📄 Query-Guided Spatial–Temporal–Frequency Interaction for Music Audio–Visual Question Answering
#音频问答 #多模态模型 #音视频 #时频分析
🔥 8.0/10 | 前25% | #音频问答 | #多模态模型 | #音视频 #时频分析
学术质量 7.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kun Li(University of Twente;IT University of Copenhagen)
- 通讯作者:Sami Sebastian Brandt(IT University of Copenhagen)
- 作者列表:Kun Li(University of Twente, IT University of Copenhagen)、Michael Ying Yang(University of Bath)、Sami Sebastian Brandt(IT University of Copenhagen)
💡 毒舌点评
这篇论文的亮点在于它为音乐音视频问答(AVQA)设计了一个从问题引导到最终预测的端到端框架,并创新性地将音频的频率域特征作为一等公民纳入时空交互中,有效解决了视觉线索微弱时(如演奏者动作不明显)的识别难题,消融实验也扎实地证明了各模块的必要性。然而,其主要短板在于提出的框架相对复杂,引入了多个预训练编码器(CLIP, VGGish, AST),整体计算开销和模型复杂度可能限制其在资源受限场景的应用,且实验主要集中在音乐场景这一相对小众的benchmark上。
🔗 开源详情
- 代码:提供了GitHub代码仓库链接:
https://github.com/lik1996/QSTar。 - 模型权重:论文中未提及公开发布预训练模型权重。
- 数据集:实验使用的MUSIC-AVQA和AVQA均为公开数据集,论文中未提供独家数据。
- Demo:论文中未提及提供在线演示。
- 复现材料:在论文附录A和正文中详细提供了实现细节,包括优化器(AdamW)、学习率(1e-4)、批次大小(64)、训练轮次(30)、硬件(单张NVIDIA H100 GPU)等。代码链接的提供极大便利了复现。
- 引用的开源项目:论文依赖并引用了CLIP、VGGish、AST、Token Merging等预训练模型或开源工具。
📌 核心摘要
本文针对音乐音视频问答(AVQA)任务中现有方法对音频利用不充分、问题信息引入较晚的问题,提出了一种名为QSTar(Query-guided Spatial–Temporal–Frequency Interaction)的新型方法。该方法的核心是在整个处理流程中引入问题引导(query guidance),并设计了一个空间-时间-频率交互(STFI)模块,以充分利用音频信号的频域特性来增强视听理解。具体地,方法包含三个主要组件:1)查询引导的多模态关联模块(QGMC),在早期阶段就用问题信息精炼音频和视觉特征;2)空间-时间-频率交互模块(STFI),在空间、时间和频率三个维度进行细粒度的跨模态交互,尤其利用音频频谱图变换器(AST)提取频率感知特征;3)基于提示的查询上下文推理模块(QCR),在最后阶段整合语言上下文进行推理。在MUSIC-AVQA基准上的实验表明,QSTar在所有问题类型上均取得了显著的性能提升,整体准确率达到78.98%,超越了先前的最优方法QA-TIGER(77.62%)和TSPM(76.79%),尤其在需要频率分析的音频类和音视频对比类问题上优势明显。消融研究验证了每个模块的有效性以及问题引导贯穿全流程的必要性。该工作的意义在于推动了多模态问答中对音频模态的精细化建模,其频率感知交互的设计为解决类似问题提供了新思路。局限性主要在于模型依赖多个预训练编码器,计算成本较高,且主要验证于音乐场景。
🏗️ 模型架构
QSTar是一个端到端的音视频问答框架,整体流程如图2所示。输入包括60秒的视频和问题文本。视频被分割成60个1秒的片段。
输入表示:
- 视觉特征:使用冻结的CLIP视觉编码器提取每个片段的帧级(Fv)和经Token Merging压缩的补丁级(Fp)特征。
- 音频特征:使用VGGish网络提取每个片段的音频特征(Fa)。
- 文本特征:使用CLIP文本编码器提取问题的句子级(Fsentence)和词级(Fw)特征。
查询引导的多模态关联模块(QGMC):这是框架的第一个核心模块,旨在用问题信息早期介入并精炼音视觉特征。它分为三步:
- 自增强:分别对视觉(Fv)、音频(Fa)和词级文本(Fw)特征应用自注意力(SA)。
- 语义捕获:以自增强后的词级文本特征为查询(Query),通过交叉注意力(CA)从视觉和音频特征中捕获与问题相关的语义信息,得到Fqv和Fqa。
- 信息传播:将捕获的语义信息聚合(Fqg),再分别以原始的视觉和音频特征为查询,通过CA将聚合信息传播回去,得到初步的查询引导特征Fvq和Faq。最后通过残差连接和FFN进行精炼,输出F’vq和F’aq。
空间-时间-频率交互模块(STFI):对QGMC输出的特征进行进一步的多维度交互。
- 空间-时间交互(STI):首先,利用音频特征(F’aq)作为键和值,通过CA对视觉补丁特征(Fp)进行空间上的声音区域聚焦,得到Fsi。同时,计算F’vq与F’aq的点积以捕获时间动态,得到Fti。两者拼接后经FFN得到空间-时间增强的视觉特征Fvi。
- 时间-频率交互(TFI):这是本文的创新点。使用预训练的AST从音频波形中提取频率感知特征Fast。通过一个频率注意力机制,结合问题信息(Fw)和Fast的时序均值,计算频率维度的注意力权重,对AST特征进行加权得到F’ast。最后,将F’ast与QGMC输出的音频特征F’aq拼接,通过卷积块融合,得到频率增强的音频特征Fai。
查询上下文推理模块(QCR)与预测:这是最后的推理与融合阶段。
- 构建查询上下文:从数据集问题类型中归纳出五个关键方面(类型、持续时间、位置、顺序、响度),将这些方面的关键词编码为提示特征(Fprompt),与问题的句子级特征(Fsentence)拼接后,经自注意力得到查询上下文特征Fqc。
- 特征精炼:以Fqc为查询,分别通过CA对STFI输出的视觉(Fvi)和音频(Fai)特征进行精炼,得到最终的Ffv和Ffa。
- 融合与预测:将Ffv和Ffa拼接后通过全连接层(FC)得到融合特征Fav。最终,用Fav与Fsentence做逐元素乘法,得到答案预测向量e,用于从预定义词表中分类预测答案。
💡 核心创新点
- 全流程问题引导的视听特征精炼:与之前大多数方法仅在最后阶段融合问题信息不同,QSTar通过QGMC模块在特征提取的早期阶段就引入问题引导,使音视觉特征从一开始就具有任务相关性,提升了后续推理的精度。
- 显式频率域交互模块(TFI):针对音乐场景中视觉线索可能微弱的问题,创新性地引入了基于AST的频率交互子模块。该模块通过频率注意力机制,利用问题信息引导模型关注最具判别力的音频频率带,有效区分具有相似视觉动作但音色不同的乐器。
- 基于提示的查询上下文推理(QCR):设计了一种轻量级的提示学习机制,将任务知识(音乐理解的关键维度)编码为提示词,与问题语义结合形成上下文,用于指导最终的特征融合,增强了模型的推理能力和可解释性。
🔬 细节详述
- 训练数据:主要在MUSIC-AVQA数据集(约40K QA对,9288个视频)上进行训练和评估。也在AVQA数据集(57K QA对)上进行了评估以验证泛化性。
- 损失函数:未在提供的文本中明确说明,但根据任务性质(分类),应为标准的交叉熵损失。
- 训练策略:
- 优化器:AdamW
- 初始学习率:1e-4
- 学习率衰减:每10个epoch衰减0.1倍
- Batch Size:64
- 训练Epoch数:30
- 关键超参数:特征投影维度统一为512。视觉补丁经Token Merging后M’的值未说明。
- 训练硬件:单张NVIDIA H100 GPU。
- 推理细节:采用分类预测方式,从预定义词表中选择答案。未提及具体的解码策略或beam search。
- 正则化或稳定训练技巧:使用了参数冻结的预训练编码器(CLIP, VGGish, AST),未提及其他特定的正则化技巧。
📊 实验结果
主要对比实验(MUSIC-AVQA测试集,准确率%)
| 方法 | Audio QA | Visual QA | Audio-Visual QA | Avg |
|---|---|---|---|---|
| AVST | 73.87 | 74.40 | 69.53 | 71.59 |
| LAVISH | 75.97 | 80.22 | 71.26 | 74.46 |
| TSPM | 76.91 | 83.61 | 73.51 | 76.79 |
| PSOT | 78.22 | 80.07 | 72.61 | 75.29 |
| QA-TIGER | 78.58 | 85.14 | 73.74 | 77.62 |
| QSTar (ours) | 80.63 | 84.17 | 75.98 | 78.98 |
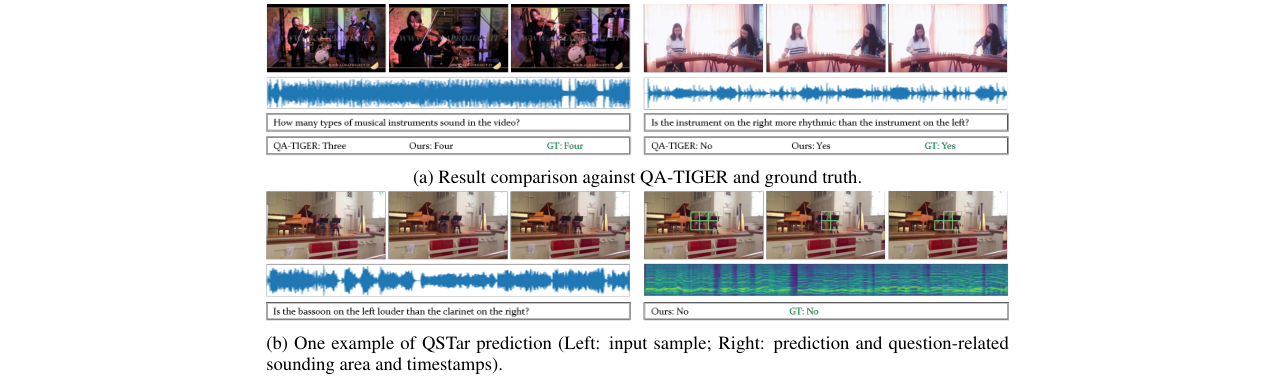
QSTar在整体平均准确率上达到了78.98%,显著优于此前的最优方法QA-TIGER(77.62%),绝对提升1.36个百分点。在音频相关问题(Audio QA)和音视频联合问题(Audio-Visual QA)上优势尤为明显,例如在Audio QA的对比类问题上比QA-TIGER高出4.2%。
与大型多模态模型对比 论文还与GPT-4o(55.72%)、VideoLLaMA2(71.98%, 微调后)等模型进行了对比,显示QSTar在专用领域基准上具有明显优势。
消融实验
- 主模块消融:移除所有模块后,平均准确率下降至73.29%。移除QGMC、QCR、STI、TFI和STFI模块分别导致准确率下降2.18%、0.79%、1.18%、1.57%和2.36%,证明了各组件的贡献。
- 问题引导阶段消融:移除早期(QGMC)、中期(TFI中的问题嵌入)和后期(QCR)的问题引导分别导致准确率下降1.05%、0.43%和0.73%,表明全流程引导的有效性。
- 提示策略消融:与使用问题转译、视频描述或生成式提示等其他策略相比,本文设计的统一关键词提示效果最佳(78.98%)。
主要消融实验结果(准确率%)
| 模块/设置 | Audio QA | Visual QA | Audio-Visual QA | Avg |
|---|---|---|---|---|
| w/o all | 73.87 | 79.15 | 70.33 | 73.29 |
| w/o QGMC | 79.08 | 83.44 | 72.92 | 76.80 |
| w/o QCR | 79.33 | 83.24 | 75.43 | 78.19 |
| w/o TFI | 78.21 | 83.24 | 74.39 | 77.41 |
| QSTar (ours) | 80.63 | 84.17 | 75.98 | 78.98 |
⚖️ 评分理由
- 学术质量:6.0/7 - 本文提出了一套完整且逻辑自洽的技术方案来解决特定问题。在MUSIC-AVQA基准上取得了显著性能提升,并通过详尽的消融研究验证了各设计模块的有效性,实验充分,证据可信。创新性在于将频率域分析和全流程问题引导进行系统性整合,属于扎实的增量式创新而非范式突破。
- 选题价值:1.0/2 - 音乐场景的音视频问答是多模态理解中的一个重要垂直领域。该工作对于提升音乐内容理解、智能视频编辑、辅助聆听等应用有潜在价值,但任务本身相对小众,对更广泛的语音/音频处理读者的直接相关性一般。
- 开源与复现加成:0.5/1 - 论文明确提供了代码仓库链接(
https://github.com/lik1996/QSTar),并在附录中详细说明了训练超参数、硬件环境等复现所需的关键信息,透明度较高。未公开模型权重,但整体复现指引较为清晰。