📄 PrismAudio: Decomposed Chain-of-Thought and Multi-dimensional Rewards for Video-to-Audio Generation
#音频生成 #强化学习 #扩散模型 #流匹配 #基准测试
🔥 9.0/10 | 前10% | #音频生成 | #强化学习 | #扩散模型 #流匹配
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Huadai Liu(香港科技大学; 阿里巴巴通义团队)
- 通讯作者:Wei Xue(香港科技大学)
- 作者列表:Huadai Liu(香港科技大学; 阿里巴巴通义团队)、Kaicheng Luo(阿里巴巴通义团队)、Wen Wang(阿里巴巴通义团队)、Qian Chen(阿里巴巴通义团队)、Peiwen Sun(香港中文大学)、Rongjie Huang(香港中文大学)、Xiangang Li(阿里巴巴通义团队)、Jieping Ye(阿里巴巴通义团队)、Wei Xue(香港科技大学)
💡 毒舌点评
亮点:论文首次将强化学习与分解式思维链(CoT)相结合,应用于视频到音频生成,巧妙地将一个复杂的多目标优化问题分解为四个可解释、可优化的维度,并提供了高效训练算法(Fast-GRPO)和高质量评测基准(AudioCanvas)。短板:该框架高度依赖一个强大的多模态语言模型(如VideoLLaMA2)来生成高质量的CoT训练数据,且音频基础模型本身也采用了多种现有先进组件(如VideoPrism、T5-Gemma),其“从零到一”的原创性贡献相对有限。
🔗 开源详情
- 代码:论文承诺将公开完整代码,但未提供具体仓库链接。
- 模型权重:论文承诺将公开所有模型权重。
- 数据集:论文承诺将公开自建的AudioCanvas基准测试集。
- Demo:论文中未提及在线演示链接。
- 复现材料:论文提供了非常详细的附录,包括训练细节、超参数、资源需求、CoT生成Prompt等,复现信息充分。
- 论文中引用的开源项目:依赖的开源项目/模型包括:Stability AI的VAE、VideoPrism、T5-Gemma、VideoLLaMA2、MS-CLAP、Synchformer、Meta Audiobox Aesthetics、StereoCRW、Gemini 2.5 Pro(用于数据生成)。
📌 核心摘要
本文针对视频到音频(V2A)生成任务中存在的“目标纠缠”(语义、时序、美学、空间等目标相互冲突)和缺乏人类偏好对齐的问题,提出了PrismAudio框架。其核心方法是将单一的推理路径分解为四个专门的CoT模块(语义、时序、美学、空间),并为每个模块设计对应的奖励函数,通过多维强化学习进行联合优化。与现有方法相比,新在:1)首次在V2A中整合分解CoT与多维RL;2)提出Fast-GRPO算法,通过混合ODE-SDE采样大幅降低训练开销;3)构建了更严谨的AudioCanvas基准测试集(包含300类单事件和501个多事件场景)。实验结果表明,在VGGSound测试集上,PrismAudio在语义一致性(CLAP: 0.47 vs. 0.43)、时序同步性(DeSync: 0.41 vs. 0.55)和空间准确性(CRW: 7.72 vs. 13.47)等指标上均优于此前SOTA的ThinkSound,并在主观评测中获得最高MOS分数。其实际意义在于为V2A生成提供了一个可解释、可精细控制且对齐人类偏好的新范式。主要局限性在于训练过程依赖LLM生成的CoT数据和多阶段训练,计算成本较高。
🏗️ 模型架构
PrismAudio的整体框架分为三个主要阶段,建立在一个基于流匹配的多模态扩散Transformer音频基础模型之上。
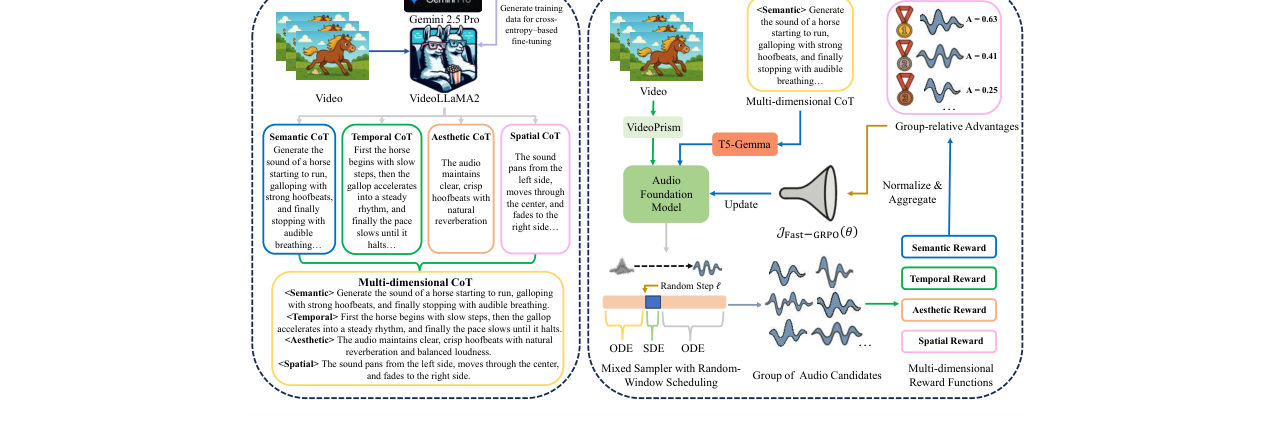
图1:PrismAudio框架概览图。左侧面板展示了CoT训练数据的构建过程:使用Gemini 2.5 Pro为视频生成四维CoT描述,然后微调VideoLLaMA2以从静音视频生成这些CoT。右侧面板展示了Fast-GRPO多维CoT-RL训练框架:使用生成的候选音频计算四维奖励,通过组相对优势更新音频模型。
CoT感知音频基础模型:
- 输入:静音视频和(可选的)文本提示。
- 输出:生成的音频波形(立体声,44.1kHz)。
- 骨干网络:基于扩散Transformer(DiT)架构,采用流匹配(Flow Matching)作为生成机制。
- 关键增强:
- 视频编码器:用VideoPrism替换了常见的CLIP编码器,以提供更强大的视频理解能力,特别是在复杂场景中。
- 文本编码器:将标准T5编码器升级为T5-Gemma,以更好地解析和利用包含复杂逻辑结构的四维CoT文本条件。
- 多模态融合:采用门控相加和交叉注意力的双重策略融合视频特征;使用门控相加直接注入Synchformer提取的时序同步特征。
分解的多维CoT推理模块: 这是PrismAudio的核心创新之一。它将传统单一的推理规划过程分解为四个并行、专门的CoT生成模块,由微调后的VideoLLaMA2模型实现。
- 语义CoT:识别视频中的音频事件、对象及其特征。
- 时序CoT:确定音频事件发生的顺序和时间关系。
- 美学CoT:评估和描述所需的音频质量,如自然度、保真度。
- 空间CoT:分析声源的方位、距离和移动模式。 这四个CoT的文本被拼接后,作为增强的结构化文本条件,用于微调音频基础模型,引导其生成。
Fast-GRPO多维RL优化框架: 这是另一核心创新,用于后训练音频基础模型,使其与人类多维偏好对齐。
- 多维奖励函数:为每个CoT维度设计独立的奖励模型:语义奖励(MS-CLAP)、时序奖励(Synchformer)、美学奖励(Meta Audiobox Aesthetics)、空间奖励(StereoCRW)。
- Fast-GRPO算法:
- 核心思想:将确定性ODE采样路径与随机SDE采样相结合。在一个随机选择的、宽度较小的时间步窗口内使用SDE��(引入随机性,用于策略探索和优化),其余时间步使用确定性ODE步(保持效率)。
- 策略与比率:在SDE步内,采样策略为高斯分布,可以解析地计算出GRPO所需的策略比率。
- 优化目标:最大化基于组相对优势的窗口化GRPO目标函数。该目标函数仅在选定的SDE步上计算,将策略模型的函数评估次数(NFE)从总步数T降低到窗口宽度w,从而大幅提升训练效率。
💡 核心创新点
- 分解式多维CoT与多维RL的整合:首次提出将V2A任务的复杂推理过程分解为语义、时序、美学、空间四个专门的CoT模块,并为每个模块配备对应的奖励函数,通过多维RL进行联合优化。这解决了现有方法中目标纠缠和缺乏偏好对齐的根本问题。
- Fast-GRPO高效训练算法:提出混合ODE-SDE采样策略和随机窗口调度,将GRPO训练的计算开销大幅降低,使其能实际应用于扩散模型的多维优化,且不影响生成质量。
- AudioCanvas高质量基准测试:构建了一个更严谨的V2A评测集,包含300个类别、超过500个多事件场景样本,并配有通过验证的高质量CoT标注,填补了现有基准在场景复杂性和标注质量上的不足。
- 增强的音频基础模型:通过采用更强大的视频编码器(VideoPrism)和文本编码器(T5-Gemma),并设计针对性的多模态特征融合策略,提升了模型的基础生成能力和对结构化CoT的理解能力。
🔬 细节详述
- 训练数据:
- 音频基础模型预训练:使用了WavCaps、AudioCaps和VGGSound数据集。
- CoT数据构建与VideoLLaMA2微调:使用VGGSound数据集,由Gemini 2.5 Pro生成四维CoT描述,然后用于微调VideoLLaMA2-AV(7B)模型。微调时冻结了视频、音频编码器和投影器,仅更新视频投影器和语言模型。
- RL后训练:使用VGGSound数据集。
- 损失函数:
- 基础模型训练:采用流匹配损失(预测速度场v_θ)。
- CoT微调:采用标准的下一token预测损失(交叉熵)。
- RL优化:采用带剪切和KL惩罚的GRPO目标函数(公式7)。KL比率权重为0.04。
- 训练策略:
- VAE微调(可选):在立体声数据上微调Stability AI的VAE,24张A800 GPU,约5天。
- 主模型预训练:8张A100 GPU,100k步,有效batch size 256,学习率1e-4,使用EMA和AMP。
- CoT微调:配置同上。
- VideoLLaMA2微调:8张A800 GPU,10 epochs,batch size 4/GPU,全局batch size 128,学习率2e-5,AdamW优化器,使用DeepSpeed ZeRO-3。
- Fast-GRPO后训练:8张A800 GPU,约5天,学习率1e-5,超参数:KL比率0.04,噪声水平0.7,组大小16,SDE步数2,总采样步数24。
- 关键超参数:音频模型参数量约518M(PrismAudio w/o CoT-RL)。推理时间约0.63秒/9秒音频。
- 训练硬件:NVIDIA A800(80GB)和A100 GPU。
- 推理细节:采用混合ODE-SDE采样器(训练时),推理时可使用标准ODE采样。无特别说明beam size或温度。
- 正则化技巧:在GRPO目标中加入KL散度正则化以防止奖励黑客攻击(reward hacking)。
📊 实验结果
论文在VGGSound测试集(域内)和自建的AudioCanvas基准(域外)上进行了全面评估。
表1:在VGGSound测试集上的客观与主观评估结果
| 方法 | 参数量 | 语义 (CLAP↑) | 时序 (DeSync↓) | 美学质量 (PQ↑, PC↓, CE↑, CU↑) | 空间准确性 (GCC↓, CRW↓) | 分布 (FD↓, KL↓) | 主观 (MOS-Q↑, MOS-C↑) | 推理时间(s) |
|---|---|---|---|---|---|---|---|---|
| GT | - | 0.46 | 0.55 | 6.30, 3.85, 4.40, 5.65 | -, - | -, - | 4.58±0.18, 4.65±0.15 | - |
| ThinkSound | 1.3B | 0.43 | 0.55 | 6.15, 3.53, 3.95, 5.48 | 4.65, 13.47 | 1.17, 1.35 | 4.05±0.55, 4.18±0.51 | 1.07 |
| PrismAudio (Ours) | 518M | 0.47 | 0.41 | 6.38, 3.24, 4.29, 5.68 | 3.77, 7.72 | 1.08, 1.23 | 4.21±0.35, 4.22±0.29 | 0.63 |
| PrismAudio w/o CoT-RL | 518M | 0.42 | 0.51 | 6.17, 3.32, 3.94, 5.48 | 4.06, 10.29 | 1.14, 1.43 | 4.02±0.48, 4.11±0.42 | 0.63 |
关键结论:PrismAudio在所有维度上均达到SOTA,且模型更小、推理更快。
表2:在AudioCanvas基准上的评估结果
| 方法 | 语义 (CLAP↑) | 时序 (DeSync↓) | 美学质量 (PQ↑, CE↑) | 空间准确性 (CRW↓) | 分布 (FD↓) | 主观 (MOS-Q↑, MOS-C↑) |
|---|---|---|---|---|---|---|
| GT | 0.48 | 0.40 | 6.47, 4.02 | - | - | 4.65±0.23, 4.72±0.20 |
| ThinkSound | 0.48 | 0.80 | 6.48, 4.10 | 22.82 | 1.95 | 3.79±0.58, 3.80±0.54 |
| PrismAudio (Ours) | 0.52 | 0.36 | 6.68, 4.26 | 12.87 | 1.92 | 4.12±0.28, 4.01±0.25 |
关键结论:在更具挑战性的域外基准上,PrismAudio依然表现稳健,而ThinkSound在时序和空间上性能大幅下降。
图2:Fast-GRPO与Flow-GRPO训练收敛曲线对比。Fast-GRPO收敛更快(200步超越Flow-GRPO的最终性能),且最终奖励分数更高(~0.51 vs ~0.47)。
消融实验关键结果:
- CoT推理策略(表3):分解的MultiCoT显著优于单块的Monolithic CoT和随机的Random CoT,证明分解和结构化推理的必要性。
- 奖励维度(表4):多维度联合优化是唯一能平衡所有目标的方法。仅优化单一维度(如语义)会导致其他维度(如时序)严重恶化。
Fast-GRPO效率:如图2所示,Fast-GRPO相比Flow-GRPO(全程SDE)训练速度提升约3倍(200步 vs 600+步达到同等性能),且最终性能更优。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一个完整、自洽且创新的系统,将分解CoT、多维RL和高效训练算法有机结合,用于解决V2A的核心难题。实验设计全面,有充足的消融研究(CoT类型、奖励维度、编码器选择等)支撑各设计点。结果可信且具有说服力。扣分点在于其系统集成度较高,部分组件(如CoT数据生成、基础模型编码器)并非最底层的原创。
- 选题价值:1.5/2:视频到音频生成是当前多模态生成的热点和难点,其研究对内容创作、游戏、影视后期等行业有直接应用价值。论文直击该领域多目标优化与对齐的痛点,选题前沿且重要。
- 开源与复现加成:1.0/1:论文明确承诺开源所有核心资源(代码、模型、数据集、基准),并提供了极其详细的实施细节(从硬件到超参数),这极大地促进了研究的可复现性和后续工作的开展。