📄 OWL : Geometry-Aware Spatial Reasoning for Audio Large Language Models
#音频大模型 #空间音频 #声源定位 #多任务学习 #数据集
🔥 8.0/10 | 前25% | #空间音频 | #音频大模型 | #声源定位 #多任务学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文标注Subrata Biswas和Mohammad Nur Hossain Khan为共同第一作者)
- 通讯作者:未说明
- 作者列表:Subrata Biswas(Worcester Polytechnic Institute电气与计算机工程系)、Mohammad Nur Hossain Khan(Worcester Polytechnic Institute电气与计算机工程系)、Bashima Islam(Worcester Polytechnic Institute电气与计算机工程系)
💡 毒舌点评
这篇论文为音频大模型装上了“空间几何眼睛”,通过“模拟训练-纯音频推理”的巧思和详实的课程学习,确实把空间定位和推理精度提升了一个台阶;但美中不足的是,其所有辉煌战绩(包括新建的百万级数据集)均建立在精心构建的合成世界里,在真实嘈杂、反射复杂的声学环境中,这套“几何内功”的实战效果还有待“出关”检验。
🔗 开源详情
- 代码:论文明确提供代码仓库链接:https://github.com/BASHLab/OWL。表明将在该仓库发布代码。
- 模型权重:未明确提及是否公开预训练模型权重,但根据“our dataset and code are available”的表述,模型权重可能包含在开源计划内。
- 数据集:论文明确表示将发布BiDepth数据集(“we construct and release BiDepth”),包含约110万QA对。
- Demo:未提及在线演示。
- 复现材料:附录提供了完整的训练超参数(表10,表11)、特征提取公式(B.1)、模型架构细节(B.2, B.3)和数据集生成细节(A节),复现指引非常充分。
- 论文中引用的开源项目:依赖SoundSpaces v2.0和Matterport3D进行模拟;音频编码器初始化自AudioMAE;语言模型使用LLaMA-2-7B;投影模块参考Q-Former;微调使用LoRA。
📌 核心摘要
- 要解决什么问题:现有的音频大语言模型(ALLMs)在空间推理方面能力薄弱,主要依赖粗糙的双耳线索和单步推理,导致在声源方向(DoA)和距离估计上精度不足,且推理过程缺乏可解释性。
- 方法核心是什么:提出OWL框架,其核心是创新的几何感知音频编码器SAGE。SAGE在训练时利用全景深度图和模拟房间脉冲响应(RIR)作为监督信号,让编码器学会将声学特征与3D空间几何结构对齐,但在推理时只需音频输入。OWL进一步将SAGE与空间接地的链式思维(CoT) 推理相结合,支持从感知到多步推理的课程学习。
- 与已有方法相比新在哪里:首次将显式的几何监督(通过RIR预测任务)引入音频编码器训练;构建了首个大规模(约110万QA对)耦合双耳音频、RIR和深度图的数据集BiDepth用于几何感知训练;引入了针对音频空间推理的多阶段课程学习和CoT监督机制,使模型能生成可解释的推理路径。
- 主要实验结果如何:在BiDepth和SpatialSoundQA两个基准上,OWL显著超越了现有方法。SAGE相比SOTA(Spatial-AST),在BiDepth数据集上平均角度误差(MAE)降低25.52%,距离错误率(DER)降低31.34%。OWL相比BAT,在BiDepth上的空间推理二分类准确率(BA)提升24.9%(77.89% vs. 69.46%),在SpatialSoundQA上的推理平均准确率达79.06%(BAT为76.89%)。OWL在真实世界音频场景分类和声源定位任务上也展现出良好的泛化能力。
- 实际意义是什么:该工作推动了音频大模型从“听到什么”向“声音在哪里、如何关联”的空间理解迈进,为构建更接近人类听觉感知的智能系统(如机器人、智能家居助手、助听设备)提供了关键技术组件和评估基准。
- 主要局限性是什么:训练和评估严重依赖合成数据(BiDepth),而真实世界声学环境更为复杂多变,模型的鲁棒性有待验证;目前的推理任务限于单轮问答,尚未扩展到多轮对话式空间推理;几何监督依赖于预先生成的深度图和RIR,限制了其在完全未知环境中的应用。
🏗️ 模型架构
OWL是一个完整的空间音频问答系统,其架构(如图4所示)由三个主要部分串联而成,旨在将原始双耳波形转化为带有空间推理的文本输出。

空间声学几何编码器 (SAGE):这是系统的感知核心,负责从双耳音频中提取几何感知的声学特征。它包含两个在训练时联合优化、但在推理时分离的模块:
- 双耳音频编码器 (ϕ_a):输入双耳波形
B_r(t)。首先进行特征提取,得到4通道输入张量(左右耳梅尔谱、相位差正弦/余弦)。然后通过一个12层Transformer编码器处理,输出包含空间和语义线索的嵌入h_a。该编码器同时支持事件分类、DoA估计和距离预测三个任务。 - RIR预测模块:仅在训练时使用。它接收由ResNet-18编码的全景深度图特征
h_d,与音频特征h_a融合,再通过ResNet-18解码器重建双耳房间脉冲响应R。此模块作为辅助任务,为音频编码器提供几何监督。 训练目标:总损失L = η1 L_binaural + η2 * L_geo。其中L_binaural是音频感知任务(分类、距离、DoA)的交叉熵损失之和,L_geo是RIR重建损失(L1损失 + 可微分的EDC衰减曲线损失),用于衡量预测RIR与真实RIR在几何声学特性上的差异。
- 双耳音频编码器 (ϕ_a):输入双耳波形
投影模块 (ψ):采用Q-Former架构。它接收SAGE编码器输出的序列特征
h_a,通过8层交叉注意力机制和64个可学习查询(Query)令牌,将其投影为与语言模型嵌入空间对齐、且长度固定的令牌序列z_q。此模块实现了声学特征到语言空间的压缩与对齐。语言解码器 (Π):使用冻结的LLaMA-2-7B模型,并通过LoRA进行高效微调。它接收投影后的声学令牌
z_q和文本提示x_t,以自回归方式生成最终答案序列y。答案可以是事件类别、位置信息(如“3点钟;上方;3.5米”),或是包含推理步骤的链式思维(CoT)解释。
数据流:双耳音频 → SAGE音频编码器 → 声学特征 h_a → Q-Former投影器 → 语言对齐令牌 z_q → LLaMA-2解码器(结合文本提示)→ 文本答案。
💡 核心创新点
- 几何感知音频编码器 (SAGE):这是核心技术创新。通过引入辅助的RIR预测任务,将显式的几何监督(来自深度图和模拟RIR)注入音频编码器的训练过程,使编码器在无需深度输入的推理阶段也能理解声学信号与空间几何的关联。
- 大规模空间推理数据集 (BiDepth):构建了首个将双耳音频、双耳RIR、全景深度图和QA标注四元组配对的大规模(≈1.1M QA对)合成数据集,为训练和评估几何感知的音频模型提供了前所未有的资源。
- 空间接地的链式思维 (CoT):首次为音频大模型引入针对空间推理的CoT监督。模型不再直接输出判断,而是先定位声源(如“声源A在8点钟方向”),再进行空间关系推理(“因此A在左侧”),使过程可解释且更准确。
- 课程学习训练范式:设计了从单源感知预训练、到双源关系推理、再到CoT指令微调的三阶段课程。这种渐进式学习策略被证明对于稳定训练、避免过拟合和最终达成复杂推理至关重要。
- 统一框架:OWL将事件检测、声源定位(DoA、距离)和高阶空间问答统一在一个端到端的框架中,展示了音频大模型在任务扩展性上的潜力。
🔬 细节详述
- 训练数据:
- SAGE预训练:使用AudioSet-2M音频片段,通过SoundSpaces v2.0和Matterport3D进行空间化模拟,生成双耳音频对。同时生成配对的双耳RIR和全景深度图(共28K对)。数据增强包括响度归一化。
- OWL微调:使用AudioSet-20K子集,生成针对四个任务类型(I-IV)的QA对,具体数量见表1(总计约109万对)。
- 损失函数:
L_binaural = α1L_cls + α2L_dis + α3*L_doa,各任务损失为交叉熵损失。权重系数在训练阶段动态调整(例如预训练阶段α1=1250,联合训练阶段α1=1250,α2=1,α3=2)。L_geo = ||R - R_hat||_1 + λ * L_EDC(R, R_hat),其中EDC损失确保重建RIR的能量衰减曲线与真实值匹配。- 总损失权重 η1=1, η2=0.01。
- 训练策略:
- SAGE:两阶段训练。第一阶段仅用
L_cls对音频编码器进行40个epoch的预训练;第二阶段联合优化编码器和RIR预测模块60个epoch。优化器为AdamW,基础学习率0.001,采用半周期余弦退火调度。 - OWL:三阶段课程学习。第一阶段(2 epochs)训练Type I/II QA(感知);第二阶段(2 epochs)训练Type III QA(关系推理);第三阶段(3 epochs)训练Type IV QA(CoT)。优化器为AdamW,学习率0.0001,余弦衰减。SAGE编码器冻结,Q-Former从头训练,LLaMA-2-7B使用LoRA微调(rank=8, α=32)。
- SAGE:两阶段训练。第一阶段仅用
- 关键超参数:
- SAGE编码器:基于AudioMAE初始化,12层Transformer,隐藏维度768,12个注意力头,共85.52M参数。
- OWL:LLM为LLaMA-2-7B。Q-Former有8层,64个查询。LoRA添加了约4.1M可训练参数(占总模型0.062%)。
- 训练硬件:SAGE和OWL均使用4块A100 GPU(80GB)训练。
- 推理细节:OWL在推理时仅使用SAGE的音频编码器和投影器。语言解码采用标准自回归生成,论文未明确说明具体解码策略(如温度、beam size)。
- 正则化技巧:SAGE训练中使用了加权采样。OWL训练中对LoRA使用了0.05的dropout。
📊 实验结果
论文在两个主要基准(BiDepth和SpatialSoundQA)上进行了全面评估,并包含了消融研究和真实世界泛化测试。
- 主要性能对比
| 模型 | 数据集 | 任务 | mAP ↑ | ER20° ↓ | MAE ↓ | DER ↓ | BA (Type III) ↑ | 备注 |
|---|---|---|---|---|---|---|---|---|
| SAGE vs. SELD基线 | ||||||||
| SELDNet | BiDepth | SELD | 39.46 | 53.21 | 38.71 | 53.38 | - | |
| Spatial-AST | BiDepth | SELD | 49.17 | 41.94 | 32.99 | 47.82 | - | |
| SAGE | BiDepth | SELD | 49.75 | 36.89 | 26.32 | 17.11 | - | 仅音频输入 |
| OWL vs. QA基线 | ||||||||
| BAT | BiDepth | QA | - | - | - | - | 69.46 | 4-bin协议 |
| OWL w/ CoT | BiDepth | QA | - | - | - | - | 77.89 | 12-bin协议 |
| BAT | SpatialSoundQA | QA | - | - | - | - | - | 推理平均准确率76.89% |
| OWL w/ CoT | SpatialSoundQA | QA | - | - | - | - | - | 推理平均准确率79.06% |
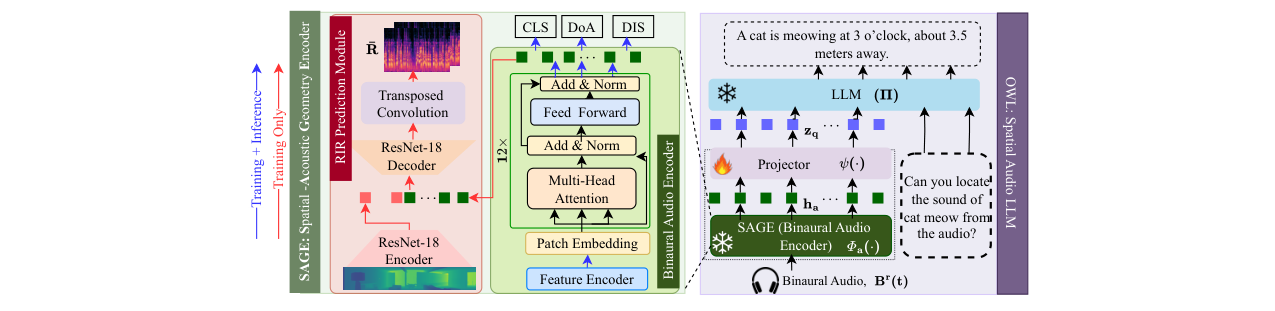
图9(图9):在BiDepth数据集上,OWL生成CoT推理示例。两个声源(Music和Electric Piano)均被正确识别并定位在接收者左侧。

图10(图10):OWL进行“下方声源”空间推理的定性结果。模型正确推理出两个声源(十二点和一点钟方向)均不在接收者下方。

图11(图11):在高混响环境中进行前后推理的定性结果。尽管对Waterfall的定位略有误差,但最终推理结论(两个声源均在后方)正确。
- 消融实验(表5, 表6)
- SAGE损失函数消融:仅用
L_binaural时,mAP=49.75但定位误差大(ER20°=36.89)。加入几何损失L_geo(η2=0.01)后,在保持mAP(49.81)的同时,显著降低ER20°(28.13)、MAE(21.67)和DER(14.32)。这证实了几何监督是提升定位精度的核心。 - OWL训练阶段消融:缺少第一阶段预训练会导致检测性能崩溃(mAP 32.92/8.97)。完整三阶段课程学习在所有任务类型上均取得最佳性能(如Type III BA: 77.89),证明渐进式课程学习的必要性。
- 真实世界泛化(表7, 表8)
- 音频场景分类:在DCASE真实双耳场景数据集上,OWL零样本平均准确率达77%,显示出良好的领域泛化。
- 声源定位:在DCASE SELD 2021真实数据集(FOA转双耳)上,OWL取得mAP 51-57%和DoA准确率31-42%,证明了其在真实环境中的有效性。
⚖️ 评分理由
- 学术质量:6.0/7:论文创新性强,提出了系统性解决方案(SAGE + BiDepth + OWL课程学习),技术实现细节充分,实验对比全面且包含深入的消融研究。主要局限在于核心训练和评估严重依赖合成数据,虽然进行了真实世界测试,但验证规模有限,结论的普适性需进一步确认。
- 选题价值:1.5/2:空间推理是音频理解和具身智能的关键瓶颈,该工作填补了音频大模型在此方面的显著空白,方向前沿且应用潜力大。但对于专注于语音识别、语音合成等主流任务的读者,直接相��性稍弱。
- 开源与复现加成:0.8/1:论文明确提供了代码仓库链接(github.com/BASHLab/OWL),承诺开源数据集和模型。附录提供了极其详尽的超参数、特征提取公式、数据集统计和训练配置,为复现提供了极大便利。未提及推理时的具体生成参数。