📄 MAPSS: Manifold-based Assessment of Perceptual Source Separation
#模型评估 #自监督学习 #信号处理 #语音分离 #音频质量
🔥 8.5/10 | 前25% | #模型评估 | #自监督学习 | #信号处理 #语音分离
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Amir Ivry(Technion - Israel Institute of Technology, Electrical and Computer Engineering)
- 通讯作者:未明确指定(根据邮箱顺序推测为Amir Ivry)
- 作者列表:Amir Ivry(Technion - Israel Institute of Technology)、Samuele Cornell(Carnegie Mellon University, Language Technologies Institute)、Shinji Watanabe(Carnegie Mellon University, Language Technologies Institute)
💡 毒舌点评
亮点在于其优雅的数学框架(流形+马氏距离)将“分离度”和“保真度”评估解耦,并为每个测量值提供了理论误差边界,这在音频评估指标中非常罕见。然而,其性能高度依赖一个预先定义的、手工设计的“失真库”来构建感知流形,这似乎将评估的泛化能力瓶颈从模型转移到了这个失真库的覆盖面上,且对时间对齐的敏感性可能限制其在实际延迟系统中的应用。
🔗 开源详情
- 代码:提供了完整的代码仓库链接:https://github.com/Amir-Ivry/MAPSS-measures 。论文明确说明代码包含完整的推理流程,包括帧级PS/PM计算及其确定性和概率误差边界。
- 模型权重:论文中未提供其使用的预训练自监督模型(wav2vec 2.0, MERT)的权重链接,但这些是公开模型,可从Hugging Face Hub等平台获取。
- 数据集:论文使用的SEBASS数据库是公开的,但需按照其原始发布渠道获取。论文中未重新分发数据。
- Demo:未提及在线演示。
- 复现材料:论文在附录和可复现性声明中提供了非常详细的计算过程、参数设置和实验细节,足以支持复现。开源代码是核心复现材料。
- 论文中引用的开源项目:主要依赖的开源工具/模型包括:wav2vec 2.0、WavLM、HuBERT(自监督语音模型)、MERT(自监督音乐模型)、SEBASS数据库、webMUSHRA(用于原始听力测试)。
📌 核心摘要
该论文针对音频源分离系统评估中,现有指标(如SDR、SI-SDR)无法区分“干扰泄漏”与“目标失真”这两种本质不同的失真模式的问题,提出了两个新的可微分、帧级评估指标:感知分离(Perceptual Separation, PS)和感知匹配(Perceptual Match, PM)。方法核心是,首先为每个参考信号生成一组覆盖广泛感知失真类型的变形版本,然后利用预训练的自监督模型(如wav2vec 2.0)将所有原始信号、失真信号及系统输出进行编码,再通过扩散映射(Diffusion Maps)将这些高维表示嵌入到一个低维流形空间。在此流形上,PM通过测量输出点与其自身“感知簇”的距离来量化自失真,而PS则通过比较该输出点与自身簇及非归属簇的相对距离来量化泄漏。与已有方法相比,新在:1)功能上解耦了泄漏与失真;2)操作在精细的帧级(75fps)并可微分;3)首次为音频评估指标提供了确定性误差半径和非渐近概率置信区间。实验表明,在SEBASS数据集(包含英语、西班牙语和音乐混合物)上,PS和PM在与人类主观评分的线性相关(PCC)和秩相关(SRCC)中,几乎总能排在18个对比指标的第一或第二。该指标的意义在于为源分离系统提供了更细粒度的诊断工具和潜在的损失函数,局限性在于其性能对时间对齐敏感,且依赖于预定义失真库的覆盖范围。
🏗️ 模型架构
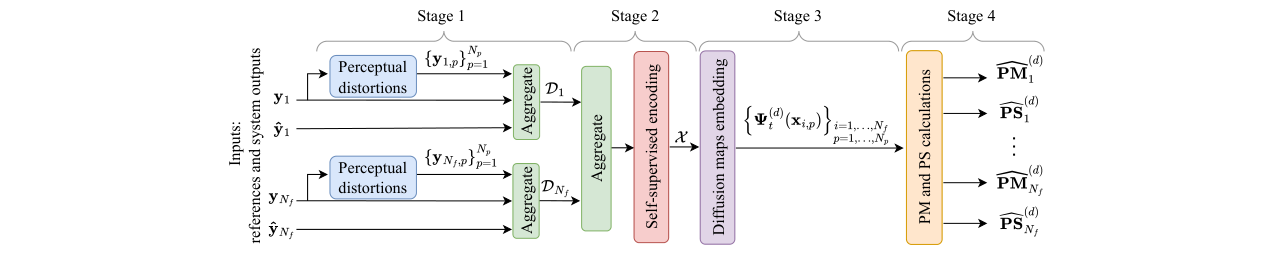
本文并非提出一个分离模型,而是提出一个评估指标框架(MAPSS)。其整体流程如图1所示,分为四个主要阶段:
- 阶段1:感知失真生成。对于混合物中的每个参考源信号,独立应用一个包含约60-70种基础失真(如陷波滤波、颤音、混响、硬削波等)的“失真库”,生成一组失真版本。这些失真旨在覆盖参考信号周围的感知听觉场。
- 阶段2:自监督编码。将所有参考信号、其失真版本以及所有系统的输出信号,独立输入到一个预训练的自监督模型中进行编码。对于语音任务使用wav2vec 2.0,对于音乐使用MERT模型。该阶段将时域波形转换为高维特征向量序列(如每秒75帧)。
- 阶段3:扩散映射嵌入。将阶段2得到的所有高维表示汇总,通过扩散映射这一流形学习技术,将它们嵌入到一个低维流形空间。扩散映射的关键性质是:嵌入后低维空间中的欧氏距离,与高维空间中表示之间的扩散距离(一种衡量数据点间差异性的度量)对齐。这为后续基于距离的测量奠定了基础。
- 阶段4:PS与PM度量计算。在构建的流形上,为每个源的失真和参考信号创建一个“感知簇”。对于该源的系统输出嵌入点:
- PM(感知匹配):计算该输出点到其自身感知簇中心的马氏距离,并通过与簇内失真点距离分布(拟合Gamma分布)的比较,得到一个归一化的概率分数(0-1)。分数越高,表示输出与原始参考及可控失真的感知差异越小,即自失真越低。
- PS(感知分离):计算该输出点到其自身簇中心和最近的非归属簇中心的马氏距离。PS分数由这两个距离的相对大小决定。分数越高,表示输出点离自身簇越近、离干扰源簇越远,即泄漏越少。
关键设计选择及其动机:
- 使用自监督编码器而非原始波形:实验表明,直接使用原始波形(波形版本)性能显著下降,证明自监督模型的表示更能捕捉感知相关特征。
- 使用扩散映射而非直接在高维空间计算距离:扩散映射能有效学习数据的内在几何结构,其欧氏距离与扩散距离的等价性为度量提供了理论依据,且能降维去噪。
- 使用马氏距离:考虑了感知簇内数据点的分布(均值与协方差),比欧氏距离更能反映点与簇的统计关联性。
- PM中使用Gamma分布拟合:验证了失真点到参考点的马氏距离平方近似服从Gamma分布,从而可以利用Gamma分布的尾部概率来定义PM分数,具有概率解释。
💡 核心创新点
- 功能解耦泄漏与失真:首次提出能同时独立量化“目标信号自失真”(PM)和“干扰信号泄漏”(PS)的评估指标,解决了传统SDR族指标将两者混合的根本问题。
- 基于流形的感知空间构建:创新性地将预训练自监督编码与扩散映射流形学习相结合,构建了一个几何意义明确(距离对齐感知差异)的低维评估空间,而非依赖手工设计的特征或端到端训练的黑盒评分器。
- 提供理论误差保证:为评估指标推导了基于流形截断的确定性误差半径和基于有限样本的非渐近、高概率置信区间。这是音频评估指标领域的重要理论补充,使度量结果更具可解释性和可靠性。
🔬 细节详述
- 训练数据:本方法本身不需要训练。其依赖的核心组件是预训练的自监督模型(wav2vec 2.0 for speech, MERT for music)和公开的SEBASS评估数据库。SEBASS包含11000个专家评分,覆盖英语、西班牙语说话人混合物及音乐混合物。
- 损失函数:不涉及训练,因此无损失函数。
- 训练策略:不涉及。
- 关键超参数:
- 失真库参数:失真类型及参数范围见附录表3(例如,加性噪声SNR从-15dB到15dB,混响RT60从0.3s到1.1s等)。
- 扩散映射参数:α=1(消除密度偏差),t=1(聚焦局部结构),截断维度d根据保留特征值总和比例τ=0.99确定,通常在20-40维。
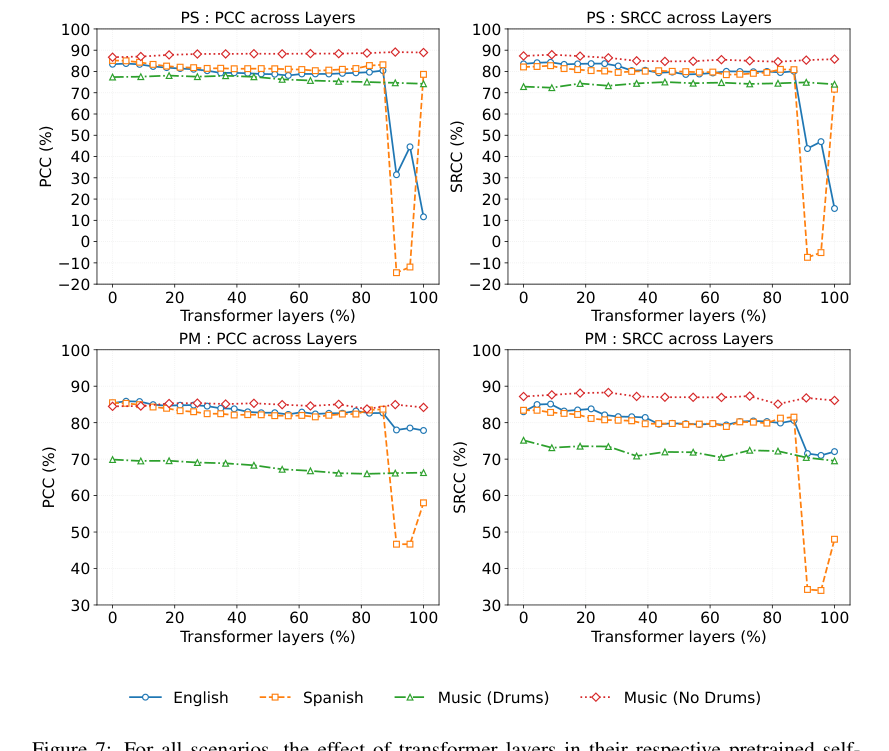
- 自监督模型层选择:对于英语(wav2vec2-Large)、西班牙语(wav2vec2-XLSR-Large)、音乐无鼓(MERT)、音乐有鼓(MERT),分别使用第2、2、3、1层。选择依据是各层在PM和PS指标上的综合性能。
- 帧级到句级聚合:PM采用简单平均,PS采用受PESQ启发的、基于p-范数和逻辑映射的加权聚合,以惩罚低分帧。
- 训练硬件:未说明(因方法无训练过程)。
- 推理细节:计算PS和PM分数时,需要为每个混合物的所有源信号生成失真库并进行编码,计算量较大,但可并行。马氏距离计算中使用ε=1e-6的Tikhonov正则化以确保矩阵可逆。
- 正则化或稳定训练技巧:不涉及。
📊 实验结果
主要评估在SEBASS数据库上进行,与18个主流指标对比,衡量与人类平均意见得分(MOS)的Pearson相关系数(PCC)和Spearman秩相关系数(SRCC)。
主要对比结果(部分关键指标,完整见论文Table 1):
| 指标 | 英语 SRCC/PCC | 西班牙语 SRCC/PCC | 音乐(有鼓) SRCC/PCC | 音乐(无鼓) SRCC/PCC |
|---|---|---|---|---|
| PS | 84.12% / 83.74% | 82.33% / 85.01% | 72.87% / 77.38% | 87.23% / 87.81% |
| PM | 84.69% / 86.36% | 83.41% / 85.30% | 75.18% / 69.88% | 88.12% / 85.26% |
| PESQ | 85.56% / 84.05% | 86.06% / 84.98% | 61.60% / 53.87% | 61.26% / 60.24% |
| SI-SDR | 78.11% / 76.96% | 84.07% / 81.38% | 42.08% / 56.98% | 70.42% / 71.96% |
| STOI | 80.85% / 78.40% | 78.79% / 82.56% | 67.29% / 71.27% | 75.64% / 78.13% |
| … (其他14个指标) | … | … | … | … |
关键结论:
- PS和PM在几乎所有场景下都名列前茅,尤其在音乐(无鼓)和英语的PCC上表现突出。
- 波形版本消融:使用原始波形(无自监督编码)的PS和PM性能大幅下降(如英语PCC从83.74%降至71.04%),证明了自监督表示的关键作用。
- 误差边界:Table 2显示,PS和PM相关系数的确定性误差半径均小于1.4%,95%置信区间宽度在可接受范围,且PM的统计稳定性优于PS。
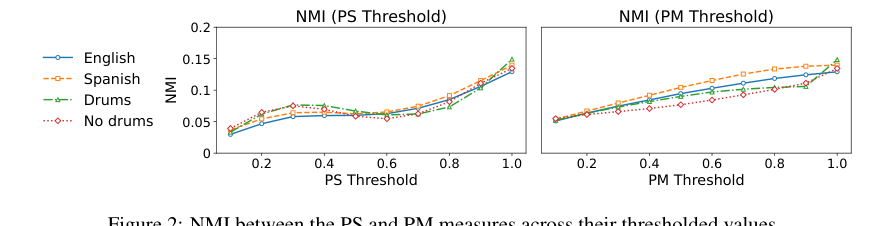
- 互补性分析:图2的归一化互信息(NMI)分析表明,随着阈值收紧(质量变差),PS和PM的NMI趋近于0,表明它们越来越互补,共同报告是有意义的。
- 稳健性与局限:对时间错位敏感(图8),超过20ms延迟后性能下降;对失真库覆盖有要求(表9),但PS的稳健性优于PM。
上图显示了在SEBASS数据集的英语、西班牙语及两种音乐混合物场景下,PS、PM及多个主流客观指标与人类MOS的SRCC和PCC值。关键结论是PS和PM(下划线标出)在大部分列中位于前两名。
⚖️ 评分理由
- 学术质量:6.2/7:在评估指标设计上具有明确的创新性和理论深度,实验设计严谨、对比充分、结果有说服力。但其创新集中于评估范式而非解决源分离问题本身,且部分设计(如失真库)略显经验性。
- 选题价值:1.5/2:直击源分离评估的核心痛点,提出的诊断性指标具有重要的理论和实践价值,能指导模型开发和优化。但“评估指标”这一子领域相对垂直,对广大AI从业者的直接影响小于解决某个具体应用问题的论文。
- 开源与复现加成:0.8/1:提供了完整的代码仓库,包含所有计算和分析脚本,复现指引清晰。减分项在于未包含预训练模型权重(需自行下载)和对SEBASS数据集的依赖(需单独获取)。