📄 OptMerge: Unifying Multimodal LLM Capabilities and Modalities via Model Merging
#多模态模型 #模型评估 #模型比较 #迁移学习 #多任务学习
✅ 7.0/10 | 前25% | #模型比较 | #迁移学习 | #多模态模型 #模型评估
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yongxian Wei (清华大学)
- 通讯作者:Chun Yuan (清华大学)
- 作者列表:Yongxian Wei (清华大学), Runxi Cheng (清华大学), Weike Jin (华为诺亚方舟实验室), Enneng Yang (中山大学), Li Shen (中山大学), Lu Hou (华为诺亚方舟实验室), Sinan Du (清华大学), Chun Yuan (清华大学), Xiaochun Cao (中山大学), Dacheng Tao (南洋理工大学)
💡 毒舌点评
亮点在于提出了首个系统性的MLLM能力融合基准和“无数据”的模态融合思路,为社区提供了重要的评估框架和基线。短板是论文标题中的“Omni-language model”在实验中仅限于简单的音视频问答融合,与真正意义上的通用全能模型差距较大,且核心方法OptMerge在理论层面更像是对现有技术的巧妙组合。
🔗 开源详情
- 代码:论文明确表示“All code and checkpoints are publicly available here”,并提供了开源承诺,但具体链接需从论文或官方页面获取。
- 模型权重:承诺公开基准中训练的所有专家模型检查点(InternVL2.5和Qwen2-VL系列,以及模态融合用的Vicuna-7B变体)。
- 数据集:使用的训练数据来自多个公开数据集,论文在表1和表11中列出了详细清单。基准本身所收集整理的数据是否作为独立数据集发布未说明。
- Demo:未提及在线演示。
- 复现材料:提供了非常详细的训练超参数(学习率、优化器、epoch数、LoRA秩等)、评估设置(使用的评测库、提示模板)和硬件信息(8xV100),复现指引充分。
- 论文中引用的开源项目:依赖多个开源模型和库,如InternVL2.5, Qwen2-VL, Vicuna, CLIP, BEATs, LanguageBind, VLMEvalKit, LMMs-Eval, mergekit等。
📌 核心摘要
本文针对多模态大语言模型(MLLM)能力整合与模态统一的需求,研究模型融合这一低成本、无数据的技术路径。论文的核心工作是:(1) 构建了首个针对MLLM的细粒度能力融合基准,涵盖VQA、几何推理、图表理解、OCR和视觉定位五种能力,并探索了跨模态(视觉-音频-视频)的模型融合;(2) 提出了一种新的模型融合算法OptMerge,通过低秩近似去除任务向量噪声,并基于任务向量间的交互优化合并参数,实验表明其在多种设置下平均性能提升2.48%;(3) 通过大量实验证明,在无需训练数据的情况下,模型融合能够构建性能媲美甚至超越多任务混合训练的增强型MLLM,并有效整合不同模态信息。其主要局限性在于,当前实验规模限于7B参数模型,且“全能模型”的探索尚处于初步阶段。
🏗️ 模型架构
本文的核心是研究“模型融合”方法,而非提出一种全新的MLLM架构。其研究对象是现有的多模态大语言模型架构,典型结构包括:视觉/音频/视频编码器、连接器(如MLP或Q-Former)和大语言模型(LLM)。
OptMerge方法的流程如下:给定一个基础模型θ0和多个在相同基础模型上微调得到的专家模型θ1…θn(每个专注于特定能力或模态)。对于每个专家模型,计算其任务向量τi = θi - θ0。OptMerge的目标是找到一个最优的合并向量τm,使得最终模型θm = θ0 + τm能够同时继承所有专家模型的能力。
具体优化过程为:首先对任务向量进行去中心化处理,然后通过奇异值分解(SVD)进行低秩近似,去除噪声和冗余信息。接着,构建一个基于任务向量交互的损失函数(公式3),该损失鼓励合并向量τm在参数空间中与各个任务向量τi在重要方向上保持一致。最后,通过梯度下降(全参数微调使用Adam,LoRA微调使用SGD)优化τm。对于LoRA微调的模型,还引入了将合并向量初始化为任务向量均值的技巧以稳定训练。最终,将优化后的τm加到基础模型上,得到具备多任务/多模态能力的统一模型。
图1展示了模型融合的两种应用场景:左侧是“能力融合”,将多个专注于不同任务(如VQA、几何、图表等)的专业MLLM融合成一个多任务MLLM;右侧是“模态融合”,将视觉、音频和视频三种模态的语言模型融合,向全能模型迈进。整个过程是数据无关的、高效的后处理方法。
💡 核心创新点
- 首个MLLM细粒度能力融合基准:不同于以往模糊的整体评估或简单的任务算术,本文系统性地划分了MLLM的五项核心能力(VQA, 几何, 图表, OCR, 视觉定位),并为每项能力收集了大规模训练数据集和对应的评估基准。这为模型融合研究提供了清晰的评估框架。
- 提出OptMerge融合算法:在WUDI Merging的基础上进行改进,主要创新在于:(a) 引入低秩SVD近似对任务向量去噪;(b) 重新设计了优化目标(公式3),使优化更鲁棒;(c) 针对LoRA微调模型提出了一套包含优化器替换(Adam->SGD)、初始化改进和低秩约束的稳定训练技巧。
- 理论分析微调对融合性能的影响:通过定理3.1证明了合并模型的损失上界由学习率η和训练迭代次数T控制的交叉任务干扰项和曲率项决定。这为实践中选择“温和微调”的专家模型以利于后续融合提供了理论依据。
- 探索无数据模态融合路径:证明了可以通过融合分别训练在视觉-语言、音频-语言、视频-语言数据上的模型,来构建一个能够处理多模态输入的统一模型,为实现全能模型提供了一种低开销的替代方案。
🔬 细节详述
- 训练数据:
- 能力微调数据:如表1所示,为五项能力分别收集了大规模公开数据集。VQA:588K样本(GQA, VQAv2等);几何:190K样本(GeoQA+等);图表:218K样本(ChartQA, DVQA);OCR:238K样本(OCRVQA, TextVQA等);视觉定位:135K样本(RefCOCO, VG)。数据被处理为指令微调格式。
- 模态微调数据:如表11所示,为视觉、音频、视频模态分别准备了对齐数据和微调数据,规模在100K-700K之间。
- 损失函数:OptMerge核心损失为公式(3):min L_l = Σ_i (1/||τ_i,l||F^2) * ||(τ_m,l - U{1:k}Σ_{1:k}V_{1:k}^⊤ - τ̄_l) (Σ_{1:k}V_{1:k}^⊤)^⊤||_F^2。该损失衡量了合并向量与去噪后的任务向量在任务特征子空间上的差异。
- 训练策略:
- 基准模型微调:InternVL2.5-1B采用全参数微调,学习率4e-5,训练1个epoch;Qwen2-VL-7B采用LoRA(秩8)微调,学习率1e-5,训练1个epoch。
- OptMerge优化:学习率1e-5(Adam)或1e-4(SGD),优化迭代300次。合并系数λ从{0.1, 0.3, 0.5, 0.7, 1.0, 1.5}中网格搜索。秩大小k设为任务向量秩的1/5。
- 关键超参数:实验涉及1B(InternVL2.5)和7B(Qwen2-VL)参数规模,后续扩展至32B(Qwen2.5-VL)。模态融合实验使用Vicuna-7B作为共享LLM。
- 训练硬件:所有实验使用8块NVIDIA V100 GPU进行。
- 推理细节:未说明解码策略、温度等具体推理参数,评估使用VLMEvalKit和LMMs-Eval库的标准设置。
- 正则化技巧:在OptMerge的LoRA模型融合中,使用SGD代替Adam作为隐式正则化;通过低秩近似和合并向量初始化为任务向量均值来稳定训练并控制范数增长(如图4所示)。
📊 实验结果
- 能力融合结果
表2:InternVL2.5(全参数微调)上的能力融合结果
| 方法 | VQA (VizWiz) | VQA (GQA) | 几何 (MathVista) | 几何 (MATH-Vision) | 图表 (ChartQA) | OCR (TextVQA) | OCR (OCRVQA) | 视觉定位 (RefCOCO) | 视觉定位 (RefCOCO+) | 视觉定位 (RefCOCOg) | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| InternVL2.5-Instruct | 29.15 | 54.62 | 46.80 | 18.42 | 69.48 | 72.51 | 41.08 | 71.69 | 65.41 | 67.40 | 53.66 |
| Weight Average | 29.96 | 54.89 | 49.60 | 18.42 | 71.64 | 74.54 | 41.86 | 52.62 | 45.29 | 52.39 | 49.12 |
| Task Arithmetic | 30.67 | 56.34 | 45.36 | 21.05 | 72.88 | 76.26 | 43.39 | 74.90 | 68.15 | 72.75 | 56.18 |
| WUDI Merging | 31.02 | 56.96 | 53.03 | 17.11 | 69.19 | 75.95 | 46.12 | 76.06 | 70.14 | 74.48 | 57.00 |
| OptMerge (Ours) | 30.97 | 57.13 | 54.48 | 21.05 | 68.72 | 76.01 | 46.35 | 75.97 | 69.72 | 73.94 | 57.44 |
| Mixture Training | 29.79 | 61.33 | 52.83 | 23.68 | 70.32 | 72.96 | 60.25 | 72.06 | 65.93 | 67.46 | 57.66 |
表3:Qwen2-VL(LoRA微调)上的能力融合结果
| 方法 | VQA (VizWiz) | VQA (GQA) | 几何 (MathVista) | 几何 (MATH-Vision) | 图表 (ChartQA) | OCR (TextVQA) | OCR (OCRVQA) | 视觉定位 (RefCOCO) | 视觉定位 (RefCOCO+) | 视觉定位 (RefCOCOg) | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2-VL-Base | 5.52 | 5.39 | 47.85 | 23.68 | 0.36 | 20.22 | 1.07 | 45.32 | 37.55 | 31.26 | 21.82 |
| Task Arithmetic | 40.52 | 62.31 | 40.36 | 26.31 | 79.67 | 81.09 | 59.50 | 75.96 | 61.33 | 75.85 | 60.29 |
| WUDI Merging | 37.19 | 56.45 | 42.96 | 27.63 | 67.84 | 79.92 | 65.56 | 76.25 | 60.72 | 71.99 | 58.65 |
| OptMerge (Ours) | 41.61 | 61.16 | 48.66 | 40.79 | 74.08 | 81.54 | 60.06 | 80.92 | 65.90 | 78.24 | 63.30 |
| Qwen2-VL-Instruct | 44.09 | 62.18 | 46.02 | 19.73 | 70.04 | 78.38 | 65.42 | 82.89 | 77.87 | 75.63 | 62.23 |
关键结论:模型融合能够整合多个专家模型的能力,其平均性能常超越单个专家模型和多任务混合训练(Mixture Training)。OptMerge在多数设置下取得最佳平均性能。在Qwen2-VL上,OptMerge(63.30)超越了作为混合训练上界的Qwen2-VL-Instruct(62.23)。
- 模态融合结果
表5:模态融合结果(零样本音视频问答)
| 数据集 | 个体模态 (视觉) | 个体模态 (音频) | 个体模态 (视频) | 权重平均 | 任务算术 | TIES Merging | TSV Merging | Iso-C | WUDI Merging | OptMerge (Ours) | 在线组合 (NaiveMC) | 在线组合 (DAMC) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MUSIC-AVQA | 50.77 | 27.93 | 49.02 | 47.75 | 52.14 | 50.35 | 53.78 | 52.77 | 52.43 | 53.50 | 53.17 | 52.80 |
| AVQA | 75.55 | 47.57 | 79.20 | 69.39 | 78.62 | 75.84 | 80.90 | 77.51 | 76.86 | 80.82 | 80.26 | 80.78 |
| 平均 | 63.16 | 37.75 | 64.11 | 58.57 | 65.38 | 63.10 | 67.34 | 65.14 | 64.65 | 67.00 | 66.88 | 66.79 |
关键结论:通过融合视觉、音频和视频语言模型,静态融合方法(如OptMerge)能够构建一个处理多模态输入的统一模型,其性能(67.00)超越了任何单一模态模型(最高64.11),甚至略优于复杂的在线动态组合方法。
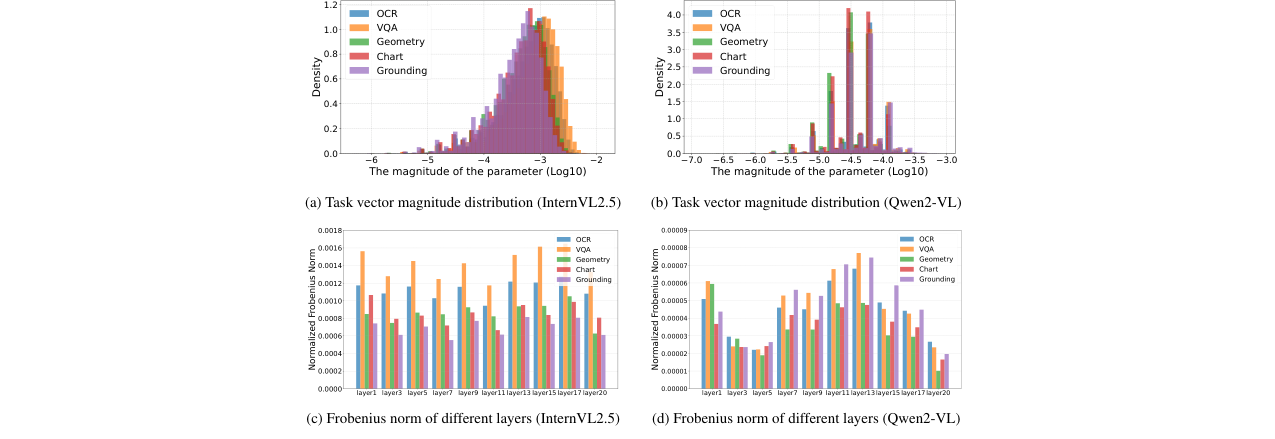
图4展示了在优化合并向量时,不同方法的Frobenius范数随迭代次数的变化。WUDI Merging的范数在优化中快速上升,而OptMerge(Ours)的范数保持相对稳定且较低,这有助于防止合并模型偏离原始分布,是性能提升的关键因素之一。
- 计算开销对比
表7:模型融合 vs. 数据混合训练的计算开销
| 方法 | 解决时间 | GPU显存占用 |
|---|---|---|
| InternVL2.5-1B (Ours) | 0.22h | 2.62GB |
| InternVL2.5-1B (Mixed) | 25.38h | 240GB |
| Qwen2-VL-7B (Ours) | 3.78h | 21.97GB |
| Qwen2-VL-7B (Mixed) | 24.56h | 256GB |
关键结论:模型融合(Ours)在时间和显存消耗上相比混合训练(Mixed)实现了数量级的降低,证明了其作为高效后处理方法的优势。
⚖️ 评分理由
- 学术质量:5.0/7:论文工作系统、完整,从理论分析、基准构建到算法提出与验证一应俱全。理论部分(定理3.1)有新意。实验设计严谨,覆盖不同模型规模和类型。主要不足是OptMerge算法本身是现有技术(SVD, 优化损失)的集成与改进,原创性未达到“突破”级别。
- 选题价值:1.5/2:选题高度契合当前MLLM发展中“高效整合”与“模态统一”的迫切需求。模型融合为社区提供了一种无需大规模数据重训即可扩展能力的可行路径,具有很高的实用价值和启发意义。与音频/语音领域的关联在于其模态融合的范式可被借鉴。
- 开源与复现加成:0.5/1:论文承诺公开所有代码、基准模型权重和详细实现,这极大增强了研究的可信度和可复现��,是重要的加分项。