📄 NExT-OMNI: Towards Any-to-Any Omnimodal Foundation Models with Discrete Flow Matching
#多模态模型 #流匹配 #跨模态检索 #语音对话系统 #模型评估
🔥 8.0/10 | 前25% | #多模态模型 | #流匹配 | #跨模态检索 #语音对话系统
学术质量 5.8/7 | 选题价值 1.7/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Run Luo (中国科学院深圳先进技术研究院、中国科学院大学)
- 通讯作者:未明确说明(论文中未以“Corresponding author”标注单独作者,但提供了多个联系邮箱)
- 作者列表:
- Run Luo (中国科学院深圳先进技术研究院, 中国科学院大学)
- Xiaobo Xia (新加坡国立大学, 中国科学技术大学) *
- Lu Wang (Rtizz-AI)
- Longze Chen (中国科学院深圳先进技术研究院, 中国科学院大学)
- Renke Shan (Rtizz-AI)
- Jing Luo (中国科学院深圳先进技术研究院, 中国科学院大学)
- Min Yang (中国科学院深圳先进技术研究院, 深圳大学) *
- Tat-Seng Chua (新加坡国立大学)
- 标注的作者在作者列表中被提及为通讯作者。
💡 毒舌点评
亮点在于论文提出了一个干净利落的统一框架(DFM),避免了自回归范式在理解/生成任务间的先天矛盾,并且在跨模态检索这类需要深度融合表征的任务上展现了架构优势。短板在于其核心生成能力(如文本生成图像)的绝对质量与FLUX等专用模型的差距可能被“统一”的光环所掩盖,且论文中“动态长度生成策略”等优化的具体效果有待更细粒度的分析。
🔗 开源详情
- 代码:提供GitHub仓库链接:https://github.com/ritzz-ai/Next-OMNI。
- 模型权重:论文提到为开源模型,并提供了模型检查点。
- 数据集:论文详细列出了训练所用的公开和合成数据集(表8),并说明了数据构建过程。部分专有数据未公开。
- Demo:论文中未提及在线演示链接。
- 复现材料:提供了极其详细的训练三阶段(PT, CPT, SFT)的配方,包括数据规模、图像/音频处理设置、学习率、模型初始化等关键信息。附录中对模型设计(编码器、解码头)、数据合成和额外实现细节有补充说明。
- 引用的开源项目:论文明确依赖并提及了Qwen2.5系列、CLIP-ViT、Whisper、FLUX、VQVAE、UniTok、WavTokenizer、GradNorm等多个开源模型和工具。
- 总结:论文在开源方面做得非常出色,为该工作的复现和后续研究提供了坚实基础。
📌 核心摘要
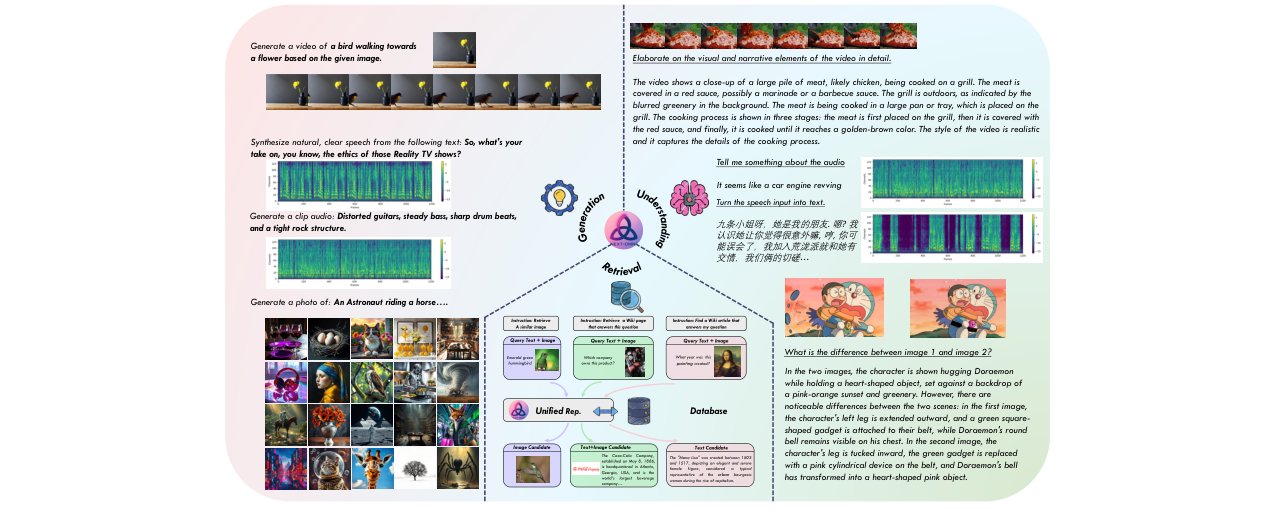
本文旨在解决现有自回归多模态模型在平衡理解与生成能力方面的内在局限,以及混合/解耦设计带来的冗余和适用性窄的问题。其核心是提出NExT-OMNI,一个基于离散流匹配(DFM)范式的开源全模态基础模型。与依赖AR的解耦模型不同,NExT-OMNI采用度量诱导概率路径和动力学最优速度,通过单一的双向注意力骨架,实现了文本、图像、视频、音频间任意到任意的生成与理解。模型在统一表征建模阶段引入重建损失,以保留细粒度信息,并设计了动态生成策略和自适应缓存以提升推理效率。在多个基准上,NExT-OMNI在全模态理解(平均分39.7 vs. OpenOmni 36.5)、多轮视觉交互(OpenING平均55.0)、语音交互(Spoken QA)以及跨模态检索(平均32.9)任务上均表现出竞争力或优于现有统一模型。实验验证了DFM架构在统一建模上的潜力,尤其是在需要深度特征融合的检索任务中。其主要局限性是目前模型规模仅为7B,且受限于资源,未能在更大规模上验证其性能上限。论文为构建下一代统一多模态基础模型提供了新的范式参考。
🏗️ 模型架构
NExT-OMNI是一个端到端的全模态统一模型,其核心思想是用离散流匹配(DFM)替代自回归(AR)作为统一的生成与理解范式。
完整输入输出流程: 模型接受交错的文本、图像、音频、视频指令。输入首先经过各自的分词/编码器转换为离散令牌序列。模型主干(一个基于LLM初始化的Transformer)在训练时,接收一个被部分噪声破坏的序列(从完全随机噪声到目标序列的中间状态),并预测目标序列的每个位置的令牌。在推理时,从完全随机噪声开始,通过多步迭代去噪过程,逐步还原出目标令牌序列,最终经模态头解码为相应的模态输出。
主要组件与数据流:
模态编码器:
- 视觉编码器:基于CLIP-ViT-Large初始化,通过统一表征预训练,将图像编码为离散视觉令牌。采用多码本量化(MCQ),码本大小为4×4096。
- 音频编码器:基于Whisper-Turbo初始化,同样通过统一表征预训练,将音频编码为离散音频令牌。码本大小为2×2048。
- 功能:这两个编码器不仅用于理解,也通过其量化器和解码器参与生成训练,实现了“一个编码器服务于理解与生成”的统一设计,避免了模型冗余。编码器输出的连续代表性向量(
c_zq)会经过投影与文本嵌入对齐,这比直接使用离散令牌索引提供了更丰富的信息。
主干网络(Backbone):
- 基于Qwen2.5-7B的预训练权重初始化。
- 采用多模态自注意力机制,在每一层实现不同模态令牌间的深度双向信息融合,而非依赖解耦的MoE/MoT机制。这是支持跨模态检索等需要深度融合任务的关键。
- 训练时保留了输出层的一个位置偏移操作,以继承AR模型的next-token预测能力,有助于理解任务。
模态头(Modality Heads):
- 功能:从主干输出的隐藏状态解码出各模态的离散令牌。由于采用MCQ,视觉和音频需要预测多个子码本索引。
- 结构:论文设计了两种轻量级头部:一种是自回归的多子码本预测(如图7左侧),另一种是并行的多令牌预测(图7右侧)。最终选择了更稳定的前者。
- 优势:与需要额外扩散/流匹配头的模型不同,DFM范式只需轻量级解码头,提高了训练和推理效率。
离散流匹配(DFM)训练范式:
- 核心:定义从噪声分布到目标分布的概率路径。训练时,采样一个时间步
t和从该路径采样的带噪序列x_t,模型预测目标序列x_1的分布。 - 损失:主要包含预测的交叉熵损失(
L_ce)和来自模态编码器的重建损失(L_rec)。后者防止模型过度偏向高层语义而丢失细节信息。 - 推理:使用Euler求解器模拟连续时间马尔可夫链,从
t=0(纯噪声)逐步迭代到t=1(目标序列),实现并行去噪。
- 核心:定义从噪声分布到目标分布的概率路径。训练时,采样一个时间步
训练与推理优化策略:
- 动态长度生成策略(DGS):训练时将响应填充至块大小的倍数;推理时根据
<EOS>置信度动态调整生成长度块,提升文本生成灵活性。 - 自适应缓存(Adaptive Cache):缓存指令部分特征,响应生成时根据特征余弦相似度选择性更新,结合DFM的并行解码,实现了比AR模型更快的推理速度(约1.2倍)。
- 动态长度生成策略(DGS):训练时将响应填充至块大小的倍数;推理时根据
架构图引用:
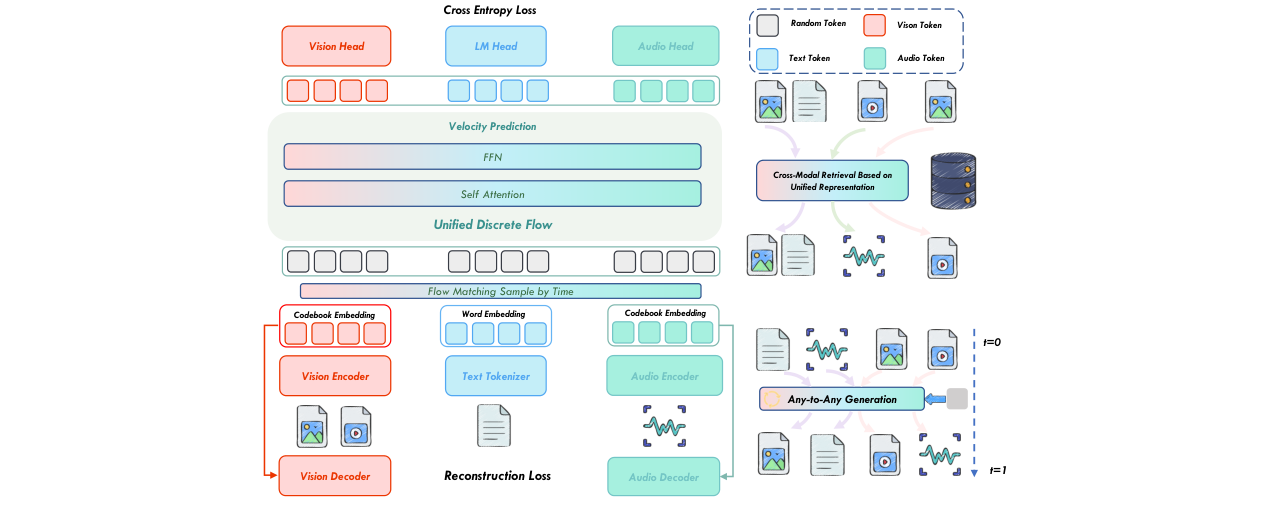
描述:该图展示了NExT-OMNI的整体框架,体现了其作为统一全模态模型的能力,包括对文本、图像、音频的任意到任意理解、生成与检索任务,并通过统一表征和并行处理实现高效响应。
描述:该图详细展示了NExT-OMNI的技术流水线。左侧显示了各模态编码器和分词器将输入转换为统一表征;中间是基于DFM的统一建模主干,通过多模态自注意力进行深度融合;右侧为生成(从x_t到x_1的流采样)和检索任务。训练使用了重建损失和交叉熵损失。
💡 核心创新点
- 首个完全基于离散流匹配(DFM)的全模态统一架构:摒弃了AR范式及其混合/解耦变体,利用DFM的并行去噪和迭代优化特性,从原生架构层面平衡了理解与生成任务,并支持更灵活的跨模态交互。
- 重建增强的统一表征建模:在模态编码器预训练和DFM训练中持续引入重建损失,约束编码器保留低层细节信息。这缓解了统一表征在理解和生成任务间的粒度冲突,并为跨模态检索提供了更丰富、融合的特征。
- 针对效率的工程创新:设计了动态长度生成策略以适应变长理解任务,并实现了基于特征相似性的自适应缓存机制。结合DFM的并行解码优势,使得该统一模型在响应速度上超越了传统AR模型。
- 扩展的统一模型应用场景:通过上述架构和表征设计,NExT-OMNI在跨模态检索任务上展现了显著优势(表4),证明了其统一表征不仅服务于生成/理解,还能泛化到更广泛的信息检索场景。
🔬 细节详述
- 训练数据:
- 数据集与规模:采用大规模交错多模态数据,分三阶段训练。预训练(PT)阶段使用约83M图文对和22M音频-文本对;持续预训练(CPT)阶段引入更高分辨率图像、长文本、视频(提取8帧)和长音频(分段),数据量显著增加;监督微调(SFT)阶段使用约19M指令数据,涵盖各模态交互任务。数据来源包括LAION, DataComp, LibriSpeech, WenetSpeech, MMC4-Core, OmniCorpus等公开数据集,以及部分专有数据。此外,还合成了5M高质量图像生成数据(Gen-5M)和4M复杂理解指令数据(Und-4M)。
- 损失函数:
- 总训练损失(公式3):
L_overall = λ1·L_ce + λ2·L_rec^V + λ3·L_rec^A。 L_ce:DFM的交叉熵损失(公式2),预测目标序列。L_rec^V / L_rec^A:视觉/音频模态的重建损失,包含像素/频谱重建、感知损失、判别器损失和VQ损失。- 权重
λ1, λ2, λ3使用GradNorm动态调整。
- 总训练损失(公式3):
- 训练策略:
- 学习率:模态编码器/解码器预训练为2e-5,联合训练时降至1e-6;主干网络在联合训练时为1e-4。
- 优化器:未明确说明,推测为AdamW。
- 训练效率:采用单模态批量训练和梯度累积实现多任务联合训练,相比随机混合训练,效率提升1.4倍。
- 其他:分类器-free guidance概率设为0.1(生成任务),响应填充块大小为64(理解任务)。
- 关键超参数:
- 模型规模:主干为Qwen2.5-7B,模态头约128M参数,总参数约7.1B。
- 码本大小:视觉编码器4×4096,音频编码器2×2048。
- 图像分辨率:预训练256×256,后续384×384,下采样率16。
- 音频长度:预训练最大15秒,后续支持更长(分段处理)。
- 视频处理:统一提取8帧作为多图输入。
- 训练硬件:论文中未明确说明GPU型号、数量和训练时长。
- 推理细节:
- 采样器:采用Euler求解器,按附录A的步骤迭代。
- 动态生成:响应长度以64为块单位,根据
<EOS>置信度(阈值0.75)动态扩展。 - 缓存:指令特征在推理全程缓存;响应特征在去噪步骤间基于余弦相似度选择性更新。
- 正则化/稳定技巧:未特别提及除GradNorm外的其他技巧。
📊 实验结果
论文在理解、生成、交互、检索四个维度进行了全面评估。
- 全模态理解(表1):在OmniBench、WorldSense和AV-Odyssey三个基准上,NExT-OMNI在多种模态组合输入下均取得最佳或次佳性能。平均分达到39.7,相比之前的SOTA模型OpenOmni(36.5)提升了3.2个绝对点。
| 模型 | OmniBench (T+V/T+A/T+A+V) | WorldSense (A/T+A/T+A+V) | AV-Odyssey | AVG |
|---|---|---|---|---|
| OpenOmni | 38.3/36.7/37.4 | 34.1/38.9/37.2 | 32.8 | 36.5 |
| NExT-OMNI | 41.4/39.5/40.7 | 37.2/42.1/40.5 | 36.4 | 39.7 |
- 多轮语音交互(表2):在Spoken QA(LLaMA Q./Web Q.)基准上,NExT-OMNI在语音到文本(S→T)和语音到语音(S→S)任务上表现出与顶尖AR模型(如Stream-Omni)相当或更优的性能。S→T平均分62.0,S→S平均分47.4。
| 模型 | Llama Q. (S→T/S→S) | Web Q. (S→T/S→S) | AVG |
|---|---|---|---|
| Stream-Omni | 76.3/65.0 | 44.2/27.5 | 60.3/46.3 |
| NExT-OMNI | 78.4/66.4 | 45.6/28.3 | 62.0/47.4 |
- 多轮视觉交互(表3):在OpenING基准上,NExT-OMNI在GPT和IntJudge两种评估方式下的平均分达到55.0,显著超过了VILA-U (48.4)、SEED-X (50.2) 和 MMaDA (47.7) 等模型。
| 模型 | GPT Evaluation (AVG) | IntJudge Evaluation (AVG) | OVERALL AVG |
|---|---|---|---|
| SEED-X | 50.2 | 50.2 | 50.2 |
| MMaDA | 47.7 | 47.7 | 47.7 |
| NExT-OMNI | 55.0 | 55.0 | 55.0 |
- 多模态检索(表4):在InfoSeek、OVEN、FashionIQ和CIRR四个检索基准上,NExT-OMNI平均Top-5准确率达到32.9,超过了所有对比模型,包括采用解耦表征的FUDOKI (30.5) 和MMaDA (31.8)。这有力证明了其统一表征在特征相似性任务上的优势。
| 模型 | 范式 | 表征 | 平均准确率 |
|---|---|---|---|
| Bagel | AR+Diff. | 解耦 | 28.5 |
| MMaDA | 离散扩散 | 统一 | 31.8 |
| NExT-OMNI | DFM | 统一 | 32.9 |
描述:该表格展示了不同模型在四个多模态检索基准上的Top-5检索准确率。NExT-OMNI在所有任务上均取得最高平均分,突出了DFM范式与统一表征在检索任务上的优势。
- 消融实验(表5):验证了各关键组件的贡献。将AR替换为DFM后,生成(GenEval 53.4→59.8)和检索性能提升,但理解略有下降。引入统一表征后,检索进一步提升(InfoSeek 28.3→32.8),但因粒度冲突导致其他任务下降。加入动态生成策略(DGS)后,理��任务大幅回升。最后加入重建损失,所有任务均达到最佳,证明其平衡了细粒度与语义信息。
| 范式 | 表征 | DGS | 重建损失 | VQAv2 | AudioCaps | GenEval | Spoken QA | InfoSeek | OVEN | AVG |
|---|---|---|---|---|---|---|---|---|---|---|
| AR | 解耦 | × | × | 55.2 | 62.8 | 53.4 | 16.4 | 28.3 | 32.1 | 41.4 |
| DFM | 统一 | ✓ | ✓ | 56.2 | 63.4 | 62.6 | 21.7 | 33.7 | 36.1 | 45.6 |
⚖️ 评分理由
- 学术质量(6.0/7):论文的创新性体现在将DFM范式系统性地应用于全模态统一建模,并设计了配套的训练与推理优化方案。技术路线清晰,实验设计全面,覆盖了模型的多方面能力。主要证据来自与前沿AR/混合模型的对比,结果可信。扣分点在于:1) 论文声称“更快响应”,但仅给出了与AR架构比较的相对加速比(1.2x),缺乏绝对时间对比;2) 对于DFM在不同模态间平衡训练的具体挑战和解决方案的讨论可更深入。
- 选题价值(1.7/2):选题处于多模态大模型研究的最前沿,旨在解决当前技术路径的根本矛盾,具有很高的理论和应用价值。其对语音模态的原生集成,对构建下一代语音交互系统具有直接启示。
- 开源与复现加成(+0.5/1):论文提供了完整的代码库(GitHub链接)、详细的训练数据配方(表8)、阶段化的超参数设置(表9)以及模型权重。这极大地促进了学术界和工业界的复现与跟进研究,是工作的一大亮点。