📄 OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs
#基准测试 #多模态模型 #跨模态 #模型评估
🔥 8.5/10 | 前25% | #基准测试 | #多模态模型 | #跨模态 #模型评估
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Caorui Li(东南大学、南京大学)
- 通讯作者:Jiaheng Liu(南京大学)
- 作者列表:Caorui Li(东南大学、南京大学)、Yu Chen(东南大学、南京大学)、Yiyan Ji(南京大学)、Jin Xu(阿里巴巴集团)、Zhenyu Cui(东南大学)、Shihao Li(南京大学)、Yuanxing Zhang(快手科技)、Zhenghao Song(M-A-P)、Dingling Zhang(南京大学)、Ying He(北京科技大学)、Haoxiang Liu(北京科技大学)、Yuxuan Wang(阿里巴巴集团)、Qiufeng Wang(东南大学)、Jiafu Tang(南京大学)、Zhenhe Wu(M-A-P)、Jiehui Luo(中央音乐学院)、Zhiyu Pan(南京大学)、Weihao Xie(华中科技大学)、Chenchen Zhang(M-A-P)、Zhaohui Wang(南京大学)、Jiayi Tian(阿里巴巴集团)、Yanghai Wang(南京大学)、Zhe Cao(南京大学)、Minxin Dai(南京大学)、Ke Wang(M-A-P)、Runzhe Wen(南京大学)、Yinghao Ma(伦敦玛丽女王大学)、Yaning Pan(复旦大学)、Sungkyun Chang(伦敦玛丽女王大学)、Termeh Taheri(伦敦玛丽女王大学)、Haiwen Xia(北京大学)、Christos Plachouras(伦敦玛丽女王大学)、Emmanouil Benetos(伦敦玛丽女王大学)、Yizhi Li(曼彻斯特大学)、Ge Zhang(M-A-P)、Jian Yang(M-A-P)、Tianhao Peng(M-A-P)、Zili Wang(M-A-P)、Minghao Liu(2077AI)、Junran Peng(北京科技大学)、Zhaoxiang Zhang(中国科学院)、Jiaheng Liu(南京大学)
💡 毒舌点评
该工作系统性地定义了评估全模态大语言模型音频-视觉协同推理能力的难题,并通过一套严谨的“人-模型”协作流程构建了一个高质量的评测集,其发现揭示了当前模型在“真正理解”音视频内容上的巨大鸿沟。然而,其核心贡献是一个评测基准(Benchmark)而非一个解决该难题的新模型,且目前数据集尚未完全公开,这限制了其即时影响力。
🔗 开源详情
- 代码:论文中提到将发布评估代码,提供了GitHub链接(https://github.com/NJU-LINK/OmniVideoBench),但未说明当前是否已开源。
- 模型权重:未提及。本文档为评测基准,不涉及新模型训练。
- 数据集:论文承诺将发布OmniVideoBench数据集(包含视频和标注),但未提及具体的发布平台或时间。论文中引用了数据集链接。
- Demo:未提及。
- 复现材料:提供了极其详细的数据集构建流程(附录B)、任务定义、评估提示词(附录C)和统计信息,复现基础扎实。
- 论文中引用的开源项目:在数据集构建和评估中引用了Gemini 2.0 Flash、DeepSeek-V3.1、Voxtral-Mini-3B(用于ASR)等模型。
📌 核心摘要
- 要解决什么问题:现有的多模态大语言模型基准测试无法全面评估模型在音频和视觉模态上的协同推理能力,往往忽视其中一个模态,或将两个模态以逻辑不一致的方式简单结合。
- 方法核心是什么:提出OmniVideoBench,一个大规模、精心设计的评测基准。核心方法包括:从YouTube和Bilibili收集628个多样化视频;设计严格的数据收集原则确保模态互补性;通过“人工标注-模型过滤-人工精修”的流程构建1000个高质量问答对,每个问答对附带明确的、标注了模态和证据的逐步推理链;定义13种任务类型覆盖核心视频理解挑战。
- 与已有方法相比新在哪里:与现有基准相比,OmniVideoBench强调模态互补性和推理逻辑一致性,覆盖长视频(最长达30分钟)、多种真实世界视频类型和音频类型(语音、声音、音乐),并为每个问题提供可追溯的原子级推理步骤,更侧重于评估真正的跨模态协同推理能力,而非单一模态感知或短时理解。
- 主要实验结果如何:评估了多种闭源和开源模型。结果显示,当前最佳模型(Gemini-2.5-Pro)准确率仅为58.90%,远低于人类表现(82.69%),表明模型在音频-视觉协同推理上存在显著差距。开源模型表现更差,接近随机猜测水平。模型在音乐理解任务上表现尤其不佳(如Gemini-2.5-Pro在音乐视频上准确率为38.46%)。详细结果见下表:
| 模型 | 音乐 | 声音 | 语音 | (0,1]分钟 | (1,5]分钟 | (5,10]分钟 | (10,30]分钟 | 平均 |
|---|---|---|---|---|---|---|---|---|
| Gemini-2.5-Pro | 38.46 | 57.72 | 61.66 | 57.83 | 64.43 | 55.02 | 55.94 | 58.90 |
| Gemini-2.0-Flash | 29.67 | 40.27 | 43.21 | 49.40 | 43.15 | 41.05 | 34.87 | 41.50 |
| Qwen3-Omni-30B-A3B | 37.36 | 34.67 | 39.26 | 45.78 | 37.03 | 38.86 | 35.11 | 38.40 |
| Qwen2.5-Omni-7B | 23.07 | 25.33 | 30.70 | 41.57 | 27.41 | 25.33 | 26.72 | 29.30 |
- 实际意义是什么:该基准测试揭示了当前多模态大语言模型在音频-视觉协同推理方面的严重不足,特别是在处理音乐等非语音音频、长视频以及需要复杂跨模态整合的任务时,为未来研究指明了关键改进方向。
- 主要局限性是什么:基准测试本身规模(1000个问答对)相对于海量视频数据仍然有限;部分视频分辨率和帧率被限制在较低水平(480p);评测主要基于多选题形式,可能无法完全反映模型的开放式生成能力;目前代码和数据集尚未完全开源。
🏗️ 模型架构
本文档是论文《OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs》,其核心贡献是提出了一个评估基准(Benchmark),而非一个可部署的新模型。因此,本文不存在传统意义上的“模型架���”。论文的重点在于如何构建和设计这个用于评估现有全模态多模态大语言模型(Omni-Modal MLLMs)能力的测试集。
其“系统架构”体现在数据集构建和评估流程上,详见下图。
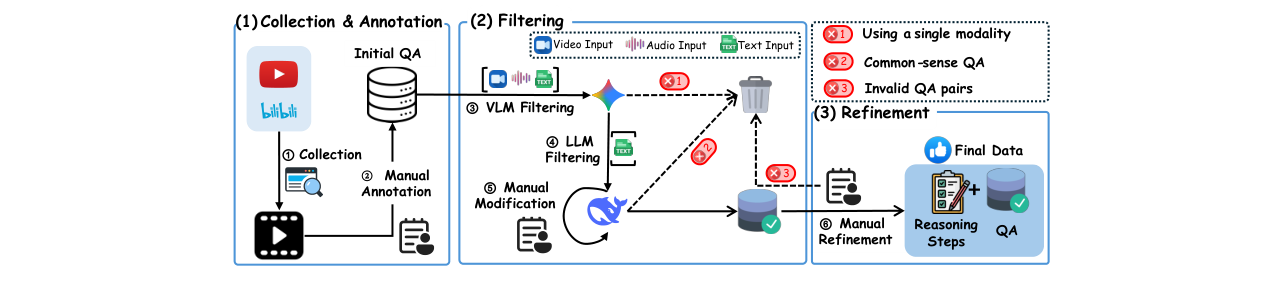
图2:数据集构建与精炼流程。该流程包含收集与标注、过滤(使用VLM和LLM)、以及人工精修三个阶段,最终产出带有推理链的问答对。
流程概述:
- 收集与人工标注:从视频中设计初始多选题,获得约2500个问答对。
- 过滤:
- VLM过滤:使用Gemini 2.0 Flash模型过滤掉仅靠单一模态(如仅视觉)即可回答的问题。
- LLM过滤:使用DeepSeek-V3.1模型过滤掉仅凭文本信息(如常识)即可回答的问题,并修改存在文本偏见的问题。
- 人工精修:最终由人工审核去除错误、非唯一答案的问题,并为每个问题补充详细的、原子化的“模态-证据-推理”步骤链,形成最终的1000个高质量问答对。
💡 核心创新点
- 面向协同推理的严格评估理念:明确指出并致力于解决现有评估中模态割裂或整合逻辑不一致的问题。通过要求问题必须依赖音视频协同推理,且答案唯一,确保了评估的有效性。
- 高质量、可追溯的推理链标注:为每个问答对提供了平均5.68步的详细推理链,每一步都明确标注所依赖的模态(视觉或音频)、具体证据和推理过程。这超越了仅评估最终答案准确性的传统方式,能够深入分析模型的推理过程与失败原因。
- 系统化、自动化的质量控制流程:结合了先进的多模态和语言大模型(Gemini 2.0 Flash, DeepSeek-V3.1)进行多轮自动化过滤(去单模态可答题、去纯文本可答题),再辅以大量人工精修,有效保证了数据集的质量和评估的公平性,减少了模型可“钻空子”的可能。
- 全面且细粒度的评估维度:设计了13种任务类型(如时空推理、因果推理、音乐理解等)和覆盖不同音频类型(语音、声音、音乐)及视频时长(从几秒到30分钟)的细分评估,能够全面刻画模型在音频-视觉理解上的能力谱系和短板。
🔬 细节详述
- 训练数据:本文档未说明用于训练任何模型的数据细节。其自身构建的评测数据集包含628个来自YouTube和Bilibili的真实世界视频,平均时长约384秒,涵盖8大类68子类;标注了1000个QA对,平均问题长度14.68词,平均答案长度4.92词。
- 损失函数:未说明。本文档为评估基准,不涉及模型训练。
- 训练策略:未说明。同上。
- 关键超参数:未说明。但论文在分析中探讨了输入视频帧数(32, 64, 128, 256)对模型性能的影响。
- 训练硬件:未说明。
- 推理细节:评估时,论文主要使用多选题形式,并提供了通用的评估提示词(Prompt),如C.1节所示,要求模型直接输出选项字母。对于消融实验,如测试ASR转录文本的影响,使用了Voxtral-Mini-3B模型生成ASR文本,并将“视觉+ASR文本”作为输入。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文在OmniVideoBench上评估了多款开源和闭源多模态模型。主要结果汇总于下表(表3):
| 模型 | 类型 | 音乐 | 声音 | 语音 | (0,1]分钟 | (1,5]分钟 | (5,10]分钟 | (10,30]分钟 | 平均准确率 |
|---|---|---|---|---|---|---|---|---|---|
| Gemini-2.5-Pro | 闭源 | 38.46 | 57.72 | 61.66 | 57.83 | 64.43 | 55.02 | 55.94 | 58.90 |
| Gemini-2.0-Flash | 闭源 | 29.67 | 40.27 | 43.21 | 49.40 | 43.15 | 41.05 | 34.87 | 41.50 |
| Qwen3-Omni-30B-A3B | 开源 | 37.36 | 34.67 | 39.26 | 45.78 | 37.03 | 38.86 | 35.11 | 38.40 |
| OmniVinci-9B | 开源 | 30.77 | 32.67 | 32.15 | 38.55 | 34.11 | 30.13 | 27.10 | 32.10 |
| Qwen2.5-Omni-7B | 开源 | 23.07 | 25.33 | 30.70 | 41.57 | 27.41 | 25.33 | 26.72 | 29.30 |
| Qwen2.5-VL-72B | 纯视觉 | 26.37 | 29.33 | 29.91 | 33.13 | 30.03 | 31.88 | 24.43 | 29.50 |
| DeepSeek-V3.1 | LLM | 28.57 | 26.17 | 27.28 | 30.91 | 27.57 | 25.00 | 26.44 | 27.60 |
关键结论:
- 模型能力远低于人类:人类评估者准确率为82.69%,而最佳模型Gemini-2.5-Pro仅为58.90%。
- 音乐理解是普遍短板:所有模型在包含音乐的视频上准确率显著低于包含语音或环境音的视频。
- 长视频理解仍有挑战:多数模型在超过10分钟的视频上性能有明显下降。
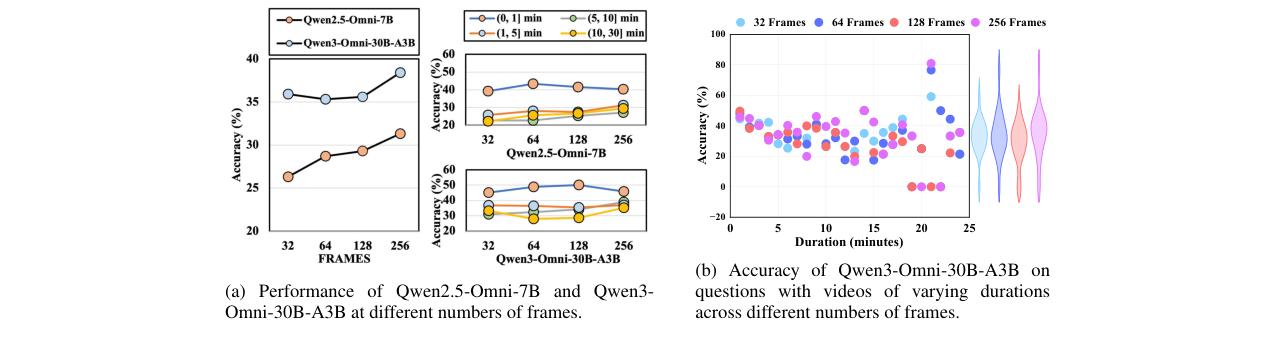
图5:模型在13种任务类型上的准确率对比。显示“背景与音乐理解”任务最困难,“关系推理”和“总结”任务相对容易。
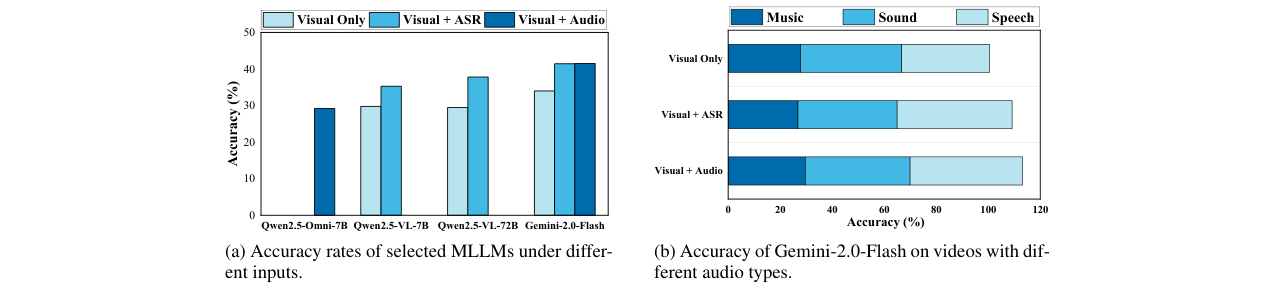
图6:不同输入条件下模型准确率对比。(a)显示“视觉+ASR文本”输入普遍优于“仅视觉”输入,但“视觉+音频”的联合模态处理能力不足;(b)显示ASR对音乐/声音类型视频帮助有限。

图7:模型性能随输入帧数变化的分析。(a)显示增加帧数可提升两个模型的性能;(b)显示这种提升在长视频上尤为明显。
⚖️ 评分理由
- 学术质量:6.5/7:论文系统性地定义了评估全模态模型音频-视觉协同推理能力的关键问题,并提出了一套严谨、可复现的基准构建方法论。实验设计全面,对比基线丰富,分析深入(包括错误分类分析),结论有充分的数据支撑。创新性主要体现在评估框架和数据构建流程的严谨性上,而非提出新的模型算法。
- 选题价值:1.5/2:音频-视觉协同理解是多模态AI的核心挑战之一,具有极高的前沿性和应用价值(如视频监控、内容创作、人机交互)。该基准测试直接针对当前模型的薄弱环节,能有效指导未来研究,对社区有明确的推动作用。
- 开源与复现加成:0.5/1:论文承诺将发布代码和数据集,提供了详细的构建流程、统计信息和评估提示词,为复现提供了良好基础。然而,截至论文发表,数据集和代码尚未完全公开,扣分0.5分。