📄 OmniCVR: A Benchmark for Omni-Composed Video Retrieval with Vision, Audio, and Text
#音频检索 #多模态模型 #基准测试 #数据集
✅ 7.0/10 | 前25% | #音频检索 | #多模态模型 | #基准测试 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Junyang Ji(清华大学、南方科技大学、快手科技)
- 通讯作者:Zhihai He(南方科技大学)、Wenming Yang(清华大学)
- 作者列表:Junyang Ji(清华大学,南方科技大学,快手科技),Shengjun Zhang(快手科技),Da Li(快手科技,中国科学院大学),Yuxiao Luo(快手科技,北京大学),Yan Wang(快手科技),Di Xu(快手科技),Biao Yang(快手科技),Wei Yuan(快手科技,项目负责人),Fan Yang(快手科技,项目负责人),Zhihai He(南方科技大学,通讯作者),Wenming Yang(清华大学,通讯作者)
💡 毒舌点评
亮点:论文一针见血地指出了当前多模态模型“视觉-文本”偏科、严重忽视音频信息的普遍问题,并通过一个高质量、大规模的诊断基准(OmniCVR)将其量化,这比提出一个改进模型更有价值。短板:提出的解决方案“AudioVLM2Vec”本质上是把音频先转录/描述成文本再喂给视觉语言模型,这种“音频-文本化”的工程化方案虽然有效,但显得不够优雅,且引入了额外的延迟和潜在信息损失,算不上是最根本的端到端解决方案。
🔗 开源详情
- 代码:论文承诺将开源完整代码库,包括数据生成脚本、训练代码和评估协议。具体代码仓库链接在提供的论文全文中未直接显示,但提到数据将发布在HuggingFace(https://huggingface.co/datasets/Jun-Yang/OmniCVR),代码链接可能随发布同步公开。论文中未明确给出代码仓库的直接URL。
- 模型权重:论文承诺将公开AudioVLM2Vec模型权重。未提及具体模型权重的发布链接。
- 数据集:OmniCVR数据集(包括160K+片段、50K+三元组、5K测试集)将完全开源。获取方式为通过上述HuggingFace链接。
- Demo:论文中未提及是否提供在线演示。
- 复现材料:论文在附录(Appendix G)中提供了用于数据生成(如生成视频描述、修改指令)的完整提示词模板,以及详细的双重验证协议说明,这对于复现数据生成管线至关重要。然而,关于模型训练的具体细节(学习率、优化器、批次大小等)论文中未提及。
- 论文中引用的开源项目/模型:论文明确使用了以下开源模型作为组件或基线:
- Qwen2.5-Omni:用于视频音频标注生成。
- Gemini 2.5 Pro:用于数据验证。
- Qwen2-Audio-7B-Instruct:用于AudioVLM2Vec中的音频描述生成。
- Qwen2-VL:作为VLM2Vec和AudioVLM2Vec的视觉-语言骨干。
- CLIP、BLIP、BLIP-2、ImageBind 等作为基线模型。
- PySceneDetect:用于视频分割。
- 所有使用的数据集(HowTo100M, MSR-VTT, VATEX, YouTube8M, YouCook2, VALOR)均为公开数据集。
📌 核心摘要
本文旨在解决现有视频检索基准和模型普遍忽视音频模态的关键问题。论文提出了首个全模态组合视频检索基准OmniCVR,该基准将视觉、音频和文本视为同等重要的第一类模态。核心方法是构建了一个包含50,000个三元组(源视频、修改文本、目标视频)的大规模数据集,其中超过57%的查询需要同时修改视觉和音频(集成查询)。为此,作者设计了一个可扩展的自动化数据生成管线,并通过大模型与人类专家的双重验证确保数据质量。为验证基准,论文提出了AudioVLM2Vec模型,其核心创新是利用音频理解大模型(Qwen2-Audio)将音频转为细粒度描述文本,再与视觉信息一同输入VLM2Vec框架。主要实验结果表明,AudioVLM2Vec在OmniCVR基准上取得了最优性能,尤其是在音频中心查询上,相比基线VLM2Vec实现了巨大的性能提升(R@1从12.4提升到77.2)。这证明了显式注入音频语义对于跨模态检索的关键作用,并暴露了现有“全模态”模型在音频推理上的根本缺陷。该工作的实际意义在于为更真实的多模态视频理解设立了新标准,推动研究向听觉-视觉-语言融合迈进。主要局限性在于提出的“音频转文本”方案带来了额外的推理延迟(约1.77倍),且该方案可能无法完美捕捉音频的所有非语义信息(如音色、节奏等)。
🏗️ 模型架构
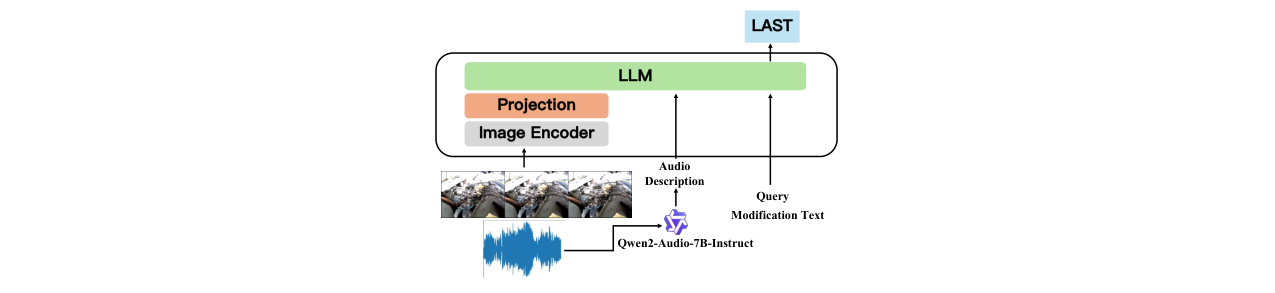
论文的核心架构贡献是AudioVLM2Vec,其设计旨在将音频语义显式地注入到基于视觉语言模型的嵌入框架中。该架构是一个针对音频检索任务的适配模型,而非一个端到端的多模态大模型。
其完整流程和组件如下:
- 输入:一个源视频和一个文本形式的修改指令。
- 双流处理:
- 视觉流:视频帧被输入一个预训练的图像编码器(如CLIP-ViT),得到视觉特征。这些特征经过一个轻量级的投影层,转换为适合输入大语言模型(LLM)的视觉令牌(Visual Tokens)。
- 音频语义流:视频的音轨被输入Qwen2-Audio-7B-Instruct模型。该模型的任务是生成关于音频内容的细粒度自然语言描述(Audio Description)。此步骤是关键创新,它将原始音频信号转化为结构化的语义文本。
- 模态融合:生成的音频描述文本与用户的原始修改指令(Modification Text)进行拼接。拼接后的文本序列被输入到LLM骨干网络(如Qwen2-VL)中。
- 联合编码与嵌入:LLM接收来自视觉流的视觉令牌和来自融合文本的文本令牌。通过其多头自注意力机制,模型能够在共享的语义空间中对视觉和(已转为文本的)音频语义进行对齐和联合推理。最终,从LLM中提取一个表示整个查询(源视频+修改指令)的固定长度的向量,即多模态嵌入。
- 检索:在检索阶段,计算该查询嵌入与候选池中所有视频的嵌入(通过类似的视觉编码器处理得到)之间的相似度,从而排序并返回最匹配的目标视频。
关键设计选择与动机:
- 音频转文本:动机在于,现有的视觉语言模型(VLM)本身不直接处理音频波形,且训练时未充分学习音频语义。直接使用音频token(如OmniEmbed)效果不佳。通过将音频信息转化为LLM熟悉的文本格式,可以“搭便车”利用LLM强大的文本理解能力,从而有效融合音频信息。
- 基于VLM2Vec扩展:选择将强大的VLM(如Qwen2-VL)转化为嵌入模型作为基础,是因为其视觉-文本对齐能力已非常强大。AudioVLM2Vec只需专注于弥补其音频处理的短板,这是一种高效的研究路径。
此外,论文还描述了OmniCVR基准的构建流程,这是一个包含三个阶段的自动化管线:
- 视频策展与分割:从多个公开数据集(如HowTo100M)收集长视频,使用PySceneDetect工具将其分割成5-15秒的语义连贯短片,并通过动作强度和场景丰富度过滤,保留信息密度高的片段。
- 全模态标注生成:使用Qwen2.5-Omni模型对分割后的视频片段进行联合视觉-音频标注,生成结构化的描述(包括场景、动作、物体、音频事件等)。
- 组合三元组挖掘:基于标注,通过三种策略生成(源视频,修改文本,目标视频)三元组:视觉中心(改变视觉,保持音频)、音频中心(保持视觉高相似,改变音频低相似)、集成(同时改变视觉和音频)。修改文本由LLM根据源和目标的描述差异自动生成。
- 双重验证:构建黄金标准测试集时,每个候选三元组需同时通过Gemini 2.5 Pro大模型和人类专家的独立审核(AND门控),确保数据质量。
💡 核心创新点
提出首个全模态组合视频检索基准(OmniCVR):
- 局限:此前所有CoVR基准(如WebVid-CoVR, EgoCVR)仅关注视觉修改,完全忽视音频。
- 创新:首次将音频(语音、音乐、环境音)提升为与视觉、文本同等重要的“第一类模态”,并系统性地构建了涵盖视觉中心、音频中心和集成查询的大规模基准数据集(50K三元组,160K+视频片段)。
- 收益:填补了评估空白,能更全面、真实地评估多模态模型的理解能力,暴露了现有模型在音频推理上的重大缺陷。
提出AudioVLM2Vec,通过“音频转文本”策略显式注入音频语义:
- 局限:现有的强大视觉-语言嵌入模型(如VLM2Vec)没有有效的音频处理路径;而原生支持多模态的模型(如OmniEmbed)其音频表征能力薄弱,被视觉信号主导。
- 创新:利用音频理解大模型(Qwen2-Audio)将音频内容转化为详细的文本描述,再将此描述作为增强的文本输入馈送给视觉-语言模型,使其能够“理解”音频。
- 收益:在音频中心检索任务上实现了巨大性能飞跃(R@1从12.4飙升至77.2),证明了该策略的有效性。控制实验表明,即使是原生支持音频的模型,替换为“音频转文本”后性能也大幅提升。
设计可扩展且严格的数据生成与验证管线:
- 局限:高质量的多模态组合数据难以大规模获取。
- 创新:结合了自动化分割、基于大模型的生成式标注、多策略三元组挖掘以及大模型+人工的双重验证协议,确保了数据的规模、多样性和高质量。
- 收益:保证了基准的可靠性和研究的可复现性。
🔬 细节详述
- 训练数据:OmniCVR基准数据。训练集包含约45K三元组,来源于HowTo100M、MSR-VTT、VATEX、YouTube8M、YouCook2、VALOR等六个公开数据集。视频片段平均长度11.8秒。数据生成过程中使用了Qwen2.5-Omni进行标注,Gemini 2.5 Pro进行验证。
- 损失函数:论文未明确说明AudioVLM2Vec训练时使用的具体损失函数。根据其任务(组合检索)和框架(基于VLM2Vec),可合理推测使用了对比学习损失(如InfoNCE Loss),用于拉近匹配对(查询嵌入,目标视频嵌入)的距离,推远不匹配对的距离。
- 训练策略:论文中未提供AudioVLM2Vec的具体训练策略细节(如学习率、优化器、batch size、训练轮数等)。这属于复现信息缺失的部分。
- 关键超参数:未明确说明模型各组件的具体尺寸(如视觉编码器、投影层、LLM的具体版本参数量)。音频描述生成模型固定为Qwen2-Audio-7B-Instruct。
- 训练硬件:论文中未提及。
- 推理细节:在评估时,为每个查询计算与候选视频嵌入的相似度,并打乱候选池5次取平均值。对于音频中心任务,特别控制了候选池中包含视觉相似但音频不同的干扰项。
- 正则化或稳定训练技巧:论文中未提及。
📊 实验结果
论文在OmniCVR基准的5K黄金标准测试集上评估了多个基线模型。主要指标为Recall@K (R@1, R@3, R@5, R@10)。
主要结果(总体性能):
| 模型 | 骨干网络 | R@1 | R@3 | R@5 | R@10 |
|---|---|---|---|---|---|
| 轻量级/任务特定模型 | |||||
| CLIP | CLIP | 27.54 | 50.46 | 56.70 | 62.62 |
| CoVR | BLIP2 | 11.46 | 22.88 | 28.08 | 35.18 |
| BLIP | BLIP | 6.3 | 11.84 | 14.12 | 17.00 |
| ImageBind | CLIP | 17.28 | 29.55 | 43.34 | 45.33 |
| 大型多模态嵌入模型 | |||||
| OmniEmbed-v0.1-multivent | Qwen2.5-Omni | 31.90 | 51.50 | 57.04 | 64.00 |
| VLM2Vec | Qwen2-VL | 38.44 | 55.48 | 60.44 | 66.60 |
| AudioVLM2Vec (本文) | Qwen2-Audio + Qwen2-VL | 66.98 | 77.84 | 80.86 | 84.40 |
音频中心检索性能:
| 模型 | 骨干网络 | R@1 | R@3 | R@5 | R@10 |
|---|---|---|---|---|---|
| OmniEmbed-v0.1-multivent | Qwen2.5-Omni | 13.6 | 28.5 | 35.8 | 47.0 |
| VLM2Vec | Qwen2-VL | 12.4 | 23.3 | 30.4 | 42.3 |
| AudioVLM2Vec (本文) | Qwen2-Audio + Qwen2-VL | 77.2 | 87.3 | 90.7 | 94.2 |
(图中展示了在音频中心检索任务中,按目标音频类别(人类语音、音乐、音效)细分的R@1性能。AudioVLM2Vec在所有类别上均显著优于VLM2Vec基线,尤其是在人类语音(+85.23%)和音乐(+70.36%)类别。)
关键发现与消融实验:
- 音频语义的关键性:AudioVLM2Vec在总体和音频中心查询上均取得SOTA。与基线VLM2Vec相比,在音频中心查询的R@1上提升了64.8个百分点(77.2 vs. 12.4),证明显式音频语义注入的决定性作用。
- 源视频的必要性:盲检索消融实验显示,移除源视频视觉帧后,AudioVLM2Vec在音频中心查询的R@1从77.2%暴跌至28.1%,降幅49.1%。这证明修改文本是相对指令,源视频提供了不可替代的上下文。
- “音频转文本”机制的优越性:控制实验对比了OmniEmbed的原生音频token和本文的“音频转文本”方法。在相同骨干和训练数据下,“音频转文本”将音频中心R@1从13.6提升至32.7(+19.1),且在所有音频类别上均有大幅提升。这表明转化为密集、语义丰富的文本描述是更有效的音频表征方式。
- 效率权衡:AudioVLM2Vec的推理延迟(4.77s)约为VLM2Vec(1.72s)的2.77倍,主要瓶颈在于音频转文本步骤。但其实时因子(RTF≈0.5)仍快于实时播放,具备部署可行性。
⚖️ 评分理由
- 学术质量:5.5/7。论文在问题定义(忽略音频的组合检索)、基准构建(高质量、大规模)和实验验证(系统、扎实)方面表现优秀,证据链完整可信。扣分点主要在于提出的AudioVLM2Vec模型在架构创新上属于有效集成而非原创性突破(将音频转文本是一种已知技术思路),且未提供其训练的具体细节,影响了技术深度的评分。
- 选题价值:1.5/2。选题切中多模态理解中被忽视的音频痛点,具有明确的前沿性和广泛的应用前景(如更智能的视频搜索、内容创作、辅助工具)。对音频研究社区和多媒体处理从业者有很强的启发和实用价值。
- 开源与复现加成:0/1。论文明确承诺将开源数据集、代码和模型,并指向了具体的HuggingFace页面,这是极好的复现承诺。但由于论文发表时可能资源尚未完全就绪,且未提供训练超参数等细节,因此给予0分中性评价,不加分也不扣分。