盲测试中评判。
📌 核心摘要
- 要解决的问题:深度学习在呼吸音分析中面临两大挑战:一是将音频信号转为频谱图会导致瞬态事件(如啰音)的信息损失;二是缺乏大规模、高质量的多模态(音频+临床文本)标注数据,且存在严重的类别不平衡。
- 方法核心:提出Resp-Agent,一个由中央控制器(Thinker-A2CA)编排的多智能体闭环系统。该系统能主动分析诊断器的弱点,并调度生成器进行针对性合成,从而将诊断与生成任务统一。诊断器采用“模态编织”将文本与音频token融合,并用稀疏音频锚点捕捉瞬态事件;生成器采用两阶段设计,先用LLM在文本诊断和参考音频风格条件下生成离散音频单元,再用流匹配解码器重建波形。
- 新在何处:1) 系统范式:首次将呼吸音的分析(诊断)和生成整合到一个由LLM驱动的闭环智能体框架中。2) 诊断器架构:提出基于稀疏全局注意力的“模态编织”和“音频锚点”机制,实现高效且精细的文本-音频跨模态对齐。3) 生成器设计:将文本LLM改造为可控的多模态音频单元生成器,并采用流匹配进行波形重建。4) 基准数据:构建并开源了首个大规模、多来源、跨机构的多模态呼吸音基准Resp-229k(22.9万条记录)。
- 主要实验结果:在ICBHI基准上,Resp-Agent的诊断性能(ICBHI Score 72.7%)超越先前最佳音频模型超过5个百分点。在自建的跨机构Resp-229k基准上,使用Thinker指导合成的平衡数据后,多模态诊断器的宏观F1从0.212大幅提升至0.598,证实了闭环生成策略的有效性。生成器在可控性(风格/内容解耦)和保真度(FAD 1.13)上也优于强基线(如微调的StableAudio Open)。关键实验结果见下表:
| 模型/方法 | 数据集 | 指标 | 原始(不平衡) | 平衡后 |
|---|---|---|---|---|
| 诊断器对比 | ||||
| Conformer (音频基线) | Resp-229k Test-CD | Macro-F1 | 0.1935 | 0.5360 |
| Resp-Agent Diagnoser (Ours) | Resp-229k Test-CD | Macro-F1 | 0.2118 | 0.5980 |
| 生成器策略对比 | ||||
| No-Synth (基线) | Resp-229k Test-CD | Macro-F1 | 0.212 | - |
| Class-Prior Rebalancing | Resp-229k Test-CD | Macro-F1 | - | 0.512 |
| Thinker-A2CA (Ours) | Resp-229k Test-CD | Macro-F1 | - | 0.598 |
| 生成器音频保真度对比 | ||||
| StableAudio Open (微调) | 个体化重建 | FAD ↓ | 1.54 | - |
| Resp-Agent Generator (Ours) | 个体化重建 | FAD ↓ | 1.13 | - |
- 实际意义:为数据稀缺且不平衡的医疗音频分析提供了一种强大的范式,即通过智能体驱动的闭环生成来主动构建更鲁棒的模型。开源的Resp-229k基准和代码将加速呼吸音领域的多模态研究。
- 主要局限性:1) 系统复杂度高,涉及多个大模型的训练与协调。2) 生成的合成音频虽用于训练有效,但其真实性和临床细节(如相位、微结构)仍需更严格的评估。3) 评估主要集中在诊断性能,对生成音频的直接临床效用(如用于教学或模拟)验证不足。
🏗️ 模型架构
Resp-Agent是一个由中央控制器协调的多智能体系统,包含三个核心模块:Thinker(规划者)、Generator(生成器) 和 Diagnoser(诊断器),形成一个“诊断->发现问题->指导合成->改进诊断”的闭环。
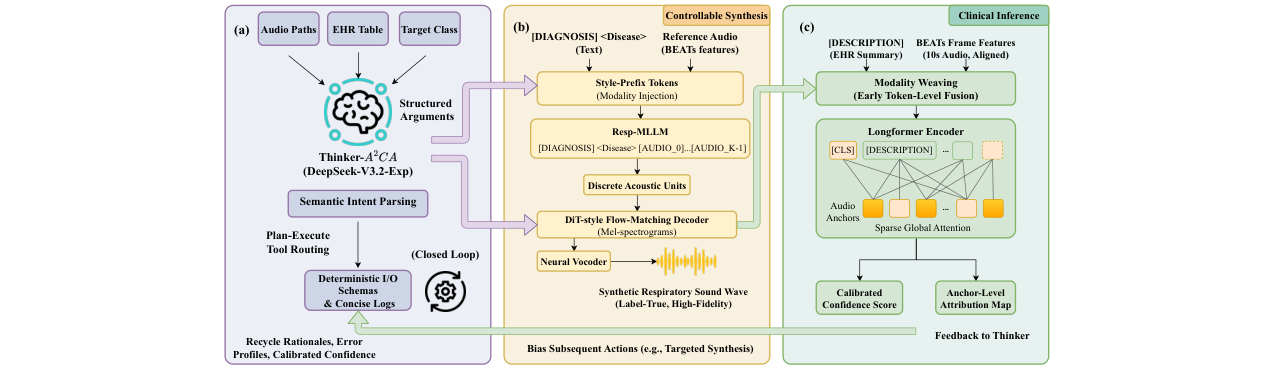
图1:Resp-Agent系统框架总览图(论文中Figure 1)。展示了三个模块如何交互:(a) Thinker (Thinker-A2CA) 作为中央规划器,解析语义意图并路由任务,其基于回收的错误档案和校准置信度指导后续行动;(b) Generator (Resp-MLLM) 利用模态注入,将文本诊断和参考音频风格作为条件,生成离散音频单元,再通过条件流匹配解码器重建波形;(c) Diagnoser 采用模态编织,在网络早期融合EHR文本和音频特征,并利用稀疏全局注意力进行跨模态推理。
- Thinker (Thinker-A2CA):
- 功能:作为中央控制器,负责解析任务、规划合成预算、并在闭环中动态调整策略。
- 实现:使用一个大型语言模型(DeepSeek-V3.2-Exp)作为推理核心。它接收诊断器的反馈(如错误档案、置信度),分析模型弱点,然后决定在哪些疾病类别或领域(Domain)上生成多少合成样本(B)。
- 关键设计:采用“主动对抗课程代理”(A2CA)策略,不只是静态平衡类别,而是动态地针对模型最难的案例(如罕见病、跨域数据)进行合成,实现精准数据增强。
- Generator (生成器): 生成器采用两阶段设计,实现内容(病理语义)与风格(录音特征)的解耦与可控生成。
图2:生成器第一阶段Resp-MLLM的详细架构(论文中Figure 2)。它通过模态注入将文本诊断语义与从参考音频提取的BEATs风格嵌入融合,提示Qwen3-0.6B-Base骨干网络,以自回归方式预测离散的BEATs声学单元序列。训练时采用随机掩码(约10%)以防止信息泄露。
- 阶段一:风格条件化的单元建模 (Resp-MLLM):
- 输入:文本诊断
d(如“Pneumonia”)和一段参考音频(用于风格)。 - 风格提取:参考音频通过预训练的BEATs编码器提取帧级特征
Z,经过时序池化压缩为K个风格描述符,再通过一个可训练的MLP投影到LLM的隐空间,得到风格嵌入E_style。 - 模态注入:在LLM的输入中,将
[AUDIO_0]...[AUDIO_{K-1}]占位符的嵌入替换为E_style,形成混合提示:[DIAGNOSER] d | [AUDIO_0]...[AUDIO_{K-1}]。 - 输出:LLM以自回归方式预测离散的BEATs声学单元序列
y。
- 输入:文本诊断
- 阶段二:条件流匹配解码 (CFM Decoder):
- 输入:阶段一预测的离散单元序列
y(作为内容条件)和BEATs特征的时序平均(作为全局音色条件)。 - 解码器:使用一个Diffusion Transformer (DiT) 参数化的条件流匹配模型,学习从高斯噪声
x0到目标梅尔频谱x1的速度场。 - 波形合成:生成的梅尔频谱通过神经声码器Vocos最终合成波形。此设计确保生成过程相位感知,能很好地重建瞬态事件。
- 输入:阶段一预测的离散单元序列
- Diagnoser (诊断器): 诊断器旨在鲁棒地融合文本与音频信息进行疾病分类。
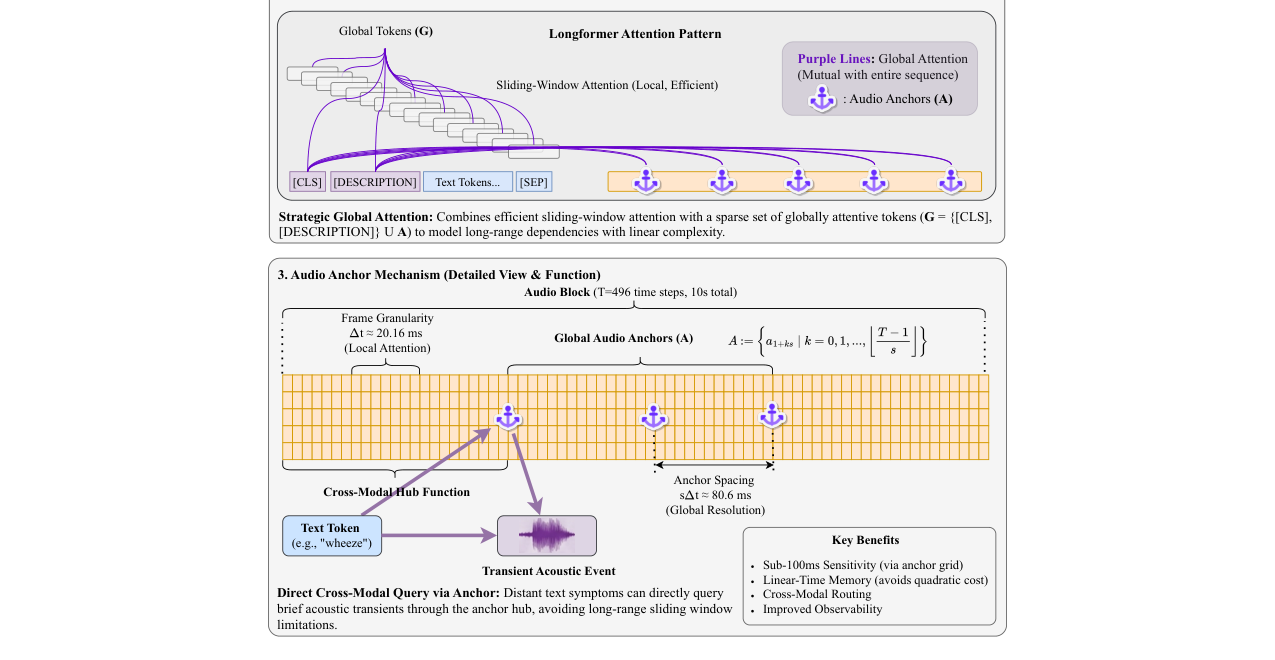
图3:诊断器架构:模态编织与战略全局注意力(论文中Figure 3)。详细展示了三个核心机制:(1) 输入层模态编织,将文本token和投影的音频嵌入融合成单一流;(2) 战略全局注意力,使用Longformer骨架,结合滑动窗口注意力和稀疏的全局token([CLS], [DESCRIPTION] 和音频锚点);(3) 音频锚点机制,作为跨模态枢纽,允许文本症状直接查询瞬态声学事件。
- 输入级模态编织:
- 文本流:临床摘要文本经过分词器得到token序列。
- 音频流:波形通过BEATs编码器提取特征,经过对齐(裁剪/填充到固定长度T=496帧),然后通过一个可训练的线性投影
W转换为音频嵌入。 - 融合:在输入层,将音频嵌入序列(作为
[AUDIO_EMBED]块)直接插入文本token序列中,形成一个交织的“编织”序列,使模型从第一层就能建模跨模态依赖。
- 战略全局注意力:
- 使用Longformer的高效注意力机制:大部分token采用局部滑动窗口注意力,但精心挑选一组全局token
G,它们与整个序列都有注意力连接。 G包括:分类符[CLS]、文本哨兵[DESCRIPTION],以及从音频块中等间隔采样的“音频锚点”(默认步长s=4,即每隔4帧选一个锚点,约80.6ms一个)。- 作用:锚点作为高效的跨模态枢纽,使得文本中的症状描述(如“干咳”)可以直接、低成本地查询序列中任何位置的瞬态音频事件,而无需通过长距离滑动窗口逐步传递,从而以线性复杂度实现约80ms级的时间分辨率。
- 使用Longformer的高效注意力机制:大部分token采用局部滑动窗口注意力,但精心挑选一组全局token
组件间数据流与交互:
- 闭环形成:Diagnoser在训练/评估中发现某些类别(如罕见病)或域(如特定设备数据)表现差,将此“错误档案”反馈给Thinker。
- 规划合成:Thinker分析反馈,动态生成一个合成预算分配表(例如,为“支气管炎”类别生成X个样本,其中Y%来自域A风格,Z%来自域B风格),并调度Generator。
- 执行合成:Generator根据Thinker的指令(目标类别
d+ 选定的参考音频风格),生成新的、高质量的合成呼吸音。 - 增强训练:合成数据被加入训练集,Diagnoser在此增强的数据集上重新训练,性能预期得到提升。
- 循环迭代:这个闭环可以迭代进行,持续优化。
💡 核心创新点
- 闭环智能体框架:将呼吸音分析从静态流水线转变为由LLM驱动的“诊断-合成”自适应闭环系统。这是方法论上的创新,将数据增强从被动手段提升为主动的、针对模型弱点的课程学习。
- 战略全局注意力与音频锚点:在多模态融合诊断器中,创新性地引入稀疏采样的音频锚点作为全局token。这解决了长序列中高效捕捉短时瞬态事件(如呼吸音中的爆裂音、哮鸣音)的难题,实现了精度与效率的平衡。
- 可控的多模态呼吸音生成器:将纯文本LLM改造为可同时接收文本语义和音频风格条件的多模态生成器。通过解耦病理内容(由文本控制)和声学风格(由参考音频控制),并结合流匹配解码,实现了高保真、可控的呼吸音合成,为解决数据稀缺提供了有力工具。
- 大规模多模态基准Resp-229k:构建了首个大规模(229k条记录)、多来源、跨机构,并配有LLM蒸馏临床叙述的呼吸音基准。其严格的跨域评估协议(训练/测试数据来自不同机构与设备)为评估模型的泛化能力提供了坚实基础。
🔬 细节详述
- 训练数据:
- 数据集:主要使用自建的Resp-229k。它聚合了UK COVID-19, ICBHI, SPRSound, COUGHVID, KAUH五个公开数据库,共229,101条质量控制后的记录,16个类别。
- 多模态对齐:使用DeepSeek-R1-Distill-Qwen-7B将各来源的结构化元数据(CSV/JSON/文件名)转换为标准化的临床摘要文本。该过程经过规则检查、LLM交叉验证和人工抽查审计,有效重写率低于0.75%。
- 预训练数据:诊断器的音频编码器(BEATs)在大规模音频数据上预训练。生成器的核心LLM骨干(Qwen3-0.6B)在Resp-229k上进行适配训练。
- 数据增强:核心创新在于使用Generator进行针对性生成,而非传统的SpecAugment等扰动增强。论文证明,传统的时移、噪声注入等朴素增强在跨域场景下会损害性能。
- 损失函数:
- 诊断器:标准交叉熵损失(Cross-Entropy Loss)。在预训练阶段使用了Focal Loss以强调少数类别。
- 生成器阶段一 (Resp-MLLM):标准的自回归语言建模损失(负对数似然)。公式为:
L_Resp = -∑ log p(y_i | y_{<i}, d, E_style)。 - 生成器阶段二 (CFM Decoder):流匹配损失,最小化预测速度场与目标速度之间的均方误差。公式为:
L_CFM = E[ || v_θ(x_t, c) - (x_1 - x_0) ||² ]。
- 训练策略:
- 诊断器:使用DeepSpeed库进行高效训练,启用梯度检查点。采用OneCycleLR学习率调度器,最大学习率1e-5。批次大小未在正文明确说明。训练10个epoch。
- 生成器:具体训练策略未在正文详述,但提到采用标准因果LLM训练,并使用了“泄漏自由”条件(随机掩码约10%的输入token)以稳定训练。
- 关键超参数:
- 风格token数 K:默认K=8。消融实验表明,K=8在风格相似性、FAD和下游F1上均优于K=0,2,4。
- 音频锚点步长 s:默认s=4,对应约80.6ms的时间分辨率。
- 文本/音频Dropout:在诊断器训练时,对文本token应用ptext=0.2的dropout,对音频帧应用paudio=0.1的dropout,以提高鲁棒性。
- BEATs码本大小 V:未明确说明。
- 生成器预算 B:核心超参数,指为平衡数据集所合成的总样本数。实验扫描了B∈{0, 10k, 20k, 30k, 50k}。
- 训练硬件:论文中未明确说明使用的GPU型号和数量。
- 推理细节:
- 诊断器:直接前向传播得到分类结果,并输出校准后的置信度分数。
- 生成器:Resp-MLLM以自回归方式生成离散单元序列;CFM解码器以32步迭代去噪(推理时步数固定);最终通过Vocos声码器生成波形。
- 正则化/稳定训练技巧:诊断器训练中使用了token/frame dropout;生成器训练中使用了随机掩码(Leak-free conditioning)以防止信息泄露。
📊 实验结果
主要基准与任务:
ICBHI 4分类:使用官方60-40%划分,评估Specificity (Sp), Sensitivity (Se) 和 ICBHI Score = 1/2(Sp+Se)。
Resp-229k 16分类(跨域):训练/验证集来自ICBHI, SPRSound, UK COVID-19;测试集(Test-CD)仅来自未见过的KAUH和COUGHVID。评估Accuracy和Macro-F1。
主诊断性能对比: 在ICBHI上,Resp-Agent达到 72.7% 的ICBHI Score,超越先前最佳方法(Dong et al., 2025)的67.55% 超过5个百分点。具体如下表:
| 方法 | 骨干网络 | 预训练数据 | Sp (%) | Se (%) | Score (%) |
|---|---|---|---|---|---|
| Dong et al. (2025) | AST | IN+AS | 85.99 | 49.11 | 67.55 |
| Resp-Agent [Ours] | LLM+Longformer | HF+SPR | 79.29 | 66.10 | 72.70 |
- Resp-229k跨域诊断结果: 在严格的跨域测试集(Test-CD)上,使用Thinker-A2CA指导合成的平衡数据训练后,多模态诊断器性能显著提升。下表总结了关键消融实验结果:
| 实验设置 | 方法 | 合成预算 B | Accuracy | Macro-F1 | Macro-F1_tail |
|---|---|---|---|---|---|
| 规划器策略对比 (Exp.1) | No-Synth (CE) | 0 | 0.849 | 0.212 | 0.074 |
| Random | 50k | 0.869 | 0.442 | 0.291 | |
| Class-Prior | 50k | 0.876 | 0.512 | 0.349 | |
| Uncertainty-Static | 50k | 0.881 | 0.546 | 0.376 | |
| Thinker-A2CA [Ours] | 50k | 0.887 | 0.598 | 0.421 | |
| 非生成 vs 生成不平衡缓解 (Exp.4) | Focal Loss (γ=2) | 0 | 0.839 | 0.267 | 0.129 |
| CE + Thinker-A2CA [Ours] | 50k | 0.887 | 0.598 | 0.421 | |
| 生成器内容-风格解耦验证 (Exp.6) | 风格交换 (平均) | - | - | Style-Sim: 0.91, P-Acc: 97.9% | FAD: 1.18 |
| 内容交换 (平均) | - | - | Style-Sim: 0.93, P-Acc: 96.1% | FAD: 1.19 | |
| 诊断器架构消融 (Exp.7) | Late Fusion, LLM EHR, 无锚点 | 0 | 0.790 | 0.160 | - |
| Modality Weaving, LLM EHR, 无锚点 | 0 | 0.650 | 0.189 | - | |
| 完整Resp-Agent (Ours) | 0 | 0.849 | 0.212 | - |
诊断器在Resp-229k上的性能总结图] 图4:诊断器在Resp-229k上的性能总结(论文中Table 8)。对比了在原始(不平衡)和平衡(使用生成器合成数据)两种数据制度下,文本基线、音频基线、无锚点的Longformer和完整多模态Resp-Agent的表现。结果显示,生成器平衡能大幅提升所有模型的Macro-F1,而完整的多模态架构在两种制度下都取得最佳性能。
- 生成器评估结果:
- 下游临床价值:使用不同方法平衡数据后训练诊断器,Resp-Agent生成的平衡数据带来最大提升。下表展示了多模态Longformer诊断器的结果:
| 训练集策略 | Accuracy | F1-Macro | 相对ΔF1 (vs. 不平衡) |
|---|---|---|---|
| 原始不平衡 | 0.8494 | 0.2118 | - |
| c-WaveGAN 平衡 | 0.8650 | 0.4520 | +0.2402 |
| AudioLDM 2 平衡 | 0.8781 | 0.5265 | +0.3147 |
| StableAudio Open 平衡 | 0.8830 | 0.5620 | +0.3502 |
| Resp-Agent 平衡 [Ours] | 0.8870 | 0.5980 | +0.3862 |
- 个体化重建保真度:与强生成模型对比,Resp-Agent生成器在风格相似度和FAD上均最优。
| 生成模型 | 余弦相似度 (Style-Sim) ↑ | FAD ↓ |
|---|---|---|
| c-WaveGAN | 0.61 ± 0.15 | 2.85 |
| AudioLDM 2 (微调) | 0.76 ± 0.11 | 1.92 |
| StableAudio Open (微调) | 0.83 ± 0.08 | 1.54 |
| Resp-Agent Generator [Ours] | 0.92 ± 0.04 | 1.13 |
⚖️ 评分理由
- 学术质量:6.5/7。创新性体现在开创性的多智能体闭环框架、新颖的音频锚点注意力机制以及将LLM适配为可控音频生成器的技术实现。技术实现正确且复杂。实验极其充分,包括在两个基准上的主实验、详细的消融研究(规划器策略、架构组件、生成器条件)、与众多强基线的对比以及生成数据的下游价值验证。证据链完整可信。扣分主要因为其创新更多是系统集成层面的“智能编排”,在单一模型架构(如DiT流匹配解码器)的理论或技术深度上未提出颠覆性突破。
- 选题价值:1.5/2。选题处于医疗AI与多模态音频处理的交叉前沿,直击呼吸音分析中的数据稀缺与不平衡两大核心痛点,应用前景明确。提出的闭环智能体范式对其他数据稀缺的垂直领域(如罕见病诊断、工业声学检测)有借鉴意义。扣分点在于呼吸音分析本身是一个相对小众且临床转化门槛高的应用领域,且系统复杂度可能限制其快速落地。
- 开源与复现加成:1.0/1。论文提供了几乎一切复现所需:完整的代码仓库、预训练模型权重、处理后的数据集(含生成的临床文本)的下载链接。附录中详细列出了实验设置、超参数、数据审计流程。这为社区复现和后续研究提供了极大便利,堪称典范。