📄 MCIF: Multimodal Crosslingual Instruction-Following Benchmark from Scientific Talks
#基准测试 #多模态模型 #多语言 #大语言模型 #语音识别
🔥 8.5/10 | 前25% | #基准测试 | #多模态模型 | #多语言 #大语言模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Sara Papi(Fondazione Bruno Kessler (Italy))
- 通讯作者:未说明(论文未明确指定通讯作者)
- 作者列表:Sara Papi (Fondazione Bruno Kessler), Maike Züfle (Karlsruhe Institute of Technology), Marco Gaido (Fondazione Bruno Kessler), Beatrice Savoldi (Fondazione Bruno Kessler), Danni Liu (Karlsruhe Institute of Technology), Ioannis Douros (Fondazione Bruno Kessler), Luisa Bentivogli (Fondazione Bruno Kessler), Jan Niehues (Karlsruhe Institute of Technology)
💡 毒舌点评
亮点:论文填补了多模态、跨语言、长上下文指令跟随评测的关键空白,创建了一个系统对齐、人工标注的高质量基准,对推动通用多模态大模型发展有明确价值。
短板:论文的核心贡献是建立评测基准,而非提出新的建模方法,对现有模型“能力不足”的诊断虽清晰,但并未直接提供解决方案;评测模型均为已发表的开源或商用模型,缺乏对自身新方法的验证。
🔗 开源详情
- 代码:提供。论文明确给出了两个代码仓库:
- 评估与推理代码:
github.com/hlt-mt/mcif(Apache 2.0许可)。 - 数据构建与标注指南:
https://github.com/hlt-mt/mcif/tree/main/dataset_build/annotation_guidelines。
- 评估与推理代码:
- 模型权重:部分提供。论文中评测的开源模型权重均通过HuggingFace链接公开。论文本身未提出新的模型权重。
- 数据集:公开。MCIF数据集在HuggingFace以CC-BY 4.0许可发布:
hf.co/datasets/FBK-MT/MCIF。模型在测试集上的输出也以相同许可发布。 - Demo:未提及。
- 复现材料:提供了完整的训练/推理细节(附录D)、超参数、提示词库(附录C)、标注指南和评估脚本,复现材料极其充分。
- 论文中引用的开源项目:依赖并提及了HuggingFace Transformers库用于模型推理,以及SHAS工具用于音频分段。
📌 核心摘要
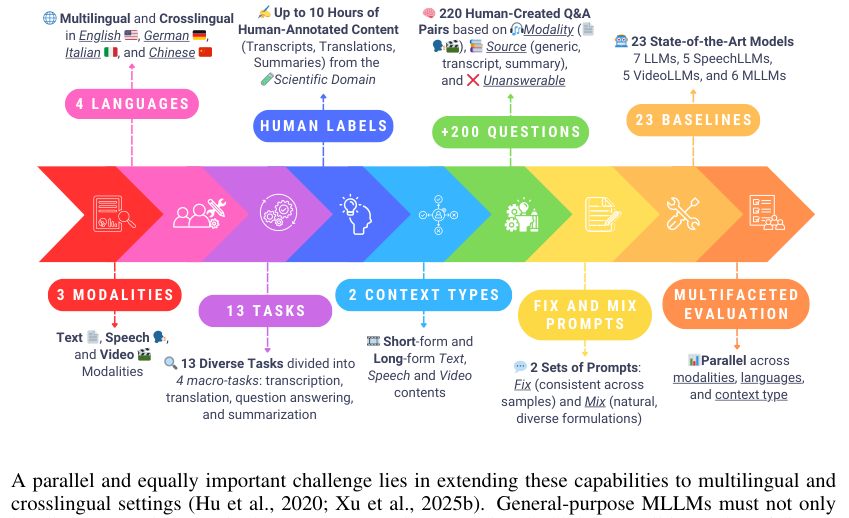
这篇论文旨在解决当前多模态大语言模型评测基准在跨语言、多模态联合处理及长上下文理解方面存在的覆盖不足、缺乏人工标注、评测维度单一等问题。方法核心是提出了MCIF(Multimodal Crosslingual Instruction Following) 基准,该基准基于科学演讲视频,平行覆盖三种模态(语音、视频、文本)、四种语言(英语、德语、意大利语、中文) 和13个任务(分为识别、翻译、问答、摘要四大类),并提供了短上下文和长上下文两种版本。与已有基准相比,MCIF的独特之处在于其完全平行的跨维度设计,允许系统评估模型在不同语言、模态和任务复杂度下遵循指令的能力。论文对23个模型(包括LLM、SpeechLLM、VideoLLM和MLLM)进行了基准测试。主要结果显示:摘要任务最具挑战性(部分模型得分甚至低于随机基线);当前MLLMs难以有效融合语音和视频模态,联合处理常无增益甚至有害;长上下文处理是普遍弱点,多数模型性能显著下降;以及模型对提示词的微小变化敏感性高。该基准的发布旨在为评估和改进跨语言多模态指令跟随系统提供一个全面框架。主要局限性在于,它本身是一个评测基准,而非一个能直接提升模型性能的新方法,其发现揭示了当前模型的普遍短板。
🏗️ 模型架构
本文的核心贡献是MCIF基准数据集与评测框架,而非提出一个新的神经网络模型架构。因此,本节重点描述该基准的结构设计。
MCIF基准的构建与组成如下:
数据来源与预处理:
- 来源:所有数据源自ACL 2023会议的公开演讲视频(CC-BY 4.0许可)。
- 采集:随机选取了21个主题多样的NLP及跨领域演讲视频,确保录音条件和说话人背景的多样性。
- 清洗:手动剔除了重复演讲者、语音质量差或包含合成语音的视频。
- 转换:视频保留原始mp4格式,音频被转换为单声道、16kHz的wav格式。
- 分段:为支持对长上下文和短上下文的探索,提供了完整视频/音频,以及使用SHAS工具自动分割的约16秒片段。
人工标注与多语言扩展:
- 转录:由专业语言学家基于ASR初稿修正,产出高质量英文转录文本。
- 问答对:由NLP领域专家(16人)为每个演讲创建至少10个问答对,问题分为三类(通用、基于摘要、基于转录),并标注所需信息模态(仅音频A、仅视频V、音视频AV、不可回答NA)。
- 摘要:直接使用原始论文的英文摘要。
- 翻译:所有英文文本(转录、问答、摘要)由专业译者翻译成德语、意大利语和中文,确保跨语言一致性。
- 质量控制:多轮人工审核,包括专业语言学家和领域专家。
指令跟随提示设计:
- 模型需要从自然语言提示中推断任务、输入模态、目标语言等信息,模拟真实交互。
- 设计了两个版本:
- MCIFfix:为每个宏观任务使用固定的提示模板。
- MCIFmix:从10个语义等价但措辞不同的提示池中随机抽取,用于评估模型对提示变化的鲁棒性。
整体平行结构:
- 每个样本包含同一演讲的三种模态(文本、音频、视频)输入。
- 每个输入都配有四种语言的提示和对应的参考答案,实现了跨模态、跨语言的完全平行对齐。
基准数据集统计概览(基于论文图1):
- 包含100个样本(其中21个有完整三模态对齐),总时长约10小时。
- 问答对:共220个独立问答对。按输入模态分布:音视频(AV) 58.6%,仅视频(V) 22.3%,不可回答(NA) 11.4%,仅音频(A) 7.7%。
- 文本长度:英语转录总词数约16.3k,摘要总词数约2.1k。
💡 核心创新点
- 首个跨语言多模态指令跟随基准:MCIF是第一个明确设计用于评估模型在跨语言和多模态(语音、视频、文本)设置下指令跟随能力的基准,填补了现有评测体系的空白。
- 完全平行的跨维度设计:基准在模态(文本/语音/视频)、语言(英/德/意/中)、任务(识别/翻译/问答/摘要)和上下文长度(长/短)上实现了严格对齐。这种设计允许进行系统的消融研究,例如分析不同模态输入对同一任务的影响。
- 人工标注与双版本提示设计:所有核心数据(转录、问答、摘要)均由人类专家创建和验证,确保了数据质量。同时,MCIFfix与MCIFmix的对比设置,可直接量化模型对指令措辞变化的鲁棒性,这是对现有评测方法的一个重要补充。
🔬 细节详述
由于本文是基准评测论文,以下详述其评测设置细节:
- 评测数据集:即MCIF基准本身,包含100个样本,分为短上下文(短片段)和长上下文(完整演讲)两种输入形式。
- 评估指标:
- 识别任务(ASR, AVR):使用词错误率(WER���。
- 翻译任务(MT, ST, AVT):使用COMET(一种神经机器翻译评估指标)。
- 问答与摘要任务:使用BERTScore,并进行了基线重标定,使得0分对应目标语言的随机输出。
- 评估模型:论文评测了23个模型,分为四类:
- LLM(7个):Aya Expanse, Gemma 3, GPT-oss, Llama 3.1, Phi4, Qwen3, Tower+。
- SpeechLLM(5个):DeSTA2, GraniteSpeech, Phi4-Multimodal, Qwen2-Audio, UltraVox v0.5。
- VideoLLM(5个):InternVL3, LLaVA-NeXT, Qwen2.5-VL, VideoLLaMA3, Video-XL2。
- MLLM(6个):Gemma 3n, Ming-Lite-Omni, MiniCPM-o-2, Ola, Qwen2.5-Omni, Gemini 2.5 Flash(商业模型)。
- 推理设置:使用HuggingFace Transformers库运行开源模型,参数量限制在20B以内。遵循各模型官方建议设置,最大生成长度为4096 token,使用单卡NVIDIA GH200 GPU。Gemini 2.5 Flash通过API调用。
- 训练策略、损失函数、关键超参数等:未说明。因为本文是基准评测工作,不涉及提出或训练新模型。
📊 实验结果
论文对23个模型在MCIFfix和MCIFmix两个版本、短上下文和长上下文两种输入下的四个宏观任务进行了全面评测。关键结果如下:
主要结果表格(来自论文表2,摘要形式): 下表展示了在MCIFmix设置下,各模型在短上下文(SHORT)和长上下文(LONG)输入中的核心任务平均分(跨语言平均)。WER↓表示越低越好,COMET↑和BERTS.↑表示越高越好。
| 上下文 | 输入模态 | 模型 | 宏观任务平均表现(MCIFmix) | |||
|---|---|---|---|---|---|---|
| 识别 (WER↓) | 翻译 (COMET↑) | 问答 (BERTS.↑) | 摘要 (BERTS.↑) | |||
| SHORT | Speech | Phi4-Multimodal | 6.7 | 80.1 | 37.4 | - |
| Video | Qwen2.5-VL | - | - | 37.8 | 37.8 | |
| MLLM | Gemini 2.5 Flash | 12.8 | 69.2 | 39.5 | - | |
| Ola | 98.8 | 76.3 | 37.0 | - | ||
| LONG | Text | Qwen3 | - | 84.5 | 20.1 | 20.1 |
| Speech | Phi4-Multimodal | 29.8 | 59.5 | 37.3 | 17.9 | |
| MLLM | Gemini 2.5 Flash | 7.9 | 79.9 | 45.9 | 21.8 | |
| Ola | 6.6 | 58.7 | 36.2 | 13.8 |
关键发现与分析:
任务难度:摘要(SUM)是最具挑战性的任务,许多模型得分很低甚至为负(如MiniCPM-o-2的长文本摘要得分-39.7)。问答(QA)受益于多模态输入,翻译(TRANS)由纯文本LLM主导(Qwen3最高)。
长上下文挑战:多数模型在长上下文输入下性能显著下降,尤其在识别和翻译任务。例如,SpeechLLM的DeSTA2在长文本翻译COMET上比短文本低约33分。
多模态融合问题:如图2
 所示,对于MLLMs,简单地结合语音和视频(Speech+Video)在识别、翻译、问答任务上常常没有带来收益,甚至比单模态更差。视频模态通常表现最弱,表明当前模型未能有效利用视觉信息。
所示,对于MLLMs,简单地结合语音和视频(Speech+Video)在识别、翻译、问答任务上常常没有带来收益,甚至比单模态更差。视频模态通常表现最弱,表明当前模型未能有效利用视觉信息。提示鲁棒性:对比MCIFfix和MCIFmix,许多模型对提示词的微小变化敏感,特别是在识别任务中,WER波动可超过60点(如DeSTA2)。
问答任务细粒度分析:如图3
 所示,对于长上下文问答:
所示,对于长上下文问答:- 问题来源:通用问题(General)得分最高(~49),基于转录的问题(Transcript)次之(~35),基于摘要的问题(Abstract)最难(~25)。这表明模型擅长获取通用信息,但难以检索细粒度内容。
- 模态匹配:SpeechLLM在音频相关问题上表现好,VideoLLM在视频相关问题上表现好,但MLLM在两类问题上均未超越单模态专家模型。
⚖️ 评分理由
- 学术质量:6.0/7:论文在实验设计上非常系统和充分,评测维度全面(23个模型,4类模型,跨语言、跨模态、跨上下文长度、双提示版本),数据分析深入(包括消融研究和细粒度问题分析)。其主要贡献是一个高质量的评测基准,而非新的算法模型,因此在原创性上稍显常规。技术正确性高,评估指标选择恰当,结论有数据支撑,可信度强。
- 选题价值:1.5/2:选题高度前沿,直接针对多模态大模型发展中的核心评估缺口(跨语言、多模态、长上下文)。该基准的发布对社区研究有明确的指导意义和实际应用价值,能推动模型在这些薄弱方向上的改进。与语音/多模态研究者高度相关。
- 开源与复现加成:+1.0/1:论文开源程度极高,明确提供了数据集(HuggingFace)、评估代码、推理代码(Apache 2.0)以及所有基线模型的输出。在复现细节上,提供了详尽的模型列表、推理设置、提示词模板和标注指南,极大地降低了复现门槛,是可复现研究的典范。