📄 MIAM: Modality Imbalance-Aware Masking for Multimodal Ecological Applications
#生态计算 #数据增强 #多模态模型 #鲁棒性
🔥 8.5/10 | 前25% | #生态计算 | #数据增强 | #多模态模型 #鲁棒性
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Robin Zbinden(洛桑联邦理工学院,EPFL)
- 通讯作者:Robin Zbinden(robin.zbinden@epfl.ch,洛桑联邦理工学院,EPFL)
- 作者列表:
- Robin Zbinden(洛桑联邦理工学院,EPFL,*共同第一作者)
- Wesley Monteith-Finas(洛桑联邦理工学院,EPFL,*共同第一作者)
- Gencer Sumbul(洛桑联邦理工学院,EPFL)
- Nina van Tiel(洛桑联邦理工学院,EPFL)
- Chiara Vanalli(洛桑联邦理工学院,EPFL)
- Devis Tuia(洛桑联邦理工学院,EPFL)
💡 毒舌点评
这篇论文的亮点在于它将一个看似简单的技术问题(掩码策略)进行了深入的理论形式化,并以此为基础设计出针对性的解决方案,实验部分尤其扎实,在生态数据集上挖掘出的可解释性发现(如NDVI和热浪的影响)也颇具价值。短板在于,其方法核心(动态调整Beta分布参数)依赖于无标签数据下对“模态性能”的估计(如重构损失),这在更通用的无监督场景下可能不稳定,且其有效性在模态数量较少(如仅有2种模态)的场景下可能被削弱。
🔗 开源详情
- 代码:是。提供了完整的开源代码仓库链接:
https://github.com/zbirobin/MIAM。 - 模型权重:是。提供了在HuggingFace上发布的预训练模型权重链接:
https://huggingface.co/zbirobin/MIAM。 - 数据集:GeoPlant和TaxaBench均为公开生态数据集,论文中提供了获取方式(引用原数据集论文)。SatBird也是公开数据集。未提供论文自行创建的新数据集。
- Demo:论文中未提及在线演示。
- 复现材料:提供了极为充分的复现材料,包括:详细的模型架构和超参数设置、训练脚本、数据划分的具体代码(附录A.1)、所有消融实验和基线方法的配置、对关键超参数λ和κ的敏感性分析结果。论文中明确声明致力于可复现性。
- 论文中引用的开源项目:
- AdamW优化器 (Loshchilov & Hutter, 2017)
- Verde库,用于空间分块交叉验证 (Roberts et al., 2017)
- 多模态Transformer架构 (Vaswani et al., 2017; Gorishniy et al., 2021)
- 训练调度方法 (Defazio et al., 2024)
- Token化方法 (Dosovitskiy et al., 2020; Gorishniy et al., 2022)
📌 核心摘要
- 解决的问题:生态应用中的多模态学习面临数据在模态间和模态内缺失的普遍问题,且现有掩码训练策略无法有效应对“模态不平衡”(主导模态阻碍其他模态学习)这一挑战。
- 方法核心:提出MIAM(模态不平衡感知掩码),一种动态掩码策略。其核心是:a) 将掩码策略形式化为单位超立方体上的概率分布;b) 设计一个混合乘积Beta分布,能探索完整的输入组合空间并优先采样超立方体的“角落”(即模态全存在或全缺失的极端情况);c) 根据训练过程中各模态的相对性能(s_m)和学习速度(d_m,性能的绝对导数)动态调整分布参数,对“强势”模态(高性能、学习稳定)施加更高的掩码概率。
- 创新之处:a) 首次系统性地将掩码策略形式化,并指出有效策略应具备全支持、角落优先、不平衡感知三大特性;b) 提出的混合Beta分布设计巧妙地兼顾了探索多样性与关键训练场景;c) 引入基于性能和学习动态的双重动态调整机制,比仅依赖静态性能的OPM方法更有效。
- 主要实验结果:在GeoPlant(物种分布建模,3种模态,多Token)和TaxaBench(物种分类,5种模态,单Token)两个生态数据集上评估。在GeoPlant测试集上,MIAM平均AUC达到86.1%,比第二好的基线(OPM,83.8%)高出2.3个百分点,尤其在被主导的卫星影像单模态评估上提升显著(见表1)。在TaxaBench测试集上,MIAM平均Top-1准确率为38.7%,优于所有基线(见表2)。消融实验(图4)证实,从均匀分布->Beta超立方体->MIAM的每一步改进都有效,且动态不平衡系数(ρ_sm, ρ_dm)对弱势模态性能至关重要。
- 实际意义:MIAM使多模态模型能更好地处理生态监测中常见的数据缺失,提升预测鲁棒性。更重要的是,它支持细粒度的贡献分析,能揭示哪些具体变量(如BIO1)、时间片段(如包含2003年热浪的年份)或图像区域(如计算NDVI的红光与近红外波段组合)对预测最关键(图5),为生态学研究提供了可解释的AI工具。
- 主要局限性:a) 方法的有效性高度依赖准确的、无偏的模态性能估计,在无标签的自监督场景下,使用重构损失作为代理可能不理想;b) 论文评估主要集中在模态数量中等(3-5种)的生态场景,其在模态极多或极少的通用多模态任务中的泛化能力有待验证;c) 虽然进行了敏感性分析,但超参数λ和κ仍需根据具体任务调整。
🏗️ 模型架构
MIAM本身并非一个完整的预测模型,而是一种应用于多模态Transformer架构的训练期掩码策略。其核心组件是掩码概率采样器。
- 整体流程:对于一个包含M个模态的输入,每个模态有T_m个Token。MIAM在训练的每个批次,为每个模态生成一个掩码概率p_m ∈ [0,1]。该模态内所有Token以概率p_m被独立地掩码(替换为一个可学习的掩码Token)。所有未被掩码的Token拼接后输入Transformer进行特征融合和预测。
- MIAM掩码概率采样器:
- 输入:当前训练轮次(epoch)下,各模态的独立性能分数s_m(如验证集AUC)和性能变化率的绝对值d_m(|Δs_m/Δepoch|)。
- 核心分布:MIAM从混合乘积Beta分布中采样概率向量p=(p_1,…,p_M)。该分布是2^M个“角落锚定”分布的加权混合。每个角落锚定分布(对应超立方体的一个角c ∈ {0,1}^M)是一个乘积Beta分布:若c_m=0,则p_m ~ Beta(1, κ_eff);若c_m=1,则p_m ~ Beta(κ_eff, 1)。κ_eff是随模态动态调整的尖度参数。
- 不平衡感知调整:关键创新在于κ_eff不是固定的。对于模态m,其κ_eff会根据其相对性能比ρ_sm/ρ_dm进行不对称调整。其中,ρ_sm和ρ_dm分别是s_m和d_m的几何归一化值。若ρ_sm/ρ_dm大(即该模态性能好且学习稳定,是“主导”模态),则当其对应角落c_m=1时,分布更集中于1(掩码概率更高);当c_m=0时,分布更集中于0(掩码概率更低)。通过超参数λ控制调整强度。
- 角落权重:为优先采样全存在(0,…,0)和全缺失(1,…,1)的角落,设置了非均匀的混合权重w_c,将一半的概率质量分配给这两个角落。
- 设计动机与交互:MIAM的设计直接回应了其提出的三大原则:a) 全支持:通过乘积Beta分布支持[0,1]^M上的连续采样;b) 角落优先:通过混合分布和非均匀权重w_c实现;c) 不平衡感知:通过动态调整κ_eff实现。这使得模型在训练中能暴露于多样且关键的输入子集,特别是迫使模型学习在主导模态缺失时利用其他模态。

图2:MIAM方法概览图。(a) 展示了每个模态的Token如何根据从混合乘积Beta分布中采样的概率p_m进行掩码。(b) 展示了分布参数如何由模态性能s_m和其绝对变化率d_m导出的不平衡系数ρ_sm和ρ_dm调制,使得相对强势(高s_m,低d_m)的模态被更频繁地掩码。
💡 核心创新点
- 将掩码策略形式化为超立方体分布并提炼设计原则:将复杂的掩码行为统一到概率分布的数学框架下,明确了全支持、角落优先、不平衡感知三个缺失的特性。这为分析和设计新策略提供了理论基础,超越了以往依赖直觉或特定形式(如均匀、狄利克雷)的方法。
- 提出混合乘积Beta分布(Beta超立方体):通过混合多个角落锚定的Beta分布,构造了一种既能覆盖整个输入组合空间(全支持),又能自然地将概率质量集中在模态全存在或全缺失的角落(角落优先)的灵活分布。这解决了现有策略(如均匀、狄利克雷)探索空间不足或约束过强的问题。
- 设计基于双重动态指标的不平衡感知调整机制:创新性地引入模态的相对性能(s_m) 和学习速度(d_m) 作为调节信号。通过调整Beta分布的尖度κ,动态地对“强势”模态(高性能且学习稳定)施加更高的掩码概率。这种机制比OPM等仅依赖静态性能分数的方法更能捕捉训练过程中的动态平衡需求。
🔬 细节详述
- 训练数据:
- GeoPlant:包含3种模态(表格环境变量、卫星影像、时间序列),任务为多标签分类(1783个物种)。数据按空间分块交叉验证划分(训练70%,验证15%,测试15%)。
- TaxaBench:包含5种模态(地面图像、卫星图像、音频、环境表格数据、地理位置),任务为物种分类(199个物种)。数据按物种分层划分(训练80%,验证10%,测试10%)。
- 损失函数:
- GeoPlant:使用加权二元交叉熵损失。
- TaxaBench:使用标准交叉熵损失。
- 训练策略:
- 优化器:AdamW,权重衰减0.01。
- 学习率:0.001,采用无调度(schedule-free)策略。
- Batch size:128。
- 训练轮数:100个epoch,使用基于验证集平均AUC的早停法。
- 其他:Dropout率为0.1。
- 关键超参数:
- MIAM:尖度基线κ=10,不平衡强度λ(GeoPlant用3,TaxaBench用1)。
- 模型架构:基于Transformer,包含3层、8头注意力机制,Token维度192(GeoPlant)或512(TaxaBench)。Token化过程:表格变量直接嵌入;时间序列和影像按年、波段、图像块进行切分并添加位置编码。
- 训练硬件:论文中未明确说明。
- 推理细节:训练好的模型,在评估时,给定任意输入子集(模态及Token的组合),将缺失的Token替换为掩码Token,输入Transformer进行预测。
- 正则化技巧:使用权重衰减(0.01)和Dropout(0.1)防止过拟合。
📊 实验结果
主要在两个生态数据集上评估,指标分别为平均AUC(GeoPlant)和Top-1准确率(TaxaBench)。
表1:GeoPlant测试集AUC性能对比
| 方法 | 部分单模态(BIO1) | 部分单模态(WorldClim) | 部分单模态(其他) | 部分单模态(2018) | 部分单模态(2000-18) | 部分单模态(Landsat) | 部分单模态(中心块) | 部分单模态(其他块) | 双模态(表格+时序) | 双模态(表格+影像) | 双模态(时序+影像) | 全模态 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Constant | 68.6 | 82.4 | 84.7 | 86.7 | 55.1 | 83.3 | 90.0 | 63.6 | 90.0 | 83.3 | 89.2 | 87.9 | 80.4 |
| Uniform | 73.3 | 85.7 | 86.3 | 87.2 | 61.2 | 86.9 | 91.1 | 65.6 | 91.6 | 86.2 | 91.8 | 92.0 | 83.2 |
| Dirichlet | 65.1 | 82.7 | 77.8 | 86.8 | 54.9 | 87.5 | 91.1 | 58.2 | 91.8 | 88.6 | 91.7 | 91.4 | 80.6 |
| Modality dropout | 48.7 | 80.8 | 77.4 | 86.4 | 66.2 | 88.6 | 91.4 | 73.2 | 92.0 | 89.2 | 91.7 | 92.0 | 81.5 |
| OPM | 68.0 | 81.9 | 80.7 | 85.3 | 68.1 | 88.4 | 90.2 | 81.1 | 90.7 | 89.5 | 91.1 | 91.2 | 83.8 |
| MIAM (ours) | 78.4 | 86.7 | 86.0 | 87.0 | 70.8 | 89.0 | 91.4 | 80.1 | 91.7 | 89.5 | 91.5 | 91.7 | 86.1 |
| Oracle | 78.0 | 87.1 | 87.7 | 87.6 | 77.1 | 89.3 | 92.2 | 81.4 | 92.3 | 89.7 | 91.7 | 92.0 | 87.2 |
关键结论:MIAM平均AUC (86.1%) 显著优于所有基线,在“部分单模态”这种极端数据缺失场景下优势尤为明显(如对BIO1预测:MIAM 78.4% vs. 次优Uniform 73.3%)。在被主导的卫星影像单模态评估上(中心块),MIAM (80.1%) 也远优于Uniform (65.6%) 和OPM (81.1%),极大缩小了与Oracle模型的差距。
表2:TaxaBench测试集Top-1准确率对比
| 方法 | 地面图像 | 音频 | 地理位置 | 环境特征 | 卫星图像 | 双模态(地+音) | 双模态(地+位) | 双模态(地+环) | 双模态(地+卫) | 三模态 | 四模态 | 五模态(全) | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Uniform | 42.4 | 41.2 | 8.40 | 7.99 | 6.76 | 59.2 | 48.8 | 64.3 | 9.02 | 51.2 | 46.9 | 65.8 | 37.7 |
| Dirichlet | 42.2 | 40.8 | 5.33 | 5.12 | 7.58 | 59.2 | 48.4 | 65.0 | 9.63 | 51.4 | 45.9 | 67.8 | 37.4 |
| Modality dropout | 41.4 | 39.8 | 5.53 | 4.51 | 8.2 | 57.2 | 44.3 | 59.2 | 9.63 | 51.0 | 45.1 | 65.0 | 35.9 |
| OPM | 33.2 | 35.0 | 5.74 | 5.12 | 7.79 | 46.3 | 34.4 | 50.0 | 10.9 | 43.6 | 42.6 | 59.4 | 31.2 |
| MIAM (ours) | 42.2 | 41.8 | 6.56 | 7.38 | 9.84 | 60.9 | 50.2 | 65.4 | 10.2 | 52.0 | 49.0 | 69.1 | 38.7 |
| Oracle | 45.3 | 44.9 | 7.58 | 9.43 | 12.9 | 63.3 | 50.0 | 66.6 | 13.1 | 51.8 | 46.5 | 69.1 | 40.0 |
关键结论:MIAM在平均性能上同样领先(38.7% vs. 次优Uniform 37.7%)。特别是在双模态及以上的多模态组合下,MIAM展现了稳定的性能提升。在单模态评估中,MIAM在最强模态(地面图像、音频)上与均匀掩码持平,在较弱模态(卫星图像)上则表现更好。
消融实验与动态分析:
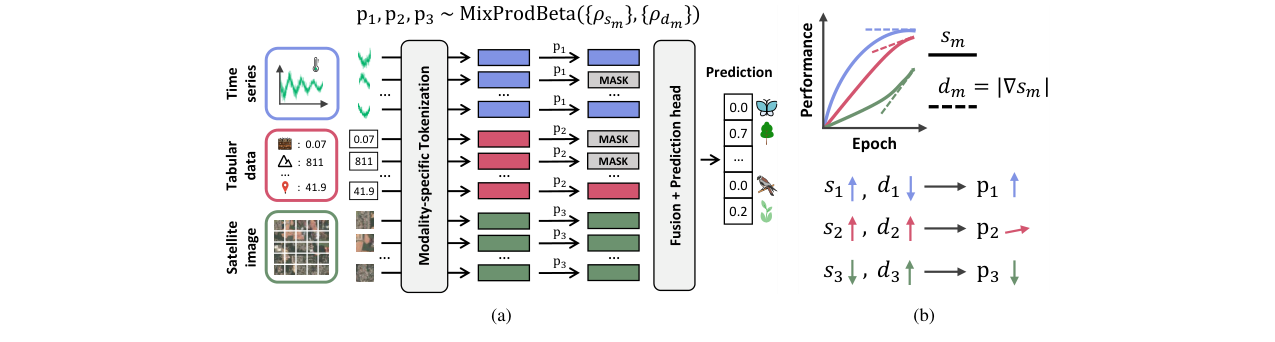
图4:左侧展示了GeoPlant验证集AUC在训练过程中的变化,对比了均匀掩码、Beta超立方体和MIAM。可以看出,每增加一个设计原则(全支持->角落优先->不平衡感知),在卫星影像等弱势模态上的性能都有提升。MIAM的训练曲线呈现周期性波动,与右侧展示的其动态系数ρ_dm的变化相关,这可能有助于模型跳出局部最优。右侧图展示了MIAM的模态不平衡系数ρ_sm(相对性能)和ρ_dm(相对学习速度)随训练轮次的变化,证实了动态调整的存在。
生态洞察贡献分析:
图5a:展示了使用不同卫星影像光谱波段组合进行评估时的测试AUC。结论是,同时包含红光(Red)和近红外(NIR)波段的组合(用于计算NDVI植被指数)性能最佳。
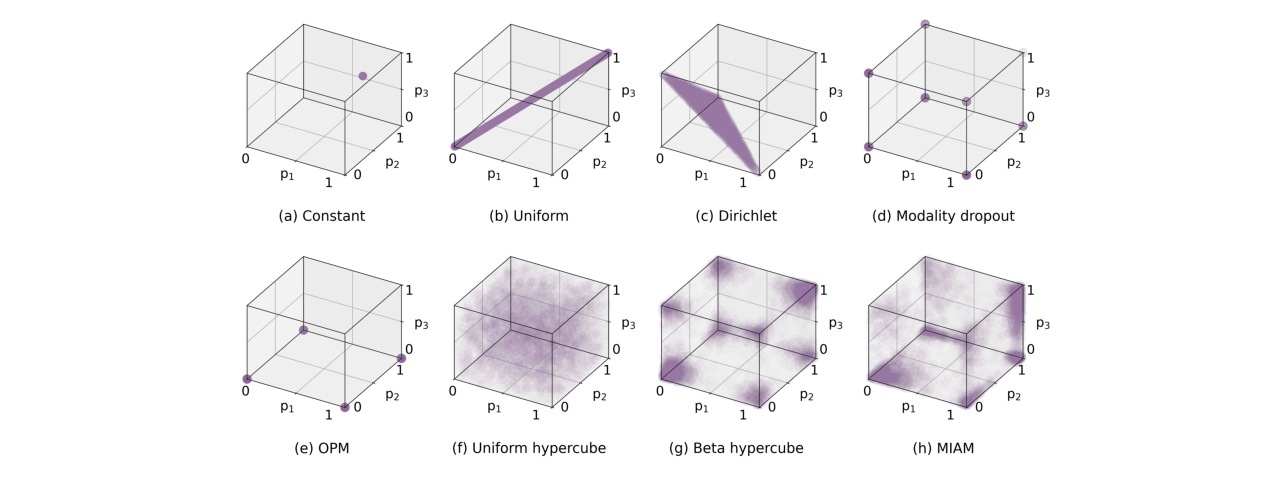
图5b:展示了使用不同长度历史气候时间序列进行评估时的测试AUC。结论是,当时间序列包含2003年欧洲热浪事件时,性能有显著提升,说明捕捉极端气候事件对物种分布预测很重要。
⚖️ 评分理由
- 学术质量:6.5/7:论文贡献了清晰的形式化框架和原则,提出了设计精巧的MIAM方法。技术实现正确,实验对比全面(多个基线、两个数据集、多种评估子集),并进行了深入的消融研究和敏感性分析,结果具有说服力。扣分点在于方法属于训练策略优化而非根本性架构创新,且对模态性能估计的依赖可能限制其在完全无监督场景的应用。
- 选题价值:1.5/2:研究多模态学习中的核心挑战(不平衡与缺失数据),并针对生态学这一重要且数据不完美的应用场景。提出的MIAM提升了模型鲁棒性和可解释性,对保护生物学有实际意义。扣分点在于生态信息学领域相对垂直,与主流的音视频处理读者群体的直接相关性稍弱。
- 开源与复现加成:0.5/1:论文明确提供了GitHub代码仓库和HuggingFace模型权重链接。附录极其详细地给出了所有数据处理、训练配置、超参数设置、敏感性分析的代码和说明,复现友好度非常高。加成0.5分。