📄 MARS-Sep: Multimodal-Aligned Reinforced Sound Separation
#语音分离 #强化学习 #多模态模型 #对比学习 #跨模态
✅ 7.5/10 | 前25% | #语音分离 | #强化学习 | #多模态模型 #对比学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zihan Zhang (Zhejiang University)
- 通讯作者:Tao Jin (Zhejiang University)
- 作者列表:Zihan Zhang (Zhejiang University), Xize Cheng (Zhejiang University), Zhennan Jiang (Institute of Automation, Chinese Academy of Sciences), Dongjie Fu (Zhejiang University), Jingyuan Chen (Zhejiang University), Zhou Zhao (Zhejiang University), Tao Jin (Zhejiang University)
💡 毒舌点评
亮点:该工作巧妙地将大语言模型对齐的RLHF范式“降维打击”式地应用于声音分离任务,通过设计因子化Beta掩码策略和多模态融合奖励,系统性地解决了传统方法中信号指标优化与语义保真度脱节的核心矛盾,实验设计全面且具有说服力。短板:方法的核心——多模态奖励模型严重依赖预训练的ImageBind编码器,其表征能力的天花板可能间接限制了MARS-Sep所能达到的最终性能上限,且论文中缺乏对这一依赖性风险的深入讨论。
📌 核心摘要
- 要解决什么问题:通用声音分离存在“度量困境”,即优化传统信号级指标(如SDR)的模型,其输出在听感上可能语义不纯净,无法有效抑制与目标源声学相似的干扰源,导致分离结果与用户查询的语义意图不匹配。
- 方法核心是什么:本文将查询条件声音分离重新构架为强化学习问题。将分离模型视为策略网络,输出时频掩码作为动作。设计了一个基于渐进式对齐的多模态编码器(增强后的ImageBind)作为奖励模型,计算分离音频与查询(音频/文本/图像)在统一嵌入空间中的相似度作为奖励信号。通过一种稳定的、基于PPO的裁剪信任域策略优化算法(融合GRPO优势归一化)来更新策略,以最大化语义奖励。
- 与已有方法相比新在哪里:1)范式创新:首次从“偏好对齐”视角统一了多模态查询声音分离,引入强化学习作为优化范式,而非传统的监督回归。2)策略设计:提出了因子化Beta掩码策略,将掩码预测转化为概率分布采样,并设计了包含熵正则和KL惩罚的裁剪目标函数,以稳定训练。3)奖励设计:使用了融合音频、文本、视觉信息的多模态聚合奖励(MLBP),并引入了渐进式编码器微调策略以提升奖励模型的判别力和稳定性。
- 主要实验结果如何:在VGGSound-clean+和MUSIC-clean+两个基准数据集上,针对四种查询设置(文本/音频/图像/组合),MARS-Sep在大多数情况下取得了最优或次优的信号指标(如SDR, SI-SDRi)和显著更高的CLAP语义分数。例如,在VGGSound-clean+文本查询中,MARS-Sep的CLAP分数为9.03%,优于OmniSep的8.98%和AudioSep的8.21%。消融实验验证了RL、渐进式微调和MLBP融合模块的有效性。用户研究也表明其分离结果在语义匹配度上优于基线。
- 实际意义是什么:该工作推动了声音分离从“信号复原”向“语义理解”的范式转变。提升后的语义一致性可以直接改善语音识别、声音事件检测等下游任务的输入质量,并为构建更符合人类意图的智能听觉系统提供了新思路。
- 主要局限性是什么:方法整体依赖于一个高质量的多模态奖励模型,该模型的性能上限可能制约了策略学习的最终效果。此外,虽然实验数据集多样,但均为合成或准合成混合,对于真实世界中极端复杂的混杂声学环境,泛化能力有待进一步验证。奖励信号可能存在的稀疏性和延迟问题,也是强化学习框架中需要更深入探讨的挑战。
详细分析
MARS-Sep是一个基于强化学习的声音分离框架,其核心架构围绕着“策略-奖励-优化”的闭环设计(见下图)。
整体输入输出流程:
- 输入:混合音频波形
x(t)和多模态查询Q(文本、音频片段或图像)。 - 中间处理:
- 混合音频通过短时傅里叶变换(STFT)得到幅度谱
X。 - 查询
Q通过对应的ImageBind编码器(文本/音频/视觉)和查询混合器(Query-Mixup)得到融合查询特征。 - 分离网络(Separate-Net,基于U-Net)接收
X和Q的特征,输出掩码提议P_θ。 P_θ通过参数化映射转化为Beta分布的浓度参数(α, β),构成随机策略π_θ。
- 混合音频通过短时傅里叶变换(STFT)得到幅度谱
- 动作采样与重建:从旧策略快照
π_θ_old中采样一个掩码M,用M对X进行掩码操作并结合相位进行逆STFT,重建分离后的音频波形ŷ。 - 奖励计算:
- 预训练的多模态编码器(渐进式微调后的ImageBind)分别将
ŷ、目标音频y⋆、目标文本t⋆、目标视频帧v⋆编码。 - 使用多模态低秩双线性池化(MLBP)将
y⋆,t⋆,v⋆的特征融合为一个目标锚点z⋆。 - 计算
ŷ的嵌入与z⋆的余弦相似度作为标量奖励R。
- 预训练的多模态编码器(渐进式微调后的ImageBind)分别将
- 策略更新:利用奖励
R、优势估计Ã和新旧策略的概率比r_θ(M),计算包含裁剪、熵正则和KL惩罚的策略梯度损失,并更新当前策略网络π_θ。同时,将π_θ快照为新的π_θ_old用于下一次迭代。
主要组件:
- 基础策略网络(Base Policy):基于OmniSep的分离架构,一个7层U-Net,在时频域预测掩码提议。它接收混合音频谱和通过ImageBind编码的查询特征。
- 随机掩码策略(Factorized Beta Mask Policy):核心创新点之一。将U-Net的输出视为对每个时频点(频率-时间-源维度)的掩码概率的预测,并将其转化为一个各点独立的Beta分布
(α, β)参数。通过从该分布中采样,使得掩码生成具有探索性,且探索范围由浓度参数κ控制。 - 多模态奖励模型(Multimodal Reward Model):基于ImageBind,但经过三个阶段的渐进式对比微调,以增强其跨模态判别能力。它负责评估分离音频与多模态查询的语义一致性。
- 稳定策略优化器(Stable Policy Optimizer):采用PPO风格的裁剪目标,结合了组相对优势归一化(GRPO)、熵正则化(鼓励探索)和KL散度惩罚(约束策略漂移),确保训练稳定。
关键设计选择及动机:
- 选择因子化Beta分布而非直接回归确定性掩码,是为了将分离过程自然地建模为随机决策,便于应用RL进行优化,并提供探索-利用的权衡机制。
- 使用MLBP融合多模态目标特征而非简单拼接或平均,是为了显式建模模态间的乘性交互,从而生成一个更强大的、统一的语义锚点来计算奖励,避免单一模态主导。
- 采用渐进式微调ImageBind而非从头训练或使用原始预训练模型,是为了逐步、稳定地提升其在声音分离任务上的语义判别力,防止灾难性遗忘,为RL提供更可靠的奖励信号。
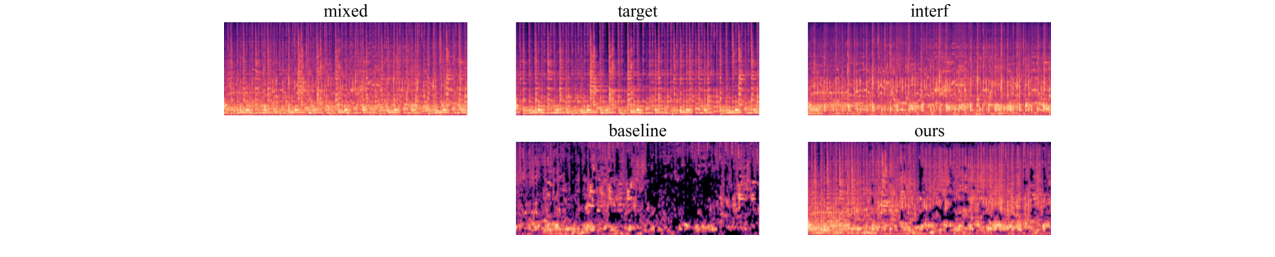
图1:MARS-Sep的强化学习循环示意图。分离器从Beta分布策略生成随机掩码动作,而冻结的快照作为旧策略用于稳定优化。来自音频、文本和视觉嵌入的多模态奖励指导策略更新,熵和KL正则化增强探索和稳定性。
图2:用于声音源判别和分离的渐进式微调策略。编码器保持冻结,特定任务的头部逐步解冻,每个阶段都建立在前一阶段最佳检查点的基础上。后两个阶段使用部分前一对齐的配对数据训练,以避免灾难性遗忘。
- 将声音分离重构为强化学习问题:这是最具范式性的创新。不同于传统监督学习直接回归理想掩码,MARS-Sep将分离过程视为在给定混合音频和查询下,通过采样掩码策略来最大化语义奖励的序列决策问题。这使得优化目标直接对齐人类意图(语义一致性),而不仅仅是像素级/波形级相似度。
- 因子化Beta掩码策略与裁剪信任域优化:针对掩码值在[0,1]区间的特点,设计了因子化Beta分布策略,并通过参数化映射与网络输出关联。同时,提出了一种融合了GRPO优势归一化、熵正则和KL惩罚的PPO变体优化器,解决了传统策略梯度在连续动作空间上的不稳定性问题,实现了高效稳定的策略更新。
- 基于渐进式对齐的多模态奖励模型:为了提供稳定、有效的奖励信号,论文设计了一个三阶段的对比学习课程来微调ImageBind编码器(音频-文本 -> 音频-音频 -> 音频-视频),逐步增强其跨模态语义判别力。奖励计算采用非对称设计:将多模态目标融合为一个锚点,与分离音频比较,这减少了采样噪声的影响,并强制分离结果与所有模态保持一致。
- 多模态低秩双线性池化(MLBP)用于查询聚合:在奖励模型中,使用MLBP将来自不同模态(音频、文本、视频)的目标特征进行融合。相比于简单聚合,MLBP能更有效地捕捉模态间的复杂交互,生成更具代表性的语义锚点,从而提供更准确、更鲁棒的奖励信号。
- 训练数据:论文在VGGSound-clean+和MUSIC-clean+两个数据集上进行实验。VGGSound-clean+是VGGSound的清洗子集,包含300+类别YouTube视频;MUSIC-clean+是MUSIC的清洗子集,包含独奏和二重奏音乐视频。预处理包括音频重采样至16kHz,裁剪至约4秒(65535样本点);图像调整至224x224像素。未明确提及具体的数据增强方法。
- 损失函数:训练损失由两部分组成:
- 监督损失(用于预训练/基线):加权二元交叉熵(WBCE)损失,用于监督掩码预测。
- 强化学习损失
L_RL(θ):即J_clip(θ)的负值。J_clip(θ)公式见论文公式(4),包含三项:a) 裁剪的策略梯度代理目标;b) 熵正则项λ_H H(π_θ),鼓励策略多样性;c) KL惩罚项-λ_KL KL(π_θ || π_θ_old),约束策略更新幅度。
- 训练策略:
- 优化器:AdamW,学习率
2e-4,权重衰减0.01。 - 批次大小:128。
- 训练步数:200,000步。
- 学习率调度:未明确说明,但提到使用了warmup策略。
- 梯度裁剪:最大梯度范数为1.0。
- 混合精度:分离器网络使用FP16/BF16,奖励计算使用FP32。
- RL细节:采用单轮PPO更新,每步更新策略快照。旧策略
π_θ_old从当前策略π_θ快照得到。优势使用指数移动平均基线(β=0.92)计算,并启用GRPO归一化。每次迭代使用1个蒙特卡洛采样。
- 优化器:AdamW,学习率
- 关键超参数:
- Beta分布浓度参数
κ = 9。 - PPO裁剪范围
ϵ = 0.2。 - 熵系数
λ_H = 0.1。 - KL系数
λ_KL = 0.01(默认开启)。 - 分离网络为7层U-Net,输出32个中间掩码(K=32)。
- STFT参数:滤波器长度1024,跳长256,窗大小1024。
- Beta分布浓度参数
- 训练硬件:论文主要实验在单张NVIDIA A800 40GB GPU上进行。消融实验部分提及在A100上进行。
- 推理细节:推理时直接使用训练好的策略网络
π_θ生成确定性掩码提议P_θ,并将P_θ转化为α=1+κP_θ,β=1+κ(1-P_θ)后取均值掩码(或直接使用P_θ作为掩码)进行重建,无需采样。未提及流式处理设置。 - 正则化与稳定训练技巧:除了上述的熵正则和KL惩罚,还包括渐进式微调以防止灾难性遗忘、优势归一化(GRPO)以减少方差、以及奖励计算的非对称设计以降低策略噪声影响。
主要Benchmark与指标: 数据集:VGGSound-clean+, MUSIC-clean+ 指标:SDR (↑), SIR (↑), SAR (↑), SI-SDRi (↑), CLAP (↑)
主要结果对比(表1:VGGSound-clean+数据集):
| 方法 | 查询类型 | Mean SDR↑ | Mean SIR↑ | Mean SAR↑ | Mean SI-SDRi↑ | Mean CLAPt↑ |
|---|---|---|---|---|---|---|
| 文本查询 | ||||||
| LASS-Net | 3.98±1.02 | 7.63±0.85 | 4.24±1.00 | 4.25±0.76 | 5.12±0.71 | |
| CLIPSEP-NIT | 2.71±0.87 | 4.58±1.37 | 13.60±0.68 | 2.41±0.53 | 7.97±0.94 | |
| AudioSep | 6.26±0.87 | 8.69±0.90 | 12.85±0.92 | 4.01±0.59 | 8.21±0.96 | |
| OmniSep | 6.70±0.66 | 9.04±0.98 | 13.61±0.77 | 4.38±0.48 | 8.98±0.89 | |
| MARS-Sep (Ours) | 6.91±0.68 | 9.14±1.00 | 13.73±0.77 | 4.55±0.44 | 9.03±0.94 | |
| 音频查询 | ||||||
| OmniSep | 7.15±0.65 | 11.65±1.02 | 11.84±0.81 | 4.35±0.52 | 8.60±0.91 | |
| MARS-Sep (Ours) | 7.33±0.67 | 11.63±1.00 | 12.00±0.84 | 4.36±0.50 | 8.91±0.91 | |
| 图像查询 | ||||||
| CLIPSEP-NIT | 4.61±0.82 | 8.11±1.32 | 12.06±0.78 | 3.48±0.60 | 8.50±0.92 | |
| iQuery | 6.20±0.78 | 9.59±0.88 | 13.45±1.01 | 3.77±0.46 | 6.08±1.12 | |
| DAVIS-Flow | 6.52±1.01 | 9.87±0.98 | 13.54±0.93 | 4.32±0.96 | 8.89±1.02 | |
| OmniSep | 6.66±0.65 | 10.00±1.05 | 13.73±0.76 | 4.43±0.50 | 8.79±0.89 | |
| MARS-Sep (Ours) | 6.93±0.67 | 10.18±1.04 | 13.41±0.72 | 4.57±0.47 | 9.19±0.91 | |
| 组合查询 | ||||||
| OmniSep | 7.79±0.72 | 10.76±1.00 | 14.53±0.93 | 5.16±0.47 | 8.85±0.92 | |
| MARS-Sep (Ours) | 7.93±0.75 | 10.65±1.00 | 14.49±0.95 | 5.20±0.45 | 9.22±0.90 |
关键结论:MARS-Sep在四种查询类型下的CLAP分数均达到最优,SDR和SI-SDRi也普遍占优,表明其在语义对齐和信号保真度上均有提升。与基线OmniSep相比,提升幅度在多数情况下是稳定但温和的(例如,SDR提升约0.2 dB,CLAP提升约0.05-0.4%)。
生成模型对比(表3,部分):
| 方法 | 数据集 | CLAPt score (%) | CLAPa score (%) |
|---|---|---|---|
| ZeroSep | MUSIC-clean+ | 20.02 ± 15.14 | 22.86 ± 18.55 |
| FlowSep | MUSIC-clean+ | 10.67 ± 14.17 | 39.25 ± 29.86 |
| MarsSep (Ours) | MUSIC-clean+ | 6.18 ± 0.93 | 21.56 ± 1.08 |
| ZeroSep | VGGSOUND-clean+ | 15.91 ± 14.17 | 22.65 ± 19.98 |
| FlowSep | VGGSOUND-clean+ | 8.84 ± 13.27 | 56.07 ± 19.57 |
| MarsSep (Ours) | VGGSOUND-clean+ | 9.03 ± 0.94 | 18.70 ± 1.23 |
关键结论:与生成式模型(ZeroSep, FlowSep)相比,MARS-Sep的CLAP分数(尤其是CLAPt)方差极小(±0.93 vs ±15.14),表明其语义对齐性能非常稳定。虽然FlowSep在某些CLAPa上得分更高,但其方差巨大,可靠性不足。
关键消融实验(表11,训练配置对比):
| 方法 | Mean SDR↑ | Mean SIR↑ | Mean SAR↑ | Mean SI-SDRi↑ | Mean CLAPt↑ |
|---|---|---|---|---|---|
| Baseline (监督+冻结编码器) | 6.70±0.66 | 9.04±0.98 | 13.61±0.77 | 4.38±0.48 | 8.98±0.89 |
| RL-only (RL+冻结编码器) | 6.71±0.70 | 9.04±1.02 | 14.08±0.80 | 4.50±0.75 | 8.96±0.90 |
| FT-only (监督+微调编码器) | 0.75±0.64 | 1.41±1.18 | 87.13±0.15 | 0.00±0.00 | 5.48±0.95 |
| RL+FT (完整模型) | 6.91±0.68 | 9.14±1.00 | 13.73±0.77 | 4.55±0.44 | 9.03±0.94 |
关键结论:仅微调编码器(FT-only)会导致灾难性结果(SDR崩溃,SAR异常高),表明传统监督目标无法有效利用更敏感的编码器。仅RL(RL-only)能带来一定提升。而RL与渐进式微调(FT)结合(RL+FT)取得最佳综合性能,验证了两个组件的互补性和必要性。
定性结果: VGGSOUND-clean+数据集上不同查询模态分离结果的对数梅尔频谱图] 图3:VGGSOUND-clean+数据集上不同查询模态分离结果的对数梅尔频谱图。目标源为“牛铃”。从左到右:(a)“牛铃”与“踢踏舞”的混合;(b) 真实“牛铃”;(c) 干扰“踢踏舞”;(d) 基线模型的文本查询分离;(e) 本文方法的文本查询分离。结论:MARS-Sep更有效地抑制了非目标成分,同时更好地保留了目标源的谐波结构和时域连续性。
设置说明:VGGSOUND-clean+和MUSIC-clean+是经过清洗的VGGSound和MUSIC子集,确保音视频对齐质量。评估采用标准分离指标,计算时使用museval工具包。
- 学术质量:6.0/7:创新性明确(RL范式迁移),技术路线正确且实现细节完备(PPO变体、Beta策略)。实验非常充分,涵盖多数据集、多查询类型、多基线对比及大量消融实验,证据链完整。主要不足在于创新属于范式应用而非理论突破,且性能提升幅度未达到颠覆性水平。
- 选题价值:1.5/2:课题直指声音分离的核心挑战(语义一致性),具有很高的前沿性和实用价值,对下游音频任务有直接帮助。
- 开源与复现加成:0.5/1:提供了代码链接,实验设置详尽,有利于复现。但未明确提及模型权重和完整训练管道的公开,加成中等。
开源详情
- 代码:论文明确提供了代码仓库链接:https://github.com/mars-sep/MARS-Sep。
- 模型权重:论文中未提及是否公开预训练的模型权重。
- 数据集:使用了VGGSound-clean+和MUSIC-clean+,论文中说明是清洗后的子集,但未提供获取方式或是否作为独立数据集发布。
- Demo:论文提供了项目主页和示例链接:https://mars-sep.github.io/。
- 复现材料:论文附录(B、C、D、E节)详细说明了实验设置、数据预处理、超参数、训练细节和评估协议,复现信息较为充分。
- 引用的开源项目:论文依赖的开源工具/模型包括:ImageBind(视觉-语言-音频基础模型),CLAP(用于评估),museval(用于评估),以及OmniSep作为基线代码库。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:https://github.com/mars-sep/MARS-Sep。
- 模型权重:论文中未提及是否公开预训练的模型权重。
- 数据集:使用了VGGSound-clean+和MUSIC-clean+,论文中说明是清洗后的子集,但未提供获取方式或是否作为独立数据集发布。
- Demo:论文提供了项目主页和示例链接:https://mars-sep.github.io/。
- 复现材料:论文附录(B、C、D、E节)详细说明了实验设置、数据预处理、超参数、训练细节和评估协议,复现信息较为充分。
- 引用的开源项目:论文依赖的开源工具/模型包括:ImageBind(视觉-语言-音频基础模型),CLAP(用于评估),museval(用于评估),以及OmniSep作为基线代码库。
🏗️ 模型架构
MARS-Sep是一个基于强化学习的声音分离框架,其核心架构围绕着“策略-奖励-优化”的闭环设计(见下图)。
整体输入输出流程:
- 输入:混合音频波形
x(t)和多模态查询Q(文本、音频片段或图像)。 - 中间处理:
- 混合音频通过短时傅里叶变换(STFT)得到幅度谱
X。 - 查询
Q通过对应的ImageBind编码器(文本/音频/视觉)和查询混合器(Query-Mixup)得到融合查询特征。 - 分离网络(Separate-Net,基于U-Net)接收
X和Q的特征,输出掩码提议P_θ。 P_θ通过参数化映射转化为Beta分布的浓度参数(α, β),构成随机策略π_θ。
- 混合音频通过短时傅里叶变换(STFT)得到幅度谱
- 动作采样与重建:从旧策略快照
π_θ_old中采样一个掩码M,用M对X进行掩码操作并结合相位进行逆STFT,重建分离后的音频波形ŷ。 - 奖励计算:
- 预训练的多模态编码器(渐进式微调后的ImageBind)分别将
ŷ、目标音频y⋆、目标文本t⋆、目标视频帧v⋆编码。 - 使用多模态低秩双线性池化(MLBP)将
y⋆,t⋆,v⋆的特征融合为一个目标锚点z⋆。 - 计算
ŷ的嵌入与z⋆的余弦相似度作为标量奖励R。
- 预训练的多模态编码器(渐进式微调后的ImageBind)分别将
- 策略更新:利用奖励
R、优势估计Ã和新旧策略的概率比r_θ(M),计算包含裁剪、熵正则和KL惩罚的策略梯度损失,并更新当前策略网络π_θ。同时,将π_θ快照为新的π_θ_old用于下一次迭代。
主要组件:
- 基础策略网络(Base Policy):基于OmniSep的分离架构,一个7层U-Net,在时频域预测掩码提议。它接收混合音频谱和通过ImageBind编码的查询特征。
- 随机掩码策略(Factorized Beta Mask Policy):核心创新点之一。将U-Net的输出视为对每个时频点(频率-时间-源维度)的掩码概率的预测,并将其转化为一个各点独立的Beta分布
(α, β)参数。通过从该分布中采样,使得掩码生成具有探索性,且探索范围由浓度参数κ控制。 - 多模态奖励模型(Multimodal Reward Model):基于ImageBind,但经过三个阶段的渐进式对比微调,以增强其跨模态判别能力。它负责评估分离音频与多模态查询的语义一致性。
- 稳定策略优化器(Stable Policy Optimizer):采用PPO风格的裁剪目标,结合了组相对优势归一化(GRPO)、熵正则化(鼓励探索)和KL散度惩罚(约束策略漂移),确保训练稳定。
关键设计选择及动机:
- 选择因子化Beta分布而非直接回归确定性掩码,是为了将分离过程自然地建模为随机决策,便于应用RL进行优化,并提供探索-利用的权衡机制。
- 使用MLBP融合多模态目标特征而非简单拼接或平均,是为了显式建模模态间的乘性交互,从而生成一个更强大的、统一的语义锚点来计算奖励,避免单一模态主导。
- 采用渐进式微调ImageBind而非从头训练或使用原始预训练模型,是为了逐步、稳定地提升其在声音分离任务上的语义判别力,防止灾难性遗忘,为RL提供更可靠的奖励信号。
图1:MARS-Sep的强化学习循环示意图。分离器从Beta分布策略生成随机掩码动作,而冻结的快照作为旧策略用于稳定优化。来自音频、文本和视觉嵌入的多模态奖励指导策略更新,熵和KL正则化增强探索和稳定性。
渐进式对齐微调策略示意图] 图2:用于声音源判别和分离的渐进式微调策略。编码器保持冻结,特定任务的头部逐步解冻,每个阶段都建立在前一阶段最佳检查点的基础上。后两个阶段使用部分前一对齐的配对数据训练,以避免灾难性遗忘。
💡 核心创新点
- 将声音分离重构为强化学习问题:这是最具范式性的创新。不同于传统监督学习直接回归理想掩码,MARS-Sep将分离过程视为在给定混合音频和查询下,通过采样掩码策略来最大化语义奖励的序列决策问题。这使得优化目标直接对齐人类意图(语义一致性),而不仅仅是像素级/波形级相似度。
- 因子化Beta掩码策略与裁剪信任域优化:针对掩码值在[0,1]区间的特点,设计了因子化Beta分布策略,并通过参数化映射与网络输出关联。同时,提出了一种融合了GRPO优势归一化、熵正则和KL惩罚的PPO变体优化器,解决了传统策略梯度在连续动作空间上的不稳定性问题,实现了高效稳定的策略更新。
- 基于渐进式对齐的多模态奖励模型:为了提供稳定、有效的奖励信号,论文设计了一个三阶段的对比学习课程来微调ImageBind编码器(音频-文本 -> 音频-音频 -> 音频-视频),逐步增强其跨模态语义判别力。奖励计算采用非对称设计:将多模态目标融合为一个锚点,与分离音频比较,这减少了采样噪声的影响,并强制分离结果与所有模态保持一致。
- 多模态低秩双线性池化(MLBP)用于查询聚合:在奖励模型中,使用MLBP将来自不同模态(音频、文本、视频)的目标特征进行融合。相比于简单聚合,MLBP能更有效地捕捉模态间的复杂交互,生成更具代表性的语义锚点,从而提供更准确、更鲁棒的奖励信号。
🔬 细节详述
- 训练数据:论文在VGGSound-clean+和MUSIC-clean+两个数据集上进行实验。VGGSound-clean+是VGGSound的清洗子集,包含300+类别YouTube视频;MUSIC-clean+是MUSIC的清洗子集,包含独奏和二重奏音乐视频。预处理包括音频重采样至16kHz,裁剪至约4秒(65535样本点);图像调整至224x224像素。未明确提及具体的数据增强方法。
- 损失函数:训练损失由两部分组成:
- 监督损失(用于预训练/基线):加权二元交叉熵(WBCE)损失,用于监督掩码预测。
- 强化学习损失
L_RL(θ):即J_clip(θ)的负值。J_clip(θ)公式见论文公式(4),包含三项:a) 裁剪的策略梯度代理目标;b) 熵正则项λ_H H(π_θ),鼓励策略多样性;c) KL惩罚项-λ_KL KL(π_θ || π_θ_old),约束策略更新幅度。
- 训练策略:
- 优化器:AdamW,学习率
2e-4,权重衰减0.01。 - 批次大小:128。
- 训练步数:200,000步。
- 学习率调度:未明确说明,但提到使用了warmup策略。
- 梯度裁剪:最大梯度范数为1.0。
- 混合精度:分离器网络使用FP16/BF16,奖励计算使用FP32。
- RL细节:采用单轮PPO更新,每步更新策略快照。旧策略
π_θ_old从当前策略π_θ快照得到。优势使用指数移动平均基线(β=0.92)计算,并启用GRPO归一化。每次迭代使用1个蒙特卡洛采样。
- 优化器:AdamW,学习率
- 关键超参数:
- Beta分布浓度参数
κ = 9。 - PPO裁剪范围
ϵ = 0.2。 - 熵系数
λ_H = 0.1。 - KL系数
λ_KL = 0.01(默认开启)。 - 分离网络为7层U-Net,输出32个中间掩码(K=32)。
- STFT参数:滤波器长度1024,跳长256,窗大小1024。
- Beta分布浓度参数
- 训练硬件:论文主要实验在单张NVIDIA A800 40GB GPU上进行。消融实验部分提及在A100上进行。
- 推理细节:推理时直接使用训练好的策略网络
π_θ生成确定性掩码提议P_θ,并将P_θ转化为α=1+κP_θ,β=1+κ(1-P_θ)后取均值掩码(或直接使用P_θ作为掩码)进行重建,无需采样。未提及流式处理设置。 - 正则化与稳定训练技巧:除了上述的熵正则和KL惩罚,还包括渐进式微调以防止灾难性遗忘、优势归一化(GRPO)以减少方差、以及奖励计算的非对称设计以降低策略噪声影响。
📊 实验结果
主要Benchmark与指标: 数据集:VGGSound-clean+, MUSIC-clean+ 指标:SDR (↑), SIR (↑), SAR (↑), SI-SDRi (↑), CLAP (↑)
主要结果对比(表1:VGGSound-clean+数据集):
| 方法 | 查询类型 | Mean SDR↑ | Mean SIR↑ | Mean SAR↑ | Mean SI-SDRi↑ | Mean CLAPt↑ |
|---|---|---|---|---|---|---|
| 文本查询 | ||||||
| LASS-Net | 3.98±1.02 | 7.63±0.85 | 4.24±1.00 | 4.25±0.76 | 5.12±0.71 | |
| CLIPSEP-NIT | 2.71±0.87 | 4.58±1.37 | 13.60±0.68 | 2.41±0.53 | 7.97±0.94 | |
| AudioSep | 6.26±0.87 | 8.69±0.90 | 12.85±0.92 | 4.01±0.59 | 8.21±0.96 | |
| OmniSep | 6.70±0.66 | 9.04±0.98 | 13.61±0.77 | 4.38±0.48 | 8.98±0.89 | |
| MARS-Sep (Ours) | 6.91±0.68 | 9.14±1.00 | 13.73±0.77 | 4.55±0.44 | 9.03±0.94 | |
| 音频查询 | ||||||
| OmniSep | 7.15±0.65 | 11.65±1.02 | 11.84±0.81 | 4.35±0.52 | 8.60±0.91 | |
| MARS-Sep (Ours) | 7.33±0.67 | 11.63±1.00 | 12.00±0.84 | 4.36±0.50 | 8.91±0.91 | |
| 图像查询 | ||||||
| CLIPSEP-NIT | 4.61±0.82 | 8.11±1.32 | 12.06±0.78 | 3.48±0.60 | 8.50±0.92 | |
| iQuery | 6.20±0.78 | 9.59±0.88 | 13.45±1.01 | 3.77±0.46 | 6.08±1.12 | |
| DAVIS-Flow | 6.52±1.01 | 9.87±0.98 | 13.54±0.93 | 4.32±0.96 | 8.89±1.02 | |
| OmniSep | 6.66±0.65 | 10.00±1.05 | 13.73±0.76 | 4.43±0.50 | 8.79±0.89 | |
| MARS-Sep (Ours) | 6.93±0.67 | 10.18±1.04 | 13.41±0.72 | 4.57±0.47 | 9.19±0.91 | |
| 组合查询 | ||||||
| OmniSep | 7.79±0.72 | 10.76±1.00 | 14.53±0.93 | 5.16±0.47 | 8.85±0.92 | |
| MARS-Sep (Ours) | 7.93±0.75 | 10.65±1.00 | 14.49±0.95 | 5.20±0.45 | 9.22±0.90 |
关键结论:MARS-Sep在四种查询类型下的CLAP分数均达到最优,SDR和SI-SDRi也普遍占优,表明其在语义对齐和信号保真度上均有提升。与基线OmniSep相比,提升幅度在多数情况下是稳定但温和的(例如,SDR提升约0.2 dB,CLAP提升约0.05-0.4%)。
生成模型对比(表3,部分):
| 方法 | 数据集 | CLAPt score (%) | CLAPa score (%) |
|---|---|---|---|
| ZeroSep | MUSIC-clean+ | 20.02 ± 15.14 | 22.86 ± 18.55 |
| FlowSep | MUSIC-clean+ | 10.67 ± 14.17 | 39.25 ± 29.86 |
| MarsSep (Ours) | MUSIC-clean+ | 6.18 ± 0.93 | 21.56 ± 1.08 |
| ZeroSep | VGGSOUND-clean+ | 15.91 ± 14.17 | 22.65 ± 19.98 |
| FlowSep | VGGSOUND-clean+ | 8.84 ± 13.27 | 56.07 ± 19.57 |
| MarsSep (Ours) | VGGSOUND-clean+ | 9.03 ± 0.94 | 18.70 ± 1.23 |
关键结论:与生成式模型(ZeroSep, FlowSep)相比,MARS-Sep的CLAP分数(尤其是CLAPt)方差极小(±0.93 vs ±15.14),表明其语义对齐性能非常稳定。虽然FlowSep在某些CLAPa上得分更高,但其方差巨大,可靠性不足。
关键消融实验(表11,训练配置对比):
| 方法 | Mean SDR↑ | Mean SIR↑ | Mean SAR↑ | Mean SI-SDRi↑ | Mean CLAPt↑ |
|---|---|---|---|---|---|
| Baseline (监督+冻结编码器) | 6.70±0.66 | 9.04±0.98 | 13.61±0.77 | 4.38±0.48 | 8.98±0.89 |
| RL-only (RL+冻结编码器) | 6.71±0.70 | 9.04±1.02 | 14.08±0.80 | 4.50±0.75 | 8.96±0.90 |
| FT-only (监督+微调编码器) | 0.75±0.64 | 1.41±1.18 | 87.13±0.15 | 0.00±0.00 | 5.48±0.95 |
| RL+FT (完整模型) | 6.91±0.68 | 9.14±1.00 | 13.73±0.77 | 4.55±0.44 | 9.03±0.94 |
关键结论:仅微调编码器(FT-only)会导致灾难性结果(SDR崩溃,SAR异常高),表明传统监督目标无法有效利用更敏感的编码器。仅RL(RL-only)能带来一定提升。而RL与渐进式微调(FT)结合(RL+FT)取得最佳综合性能,验证了两个组件的互补性和必要性。
定性结果: VGGSOUND-clean+数据集上不同查询模态分离结果的对数梅尔频谱图] 图3:VGGSOUND-clean+数据集上不同查询模态分离结果的对数梅尔频谱图。目标源为“牛铃”。从左到右:(a)“牛铃”与“踢踏舞”的混合;(b) 真实“牛铃”;(c) 干扰“踢踏舞”;(d) 基线模型的文本查询分离;(e) 本文方法的文本查询分离。结论:MARS-Sep更有效地抑制了非目标成分,同时更好地保留了目标源的谐波结构和时域连续性。
设置说明:VGGSOUND-clean+和MUSIC-clean+是经过清洗的VGGSound和MUSIC子集,确保音视频对齐质量。评估采用标准分离指标,计算时使用museval工具包。
⚖️ 评分理由
- 学术质量:6.0/7:创新性明确(RL范式迁移),技术路线正确且实现细节完备(PPO变体、Beta策略)。实验非常充分,涵盖多数据集、多查询类型、多基线对比及大量消融实验,证据链完整。主要不足在于创新属于范式应用而非理论突破,且性能提升幅度未达到颠覆性水平。
- 选题价值:1.5/2:课题直指声音分离的核心挑战(语义一致性),具有很高的前沿性和实用价值,对下游音频任务有直接帮助。
- 开源与复现加成:0.5/1:提供了代码链接,实验设置详尽,有利于复现。但未明确提及模型权重和完整训练管道的公开,加成中等。