📄 MambaVoiceCloning: Efficient and Expressive Text-to-Speech via State-Space Modeling and Diffusion Control
#语音合成 #状态空间模型 #流式处理 #跨语言
✅ 6.5/10 | 前50% | #语音合成 | #状态空间模型 | #流式处理 #跨语言
学术质量 5.0/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Sahil Kumar (PhD Program in Mathematics, Yeshiva University, New York, NY 10033, USA)
- 通讯作者:Youshan Zhang* (School of Artificial Intelligence, Chuzhou University, Anhui, 239000, China)
- 作者列表:Sahil Kumar(叶史瓦大学数学博士项目)、Namrataben Patel(叶史瓦大学数学博士项目)、Honggang Wang(叶史瓦大学计算机科学与工程系)、Youshan Zhang(滁州学院人工智能学院)
💡 毒舌点评
亮点在于其设计的彻底性:为了证明SSM可以完全取代注意力,论文把TTS条件路径里的注意力模块剥得干干净净,只剩下一个训练时用的对齐器,这种“手术式”的架构验证值得肯定。短板则是性能提升实在像“技术微调”多过“范式突破”,在严格控制的条件下,MOS的些许涨跌更像是统计噪声的边缘胜利,让人怀疑其实际部署中的感知差异。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:https://github.com/sahilkumar15/MVC。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用的是公开数据集(LJSpeech, LibriTTS, VCTK, CSS10),并描述了详细的预处理流程。
- Demo:论文中未提及在线演示。
- 复现材料:提供了极其详细的复现材料,包括:完整的训练算法(算法1)、统一的优化器与学习率调度(附录C.2)、所有基线模型(StyleTTS2, VITS, JETS, Hybrid-Mamba)的匹配配置细节(附录C.4)、以及消融和超参数敏感性实验的设置。
- 引用的开源项目:主要依赖了以下开源工具/模型:StyleTTS2(解码器/声码器)、phonemizer(文本处理)、HiFi-GAN/iSTFTNet(声码器)、ESPnet(WER评估模型)。
📌 核心摘要
本文研究了一个问题:基于扩散的TTS模型,能否在推理时将文本、节奏和韵律的整个条件路径完全替换为状态空间模型(SSM),从而移除所有注意力机制?为此,作者提出了MambaVoiceCloning(MVC)模型。该模型核心包含三个Mamba组件:一个门控双向Mamba文本编码器、一个由训练时临时对齐器监督的临时双向Mamba、以及一个带有AdaLN调制的表达性Mamba。论文在LJSpeech和LibriTTS上训练,并在VCTK、CSS10和长段落文本上进行评估。实验结果表明,与基线StyleTTS2、VITS以及容量匹配的Mamba混合架构相比,MVC在MOS/CMOS、F0 RMSE、MCD和WER上取得了“适度但统计可靠”的提升,同时将编码器参数减少至21M,吞吐量提升1.6倍。然而,扩散解码器仍然是主要的延迟来源。该工作的实际意义在于验证了全SSM条件路径在提升编码器效率、内存占用和流式部署方面的潜力。其主要局限性在于性能提升幅度较小,且模型仅在英文数据集上训练,缺乏对细粒度情感控制的建模。
🏗️ 模型架构
MVC是一个基于扩散解码器的TTS系统,其核心创新在于将推理时的条件生成路径完全重构为SSM(Mamba)模块,解码器和声码器部分沿用现有StyleTTS2架构。
完整流程:输入为音素化文本和参考音频波形。参考音频被转换为Mel谱图,用于提取全局风格嵌入e。文本和e共同输入到三个并行的Mamba编码器中,分别处理文本特征、韵律(表达性)和节奏(时间)信息。这三个编码器的输出经过融合后,通过一个“语音动态”阶段生成最终的条件序列hD,该序列驱动固定的扩散解码器生成Mel谱图,最后由声码器转换为波形。
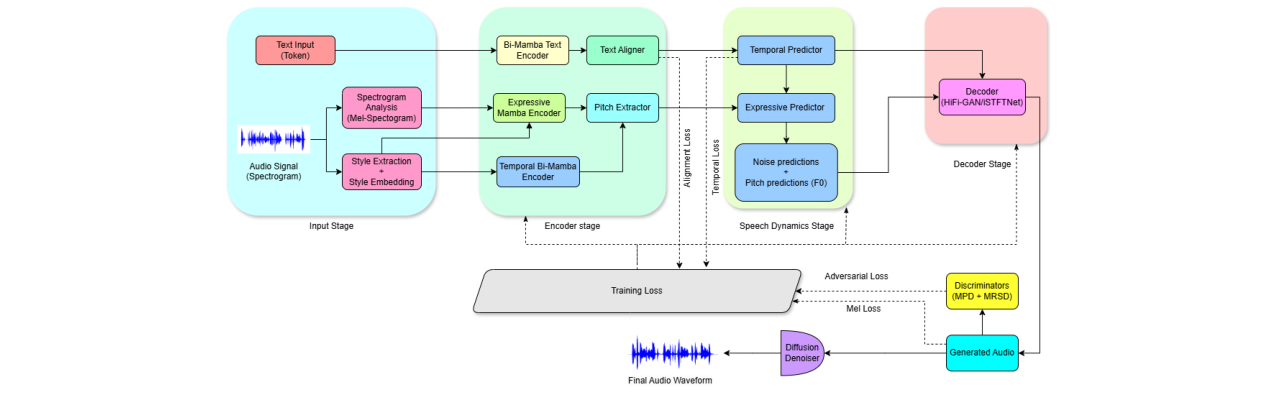
图1:MVC系统架构概览图。显示了Bi-Mamba文本编码器、临时Bi-Mamba和表达性Mamba的流程,以及它们如何共同驱动扩散解码器。
主要组件:
- 输入处理:文本经过归一化和音素化。Mel谱图计算标准。全局风格嵌入
e由Mel谱图通过一个浅层卷积/GRU模块得到,提供全局说话人/风格信息。 - 门控双向Mamba文本编码器:替代自注意力。输入文本嵌入
x,分别通过前向和后向Mamba扫描得到hf和hb。不同于以往简单的拼接,本文采用门控机制融合双向信息:hT = σ(Wg[hf; hb]) ⊙[hf; hb] Wo。最后,通过AdaLN使用风格嵌入e进行调制,得到hT,s。这是论文的核心创新之一,旨在提升长程韵律稳定性。 - 表达性Mamba编码器:处理Mel谱图特征
M,结合风格嵌入e,通过门控变换和AdaLN调制后,输入到Mamba块,输出表达性特征hE,捕获长时韵律动态。 - 临时双向Mamba编码器:建模节奏和音素-帧对齐。同样使用风格嵌入
e进行调制,通过双向Mamba和卷积捕获上下文依赖的时间模式,并线性融合。 - 训练时对齐器:一个轻量级的2层Transformer,仅在训练时使用,为临时编码器提供软对齐监督。推理时完全丢弃,这是保证推理路径SSM-only的关键。
- 语音动态与解码器条件:融合表达性和临时特征,预测基频
F0轨迹和残差噪声n,组合成最终条件hD,输入到StyleTTS2扩散解码器。
💡 核心创新点
- 完全SSM推理路径:与先前混合架构(如保留注意力用于时长或风格模块)不同,MVC在推理时,文本、节奏、韵律的条件路径完全由Mamba模块构成,无任何注意力或RNN式循环层。这直接回应了论文的研究问题,追求线性时间复杂度O(T)和有界激活内存。
- 门控双向Mamba融合与AdaLN:在文本编码器中,用带有门控机制的融合策略替代了简单的拼接。该门控能根据局部句法线索调制前向/上下文信息,结合AdaLN风格调制,被证明对长程韵律稳定性和OOD泛化至关重要(消融实验表8显示去除任一项会显著降低性能)。
- 轻量级训练时对齐器:为了获得帧级对齐监督而不污染推理路径,论文引入了一个在训练时使用、推理时丢弃的注意力对齐器。实验证明该设计对对齐噪声具有鲁棒性(附录B.7)。
🔬 细节详述
- 训练数据:主要使用LJSpeech(24小时,1说话人)和LibriTTS(245小时,1151说话人)。评估使用VCTK(零样本说话人)、CSS10(ES/DE/FR跨语言)和Gutenberg长段落(OOD文本)。
- 损失函数:
Ltotal = λmel Lmel + λadv Ladv + λalign Lalign。Lmel为Mel重建损失(L1);Ladv为对抗损失(使用多周期和多分辨率判别器);Lalign为对齐正则化损失(训练时对齐器的单调性先验)。 - 训练策略:使用AdamW优化器,学习率1e-4,权重衰减1e-4,余弦退火学习率调度,预热10k步,梯度裁剪1.0,指数移动平均(EMA,0.999),自动混合精度训练。LJSpeech模型训练200 epochs,LibriTTS模型训练300k步。
- 关键超参数:所有Mamba块使用状态维度
d_ssm=96,深度卷积核大小kconv=5,门控温度τgate=1.0。编码器深度:文本编码器默认6层。编码器总参数约21M。 - 训练硬件:论文未明确说明训练硬件型号和数量,仅提到在实验中使用了4块A100 40GB GPU(附录C.2)。
- 推理细节:使用固定的5步扩散调度。对于流式处理,将双向文本编码器替换为因果的Uni-Mamba,并支持有限前瞻(look-ahead L)。
- 正则化/稳定技巧:梯度裁剪、EMA、以及Mamba选择性扫描本身带来的数值稳定性是主要的稳定手段。
📊 实验结果
论文在严格控制的协议下(相同数据预处理、Mel前端、扩散解码器、声码器、优化器和训练调度)进行了评估。
主观评估(表1, LibriTTS未见说话人):
| 模型 | MOS-N ↑ | MOS-S ↑ |
|---|---|---|
| Ground Truth | 4.60 | 4.35 |
| VITS | 3.69 | 3.54 |
| StyleTTS2 | 4.15 | 4.03 |
| MVC (ours) | 4.22 | 4.07 |
| MVC在MOS-N和MOS-S上略微超过StyleTTS2,差异在统计学上显著(p < 0.01)。 |
客观评估(表4, LJSpeech):
| 模型 | F0 RMSE ↓ | MCD ↓ | WER ↓ | PESQ ↑ | RTF ↓ |
|---|---|---|---|---|---|
| VITS | 0.667 ± 0.011 | 4.97 ± 0.09 | 7.23% | 3.64 ± 0.08 | 0.0211 |
| StyleTTS2 | 0.651 ± 0.013 | 4.93 ± 0.06 | 6.50% | 3.79 ± 0.07 | 0.0174 |
| MVC (ours) | 0.653 ± 0.014 | 4.91 ± 0.07 | 6.52% | 3.85 ± 0.06 | 0.0169 |
| MVC取得了最佳的MCD和PESQ,以及最低的RTF。F0 RMSE和WER与StyleTTS2持平。 |
消融研究关键结果(表6 & 表8):
- 组件移除(OOD集,CMOS-N下降):移除表达性Mamba(-0.41),移除文本编码器(-0.38),移除临时编码器(-0.36)。表明每个模块都提供不可冗余的信息。
- 融合与条件消融(LJSpeech长句MOS):
- 完整MVC(门控+AdaLN): 4.16 ± 0.07
- 仅门控(无AdaLN): 4.02 ± 0.08
- 仅AdaLN(无门控): 3.95 ± 0.04
- 仅拼接(无门控,无AdaLN): 3.64 ± 0.09 表明门控融合和AdaLN两者对长程稳定性都至关重要。
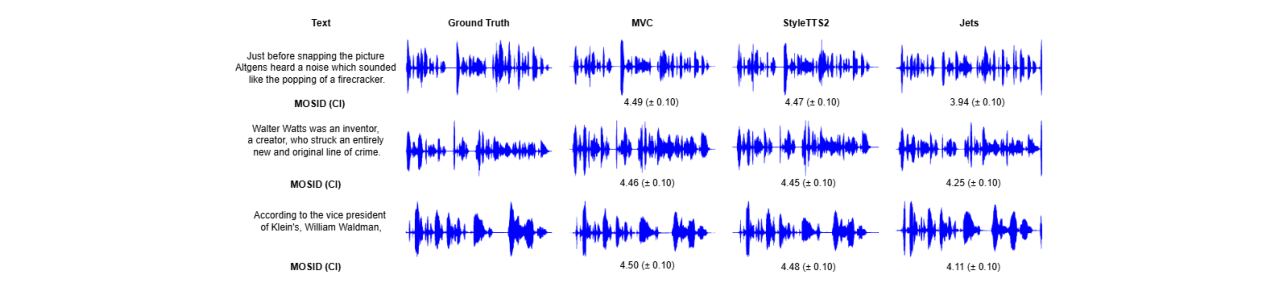
图2:在LJSpeech上的波形对比和MOS评估。MVC的波形与真值对齐更紧密。
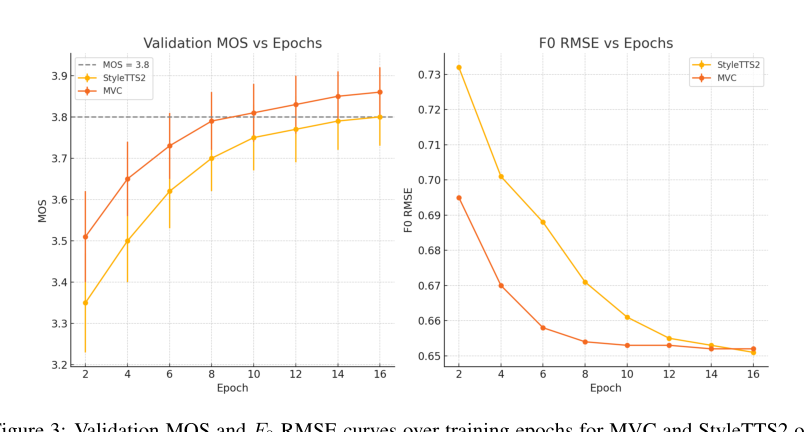
图4:频谱图对比。MVC更好地保持了谐波连续性和共振峰结构。
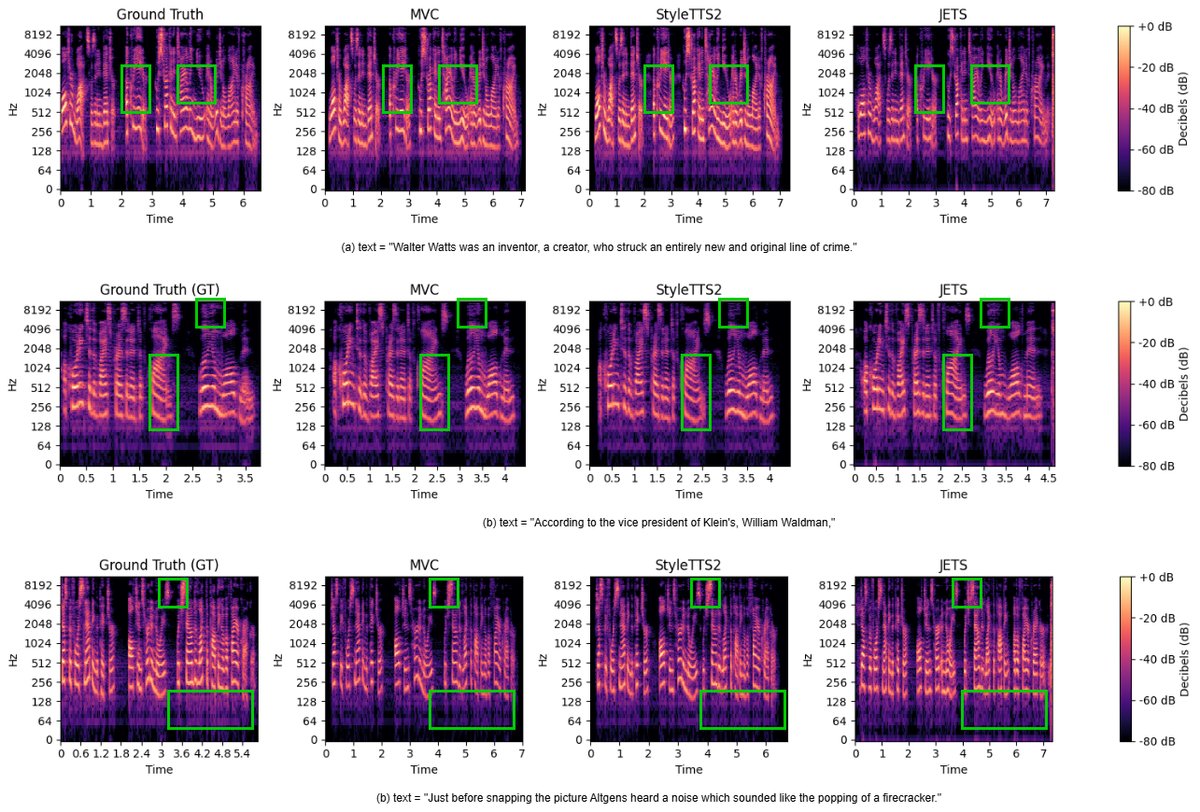
图6:模块运行时间分解。显示扩散解码器是主要延迟来源。
流式性能(表5):前瞻长度L从0.25秒到2.0秒,WER从11.2%下降到7.3%,MOS从3.74上升到3.91,表明SSM-only条件路径能优雅降级。
⚖️ 评分理由
- 学术质量(5.0/7):论文结构清晰,动机明确,技术方案(完全SSM路径、门控融合)有创新性。实验设计公平且充分,包括了与混合架构基线的对比、充分的消融研究和超参数敏感性分析。然而,所有核心质量指标(MOS, CMOS)的提升幅度都非常小(通常<0.1),这削弱了“改进”的显著性和说服力,使其更像一次有价值的架构探索,而非一次性能突破。
- 选题价值(1.0/2):研究如何为TTS设计高效、低内存的条件编码器具有实际应用价值,特别是对于边缘部署和流式合成。使用Mamba这一新兴架构进行尝试是前沿的。但选题范围限定在英文TTS,且性能提升有限,限制了其影响力。
- 开源与复现加成(0.5/1):提供了明确的代码链接,并在附录中详细说明了训练流程、基线配置和超参数,复现性良好。这显著提升了论文的可验证性和实用价值。