📄 OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
#多模态模型 #语音大模型 #对比学习 #跨模态 #大语言模型
✅ 7.5/10 | 前25% | #多模态模型 | #多模态模型 | #语音大模型 #对比学习
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Hanrong Ye(NVIDIA)
- 通讯作者:Hongxu Yin(NVIDIA), Pavlo Molchanov(NVIDIA)
- 作者列表:Hanrong Ye, Chao-Han Huck Yang, Arushi Goel, Wei Huang, Ligeng Zhu, Yuanhang Su, Sean Lin, An-Chieh Cheng, Zhen Wan, Jinchuan Tian, Yuming Lou, Dong Yang(以上作者标注为“Core Contribution”,均来自NVIDIA), Zhijian Liu, Yukang Chen, Ambrish Dantrey, Ehsan Jahangiri, Sreyan Ghosh, Daguang Xu, Ehsan Hosseini-Asl, Danial Mohseni Taheri, Vidya Murali, Sifei Liu, Yao Lu, Oluwatobi Olabiyi, Yu-Chiang Frank Wang, Rafael Valle, Bryan Catanzaro, Andrew Tao, Song Han, Jan Kautz, Hongxu Yin§†, Pavlo Molchanov§*(标注“§Equal Advisory”,“†Corresponding Authors”), 机构均为NVIDIA。
💡 毒舌点评
论文在系统性地探索全模态LLM架构与数据配方上做得非常扎实,尤其是OmniAlignNet结合时间编码的设计有清晰的工程动机。然而,论文对模型的具体规模(参数量、计算成本)和数据合成管道的细节披露略显不足,使得“效率优势”的宣称(如0.2T token训练)的完整上下文不够透明,更像是一个精心调优的大型系统工程展示,而非在某个单一技术点上的颠覆性创新。
🔗 开源详情
- 代码:论文中提及将公开代码,但未提供具体仓库链接。
- 模型权重:论文中提及将公开模型,但未提供具体下载地址。
- 数据集:论文中提及构建了24M数据集,并提到了部分来源数据集,但未说明完整数据集的开源获取方式。
- Demo:未提及在线演示。
- 复现材料:论文提供了模型架构图、主要消融实验设置、训练策略概览(两阶段、GRPO配置)和部分超参数(如GRPO的采样数、批次大小),为复现提供了重要信息。详细的超参数配置、检查点等可能在附录中,但当前摘要未完全涵盖。
- 论文中引用的开源项目:提到了Magpie TTS, Long-RL训练框架, Whisper, Qwen系列模型等作为基线或工具,但未明确列出所有依赖项。
📌 核心摘要
- 要解决什么问题:本文旨在构建一个能同时高效、准确理解视觉、音频(含语音和环境音)和文本的开源全模态大语言模型(LLM),以克服现有模型在跨模态对齐、时序建模和数据效率上的不足。
- 方法核心是什么:核心是模型架构与数据工程的协同创新。架构上提出三项关键技术:(1)OmniAlignNet,通过对比学习将视觉和音频嵌入对齐到统一的潜在空间;(2)时间嵌入分组(TEG),基于时间戳对视觉和音频嵌入进行分组以捕获相对时序;(3)约束旋转时间嵌入(CRTE),通过旋转编码注入绝对时间信息。数据上,构建了一个包含2400万对话的管道,通过“隐式学习”(利用已有视频QA数据)和“显式学习”(生成带跨模态标签的新数据)来训练模型。
- 与已有方法相比新在哪里:新在将上述三项架构创新系统性整合,并提出专门解决“模态特定幻觉”的数据合成流程(通过LLM融合独立的视觉和音频描述)。与Qwen2.5-Omni等SOTA模型相比,该方法在更少的训练数据(0.2T token vs 1.2T)下实现了性能提升。
- 主要实验结果如何:在多个基准测试上取得显著提升。在跨模态理解DailyOmni上得分66.50(+19.05 vs Qwen2.5-Omni),在音频MMAR上58.40(+1.7),在视频Video-MME上68.2(+3.9)。在机器人导航、医疗AI等下游任务中也展示了有效性。关键消融实验证明了TEG、CRTE和OmniAlignNet的有效性(详见下表)。
主要消融实验结果(Table 1):
| 方法 | Omni WorldSense↑ | Dailyomni↑ | Omnibench↑ | Average↑ |
|---|---|---|---|---|
| Token Concatenation – Baseline | 42.21 | 54.55 | 36.46 | 45.51 |
| + TEG (ours) | 44.51 | 60.99 | 37.65 | 47.72 |
| ++ CRTE (ours) | 45.46 | 65.66 | 39.64 | 50.25 |
| +++ OmniAlignNet (ours) | 46.21 | 65.83 | 45.74 | 52.59 |
与Qwen2.5-Omni在关键基准上的对比(Table 3, 4, 5):
| 基准任务 | Qwen2.5-Omni | OmniVinci (Ours) |
|---|---|---|
| Omni WorldSense | 45.40 | 48.23 |
| Omni Dailyomni | 47.45 | 66.50 |
| Audio MMAR | 56.70 | 58.40 |
| Video-MME (w/o sub.) | 70.3 | 68.2 |
| 注:Video-MME上Qwen2.5-Omni略高,但OmniVinci在LongVideoBench和MVBench上更优 |
图1(论文Figure 1):直观对比OmniVinci与Qwen2.5-Omni等模型在DailyOmni、MMAR、Video-MME等关键基准上的得分优势。
- 实际意义是什么:证明了通过精心的架构设计和数据工程,可以构建出更高效(训练数据少6倍)、能力更均衡(视听融合增强理解)的全模态基础模型。为机器人控制、智能工厂、医疗辅助诊断等需要同时处理多种感官输入的下游智能体提供了强大的骨干模型。
- 主要局限性:论文对计算成本(如训练总GPU小时数)和完整的模型规模(虽提及9B参数)交代不够详细。数据合成管道的细节(如何确保合成数据质量、多样性)主要在图示中体现,文本描述较简略。此外,尽管展示了应用,但未对所有下游任务进行深入的错误分析。
🏗️ 模型架构
OmniVinci的整体架构是一个基于自回归范式的全模态理解LLM。其核心流程是将来自不同模态(图像、视频帧、音频、文本)的输入,通过专用的编码器和对齐机制,统一转换为LLM可处理的嵌入序列。
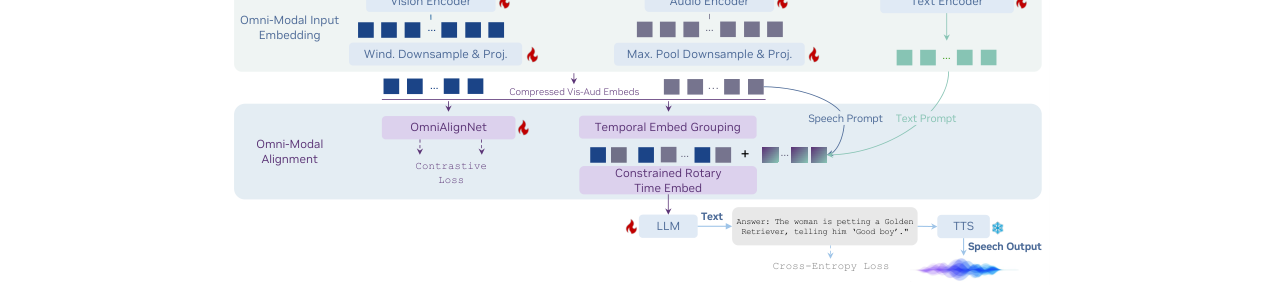
图2(论文Figure 2):展示了从多模态输入到统一嵌入序列再到LLM处理的完整流程。视频被分解为图像帧和音频流,分别经过视觉和音频编码器。核心是OmniAlignNet、时间嵌入分组(TEG)和约束旋转时间嵌入(CRTE)三个模块,它们将异构的视听嵌入对齐并组织成有序的序列输入LLM。输出可以是文本,也可连接TTS模块生成语音。
主要组件详解:
多模态输入嵌入:
- 视觉编码器:处理图像或视频帧,输出视觉嵌入序列。
- 音频编码器:一个统一的编码器,同时处理环境音和语音,输出音频嵌入序列。
- 文本编码器:处理文本提示。
- 论文未详细说明具体编码器型号(如ViT、Whisper等),但提到了它们的存在。
全模态对齐机制:这是架构的核心创新点,旨在将视觉和音频嵌入整合到一个共享的潜在空间。
- OmniAlignNet:一个基于查询的交叉注意力模块。它初始化视觉查询
Qv和音频查询Qa,分别与原始的视觉嵌入Ev和音频嵌入Ea进行交叉注意力操作,然后通过多层自注意力和L2归一化,得到视觉-全模态嵌入V和音频-全模态嵌入A。最终,使用CLIP风格的对比损失(L_o-align)来最小化同一视频内V和A的距离,最大化不同视频间的距离。

图3(论文Figure 3):详细展示了OmniAlignNet的结构。使用查询嵌入通过交叉注意力从视觉/音频tokens中提取全局特征,再通过自注意力层和L2归一化得到统一的视觉-全模态和音频-全模态嵌入,最后使用CLIP对比损失进行对齐。
- 时间嵌入分组 (TEG):解决跨模态的时间对齐问题。根据时间戳
T_G将视觉和音频嵌入划分为多个时间组(如G1_v,G1_a,G2_v,G2_a),然后按时间顺序交叉拼接([G1_v, G1_a, G2_v, G2_a])。这使得LLM能感知到“在某个时间段,视觉和音频内容是同时发生的”,从而更好地建模视听关系。 约束旋转时间嵌入 (CRTE):在TEG的基础上,进一步注入绝对时间信息。它通过调制旋转位置编码(RoPE)的频率来编码时间戳。其关键在于引入最大时间跨度T_max来约束基础频率,从而平衡对短时和长时时间差的敏感性。对每个嵌入向量x,其第i维的旋转角度由ω_i t_j决定(t_j为当前时间戳)。这为模型提供了明确的、连续的绝对时间信号。
- OmniAlignNet:一个基于查询的交叉注意力模块。它初始化视觉查询
LLM主干:接收处理后的全模态嵌入序列(可能还包含文本嵌入),进行自回归生成,完成理解与推理任务。输出为文本,可选地连接TTS模型生成语音输出。
设计选择动机:
- 分解视频:将视频视为图像序列和音频流的组合,简化了编码器设计。
- 统一音频编码器:避免为语音和环境音设计不同模型,提高效率。
- 三阶段对齐:先通过TEG建立粗粒度的相对时序,再通过CRTE注入精确的绝对时间,最后通过OmniAlignNet进行语义层面的双向对齐,形成了一个从时间到语义的完整对齐管道。
💡 核心创新点
- OmniAlignNet:提出了一种基于查询和对比学习的双向模态对齐模块,显式地在共享潜在空间中强化视觉与音频嵌入的语义关联,而不仅仅是简单地拼接或投影。这使得模型能更有效地利用模态间的互补信息。
- 时间嵌入分组 (TEG):一种简单而有效的数据预处理方法,通过对嵌入序列进行基于时间戳的重新排序,直接向LLM提供了清晰的、跨模态的时间对齐结构,无需额外学习参数。
- 约束旋转时间嵌入 (CRTE):改进了已有的RoTE方法,通过引入
T_max约束频率,解决了绝对时间编码对微小扰动敏感和难以捕捉长时间跨度依赖的问题,提供了更鲁棒和多尺度的绝对时间信息。 - 全模态数据合成管道:针对全模态数据稀缺的问题,提出了一个三步生成流程:先独立生成视觉和音频描述,再利用LLM进行跨模态修正和融合,最后用推理LLM生成带推理链的QA对。该管道直接针对“模态特定幻觉”问题进行设计。
🔬 细节详述
- 训练数据:
- 规模:总共2400万对话数据,包含单模态和全模态对话。
- 来源:来自150+个子数据集,覆盖图像(36%)、非语音声音(21%)、语音(17%)、全模态(15%)、视频(11%)。
- 全模态数据构建:通过“隐式学习”(利用现有视频QA数据)和“显式学习”(使用上述数据引擎合成)获得。
- 数据增强:通过Magpie TTS模型将文本提示转换为语音,生成语音提示的视听输入对。
- 损失函数:
- 主要训练损失:未在摘要部分明确说明,通常为标准的自回归交叉熵损失。
- OmniAlignNet损失:对称的CLIP对比损失
L_o-align(见公式1),用于对齐视觉和音频嵌入。 - 强化学习(GRPO)损失:基于规则奖励函数的策略优化目标(公式6、7),用于后训练阶段提升推理能力。
- 训练策略:
- 两阶段训练:1) 模态特定训练(先分别训练视觉、音频能力);2) 全模态联合训练。
- 联合训练数据:混合使用单模态数据和全模态数据。
- 后训练:使用GRPO强化学习,基于18K全模态MCQ数据集进行微调。
- 关键超参数:
- 模型规模:最终报告中提到OmniVinci为9B参数。
- TE分组时长
T_G:未说明具体值(附录E.9提到有消融研究)。 - CRTE的
T_max、θ:未在摘要部分给出。 - GRPO训练:采样数G=8,批次大小64,最大提示长度1024 tokens,最大响应长度2048 tokens,温度1.0,top-p 0.99。
- 训练硬件:未说明。
- 推理细节:解码策略、beam size等未在摘要部分说明。
- 正则化或稳定训练技巧:未明确提及。
📊 实验结果
论文进行了广泛的实验,涵盖消融研究、基准测试和下游任务。
设计选择消融研究 (Table 1):已在核心摘要中列出,证明了TEG、CRTE和OmniAlignNet的递进式贡献。
全模态基准测试 (Table 3):
| 模型 | Omni WorldSense↑ | Dailyomni↑ | Omnibench↑ | Average↑ |
|---|---|---|---|---|
| Gemini-2.0-Flash-Lite | 61.32 | - | - | - |
| Qwen2.5-Omni | 45.40 | 47.45 | 56.13 | 49.66 |
| OmniVinci | 48.23 | 66.50 | 46.47 | 53.73 |
结论:OmniVinci在平均分上超越Qwen2.5-Omni,在Dailyomni上优势显著。
- 音频基准测试 (Table 4, 7):
| 模型 | MMAR↑ | WER (↓) LibriSpeech-clean | WER (↓) LibriSpeech-other | WER (↓) Average |
|---|---|---|---|---|
| Qwen2.5-Omni | 56.70 | 1.8 | 3.4 | 6.8 |
| OmniVinci | 58.40 | 1.7 | 3.7 | 6.3 |
| 注:表示结果来自其他论文* |
结论:在音频理解和ASR上均取得最佳或接近最佳的成绩。
- 视频基准测试 (Table 5):
| 模型 | LongVideoBench val↑ | MVBench test↑ | Video-MME w/o sub.↑ |
|---|---|---|---|
| Qwen2.5-Omni | - | 70.3 | 64.3 |
| NVILA | 57.7 | 68.1 | 64.2 |
| OmniVinci | 61.3 | 70.6 | 68.2 |
结论:在长视频理解和综合视频分析上表现优异。
- 强化学习后训练效果 (Table 8):
| 模型 | Omni WorldSense↑ | Dailyomni↑ | Omnibench↑ | Average↑ |
|---|---|---|---|---|
| OmniVinci | 48.23 | 66.50 | 46.47 | 53.73 |
| OmniVinci + RL | 48.70 | 67.08 | 47.79 | 54.52 |
结论:GRPO后训练带来了全模态理解基准上的持续提升。
- 下游任务示例:
- 机器人导航:在R2R-CE基准上,语音驱动的OmniVinci达到了与文本驱动的NVILA可比的性能(Table 9)。
- 网球解说:在自制网球视频数据集上,OmniVinci在击球回合数预测等任务上大幅超越Qwen2.5-Omni(Table 11)。
- 医疗AI:在CT解读视频QA任务上,OmniVinci平均准确率82% vs Qwen2.5-Omni的79%,在时序推理上优势明显(Table 13)。
图6(论文Figure 6):左图显示OmniVinci在GRPO训练中准确率奖励和格式奖励的收敛速度优于Qwen2.5-Omni。右图显示包含音频输入的OmniVinci在RL训练中收敛更好。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个完整且逻辑清晰的全模态LLM构建方案,架构创新(OmniAlignNet, TEG, CRTE)有扎实的工程和理论基础,数据合成管道设计巧妙,实验全面且包含关键消融。扣分点在于部分核心组件(如编码器细节)和训练超参数未在正文中完全公开,且创新更多是已有技术的精巧组合与优化,而非范式级革新。
- 选题价值:1.5/2:全模态理解是当前AI领域最前沿、最具挑战和应用潜力的方向之一。论文直接面向这一核心问题,其成果对构建更通用、更高效的AI智能体具有重要参考价值。
- 开源与复现加成:0.5/1:论文明确承诺开源代码和模型,并提供了详细的架构图和实验设置,为复现提供了良好基础。但由于缺乏具体链接和部分训练细节,当前的完全复现仍有门槛,因此给予中等加成。