📄 MindMix: A Multimodal Foundation Model for Auditory Perception Decoding via Deep Neural-Acoustic Alignment
#多模态模型 #音频分类 #预训练 #对比学习 #跨模态
🔥 9.0/10 | 前10% | #音频分类 | #多模态模型 | #预训练 #对比学习
学术质量 6.5/7 | 选题价值 1.8/2 | 复现加成 0.7 | 置信度 高
👥 作者与机构
- 第一作者:Rui Liu(香港理工大学)
- 通讯作者:Jibin Wu(香港理工大学),Kay Chen Tan(香港理工大学)
- 作者列表:Rui Liu(香港理工大学),Zhige Chen(香港理工大学),Shu Peng(香港理工大学),Wenlong You(香港理工大学),Zhi-An Huang(香港城市大学(东莞)),Jibin Wu(香港理工大学),Kay Chen Tan(香港理工大学)
💡 毒舌点评
亮点:这篇论文最大的亮点是“用事实说话”——它不像许多基础模型论文那样只提理论创新,而是直接用一套横跨注意力解码、情感分析、音乐检索的“组合拳”实验结果,无可辩驳地证明了其提出的CALRA模块在建立深度神经-声学对齐上的巨大威力,尤其是在AAD任务上近乎100%的准确率堪称惊艳。 短板:然而,论文也坦承了“配对数据稀缺”这一阿喀琉斯之踵。当前实验所用的100多小时对齐数据量,相对于其宣称的“基础模型”定位和庞大的单模态预训练数据(3500+小时)而言仍显单薄,这限制了我们对模型在更复杂、更嘈杂的真实世界声学场景下是否依然如此“全能”且“鲁棒”的判断。
📌 核心摘要
这篇论文旨在解决现有EEG基础模型在听觉感知解码任务中效果有限的问题,其根源在于模型缺乏与声学刺激信息的深度耦合。作者提出了MindMix,一个专门为学习神经-声学对齐表征而设计的多模态基础模型。与以往方法相比,MindMix的创新在于:1) 采用两阶段训练,先用大规模单模态EEG数据预训练一个高容量编码器,再用配对的EEG-音频数据进行跨模态对齐;2) 引入了一个新颖的“跨注意力低秩对齐”(CALRA)模块,该模块包含类型特定对齐器、双向跨注意力机制和共享低秩融合,实现了模态间细粒度的深度交互。在听觉注意力解码(AAD)、听觉情感识别和跨模态音乐检索等多个任务上的实验表明,MindMix显著超越了现有的任务特定模型和单模态基础模型。例如,在KUL数据集上的AAD任务,MindMix达到了99.82%的平衡准确率,远超最强基线DARNet的94.81%。该工作为多模态脑解码和听觉脑机接口的研究奠定了重要基础。其主要局限性在于,当前领域内大规模配对EEG-音频语料库的稀缺,限制了对模型性能缩放定律的进一步探索。
详细分析
01.模型架构
MindMix采用双流架构,通过对比学习目标在共享嵌入空间中对齐EEG和音频表征。整体流程如图1所示:输入一对EEG片段(\(S_{EEG}\))和音频片段(\(S_{Audio}\)),分别通过各自的编码器生成初始嵌入(\(E_{proj}, A_{proj}\)),然后输入核心的CALRA模块进行深度交互和对齐,输出最终对齐嵌入(\(E_{aligned}, A_{aligned}\)),用于对比损失计算。
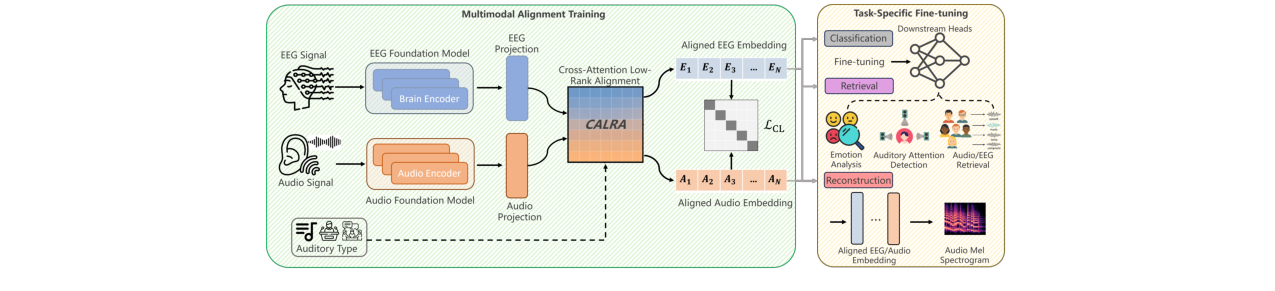
图1:MindMix整体框架图。展示了从输入EEG-音频对,经过双流编码器、CALRA模块,到对比学习输出的完整流程。
- EEG编码器(\(f_{EEG}\)):
- 功能:从嘈杂、多通道的EEG信号中提取鲁棒的、可迁移的神经表征。
- 内部结构与关键设计:
- 通道无关分块:为处理不同数据集间电极配置的差异性,将每个EEG通道独立分割为固定长度的时间块,再通过1D卷积得到初始嵌入。这种策略允许模型处理异构通道配置。
- 离散神经表征:引入共享码本将初始嵌入量化为离散的神经令牌(\(v \in \mathcal{V}\)),旨在学习更结构化、更鲁棒的表征。
- 位置与空间嵌入:在量化后的令牌上添加可学习的时间位置嵌入(T)和空间(通道)嵌入(E)。空间嵌入将标准10-20系统的电极名称映射为向量,使模型能区分不同通道的解剖来源,无论总通道数如何变化。
- 预训练目标:EEG编码器通过多任务自监督目标进行预训练,如图2所示。
- 掩码令牌预测:随机掩码部分块嵌入,主Transformer编码器根据可见部分预测被掩码的原始神经令牌,损失为\(L_M\)。
- 频谱重构:并行的一个较小Transformer编码器从未掩码嵌入重构原始块的傅里叶频谱(幅度A和相位ψ),损失为\(L_S\)。
图2:EEG编码器的多任务预训练架构。展示了掩码令牌预测(主分支)和频谱重构(辅助分支)两个并行任务。
- 音频编码器(\(f_{Audio}\)):
- 功能:提取音频的高阶语义表征。
- 结构:采用预训练的Wav2Vec 2.0模型作为骨干,提取其最后隐藏状态序列,经平均池化后通过线性投影层得到初始音频嵌入\(A_{proj}\)。
- 跨注意力低秩对齐模块(CALRA):
- 功能:实现EEG和音频表征的深度、语境感知的对齐,是MindMix的核心创新。它采用“先精炼,后对比”的策略。
- 三大组件:
- 类型特定对齐器:根据听觉刺激类型(如语音、音乐)将输入嵌入路由到不同的可学习变换(\(f_k\)),以适应不同刺激类型下的神经响应差异。
- 双向跨注意力:在全局嵌入向量层面,让EEG嵌入从音频嵌入检索相关上下文,同时音频嵌入也从EEG嵌入检索神经特征,实现双向信息交互。
- 共享低秩对齐:将跨注意力输出的表征投影到一个共享的低维瓶颈空间,并进行元素级乘积(\(\odot\)),以强制执行双线性交互,捕捉复杂的非线性跨模态依赖关系。最终通过残差连接和层归一化得到对齐后的嵌入。
- 设计动机:CALRA旨在超越简单的线性投影或早期融合(如拼接),通过全局精炼和深度双线性交互,捕捉EEG-Audio之间细粒度的、乘法依赖的映射关系。

图3:CALRA模块结构图。清晰地展示了类型特定对齐、双向跨注意力和共享低秩对齐三个组件的串联流程。
02.核心创新点
- 首个面向听觉解码的多模态基础模型框架(MindMix):区别于主要基于单模态EEG数据训练的基础模型(如LaBraM, EEGPT),MindMix在设计之初就整合了大规模配对的EEG-音频数据,通过两阶段训练(先单模态EEG预训练,再多模态对齐)来显式地学习深度耦合的神经-声学表征。
- 新颖的CALRA对齐模块:CALRA模块是实现深度对齐的技术核心。它通过类型特定路由、双向全局跨注意力以及关键的低秩双线性融合,克服了传统投影对齐(如CLIP)或简单拼接融合在建模EEG-音频复杂关系时的不足,实现了更精细、更强大的模态间交互。
- 大规模、多任务、多数据集的综合验证:论文不仅提出了模型,还在三个具有不同特性的听觉解码任务族(AAD、情感识别、音乐检索)上,使用了六个公开数据集进行了全面评估。实验结果全面超越了强基线,并通过详尽的消融研究验证了每个组件的有效性。
03.细节详述
- 训练数据:
- 阶段1(单模态预训练):使用超过3500小时的EEG数据,来自9个公开数据集,涵盖运动想象、癫痫检测、睡眠分期等多种范式。
- 阶段2(多模态对齐):使用超过100小时的配对EEG-音频数据,来自7个公开数据集,包含音乐、竞争性语音(AAD)和自然故事聆听等多种听觉刺激。
- 预处理:EEG信号经过1-40Hz带通滤波、下采样至200Hz、分割为2秒不重叠的epoch,并进行逐通道z-score标准化。音频信号重采样至16kHz,分割为2秒epoch,并进行峰值归一化。
- 损失函数:整个框架通过端到端的对比学习目标(InfoNCE损失,公式10)进行优化。该损失最大化批次内正确EEG-音频对的余弦相似度,同时最小化错误对的相似度。温度参数τ是可学习的。
- 训练策略:
- 优化器:AdamW(β1=0.9, β2=0.95, weight_decay=0.05)。
- 学习率调度:采用余弦学习率调度,并有10个epoch的线性warmup。峰值学习率:预训练和对齐阶段为1e-4,下游微调阶段为1e-5。
- 批次大小:阶段1为512,阶段2为256,阶段3(下游微调)为64。
- 训练轮数:根据验证集性能收敛情况确定。
- 关键超参数:见下表(摘自论文附录表A2)。
- 训练硬件:8张NVIDIA A6000 GPU。总预训练计算量约240 GPU小时(阶段1约160小时,阶段2约80小时)。
- 推理细节:未提及特殊的解码策略或流式设置,使用2秒决策窗口。
- 正则化技巧:使用了层归一化(Layer Normalization)、残差连接。模型架构中提及了Dropout(论文中未详细说明具体应用位置和比率)。
| 类别 | 超参数 | 值 |
|---|---|---|
| EEG编码器 | Transformer层数 | 12 |
| 嵌入维度 | 200 | |
| 注意力头数 | 10 | |
| 前馈网络维度 | 800 | |
| 分块编码器 | 3层1D CNN | |
| 分块维度 | 200 | |
| 输出通道数 | 8 | |
| CALRA模块 | 输入/输出维度 | 256 |
| 低秩维度 | 128 | |
| 注意力头数 | 4 | |
| FFN隐藏维度 | 512 | |
| 优化器 | 类型 | AdamW |
| 微调学习率 | 1 × 10⁻⁵ | |
| 权重衰减 | 0.01 | |
| Adam Betas | (0.9, 0.95) | |
| Warmup轮数 | 3 |
04.实验结果
论文在三个任务族上进行了评估,主要结果见表2。MindMix在所有任务和指标上均取得了最佳性能,优势显著。
表2:主要性能对比(摘录)
| 任务 | 方法 | 数据集 | 指标1 | 指标2 |
|---|---|---|---|---|
| 语音AAD | DARNet | KUL | Balanced Acc: 0.9481±0.036 | Weighted F1: 0.9567±0.025 |
| MindMix | KUL | Balanced Acc: 0.9982±0.008 | Weighted F1: 0.9991±0.004 | |
| 情感分析 | LaBraM | HR-EEG4EMO | Balanced Acc: 0.7295±0.082 | Weighted F1: 0.7829±0.081 |
| MindMix | HR-EEG4EMO | Balanced Acc: 0.8878±0.045 | Weighted F1: 0.8869±0.046 | |
| 音乐检索 | MusicAAD | MAD-EEG | Duo Acc: 0.9425±0.028 | Trio Acc: 0.8722±0.038 |
| MindMix | MAD-EEG | Duo Acc: 0.9475±0.025 | Trio Acc: 0.8824±0.042 |
关键消融实验(表3):
- CALRA模块有效性:移除CALRA,改用标准共注意力(Co-Attention)或简单拼接MLP(Concat-MLP),性能在AAD(KUL)上从99.82%分别下降至97.85%和95.93%,在情感识别(EEG4EMO)上从88.78%分别下降至86.29%和85.74%。
- EEG编码器选择:将自定义EEG编码器替换为LaBraM或CBraMod骨干,性能也出现明显下降(AAD降至97.44%和96.37%)。
- CALRA组件拆解:移除双向跨注意力(w/o Cross-Attention)导致性能下降最大(AAD降至94.35%),证明其是CALRA最关键的组件。

图4:MindMix全模型与其单模态(EEG-Only)变体的性能对比。直观展示了跨模态对齐带来的巨大性能增益。
神经科学解释:
- Mel频谱重构:从对齐后的EEG嵌入(\(E_{aligned}\))重构音频Mel频谱,MindMix的皮尔逊相关系数(PCC)在DTU和KUL上分别达到0.88和0.91,显著优于基线。
- 空间注意力拓扑图:模型的注意力权重高度集中在左颞叶区域,这与主听觉皮层和语音处理的左侧化现象高度一致,表明模型学习到了具有生物学意义的表征。
图5:神经科学可解释性分析。(a) 从EEG重构的Mel频谱图对比;(b) EEG编码器空间注意力权重的脑地形图,显示了与听觉皮层一致的激活模式。
05.评分理由
- 学术质量(6.5/7):创新性强,提出了首个专门的EEG-音频多模态对齐基础模型。技术方案设计合理,CALRA模块有理论支撑和充分的消融验证。实验极其充分,涵盖了多种任务、多个数据集、多种基线对比以及深入的分析(包括鲁棒性、效率、跨数据集泛化)。结果令人信服,性能提升显著。轻微不足在于对极端数据稀缺情况下的泛化能力探索有限。
- 选题价值(1.8/2):选题处于神经科学、BCI和多模态AI的交叉前沿,具有很高的理论价值和潜在的应用前景(如新型人机交互、神经疾病诊断)。对于关注音频智能和脑科学的读者有很强吸引力。
- 开源与复现加成(0.7/1):论文公开了代码仓库链接,提供了详尽的数据集列表、预处理流程、模型架构细节、全部超参数配置、计算成本分析以及评估协议,复现指引非常完备。主要扣分点是未明确���明是否开源预训练模型权重。
开源详情
- 代码:论文中提供了代码仓库链接:https://github.com/CookieMikeLiu/MindMix。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文中使用的所有数据集均为公开可用,并详细列出了名称、来源和小时数。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了极其详尽的复现材料,包括:标准化数据预处理流程、完整的模型架构描述、所有训练超参数配置(表A2)、分阶段的训练策略、详细的评估协议(包括严格的跨试验评估)、以及计算成本分析。
- 论文中引用的开源项目:依赖的开源模型包括Wav2Vec 2.0、LaBraM、CBraMod、EEGNet等。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:https://github.com/CookieMikeLiu/MindMix。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文中使用的所有数据集均为公开可用,并详细列出了名称、来源和小时数。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了极其详尽的复现材料,包括:标准化数据预处理流程、完整的模型架构描述、所有训练超参数配置(表A2)、分阶段的训练策略、详细的评估协议(包括严格的跨试验评估)、以及计算成本分析。
- 论文中引用的开源项目:依赖的开源模型包括Wav2Vec 2.0、LaBraM、CBraMod、EEGNet等。
🏗️ 模型架构
MindMix采用双流架构,通过对比学习目标在共享嵌入空间中对齐EEG和音频表征。整体流程如图1所示:输入一对EEG片段(\(S_{EEG}\))和音频片段(\(S_{Audio}\)),分别通过各自的编码器生成初始嵌入(\(E_{proj}, A_{proj}\)),然后输入核心的CALRA模块进行深度交互和对齐,输出最终对齐嵌入(\(E_{aligned}, A_{aligned}\)),用于对比损失计算。
MindMix框架概览图] 图1:MindMix整体框架图。展示了从输入EEG-音频对,经过双流编码器、CALRA模块,到对比学习输出的完整流程。
- EEG编码器(\(f_{EEG}\)):
- 功能:从嘈杂、多通道的EEG信号中提取鲁棒的、可迁移的神经表征。
- 内部结构与关键设计:
- 通道无关分块:为处理不同数据集间电极配置的差异性,将每个EEG通道独立分割为固定长度的时间块,再通过1D卷积得到初始嵌入。这种策略允许模型处理异构通道配置。
- 离散神经表征:引入共享码本将初始嵌入量化为离散的神经令牌(\(v \in \mathcal{V}\)),旨在学习更结构化、更鲁棒的表征。
- 位置与空间嵌入:在量化后的令牌上添加可学习的时间位置嵌入(T)和空间(通道)嵌入(E)。空间嵌入将标准10-20系统的电极名称映射为向量,使模型能区分不同通道的解剖来源,无论总通道数如何变化。
- 预训练目标:EEG编码器通过多任务自监督目标进行预训练,如图2所示。
- 掩码令牌预测:随机掩码部分块嵌入,主Transformer编码器根据可见部分预测被掩码的原始神经令牌,损失为\(L_M\)。
- 频谱重构:并行的一个较小Transformer编码器从未掩码嵌入重构原始块的傅里叶频谱(幅度A和相位ψ),损失为\(L_S\)。
图2:EEG编码器的多任务预训练架构。展示了掩码令牌预测(主分支)和频谱重构(辅助分支)两个并行任务。
- 音频编码器(\(f_{Audio}\)):
- 功能:提取音频的高阶语义表征。
- 结构:采用预训练的Wav2Vec 2.0模型作为骨干,提取其最后隐藏状态序列,经平均池化后通过线性投影层得到初始音频嵌入\(A_{proj}\)。
- 跨注意力低秩对齐模块(CALRA):
- 功能:实现EEG和音频表征的深度、语境感知的对齐,是MindMix的核心创新。它采用“先精炼,后对比”的策略。
- 三大组件:
- 类型特定对齐器:根据听觉刺激类型(如语音、音乐)将输入嵌入路由到不同的可学习变换(\(f_k\)),以适应不同刺激类型下的神经响应差异。
- 双向跨注意力:在全局嵌入向量层面,让EEG嵌入从音频嵌入检索相关上下文,同时音频嵌入也从EEG嵌入检索神经特征,实现双向信息交互。
- 共享低秩对齐:将跨注意力输出的表征投影到一个共享的低维瓶颈空间,并进行元素级乘积(\(\odot\)),以强制执行双线性交互,捕捉复杂的非线性跨模态依赖关系。最终通过残差连接和层归一化得到对齐后的嵌入。
- 设计动机:CALRA旨在超越简单的线性投影或早期融合(如拼接),通过全局精炼和深度双线性交互,捕捉EEG-Audio之间细粒度的、乘法依赖的映射关系。
CALRA模块结构图] 图3:CALRA模块结构图。清晰地展示了类型特定对齐、双向跨注意力和共享低秩对齐三个组件的串联流程。
💡 核心创新点
- 首个面向听觉解码的多模态基础模型框架(MindMix):区别于主要基于单模态EEG数据训练的基础模型(如LaBraM, EEGPT),MindMix在设计之初就整合了大规模配对的EEG-音频数据,通过两阶段训练(先单模态EEG预训练,再多模态对齐)来显式地学习深度耦合的神经-声学表征。
- 新颖的CALRA对齐模块:CALRA模块是实现深度对齐的技术核心。它通过类型特定路由、双向全局跨注意力以及关键的低秩双线性融合,克服了传统投影对齐(如CLIP)或简单拼接融合在建模EEG-音频复杂关系时的不足,实现了更精细、更强大的模态间交互。
- 大规模、多任务、多数据集的综合验证:论文不仅提出了模型,还在三个具有不同特性的听觉解码任务族(AAD、情感识别、音乐检索)上,使用了六个公开数据集进行了全面评估。实验结果全面超越了强基线,并通过详尽的消融研究验证了每个组件的有效性。
🔬 细节详述
- 训练数据:
- 阶段1(单模态预训练):使用超过3500小时的EEG数据,来自9个公开数据集,涵盖运动想象、癫痫检测、睡眠分期等多种范式。
- 阶段2(多模态对齐):使用超过100小时的配对EEG-音频数据,来自7个公开数据集,包含音乐、竞争性语音(AAD)和自然故事聆听等多种听觉刺激。
- 预处理:EEG信号经过1-40Hz带通滤波、下采样至200Hz、分割为2秒不重叠的epoch,并进行逐通道z-score标准化。音频信号重采样至16kHz,分割为2秒epoch,并进行峰值归一化。
- 损失函数:整个框架通过端到端的对比学习目标(InfoNCE损失,公式10)进行优化。该损失最大化批次内正确EEG-音频对的余弦相似度,同时最小化错误对的相似度。温度参数τ是可学习的。
- 训练策略:
- 优化器:AdamW(β1=0.9, β2=0.95, weight_decay=0.05)。
- 学习率调度:采用余弦学习率调度,并有10个epoch的线性warmup。峰值学习率:预训练和对齐阶段为1e-4,下游微调阶段为1e-5。
- 批次大小:阶段1为512,阶段2为256,阶段3(下游微调)为64。
- 训练轮数:根据验证集性能收敛情况确定。
- 关键超参数:见下表(摘自论文附录表A2)。
- 训练硬件:8张NVIDIA A6000 GPU。总预训练计算量约240 GPU小时(阶段1约160小时,阶段2约80小时)。
- 推理细节:未提及特殊的解码策略或流式设置,使用2秒决策窗口。
- 正则化技巧:使用了层归一化(Layer Normalization)、残差连接。模型架构中提及了Dropout(论文中未详细说明具体应用位置和比率)。
| 类别 | 超参数 | 值 |
|---|---|---|
| EEG编码器 | Transformer层数 | 12 |
| 嵌入维度 | 200 | |
| 注意力头数 | 10 | |
| 前馈网络维度 | 800 | |
| 分块编码器 | 3层1D CNN | |
| 分块维度 | 200 | |
| 输出通道数 | 8 | |
| CALRA模块 | 输入/输出维度 | 256 |
| 低秩维度 | 128 | |
| 注意力头数 | 4 | |
| FFN隐藏维度 | 512 | |
| 优化器 | 类型 | AdamW |
| 微调学习率 | 1 × 10⁻⁵ | |
| 权重衰减 | 0.01 | |
| Adam Betas | (0.9, 0.95) | |
| Warmup轮数 | 3 |
📊 实验结果
论文在三个任务族上进行了评估,主要结果见表2。MindMix在所有任务和指标上均取得了最佳性能,优势显著。
表2:主要性能对比(摘录)
| 任务 | 方法 | 数据集 | 指标1 | 指标2 |
|---|---|---|---|---|
| 语音AAD | DARNet | KUL | Balanced Acc: 0.9481±0.036 | Weighted F1: 0.9567±0.025 |
| MindMix | KUL | Balanced Acc: 0.9982±0.008 | Weighted F1: 0.9991±0.004 | |
| 情感分析 | LaBraM | HR-EEG4EMO | Balanced Acc: 0.7295±0.082 | Weighted F1: 0.7829±0.081 |
| MindMix | HR-EEG4EMO | Balanced Acc: 0.8878±0.045 | Weighted F1: 0.8869±0.046 | |
| 音乐检索 | MusicAAD | MAD-EEG | Duo Acc: 0.9425±0.028 | Trio Acc: 0.8722±0.038 |
| MindMix | MAD-EEG | Duo Acc: 0.9475±0.025 | Trio Acc: 0.8824±0.042 |
关键消融实验(表3):
- CALRA模块有效性:移除CALRA,改用标准共注意力(Co-Attention)或简单拼接MLP(Concat-MLP),性能在AAD(KUL)上从99.82%分别下降至97.85%和95.93%,在情感识别(EEG4EMO)上从88.78%分别下降至86.29%和85.74%。
- EEG编码器选择:将自定义EEG编码器替换为LaBraM或CBraMod骨干,性能也出现明显下降(AAD降至97.44%和96.37%)。
- CALRA组件拆解:移除双向跨注意力(w/o Cross-Attention)导致性能下降最大(AAD降至94.35%),证明其是CALRA最关键的组件。
MindMix与其单模态变体的性能对比图] 图4:MindMix全模型与其单模态(EEG-Only)变体的性能对比。直观展示了跨模态对齐带来的巨大性能增益。
神经科学解释:
- Mel频谱重构:从对齐后的EEG嵌入(\(E_{aligned}\))重构音频Mel频谱,MindMix的皮尔逊相关系数(PCC)在DTU和KUL上分别达到0.88和0.91,显著优于基线。
- 空间注意力拓扑图:模型的注意力权重高度集中在左颞叶区域,这与主听觉皮层和语音处理的左侧化现象高度一致,表明模型学习到了具有生物学意义的表征。
图5:神经科学可解释性分析。(a) 从EEG重构的Mel频谱图对比;(b) EEG编码器空间注意力权重的脑地形图,显示了与听觉皮层一致的激活模式。
⚖️ 评分理由
- 学术质量(6.5/7):创新性强,提出了首个专门的EEG-音频多模态对齐基础模型。技术方案设计合理,CALRA模块有理论支撑和充分的消融验证。实验极其充分,涵盖了多种任务、多个数据集、多种基线对比以及深入的分析(包括鲁棒性、效率、跨数据集泛化)。结果令人信服,性能提升显著。轻微不足在于对极端数据稀缺情况下的泛化能力探索有限。
- 选题价值(1.8/2):选题处于神经科学、BCI和多模态AI的交叉前沿,具有很高的理论价值和潜在的应用前景(如新型人机交互、神经疾病诊断)。对于关注音频智能和脑科学的读者有很强吸引力。
- 开源与复现加成(0.7/1):论文公开了代码仓库链接,提供了详尽的数据集列表、预处理流程、模型架构细节、全部超参数配置、计算成本分析以及评估协议,复现指引非常完备。主要扣分点是未明确���明是否开源预训练模型权重。