📄 Physics-Informed Audio-Geometry-Grid Representation Learning for Universal Sound Source Localization
#声源定位 #物理信息 #麦克风阵列 #空间音频
🔥 8.0/10 | 前25% | #声源定位 | #物理信息 | #麦克风阵列 #空间音频
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.7 | 置信度 高
👥 作者与机构
- 第一作者:Min-Sang Baek(Hanyang University, Department of Electronic Engineering)
- 通讯作者:Joon-Hyuk Chang(Hanyang University, Department of Electronic Engineering)
- 作者列表:Min-Sang Baek(Hanyang University, Department of Electronic Engineering)、Gyeong-Su Kim(Hanyang University, Department of Electronic Engineering)、Donghyun Kim(Hanyang University, Department of Electronic Engineering)、Joon-Hyuk Chang(Hanyang University, Department of Electronic Engineering)
💡 毒舌点评
亮点:论文系统性地将“物理规律”(如TDOA仅依赖麦克风相对位置)转化为可学习的网络模块(如rMPE和LNuDFT),这种“物理信息引导”的思路比纯粹的黑盒数据驱动更优雅,也显著提升了对未见阵列的泛化能力。短板:提出的框架在极端密集网格(如D>4096)下,于真实数据集上的性能收益不明显甚至略有下降,这暗示了模型在处理微小扰动时的稳定性或表示空间的极限可能仍有探索空间。
🔗 开源详情
- 代码:提供公开GitHub仓库链接(https://github.com/BaekMS/Audio-Geometry-Grid_Representation-Learning)。
- 模型权重:论文中未明确提及是否公开预训练模型权重。
- 数据集:使用了公开的LOCATA挑战赛数据集(NAO robot和Eigenmike录音),以及合成的数据集。合成过程详细描述在附录中。
- Demo:未提及。
- 复现材料:非常充分。包括完整的模型架构细节(附录A.3, A.4)、损失函数公式、训练策略(MSGL、DSCL)、所有超参数设置、合成数据生成算法(算法3)、评估指标定义、以及用于复现的核心代码链接。
- 论文中引用的开源项目:使用了
gpuRIR进行房间冲激响应仿真,fvcore用于计算复杂度,py-webrtcvad用于生成语音活动检测标签,以及公开的LibriSpeech、MS-SNSD、TIMIT、ESC-50等数据集。
📌 核心摘要
- 问题:现有的深度神经网络声源定位(SSL)方法严重依赖于固定的麦克风阵列(MA)几何结构和预定义的到达方向(DOA)网格,导致其泛化性差,无法适应未见过的阵列或灵活的网格需求。
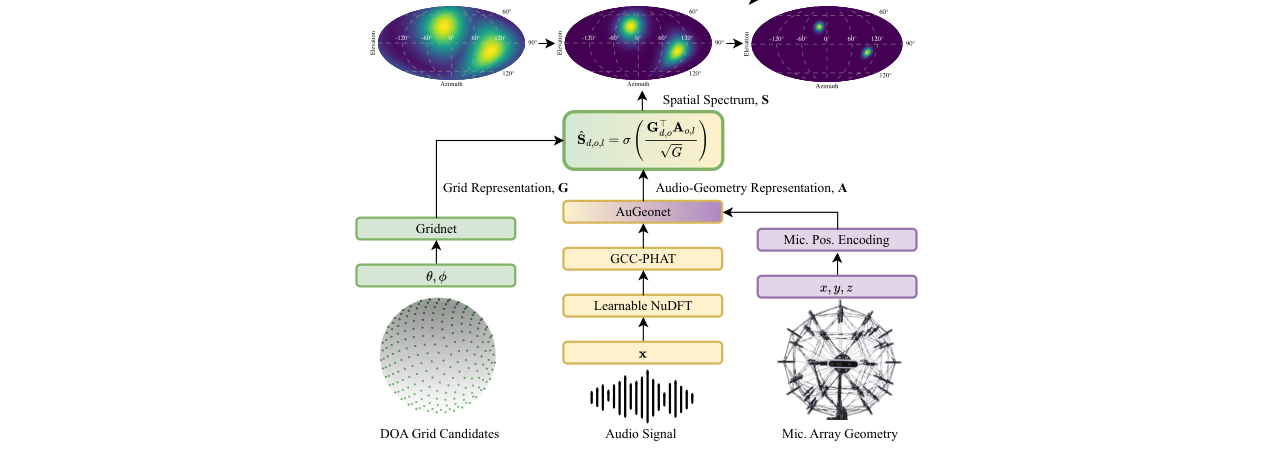
- 方法核心:提出了音频-几何-网格表示学习(AGG-RL)框架。该框架包含两个网络:AuGeonet(从音频和阵列几何中提取音频-几何表示)和Gridnet(从候选DOA网格中提取网格表示)。两者在共享的潜在空间中通过内积对齐,生成概率空间谱。
- 创新点:a) 引入可学习非均匀离散傅里叶变换(LNuDFT),使模型能自适应地分配频率bin,重点关注物理信息丰富的相位区域(如图2所示);b) 设计相对麦克风位置编码(rMPE),将麦克风坐标相对于参考通道进行编码,与TDOA的物理特性一致;c) 通过表示学习对齐,实现了网格灵活和几何不变的SSL,无需重新训练即可适应新阵列和新网格。
- 主要实验结果:在LOCATA等真实与合成数据集上,AGG-RL在未见阵列(如Eigenmike)和动态阵列配置上取得了最佳性能。如表3所示,在Eigenmike数据集上,该方法MAE为11.24°,ACC10为72.17%,显著优于基线Unet(14.89°/65.82%)和GI-DOAEnet(93.61°/0.00%)。消融实验(表3)证实了LNuDFT和rMPE的有效性。
- 实际意义:该方法为构建能适应各种硬件(不同麦克风阵列)和任务需求(不同定位精度/网格)的“通用”声源定位系统提供了新思路,在机器人、自动驾驶、AR/VR等多领域有应用潜力。
- 主要局限性:a) 计算复杂度:虽然AuGeonet部分复杂度随通道数线性增长,但Gridnet部分随网格点数D线性增长,D很大时可能带来额外开销(表5)。b) 性能边界:在真实数据上,当D超过2048时性能提升不明显甚至略有下降(表4),表明模型对过度密集网格的表示能力或鲁棒性存在边界。
🏗️ 模型架构
AGG-RL框架(如图2所示)是一个端到端的系统,接受多通道音频信号、麦克风阵列几何坐标和候选DOA网格作为输入,最终输出每个网格点上的声源存在概率(空间谱)。
核心组件与数据流:
音频-几何表示网络(AuGeonet):
- 输入:原始多通道音频信号
x和麦克风阵列三维坐标p。 - 流程:
- LNuDFT:对每个通道的音频信号应用可学习的非均匀DFT,生成频域表示
X_c。这一步是可学习的,优化后的频率分配如图3所示,倾向于在1.5-7.5 kHz的中高频区域密集采样,以获取更鲁棒的相位信息。 - 相对相位特征(GCC-PHAT):基于LNuDFT的输出,计算相对于参考通道的广义互相关-相位变换(GCC-PHAT)特征
X^GCC,强调相位差异。 - 相对麦克风位置编码(rMPE):将麦克风坐标转换为相对于参考通道的球坐标(距离、方位角、仰角),并编码为正弦位置编码向量
P(如公式10-12)。这直接嵌入了“TDOA依赖相对位置”的物理先验。 - 特征提取与融合:将GCC-PHAT特征与rMPE拼接,通过一系列卷积块、通道维度的多头自注意力(CW-MHSA)和时序GRU网络,提取时空特征。
- 输出:通过表示映射块(RMB),输出O个维度为G的音频-几何表示(AGR)
A。AGG-RL中,O=3,G=256。
- LNuDFT:对每个通道的音频信号应用可学习的非均匀DFT,生成频域表示
- 输入:原始多通道音频信号
网格表示网络(Gridnet):
- 输入:候选DOA网格点坐标(方位角,仰角)。
- 流程:
- 网格编码:使用与rMPE类似的正弦编码将角度坐标转换为固定维度的向量。
- 网络:经过一个简单的多层感知机(MLP),由3个线性层和ELU激活函数构成。
- 输出:每个候选DOA点对应一个维度为G的网格表示(GR)
G。该网络独立于音频和阵列几何,学习的是DOA方向的通用表示。
相似度计算与输出:
- 对齐:将AuGeonet输出的每个AGR向量(对应一个时间帧和输出层)与所有候选DOA的GR向量进行内积计算,并经过sigmoid函数。
- 输出:生成一个概率空间谱
S,其中每个值表示该网格点处存在声源的置信度。通过迭代峰值检测算法(算法2)即可得到最终的DOA估计。
关键设计动机:将表示解耦为与音频几何相关的A和与几何无关的G,通过相似度匹配,使得模型在推理时只需计算A,而G可以预计算缓存,且G的输入(网格点)可以任意更换,从而实现了网格灵活性。相对编码(rMPE)和自适应频率分析(LNuDFT)则旨在提供更符合声学物理规律、泛化性更强的特征表示,实现几何不变性。
💡 核心创新点
- 音频-几何-网格表示学习(AGG-RL)框架:首次提出将音频信号、阵列几何和DOA网格信息统一到一个表示学习框架中进行联合学习。通过将音频-几何表示(AGR)与网格表示(GR)在共享潜在空间对齐,突破了传统SSL方法对固定网格和固定阵列的限制,实现了“一次训练,网格灵活、几何不变”的通用定位。
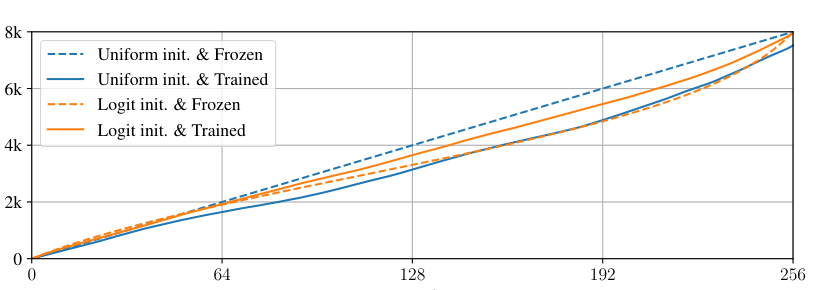
- 可学习非均匀离散傅里叶变换(LNuDFT):将传统的非均匀DFT中的频率bin位置参数化为可学习变量。这允许神经网络在训练过程中自适应地优化频率轴的采样策略,使其在物理上更具信息量的频率区域(如相位变化剧烈但未发生混叠的中高频区)分配更密集的bin,从而增强了相位特征的区分性和鲁棒性(如图3所示)。
- 相对麦克风位置编码(rMPE):针对声源定位中TDOA/IPD仅依赖麦克风相对位置的物理事实,设计了相对于参考通道的位置编码方式。与绝对坐标编码相比,rMPE直接符合波动物理学原理,有助于模型学习到更纯粹、与绝对坐标系无关的几何特征,显著提升了对未见阵列的泛化能力(表3消融实验(ii))。
- 物理信息引导的归纳偏置:LNuDFT和rMPE共同体现了“物理信息机器学习”的思想。它们不是完全由数据驱动从头学习,而是将声波传播、傅里叶分析等已知物理规律作为结构性约束和先验知识嵌入模型设计,引导学习朝向物理上有意义且泛化性更强的表示,提高了模型的可解释性和样本效率。
🔬 细节详述
- 训练数据:使用合成数据进行训练。数据集:语音来自LibriSpeech(训练/验证),噪声来自MS-SNSD(训练/验证)。规模:训练集在每个epoch动态生成28,800个4秒样本。预处理:重采样至16kHz,裁剪或填充至4秒。数据增强:在合成时,随机采样房间尺寸、RT60、麦克风阵列几何(4-12通道,动态生成)、声源位置、信噪比、信干比等参数,实现极大的数据多样性。阵列几何根据通道数C,随机生成,麦克风间距受公式(23)约束。
- 损失函数:采用加权二元交叉熵损失(公式22)。作用:训练模型输出概率空间谱与软标签(Oracle空间谱)一致。权重
ρ=2,用于平衡正负样本(真实声源方向与其他方向)。软标签由不同波束宽度的Oracle空间谱生成(附录A.6),实现了深度监督课程学习(DSCL),先学习粗略空间分布,再逐步细化。 - 训练策略:
- 优化器:Adam,梯度裁剪上限为1。
- 学习率:初始为
1e-3,采用自适应衰减策略:若验证损失连续2个epoch未改善,则衰减为原来的0.9。 - 批量大小:大部分模型为16,Neural-SRP为1。
- 训练轮数:最多300个epoch,结合多阶段几何学习(MSGL)策略。前10轮在固定四面体阵列(4通道)上训练,11-20轮在动态4通道阵列上训练,21-300轮在动态4-12通道阵列上训练,各阶段有特定的学习率和权重衰减(表6)。
- 关键超参数:AuGeonet中,特征维度M=128,rMPE缩放因子α=7,频率因子β=4,输出层O=3,最终表示维度G=256。LNuDFT初始化参数
ε_start=0.15,ε_end=0.95,训练约束ε_min=0.01,ε_max=100。Gridnet层数B=3,调制频率ξ=1。评估用Fibonacci网格点数D=2048。 - 训练硬件:在单张NVIDIA RTX 3090或4090 GPU上训练。
- 推理细节:使用训练好的模型直接推理。对于预测的空间谱,使用迭代最大峰值选择算法(算法2),设置角距边距
L=10°,提取多个声源的DOA。 - 正则化技巧:除了MSGL和DSCL训练策略,还使用了批归一化(BN)和层归一化(LN),以及ELU激活函数。
📊 实验结果
论文在四个评估数据集(NAO robot(真实,已见)、Eigenmike(真实,未见)、Dynamic-S(合成,已见通道数)、Dynamic-U(合成,未见通道数))上进行了全面比较,基线包括传统方法(MUSIC, SRP-PHAT)和最新DNN方法(Unet, Neural-SRP, GI-DOAEnet)。
主要性能对比(表3):
| 方法 | NAO robot | Eigenmike | Dynamic-S | Dynamic-U | ||||
|---|---|---|---|---|---|---|---|---|
| MAE↓ | ACC10↑ | MAE↓ | ACC10↑ | MAE↓ | ACC10↑ | MAE↓ | ACC10↑ | |
| MUSIC(512) | 20.63 | 64.95 | 29.93 | 36.37 | 30.35 | 27.94 | 27.13 | 33.20 |
| SRP-PHAT(2048) | 21.77 | 67.84 | 26.88 | 53.22 | 43.89 | 25.10 | 38.40 | 32.39 |
| Unet | 10.89 | 86.25 | 14.89 | 65.82 | 19.94 | 58.88 | 19.15 | 60.57 |
| Neural-SRP | 9.72 | 78.66 | 52.75 | 22.16 | 19.60 | 52.32 | 21.18 | 45.51 |
| GI-DOAEnet_FM | 11.31 | 77.36 | 93.61 | 0.00 | 15.49 | 64.36 | 54.81 | 6.10 |
| Proposed | 8.25 | 90.78 | 11.24 | 72.17 | 10.32 | 77.34 | 14.12 | 63.17 |
关键结论:
- 所提方法在所有数据集和指标上均取得最优,尤其是在未见阵列(Eigenmike)上优势巨大(MAE降低约3.65°,ACC10提高6.35%),证明了其卓越的泛化能力。
- GI-DOAEnet在未见阵列上性能崩溃(ACC10接近0),突显了传统绝对位置编码对新阵列的脆弱性。
- 为Unet和Neural-SRP添加AGG-RL模块(表中“with AGG-RL”行)能提升其泛化性,但整体仍不及所提完整方法,表明端到端的联合学习更优。
消融实验与分析:
- 组件有效性(表3下半部分):
- 将rMPE替换为PM版本((i)),性能略有下降,说明FM编码更优。
- 去除GCC-PHAT和rMPE,使用标准DFT和aMPE((ii)),性能在未见数据上急剧下降,证实了相对表示的关键作用。
- 去除LNuDFT(使用标准DFT)((iii)),性能下降,验证了自适应频率分析的价值。
- 对比LNuDFT的不同初始化策略((iv),(v)),发现提出的Logit初始化((v))在未见动态阵列(Dynamic-U)上表现最佳,说明合理的初始化有助于泛化。
- 网格灵活性(表4):随着网格点数D从128增加到16384,性能先快速提升后趋于平稳。在D>=512后性能已稳定,且在真实数据上D过大(>2048)时性能可能轻微下降,表明框架确实支持灵活的网格选择,且存在一个“最佳”分辨率范围。
不同环境条件下的鲁棒性:图9显示,所提方法在各种SNR和RT60条件下均优于基线(Unet with AGG-RL, Neural-SRP with AGG-RL),展示了在噪声和混响环境中的稳健性。

定性结果可视化:图10-13展示了空间谱。与基线方法相比,所提方法生成的谱峰值更尖锐、更稳定,与真实声源位置(Oracle)高度吻合,尤其在处理多声源和未见阵列时,表现出更好的分辨能力和鲁棒性。

⚖️ 评分理由
- 学术质量:6.0/7 - 论文针对SSL领域的核心泛化性问题,提出了一个设计精巧、物理原理清晰的完整解决方案(AGG-RL)。创新点明确(框架、LNuDFT、rMPE),技术实现严谨。实验设计全面,包含多种基线、消融研究、不同条件分析和可视化,数据充分支持结论。扣分点在于,对于更极端的场景(如超密集网格)的讨论可以更深入,且部分超参数选择缺乏更广泛的敏感性分析。
- 选题价值:1.5/2 - 声源定位是空间音频感知的基础,其通用化和鲁棒性是落地应用的关键瓶颈。本文的研究方向具有明确的实际需求和前沿性,对机器人、智能设备等领域的研发人员有直接参考价值。任务本身属于音频处理的一个专门分支,受众相对语音识别等更广义的任务稍窄。
- 开源与复现性:0.7/1 - 论文明确提供了开源代码链接(https://github.com/BaekMS/Audio-Geometry-Grid_Representation-Learning),并在附录中给出了极其详尽的训练细节、超参数、数据生成算法等,可复现性很高。未明确提及是否提供预训练模型权重,略微影响快速验证的便利性。