📄 Pay Attention to CTC: Fast and Robust Pseudo-Labelling for Unified Speech Recognition
#语音识别 #CTC #注意力机制 #半监督学习 #音视频
🔥 8.0/10 | 前10% | #语音识别 | #CTC #注意力机制 | #CTC #注意力机制
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Alexandros Haliassos(NatWest AI Research, Imperial College London)
- 通讯作者:未说明
- 作者列表:Alexandros Haliassos(NatWest AI Research, Imperial College London), Rodrigo Mira(NatWest AI Research), Stavros Petridis(NatWest AI Research, Imperial College London)
💡 毒舌点评
这篇论文通过巧妙地将CTC的快速鲁棒解码与Teacher Forcing结合,一举解决了原USR框架中自回归伪标签生成缓慢且易受分布偏移影响的痛点,同时通过混合采样策略平衡了训练与测试的差异,是典型的“工程智慧”推动方法进步的案例;但其核心贡献更偏向于训练策略的优化而非模型架构的根本性突破,且混合采样策略带来的增益在消融实验中并不总是显著。
🔗 开源详情
- 代码:论文提及代码仓库链接为
https://github.com/ahaliassos/usr。 - 模型权重:未明确提及是否公开USR 2.0的预训练或微调模型权重。
- 数据集:论文使用了多个公开数据集(LRS3, LRS2, VoxCeleb2, AVSpeech, LibriSpeech, WildVSR),并说明了其获取与使用方式。未提及新发布数据集。
- Demo:未提及。
- 复现材料:论文附录提供了详细的实验设置(数据集、预处理、模型变体、训练超参数),并指出训练配置、数据集准备和评估代码包含在补充材料中。
- 引用的开源项目:AV-HuBERT, BRAVEn, USR(原始版本),ESPnet。
📌 核心摘要
- 问题:现有的统一语音识别(USR)框架通过自回归解码生成注意力分支的伪标签,导致训练效率低下(自回归是瓶颈),且CTC和注意力分支的解耦监督使其在分布外数据(如长语音、噪声、跨域数据)上鲁棒性差,容易因自回归错误累积而性能下降。
- 方法核心:提出USR 2.0,其核心是CTC驱动的Teacher Forcing:教师模型用贪心CTC解码生成伪标签,然后将其作为解码器输入,通过单次前向传播并行生成注意力伪标签,避免了自回归解码。这使得CTC和注意力伪标签长度对齐,学生解码器可以同时预测两者,从而耦合两个分支。此外,为缓解训练-测试不匹配(训练时用CTC输入,推理时自回归),引入混合采样策略,在训练时以50%概率交替使用标准AR模式和CTC驱动模式。
- 与已有方法相比新在哪里:与USR相比,USR 2.0将伪标签生成从耗时的逐token自回归解码变为一次性的Teacher Forcing并行解码,速度大幅提升。同时,它改变了监督范式:在CTC驱动模式下,解码器同时被CTC和注意力伪标签监督,使注意力分支获得了CTC的鲁棒性。在AR模式下,CTC分支则被两种伪标签监督,实现了信息互补。
- 主要实验结果:
- 训练效率:训练时间减少约2倍(见图5)。
- 鲁棒性:在长语音(VoxCeleb2)上,USR 2.0的WER显著低于USR等基线(见图3);在噪声环境(LRS3加噪)和多个OOD数据集(LibriSpeech, WildVSR, AVSpeech)上均大幅超越原始USR和自监督基线(见表1,表3)。
- 性能:在LRS3、LRS2和WildVSR数据集上,USR 2.0(Huge模型)使用单一统一模型在ASR、VSR和AVSR任务上均达到或超越当时的最优水平(SOTA)。关键数据如下表所示:
| 数据集 | 方法 | VSR WER (%) | ASR WER (%) | AVSR WER (%) |
|---|---|---|---|---|
| LRS3 (Base, Low-res) | USR | 36.0 | 3.2 | 3.0 |
| USR 2.0 | 36.2 | 3.0 | 2.9 | |
| LRS3 (Large, High-res) | USR | 26.9 | 2.4 | 2.4 |
| USR 2.0 | 23.7 | 2.3 | 2.2 | |
| LRS3 (Huge) | USR 2.0 | 17.6 | 0.9 | 0.8 |
| LRS2 (Large) | USR | 22.3 | 1.2 | 1.1 |
| USR 2.0 | 21.5 | 1.3 | 1.0 | |
| WildVSR (Large) | USR | 46.4 | - | - |
| USR 2.0 | 38.5 | - | - |
- 实际意义:USR 2.0显著提升了统一语音识别模型的训练效率与在复杂真实场景下的鲁棒性,使其更实用。单一模型处理ASR/VSR/AVSR任务降低了部署复杂度。该训练范式(CTC驱动的Teacher Forcing与混合采样)也可推广至其他序列到序列的自训练任务。
- 主要局限性:
- 相比完全监督的微调方法,其整体训练时长仍然较长。
- 对于ASR和AVSR等本身性能已很高的任务,性能提升更多依赖无标签数据质量,而非数量,当前使用的贪心解码伪标签可能限制其上限。
- CTC驱动的Teacher Forcing生成的注意力伪标签在序列层面可能缺乏全局连贯性,但这在自训练框架下被证明是可接受的。
🏗️ 模型架构
本文的核心贡献在于改进训练时的伪标签生成与监督策略,而非改变基础模型架构。其基础架构沿用了原始USR(Haliassos et al., 2024a)的设计:一个共享的Transformer编码器,配备模态特定的ResNet-18前端,以及两个输出头——CTC层和基于注意力的Transformer解码器。
完整的输入输出流程(以AVSR为例):
- 学生模型输入:对未标记的音视频数据,学生模型接收经过掩码处理的音频和视频特征(掩码用于强制模型理解上下文)。
- 学生模型处理:特征通过模态特定的前端网络投影到共享维度,连接后输入Transformer编码器,得到统一的表示。
- 学生模型输出:编码器表示分别送入CTC层和Transformer解码器。解码器在CTC驱动模式下,还额外接收由教师模型CTC分支生成的伪标签作为输入。
- 教师模型输入:对相同的未标记数据,教师模型接收未经掩码的原始音视频特征,以保证伪标签质量。
- 教师模型处理:经过与学生相同的编码器(但参数为学生模型的指数滑动平均)。
- 教师模型输出与伪标签生成(核心创新):
- CTC伪标签:教师编码器输出经CTC层,通过贪心解码和“合并与折叠”操作,生成长度为UCTC的伪标签序列
y_tilde^CTC。 - 注意力伪标签(USR 2.0模式):不再进行自回归解码。而是将
y_tilde^CTC作为教师解码器的输入,通过单次前向传播(Teacher Forcing),并行生成长度为UCTC的注意力伪标签序列y_tilde^Att。这保证了两种伪标签长度对齐。
- CTC伪标签:教师编码器输出经CTC层,通过贪心解码和“合并与折叠”操作,生成长度为UCTC的伪标签序列
- 损失计算与更新:学生模型用其预测的CTC和注意力输出,去匹配教师生成的伪标签
y_tilde^CTC和y_tilde^Att。根据当前是“CTC驱动模式”还是“AR模式”,损失函数的监督目标有所不同(详见第4.2节公式5与6)。教师参数通过指数滑动平均从学生更新。
关键设计选择与动机:
- CTC驱动的Teacher Forcing:动机是消除自回归解码这一训练瓶颈,并将CTC的鲁棒性(单调对齐、条件独立)转移到注意力分支。虽然生成的注意力序列可能不连贯,但在自训练场景下,学生和教师基于相同的CTC前缀进行条件预测,保证了知识的有效传递。
- 混合采样:动机是缓解因教师使用CTC输入、而学生在推理时需自回归所导致的“暴露偏差”。通过随机切换到标准AR模式(使用真实或自回归解码的伪标签),让解码器在训练时也接触其自身可能生成的输入模式。
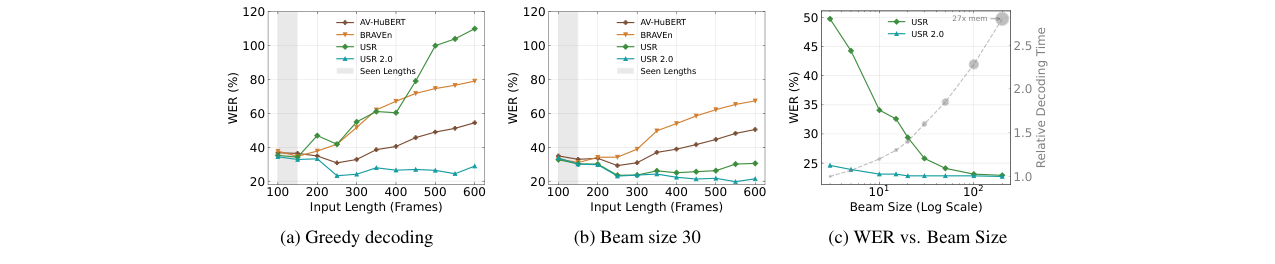
图2:展示了原始USR(左)与USR 2.0的两种模式(中:CTC驱动模式,右:AR模式)在伪标签生成与学生模型监督方式上的核心区别。
💡 核心创新点
CTC驱动的Teacher Forcing伪标签生成:
- 局限:原始USR使用自回归解码生成注意力伪标签,速度慢且易因分布偏移产生累积错误。
- 创新:利用教师模型的贪心CTC输出作为固定前缀,通过Teacher Forcing单次前向传播并行生成注意力伪标签,将生成速度从
O(U)(序列长度)提升至O(1)。这不仅解决了效率问题,还将CTC的鲁棒性间接传递给了注意力分支。 - 收益:训练速度提升约2倍,且在分布外数据(长语音、噪声)上性能显著提升。
耦合分支的双重监督:
- 局限:原始USR中CTC和注意力分支各自独立地用对应的伪标签进行监督,属于解耦监督。
- 创新:在CTC驱动模式下,学生解码器同时被CTC伪标签和注意力伪标签进行监督(损失函数为两者加权和)。这迫使解码器学习一个更鲁棒的映射:既能产生注意力表达的细节,又能遵循CTC提供的稳定对齐。
- 收益:增强了注意力解码器对分布偏移的抵抗力,减少了对昂贵束搜索的依赖(见图3)。
混合采样策略平衡训练与测试:
- 局限:完全使用CTC输入进行Teacher Forcing会导致训练与自回归推理之间的不匹配。
- 创新:以固定概率(0.5)随机切换训练模式。在CTC驱动模式下,解码器学习从CTC前缀预测;在AR模式下,解码器像原始USR一样从自身或真实标签预测。这本质上是一种针对“伪标签来源不匹配”的计划采样。
- 收益:在保持OOD鲁棒性的同时,缓解了训练-测试差异,微调了ID与OOD性能的平衡(见图4)。
🔬 细节详述
- 训练数据:
- 有标签数据:低资源设置:LRS3的30小时“trainval”分区;高资源设置:LRS3的433小时。
- 无标签数据:LRS3剩余数据、VoxCeleb2的英文子集(1326小时)、AVSpeech过滤后的英文子集(1327小时)。
- 预处理:视频帧稳定、裁剪(96x96)、转灰度。音频无预处理。学生输入使用时间零掩码(视频最大0.4s,音频最大0.6s)。
- 损失函数:
- 标记数据:标准的联合CTC-注意力损失:
L = λ L_CTC + (1-λ) L_Att,其中λ=0.1,注意力损失使用标签平滑(0.1)。 - 无标签数据:根据模式(公式5与6),加权组合CTC和注意力交叉熵损失。权重
λ_CTC=0.1,模态权重w_A=w_AV=0.7,w_V=0.3。无标签与标记损失比γ_A=γ_AV=0.75,γ_V=0.97。
- 标记数据:标准的联合CTC-注意力损失:
- 训练策略:
- 优化器:AdamW (
β1=0.9,β2=0.98,weight_decay=0.04)。 - 调度:15个epoch线性warmup,然后余弦衰减,共训练50个epoch。
- 正则化:Drop Path(Base模型0.1,Large模型0.2,Huge模型0.3),梯度裁剪(阈值3.0)。
- 置信度过滤:序列级阈值
τ=0.8,过滤低置信伪标签。
- 优化器:AdamW (
- 关键超参数(模型大小):
- Base: 86M参数,12/6 Transformer层,维度512。
- Base+: 171M参数,12/6 Transformer层,维度768。
- Large: 503M参数,24/9 Transformer层,维度1028。
- Huge: 953M参数,36/9 Transformer层,维度1280。
- 训练硬件:Base模型在8块H200 GPU上训练约1天;Base+在32块GPU上训练约2天;Large在32块GPU上训练约3天;Huge在64块GPU上训练约4天。
- 推理细节:除非特别说明,均使用联合CTC-注意力解码(ESPnet),束大小为40,CTC权重为0.1,使用1000 token的SentencePiece词汇表。
📊 实验结果
论文在多个基准数据集和多种条件下进行了全面的实验验证。
- 分布外鲁棒性(关键证据)
- 长语音鲁棒性(图3):在自动转录的VoxCeleb2测试集上,USR 2.0(Base模型)在贪心解码下,随着输入长度增加,WER上升缓慢,显著优于USR、BRAVEn和AV-HuBERT。即使使用束大小为30的解码,USR 2.0仍优于USR,且在小束大小下优势更明显(图3c)。
- 噪声鲁棒性(表1):在LRS3测试集添加不同SNR的NOISEX噪声。对于长语音样本(>100帧),USR 2.0在所有SNR下均显著优于所有基线。例如,在0dB SNR下,AVSR的WER:USR 2.0为10.8%,USR为12.0%,BRAVEn为26.4%。
- 跨数据集OOD测试(表3):在LibriSpeech、WildVSR和AVSpeech上进行零样本评估(贪心解码)。USR 2.0在所有三个数据集上都大幅领先。例如,在WildVSR VSR任务上,USR 2.0的WER为73.7%,远低于USR的80.0%。
长语音鲁棒性实验结果对比图] 图3:展示了不同模型在VoxCeleb2数据集上,WER随输入帧数变化的对比。USR 2.0在长语音上表现出最强的鲁棒性。
混合采样概率消融实验结果图] 图4:展示了改变AR模式采样概率对ID(LRS3)和OOD(AVSpeech)性能以及训练时间的影响。概率0.5是效率与性能的平衡点。
分布内性能(表2) 在LRS3基准测试上,USR 2.0在各种资源设置下均达到或超越SOTA。特别是在使用VoxCeleb2无标签数据预训练后,增益更为明显。例如,在Large模型高资源设置下,AVSR WER:USR 2.0为2.2%,优于AV-data2vec的2.7%和BRAVEn的2.4%。
训练效率(图5) 在VSR任务上,USR 2.0的WER-训练时间曲线始终位于USR下方,达到相同性能所需时间约为USR的一半。这源于更快的训练步骤(CTC-driven Teacher Forcing)和更快的收敛(所需epoch数更少)。
消融实验(表4与表10)
- CTC驱动模式:解码器同时预测CTC和注意力伪标签对ID和OOD性能都至关重要(表4)。
- AR模式:CTC分支同时被两种伪标签监督,且注意力分支只被注意力伪标签监督是最佳配置。
- 混合采样概率(图4):概率0.5在ID性能、OOD鲁棒性和训练时间之间取��了良好平衡。
- 损失权重(表10a, 10b):调整辅助伪标签的损失权重可以权衡ID准确性和OOD鲁棒性。
⚖️ 评分理由
- 学术质量:6.0/7 - 论文针对现有框架的具体痛点提出了清晰、有效的解决方案(CTC-driven Teacher Forcing,耦合监督,混合采样)。技术实现正确,逻辑自洽。实验设计全面,覆盖了不同规模、资源、数据集和评估条件,消融实验充分。所有结论都有扎实的数据支撑。创新点在于对现有组件的巧妙组合与训练策略的重新设计,而非提出全新的基础模块。
- 选题价值:1.5/2 - 统一语音识别(USR)是当前语音领域的重要前沿方向,旨在用单一模型处理多种模态和任务。论文解决了该方向实用化的两个核心障碍(效率与鲁棒性),其改进对于推动多模态语音处理技术的实际部署具有重要价值。相关性高。
- 开源与复现加成:0.5/1 - 论文在附录或正文中提供了代码仓库链接(
https://github.com/ahaliassos/usr),并详细说明了实验设置、超参数和数据集处理。这为复现提供了良好基础。但未明确提及是否公开预训练模型权重,扣0.5分。