📄 Omni-Reward: Towards Generalist Omni-Modal Reward Modeling with Free-Form Preferences
#多模态模型 #基准测试 #数据集 #强化学习
🔥 8.0/10 | 前25% | #基准测试 #数据集 | #强化学习 #多任务学习 | #多模态模型 #基准测试
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.9 | 置信度 高
👥 作者与机构
- 第一作者:Zhuoran Jin(中国科学院大学人工智能学院,中国科学院自动化研究所,国家认知与决策智能重点实验室)
- 通讯作者:Jun Zhao(中国科学院大学人工智能学院,中国科学院自动化研究所,国家认知与决策智能重点实验室)
- 作者列表:Zhuoran Jin(中国科学院大学人工智能学院,中国科学院自动化研究所), Hongbang Yuan(中国科学院大学人工智能学院,中国科学院自动化研究所), Kejian Zhu(中国科学院大学人工智能学院,中国科学院自动化研究所), Jiachun Li(中国科学院大学人工智能学院,中国科学院自动化研究所), Pengfei Cao(中国科学院大学人工智能学院,中国科学院自动化研究所), Yubo Chen(中国科学院大学人工智能学院,中国科学院自动化研究所), Kang Liu(中国科学院大学人工智能学院,中国科学院自动化研究所), Jun Zhao(中国科学院大学人工智能学院,中国科学院自动化研究所)
💡 毒舌点评
这篇论文最大的贡献是“立规矩、搭台子”——提出了首个覆盖全模态且支持自由格式偏好的奖励建模基准和数据集,填补了领域空白,为后续研究提供了标准评测场。其短板在于模型架构本身(Omni-RewardModel)是现有技术(如Bradley-Terry框架、GRPO强化学习)在更大规模多模态数据上的直接应用,缺乏针对“自由格式偏好”理解的独创性建模机制。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://github.com/HongbangYuan/OmniReward
- 模型权重:提及了公开Omni-RewardModel权重,下载链接为:https://hf.co/datasets/HongbangYuan/OmniRewardBench (注:此处链接标签为Dataset,但文中暗示模型权重也可能在此或类似路径)
- 数据集:明确公开两个数据集:Omni-RewardBench (https://hf.co/datasets/HongbangYuan/OmniRewardBench) 和 Omni-RewardData (https://hf.co/datasets/jinzhuoran/OmniRewardData),均托管于HuggingFace。
- Demo:论文中未提及在线演示。
- 复现材料:论文在正文和附录中描述了数据收集、标注流程、模型训练细节(如骨干模型选择、训练数据比例、强化学习算法)以及评估协议,复现信息较为充分。
- 引用的开源项目:模型构建依赖MiniCPM-o-2.6和Qwen2.5-VL等开源多模态模型。训练数据整合了多个公开数据集,如Skywork-Reward-Preference, RLAIF-V, HPDv2, VideoDPO等。
📌 核心摘要
- 要解决什么问题:现有的奖励模型存在两个核心挑战:一是模态不平衡,主要关注文本和图像,对音频、视频、3D等模态支持不足;二是偏好刚性,基于固定的二元偏好对训练,无法捕捉复杂多样的个性化偏好。
- 方法核心是什么:提出Omni-Reward框架,包含三个核心组件:(1) 评测基准Omni-RewardBench,首个支持自由格式偏好描述、覆盖9类任务5种模态的奖励模型评测集;(2) 训练数据集Omni-RewardData,包含248K通用偏好对和69K用于指令微调的自由格式偏好对;(3) 模型Omni-RewardModel,包括判别式(BT)和生成式(R1)两种全模态奖励模型。
- 与已有方法相比新在哪里:(1) 首次系统性地将奖励建模扩展到全模态场景(包括音频、3D);(2) 首次在奖励建模中引入自由形式的自然语言偏好描述,替代传统的二元选择,以支持动态、个性化的偏好对齐;(3) 构建了迄今为止最全面的多模态奖励建模训练数据集。
- 主要实验结果如何:
- 在自有基准Omni-RewardBench(w/ Ties设置)上,Omni-RewardModel-BT达到65.36% 准确率,超越最强基线(Claude 3.5 Sonnet的66.54%已属顶级,但模型整体仍有提升空间)。
- 在公开基准VL-RewardBench上,Omni-RewardModel-BT达到76.3% 准确率,取得SOTA性能。
- 消融实验证明,使用混合多模态数据进行训练比单模态数据显著提升泛化能力;指令微调数据对于处理自由格式偏好至关重要。
| 模型 | Omni-RewardBench (w/ Ties) | VL-RewardBench |
|---|---|---|
| Claude 3.5 Sonnet (最强基线) | 66.54% | 55.3% |
| Omni-RewardModel-BT | 65.36% | 76.3% |
| Omni-RewardModel-R1 | 60.18% | 未报告 |
- 实际意义是什么:为未来的全模态大模型(如GPT-4o, Qwen2.5-Omni)提供了对齐所需的关键基础设施——评测标准和训练数据。推动了奖励建模从“固定偏好”向“个性化偏好”的范式转变,使AI系统能更灵活地适应不同用户或场景的具体需求。
- 主要局限性是什么:(1) Omni-RewardBench的规模(3.7K对)相对较小,可能不足以全面评估超大规模模型;(2) 任务定义相对粗粒度,每种模态任务内的多样性还可进一步细分;(3) 当前数据仅限单轮交互,未涵盖多轮对话偏好。
🏗️ 模型架构
Omni-RewardModel包含两个变体,其整体架构如下图所示。核心是基于一个多模态大语言模型(如MiniCPM-o-2.6或Qwen2.5-VL)作为骨干网络,处理来自文本、图像、视频、音频等模态的输入。

图2:Omni-RewardModel架构概览。左侧(1)为判别式模型,右侧(2)为生成式模型。
完整输入输出流程:
- 输入:每个样本包含可选的偏好指令
c、输入x(可以是文本、文本+图像、文本+视频等)以及两个候选响应y1,y2。 - 输出:
- 判别式模型 (Omni-RewardModel-BT):直接输出一个标量奖励分数
reward。 - 生成式模型 (Omni-RewardModel-R1):输出一个包含推理过程(CoT)的文本评论,最后给出偏好预测
p(可以是y1,y2, 或tie)。
- 判别式模型 (Omni-RewardModel-BT):直接输出一个标量奖励分数
主要组件与功能:
- 多模态编码器:包括视觉编码器(处理图像/视频帧)、音频编码器(处理音频片段),用于将非文本模态转化为模型可理解的表示。在训练判别式模型时,这些编码器参数被冻结。
- 语言模型解码器 (LM Decoder):接收编码后的多模态特征和文本指令,进行跨模态融合与推理。这是模型的核心。
- 价值头 (Value Head):对于判别式模型,在LM解码器的最终隐藏状态之上添加一个线性层,输出标量奖励分数。
- LM Head:对于生成式模型,使用标准的语言模型输出头来生成文本序列(包括推理过程和最终判断)。
关键设计选择及数据流:
- 判别式路径:
(c, x, y1, y2)→ 多模态编码器+LM解码器 →rBT(c, x, yc)和rBT(c, x, yr)→ 使用Bradley-Terry损失训练。 - 生成式路径:
(c, x, y1, y2)→ LM解码器 → 生成推理文本e和预测偏好p'→ 使用GRPO强化学习训练,奖励信号来自p'与真实标签p的匹配程度。 - 自由格式偏好的体现:偏好指令
c作为系统消息输入,使得模型可以在推理时根据不同的c调整其评分或判断标准。
💡 核心创新点
- 全模态奖励建模基准(Omni-RewardBench):首次构建了一个覆盖文本、图像、视频、音频、3D五种模态、包含9类任务的奖励模型评测基准,且每对样本都配有人类撰写自由形式偏好描述。这直接定义了全模态奖励模型该“考什么”,解决了现有评测集中模态覆盖不全、偏好形式单一的问题。
- 自由格式偏好数据与训练范式:通过构造指令微调数据,让奖励模型学习根据自然语言描述的偏好(如“响应应该更学术化” vs “响应应该更通俗易懂”)来调整评分。这突破了传统RM只能学习固定、隐式偏好的局限,使RM能动态适应个性化、多维度的评价标准。
- 大规模全模态奖励数据集(Omni-RewardData):整合现有偏好数据并新收集了包含自由格式偏好描述的指令微调数据,形成了一个跨任务(T2T, TI2T, T2I, T2V)的大规模训练集,为训练泛化能力强的全模态RM提供了数据基础。
🔬 细节详述
- 训练数据:
- Omni-RewardBench (评测集): 3,725对,人工标注,每对包含自由形式偏好描述。
- Omni-RewardData (训练集): 共计约317K对。包括248K通用偏好对(来自Skywork-Reward, RLAIF-V, OmniAlign-V, HPDv2, VideoDPO等现有数据集)和69K新构建的指令微调对(使用GPT-4o生成偏好描述,并经多模型验证)。
- 损失函数:
- 判别式模型:使用Bradley-Terry损失:
LBT = -log(exp(r(c, x, yc)) / (exp(r(c, x, yc)) + exp(r(c, x, yr)))),旨在最大化被偏好响应的奖励分数。 - 生成式模型:使用基于GRPO的强化学习。奖励信号是二元的:如果预测偏好
p'与真实标签p一致,则给予正奖励,否则为负奖励或零奖励。模型优化目标是最大化期望回报。
- 判别式模型:使用Bradley-Terry损失:
- 训练策略:
- 判别式模型:基于MiniCPM-o-2.6,冻结视觉和音频编码器,只微调语言模型解码器和价值头。
- 生成式模型:从Qwen2.5-VL-7B-Instruct开始,在仅10K样本上从头训练(未使用大模型蒸馏)。
- 关键超参数:论文未在正文中详细说明学习率、batch size等具体超参数,但在附录中承诺提供完整细节。
- 训练硬件:论文中未提及具体GPU型号和训练时长。
- 推理细节:对于生成式RM,采用成对(pairwise)格式,先生成对两个响应的评论,再做最终判断。具体提示模板见附录K。
📊 实验结果
主要基准评测结果(Omni-RewardBench): 下表展示了在更困难的w/ Ties设置下的整体和部分任务表现(部分行摘要自论文表格)。
| 模型 | T2T | TI2T | TV2T | TA2T | T2I | T2V | T2A | T23D | TI2I | Overall |
|---|---|---|---|---|---|---|---|---|---|---|
| 最强基线(Claude 3.5 Sonnet) | 76.74 | 61.55 | 67.04 | - | 61.69 | 64.27 | - | 68.54 | 65.94 | 66.54 |
| Omni-RewardModel-BT | 75.30 | 60.23 | 68.85 | 70.59 | 58.35 | 64.08 | 63.99 | 67.88 | 58.95 | 65.36 |
| Omni-RewardModel-R1 | 71.22 | 56.06 | 63.88 | - | 61.69 | 58.22 | - | 63.91 | 46.29 | 60.18 |
| UnifiedReward1.5 | 59.47 | 54.17 | 69.30 | - | 58.35 | 69.57 | - | 61.59 | 45.41 | 59.69 |
结论:Omni-RewardModel-BT在整体性能上接近最强商业模型,且在TA2T(音频理解)、T2A(音频生成)等传统弱势任务上表现出显著优势(70.59% vs 平均59.66%),证明了其全模态泛化能力。
消融实验(验证数据构成的影响): 下表显示了在Omni-RewardBench上,使用不同训练数据子集时的模型性能(w/ Ties)。
| 模型(基于MiniCPM-o-2.6) | Overall Acc |
|---|---|
| 基础模型 | 46.67 |
| + 仅T2T数据 | 57.13 |
| + 仅TI2T数据 | 58.84 |
| + 仅T2I & T2V数据 | 57.50 |
| + 全部数据(Full) | 65.36 |
| + 仅通用偏好数据(无指令微调) | 58.67 |
结论:混合多模态数据训练(Full)效果最好。移除指令微调数据后性能明显下降(65.36 -> 58.67),证明了自由格式偏好数据的重要性。
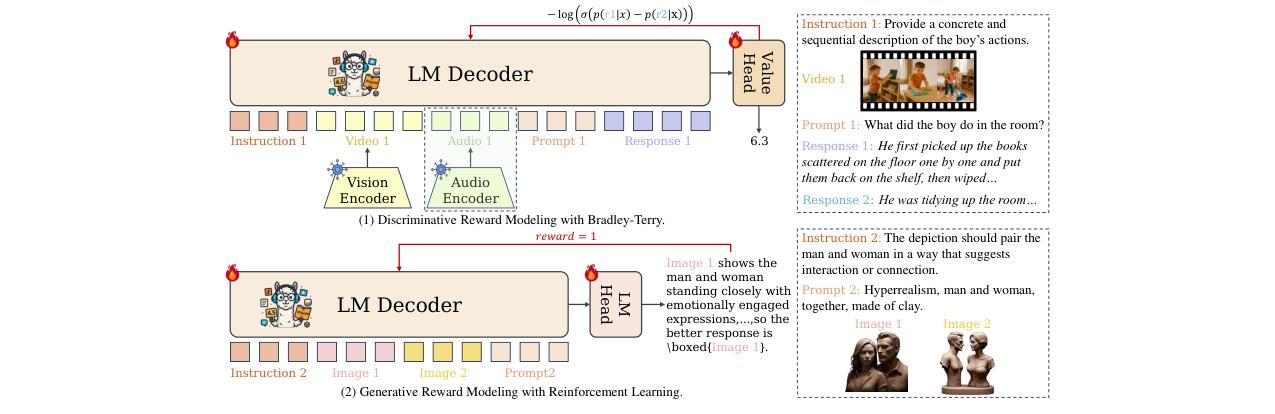
图3:Omni-RewardBench上各任务间性能的皮尔逊相关系数热力图。可见理解任务(如T2T, TI2T, TV2T)之间、生成任务(如T2V, T23D, TI2I)之间存在较强相关性,说明RM在这些任务类别内能捕捉到共通的模式。
公开基准评测结果(VL-RewardBench):
| 模型 | Overall Acc |
|---|---|
| Omni-RewardModel-BT | 76.3 |
| Skywork-VL-Reward | 73.1 |
| IXC-2.5-Reward | 65.8 |
| UnifiedReward | 66.1 |
| GPT-4o | 65.8 |
结论:Omni-RewardModel在专注于视觉语言奖励建模的公开基准上取得了SOTA性能,说明其在“通用偏好”建模上同样强大。
⚖️ 评分理由
- 学术质量:6.5/7。论文工作完整、扎实,问题定义准确,解决方案系统化(基准+数据+模型),实验设计合理且结果有力。主要扣分点在于模型架构(Omni-RewardModel)本身是现有技术的组合应用,针对“自由格式偏好理解”的建模深度有限,创新性更多体现在数据和评测体系构建上。
- 选题价值:1.8/2。奖励模型是AI对齐的核心组件。将奖励建模扩展至全模态并支持自由偏好,是顺应多模态大模型发展的关键且紧迫的需求。该工作为这一新方向奠定了重要基础,具有很高的前瞻性和实用价值。
- 开源与复现加成:0.9/1。论文承诺开源所有核心资源(Benchmark, Data, Model, Code),并提供了详细的训练设置(尽管部分具体超参数在正文中省略),这极大地提升了工作的可信度和可复现性。扣0.1分是因为正文对训练细节的描述可以更详尽。