📄 MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
#基准测试
✅ 7.5/10 | 前50% | #基准测试 | #模型评估
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Dingdong Wang(香港中文大学)
- 通讯作者:未说明
- 作者列表:Dingdong Wang(香港中文大学),Junan Li(香港中文大学),Jincenzi Wu(香港中文大学),Dongchao Yang(香港中文大学),Xueyuan Chen(香港中文大学),Tianhua Zhang(香港中文大学),Helen M. Meng(香港中文大学)
💡 毒舌点评
这篇论文的核心贡献在于构建了一个任务体系非常庞大、且强调语言学理论指导的语音理解基准,其对“听觉细节”(如韵律、语音学)的侧重确实弥补了现有SLU基准只关注语义的盲区。然而,作为一篇Benchmark论文,它在提出评估标准后,并未对如何改进模型以攻克这些新挑战给出方法论层面的洞察,其价值更偏向于“诊断”而非“治疗”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。本文是基准论文,不涉及提出新模型。
- 数据集:已公开。论文明确指出基准数据集在Hugging Face上可用:https://huggingface.co/datasets/ddwang2000/MMSU。
- Demo:未提及。
- 复现材料:附录提供了非常详细的数据构建细节,包括数据来源列表、任务定义与示例、数据分布、错误案例分析、以及GPT-4o的使用提示,这有助于理解基准构建过程。
- 论文中引用的开源项目:引用了多个用于数据构建的开源数据集(如MELD, GigaSpeech, CommonVoice, Switchboard等)和模型(如Whisper, GPT-4o)。
📌 核心摘要
- 要解决什么问题:现有语音大模型(SpeechLLMs)的评估基准主要关注语义内容,忽略了语音中丰富的声学特征(如韵律、重音、副语言特征)以及基于这些特征的复杂推理能力,导致对模型真实语音理解能力的评估不全面。
- 方法核心:提出MMSU基准,包含5000个由专家精心设计和审核的“音频-问题-答案”三元组,覆盖47个细粒度任务,这些任务系统性地根植于语言学理论(包括语音学、韵律学、修辞学、句法学、语义学和副语言学)。
- 与已有方法相比新在哪里:与现有基准相比,MMSU首次系统性地将语言学理论融入任务设计,覆盖了更广泛的声学特征(如口音、语速变化、停顿、延长音、非言语声音等),并强调了基于声学线索的推理任务(如基于韵律的推理、讽刺检测、双关语解释)。
- 主要实验结果:对22个先进的SpeechLLMs和OmniLLMs进行了评估。结果显示,当前模型与人类表现存在显著差距:最佳人类评估者平均准确率为89.72%,而表现最好的模型(Gemini-1.5-Pro)仅为60.68%。模型普遍在语音学(如近音感知、音节感知)和部分推理任务(如讽刺检测、对联匹配)上表现不佳。噪声实验表明模型确实利用了声学信号,而非仅依赖文本统计。关键性能对比见下表。
| 模型 | 参数量 | 感知平均准确率 (%) | 推理平均准确率 (%) | 总体平均准确率 (%) |
|---|---|---|---|---|
| Human | - | 91.24 | 86.77 | 89.72 |
| Gemini-1.5-Pro | - | 46.10 | 76.16 | 60.68 |
| Qwen2.5-Omni-7B | 7B | 42.50 | 79.83 | 60.57 |
| Kimi-Audio | 7B | 43.52 | 76.03 | 59.28 |
| MiniCPM-o | 8.6B | 40.54 | 73.57 | 56.53 |
| GPT-4o-Audio | - | 39.67 | 71.96 | 56.38 |
| Random Guess | - | 24.90 | 25.02 | 25.37 |
- 实际意义:MMSU为全面评估语音大模型在真实、复杂语音交互中的能力提供了新的标准,其发现(如模型在声学细节感知上的普遍短板)为未来模型的训练和改进指明了具体方向。
- 主要局限性:1) 基准规模(5000题)相对于47个任务来说,每个任务平均数据量有限;2) 所有任务均为选择题,可能无法完全模拟真实世界中开放式、生成式的语音交互场景;3) 作为评估基准,论文本身并未提出提升模型在MMSU上表现的新方法。
🏗️ 模型架构
本文并非提出一个新的语音大模型架构,而是提出了一个用于评估现有语音大模型的基准框架。其架构设计体现在基准本身的结构上。
MMSU的评估框架采用三层级结构(如图1和图2所示):
- 第一层:区分感知能力与推理能力。感知任务侧重于提取基本音频信息(如识别重音、语调、口音),而推理任务则需要整合声学信息与语义上下文,进行更深层的认知处理(如讽刺检测、语境推理)。
- 第二层:在感知和推理维度下,进一步划分为语言学和副语言学两大类。语言学涵盖语音的结构和意义,副语言学研究声音特征(如情绪、音调)对语义解释的影响。
- 第三层:对上述分类进行细分。语言学下分为语义学和语音学;副语言学下分为说话者特征(如音色、身份)和说话风格(如音高、语速、情感)。每一类都对应具体的评估任务。
评估流程是标准化的:每个实例由一段音频和一个问题组成,模型需要从四个选项(A-D)中选择一个答案。为避免位置偏差,选项顺序随机化。所有模型使用相同的优化指令提示进行评估。

图1:MMSU基准概览图,展示了其三大特征及任务示例。
图2:MMSU任务分类法(Task taxonomy)示意图,清晰展示了47个任务在感知/推理、语言学/副语言学等维度的系统划分。
💡 核心创新点
- 系统性整合语言学理论:将语音学、韵律学、修辞学等语言学子领域的理论系统地融入基准的任务设计,而非零散地考察个别现象。这使得评估具有坚实的理论基础,能更全面地捕捉语音理解的复杂性。
- 强调真实世界声学特征与数据:基准优先使用真实世界录音而非合成语音,并涵盖了口音、非言语声音、语误等在日常交流中常见但被先前基准忽略的声学现象,提高了评估的生态效度。
- 设计细粒度感知与推理任务:创建了47个新颖任务,特别是涉及声学线索的推理任务(如基于重音、停顿、延长音的推理),以及考察语音学知识(如近音感知、音节感知)的任务,这些任务在以往的语音理解基准中很少出现。
🔬 细节详述
- 训练数据:本基准是用于评估的数据集,本身不涉及模型训练。其构建数据来源包括:
- 开源数据集:占总数据的76.74%,如MELD, GigaSpeech, CommonVoice, Switchboard等,提供真实对话、情感语音、多口音等。
- 定制录音:占13.44%,与专业配音演员和15名不同背景的说话者合作,针对韵律、重音等任务录制高质量音频。
- 合成音频:占9.82%,使用Azure TTS的20种不同声音生成,用于补充部分语义任务。
- 损失函数:未说明(本文为基准论文,不涉及模型训练)。
- 训练策略:未说明。
- 关键超参数:未说明。论文评估了参数量从3B到不公开的各种模型。
- 训练硬件:未说明。
- 推理细节:所有模型使用相同的优化指令跟随提示进行评估,采用选择题形式(从A-D中选择)。为避免偏差,答案选项顺序在数据集中随机化。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文对22个模型进行了全面评估,并进行了任务分析、噪声实验和错误分析。
主要评估结果(详见论文表3):已用Markdown表格列出。结果显示,最强模型Gemini-1.5-Pro(60.68%)与人类基线(89.72%)仍有近30个百分点的差距,说明基准具有挑战性。开源模型(如Qwen2.5-Omni-7B)与闭源模型(如Gemini-1.5-Pro)性能接近。模型普遍在语音学和副语言学相关任务上表现较弱。
任务特定性能分析(图4):
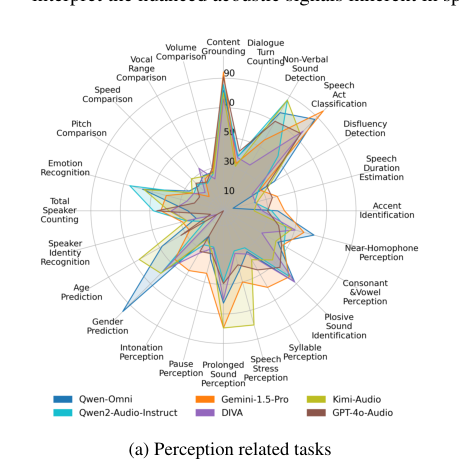
图4:不同模型在感知和推理各类任务上的准确率分布热力图,揭示了模型在不同任务上的能力差异。
- 模型在诸如近音感知、辅元音感知、音节感知等语音学感知任务上普遍表现很差。
- 在讽刺检测、对联匹配、背景场景识别等复杂推理任务上也面临挑战。
- 不同模型有各自的优势任务,如GPT-4o-Audio在情绪识别和语调感知上表现不佳,而Qwen2.5-Omni在性别预测上突出。
噪声条件下的性能(图5a):
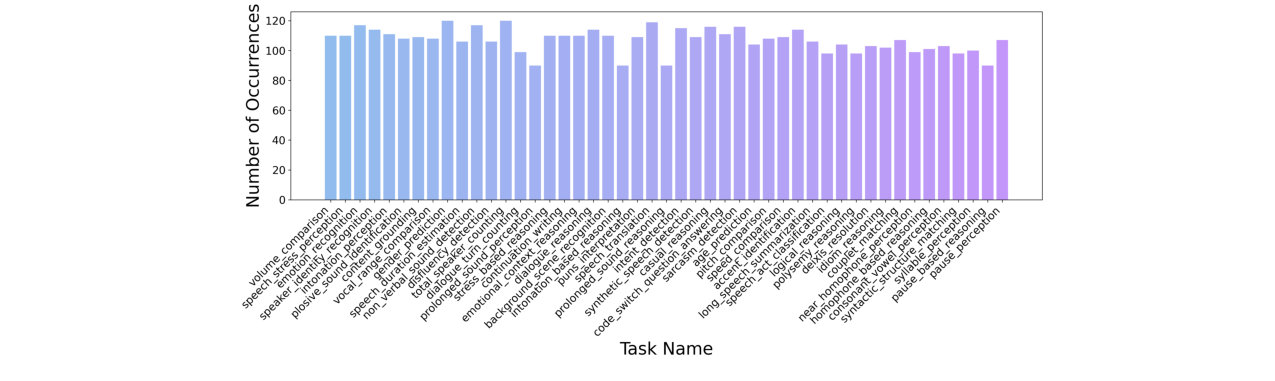
图5(a):噪声实验对比图。向音频输入中添加高斯噪声,结果显示所有模型性能仅有小幅下降,表明模型确实在利用声学信号。
- 在添加噪声后,模型性能下降幅度有限,证实模型并非仅依赖文本或统计偏差。
错误分析(表4):
- 分析了GPT-4o-Audio等五个代表性模型的错误类型。感知错误(Perceptual Errors) 是所有模型最主要的失败原因,占比约50%,这再次印证了模型在声学特征感知上的短板。
数据分布(图6):

图6:MMSU数据集中每个任务的数据量分布柱状图,显示数据分布均衡。
⚖️ 评分理由
- 学术质量:5.5/7。论文系统性地构建了一个具有语言学理论基础的、覆盖广泛的语音理解基准,实验评估充分,分析深入,质量控制严格(专家参与)。扣分点在于:作为一篇Benchmark论文,其核心创新在于“评估什么”和“如何评估”,而非提出解决这些问题的“新方法”,技术上的突破性有限。
- 选题价值:1.5/2。选题切中当前语音大模型评估的关键空白(忽略声学细节和复杂推理),前沿性强。该基准为社区提供了宝贵的评估工具,能直接推动模型在这些被忽视维度上的改进,具有很高的实用价值和影响力。
- 开源与复现加成:0.3/1。论文明确提供了数据集的HuggingFace链接(https://huggingface.co/datasets/ddwang2000/MMSU),并在附录中详细说明了数据构建过程、来源和任务定义,复现性较好。但未提供完整的代码仓库(如数据清洗、评估脚本),也未开源任何评估用的模型权重,因此加成有限。