📄 ParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
#语音对话系统 #强化学习 #语音大模型 #语音合成 #基准测试
🔥 8.0/10 | 前25% | #语音对话系统 | #强化学习 | #语音大模型 #语音合成
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Shu-wen Yang(台湾大学通讯工程研究所)
- 通讯作者:Ming Tu(字节跳动 Seed),Lu Lu(字节跳动 Seed)
- 作者列表:Shu-wen Yang(台湾大学通讯工程研究所,字节跳动 Seed†),Ming Tu(字节跳动 Seed†),Andy T. Liu(字节跳动 Seed),Xinghua Qu(字节跳动 Seed),Hung-yi Lee(台湾大学通讯工程研究所),Lu Lu(字节跳动 Seed†),Yuxuan Wang(字节跳动 Seed),Yonghui Wu(字节跳动 Seed)
💡 毒舌点评
亮点:论文系统性地定义了副语言感知的S2S交互评估难题,并构建了从基准测试到自动评测再到强化学习训练的完整闭环,其提出的“PolyTone”训练策略和多阶段评测框架有效缓解了音频大模型的风格幻觉问题,实验结果令人信服。短板:整个框架高度依赖复杂的多阶段流程和多个外部模型(如Whisper, AudioReasoner, Qwen2.5-Omni),虽然论文提供了蒸馏后的奖励模型方案,但最终模型的轻量化和部署效率存在疑问,且核心RL方法(GRPO)并非原创。
🔗 开源详情
- 代码:论文明确承诺开源代码(项目页面:https://paras2sbench.github.io/),但未在文中提供具体GitHub仓库链接。
- 模型权重:承诺开源模型(文中提到“开源…模型”),但未具体说明开源哪个阶段的模型(SFT模型、奖励模型还是RL模型)。
- 数据集:承诺开源ParaS2SBench基准测试数据集以及用于训练的合成数据。
- Demo:项目页面提供演示。
- 复现材料:提供了详细的数据构建步骤(附录A.2)、评测器细节(附录A.3)、RL框架公式化(附录A.4)、消融实验设置(附录A.5)、人工评测说明(附录A.6)、以及所有用于数据生成和评测的Prompt模板(附录A.8),复现信息较为充分。
- 引用的开源项目:依赖Whisper-V3(转录)、AudioReasoner(语气提取)、Emotion2vec(情绪分���)、Qwen2.5-Omni(奖励模型基础)、Kimi-Audio(S2S基础模型)、CosyVoice/YourTTS(语音合成)等多个开源项目。
📌 核心摘要
这篇论文针对现有语音到语音(S2S)模型无法根据用户语音中的副语言特征(如情绪、语气、年龄、性别)生成合适内容和风格回应的问题,提出了一个完整的解决方案框架ParaS2S。首先,论文构建了首个直接评估波形级S2S交互自然度的基准测试ParaS2SBench,它包含合成和真实语音查询,每个查询都设计了对比性的说话风格,要求模型必须“听”音频而非仅依赖文本内容。其次,针对当前端到端音频大模型(ALLM)作为评测器会产生的风格幻觉问题,论文提出了一个基于“PolyTone”训练策略的多阶段自动评测器,通过将内容和风格分析解耦,其与人类评分的相关性显著优于ALLM基线(Pearson相关性高出10%-15%)。最后,论文利用该自动评测器指导强化学习(RL)训练流程ParaS2SAlign,通过一个轻量级的SFT热启动和奖励模型蒸馏,在仅使用10小时配对数据的情况下,使基础模型(Kimi-Audio)在ParaS2SBench上的性能比纯SFT方法提升了10%以上,并超越了所有已有的开源和闭源模型。实验表明,RL方法在数据效率上远优于SFT,且能保持模型原有的通用对话能力。主要局限性在于框架复杂,且副语言交互评估本身依赖于多个组件的准确性。
🏗️ 模型架构
ParaS2S并非一个单一模型,而是一个包含数据构建、评测和训练的完整框架。其核心架构和流程如下:
ParaS2SBench (基准测试构建):
- 查询生成流程:使用LLM生成包含“中性内容”和“两个对比性说话风格”的查询(如“我刚遇到前任”,语气为惊喜/悲伤)。然后通过LLM进行过滤(中立性、合理性、副语言相关性测试)。最后,使用最合适的TTS系统(如gpt-4o-mini-tts用于情感,CosyVoice用于性别/年龄)合成查询语音,并用Emotion2vec和WER进行过滤,辅以人工审核。
- 评测流程:自动评测器采用多阶段架构:(1) 使用Whisper-V3获取转录文本。(2) 使用专门训练(PolyTone)的声学分析师提取输入/输出的性别、年龄、情绪、讽刺标签。(3) 使用AudioReasoner提取输出语音的“语气”描述文本。(4) 将上述所有文本信息输入LLM(如ChatGPT),根据专家设计的指南(附录A.8.5)在1-5分尺度上评分。
ParaS2SAlign (对齐训练框架):
- S2S模型:论文以Kimi-Audio为基础模型,它是一个双头(文本/音频)自回归模型,输入语音和文本嵌入求和后进入Transformer。
- 训练流程:
- 阶段1:SFT热启动:使用构建的指令-响应配对数据(约100小时)对基础模型进行少量(2个epoch)微调,使其初步具备副语言感知能力,以便后续采样出质量尚可的响应。
- 阶段2:奖励模型蒸馏:用热启动模型对大量查询生成多个候选响应,并用完整的多阶段自动评测器(O5配置,无需真实标签)打分,构建偏好数据集。然后,用LoRA微调一个Qwen2.5-Omni作为奖励模型,输入为(查询语音, 响应语音, 评分指南),输出一个分数。
- 阶段3:GRPO强化学习:在未标注的语音数据上,使用GRPO算法优化策略模型。具体是,对每个查询采样一组(G=8)响应,用奖励模型打分计算归一化优势,然后通过策略梯度更新模型,并引入KL散度惩罚防止偏离原始模型太远。
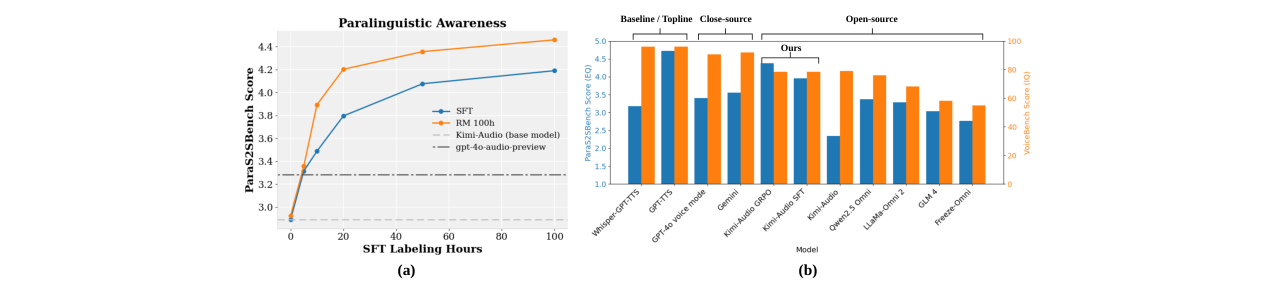
图1:ParaS2S整体框架图。底部展示了ParaS2SBench的数据集构建和自动评测器流程;顶部展示了ParaS2SAlign中的奖励模型蒸馏过程。蒸馏出的奖励模型可用于PPO、GRPO等标准RL算法。
💡 核心创新点
- 首个波形级副语言感知S2S基准测试 (ParaS2SBench):与以往仅评估输出文本的基准不同,它直接评估输入输出语音对在内容和风格上的自然度,其“对比说话风格”的设计能有效检测模型的“音盲”问题。
- 抗风格幻觉的多阶段自动评测器:通过PolyTone训练(使用内容相同、风格不同的语音)训练专用的声学分析器,并将内容与风格分析解耦,构建了一个比端到端ALLM更可靠、与人类评分相关性更高的自动评测器。这是后续所有训练的基础。
- 基于可扩展AI反馈的RL对齐框架 (ParaS2SAlign):首次将强化学习应用于副语言感知的S2S对话建模,并设计了“SFT热启动-奖励模型蒸馏-GRPO训练”的两阶段流程。该方法能从无标注的未配对语音中学习,显著减少了对昂贵配对演示数据的依赖(仅需10小时热启动数据即可达到纯SFT用5倍数据的效果)。
🔬 细节详述
- 训练数据:
- PolyTone训练数据:为训练情绪、讽刺、性别、年龄分类器生成,每个类别1万条语音,内容相同风格不同。
- SFT/热启动数据:构建约1万条语音提示,每条对应一个LLM生成并由TTS合成的响应,共约100小时。训练时用于2个epoch的热启动。
- 奖励模型蒸馏数据:使用热启动模型对约1万条提示,每条生成32个候选响应,共约32万对(提示,响应,分数)三元组。
- RL训练数据:使用所有语音提示(约10万条),但仅使用语音,丢弃所有标签。
- 损失函数:
- SFT和奖励模型微调:标准的下一个token预测交叉熵损失。
- GRPO:基于策略梯度的目标函数(公式3),包含重要性采样比、裁剪项和KL散度惩罚项(公式4)。
- 训练策略与超参数:
- SFT:8x H100 GPU,FSDP,学习率1e-5,全局batch size 64,训练2个epoch。
- 奖励模型LoRA:1x H100 GPU,学习率1e-6,batch size 10。
- GRPO:8x H100 GPU,FSDP,学习率5e-4,全局查询batch size B=32,组大小G=8(每个batch共256个评分完成),KL权重β=0.2。
- 关键超参数:基础模型为Kimi-Audio(未说明具体参数量)。奖励模型基于Qwen2.5-Omni并使用LoRA适配器。
- 训练硬件:主要使用NVIDIA H100 GPU(8卡用于SFT和RL,单卡用于PolyTone训练和奖励模型微调)。
- 推理细节:S2S模型(如Kimi-Audio)使用流匹配解码器将音频token解码为波形。评测时使用Whisper-V3转录,AudioReasoner生成语气描述。RL训练时采用高采样温度以增加响应多样性。
- 正则化:在GRPO中使用KL散度惩罚(β=0.2)以保持原始能力,防止灾难性遗忘。
📊 实验结果
论文通过在ParaS2SBench(合成和真实语音)上的自动评分和人工评分验证了框架的有效性。
表4:在ParaS2SBench上的性能对比(自动评测器评分,1-5分)
| 模型 | 合成语音(平均) | 真实语音(IEMOCAP + MELD平均) | 总平均 |
|---|---|---|---|
| 基线 (Whisper-GPT-TTS) | 3.022 | 3.487 | 3.176 |
| 闭源模型 | |||
| gpt-4o-audio-preview | 3.284 | 3.639 | 3.403 |
| Gemini | 3.447 | 3.762 | 3.552 |
| 开源模型 | |||
| Qwen2.5 Omni | 3.248 | 3.612 | 3.369 |
| GLM-4-Voice | 3.033 | 3.037 | 3.034 |
| LLaMa-Omni 2 | 3.215 | 3.443 | 3.291 |
| Freeze-Omni | 2.680 | 2.948 | 2.769 |
| Kimi-Audio (基础模型) | 2.892 | 1.265 | 2.350 |
| 本文方法 | |||
| Kimi-Audio SFT | 4.076 | 3.714 | 3.955 |
| Kimi-Audio GRPO | 4.441 | 4.161 | 4.382 |
| 上行线 (GPT-TTS) | 4.705 | 4.766 | 4.725 |
关键结论:GRPO模型在总平均分上比SFT模型提升了10%以上,比基础模型提升了86%,并超越了所有现有模型。基础模型(Kimi-Audio)在真实语音(特别是MELD数据集)上表现很差,凸显了问题。
表3:自动评测器与人类评分在响应排序上的一致性(部分结果)
| 响应类型 | 模型 | 自动评分 (平均) | 人类评分 (平均) |
|---|---|---|---|
| TTS (好) | gpt-4o-mini-tts | 4.649 (1) | 4.469 (1) |
| TTS (坏) | gpt-4o-mini-tts (bad) | 1.227 (8) | 1.265 (8) |
| S2S模型 | gpt-4o-audio-preview | 3.077 (6) | 2.909 (5) |
| S2S模型 | Qwen2.5 Omni | 3.113 (5) | 2.863 (6) |
关键结论:自动评测器对模型和响应的排序与人类高度一致,验证了其作为代理的可靠性。
图2(a):不同标注数据量下RL与SFT的效果对比(消融实验)
图2(a):展示了在不同大小的SFT热启动数据上,进行GRPO后训练与纯SFT训练的性能对比。关键结论是:RL(GRPO)在不同数据量下均能稳定提升SFT模型的性能,且仅用20小时热启动数据+RL就能超过用完整100小时数据训练的SFT模型,证明了RL的数据效率。
表2:自动评测器与人类评分的相关性对比(Pearson)
| 方法 | 平均相关性 |
|---|---|
| 基线 (gpt-audio) | 0.618 |
| 本文多阶段评测器 (O2, 使用风格描述) | 0.776 |
| 本文多阶段评测器 (O5, 使用预测标签) | 0.723 |
关键结论:多阶段评测器显著优于端到端ALLM基线。使用自然语言“语气描述”比使用离散“情绪标签”更能捕捉响应风格。
⚖️ 评分理由
- 学术质量 (6.5/7):论文工作完整、系统,从问题定义、基准构建、评测器设计到训练框架均有清晰阐述和扎实实验。创新点明确(基准、抗幻觉评测器、RL框架),技术路线正确。消融实验充分(评测器对比、GRPO参数、数据效率)。但核心RL方法(GRPO)是直接应用,主要创新在于将其适配到S2S副语言任务并构建了配套的自动化奖励生成流程。
- 选题价值 (1.0/2):副语言感知的S2S交互是构建自然、共情语音助手的关键难题,该研究填补了该领域缺乏系统评估和有效优化方法的空白,具有明确的学术价值和应用潜力。但研究问题相对垂直。
- 开源与复现加成 (0.5/1):论文明确承诺开源数据、代码和模型,这极大地提升了工作的可复现性和社区影响力。附录提供了详细的数据构建流程、评测指南和超参数。主要扣分点是论文本身并未给出代码仓库的最终URL,但承诺了会开源。